-
Java后端社招3年
写在前面
1.Mysql索引在什么情况下会失效
2.MySql的存储引擎InnoDB与MyISAM的区别
3.Mysql在项目中的优化场景,慢查询解决等
4.Mysql有什么索引,索引模型是什么
5.B-树与B+树的区别?为什么不用红黑树
6.Mysql主从同步怎么做
7.乐观锁与悲观锁的区别?
8.聊聊binlog日志
9.redis 持久化有哪几种方式,怎么选?
10.redis 主从同步是怎样的过程?
11.redis 的 zset 怎么实现的?
12.Redis 过期策略和内存淘汰策略
1.Mysql索引在什么情况下会失效
-
查询条件包含
or,可能导致索引失效 -
如果字段类型是字符串,
where时一定用引号括起来,否则索引失效 -
like通配符可能导致索引失效。 -
联合索引,查询时的条件列不是联合索引中的第一个列,索引失效。
-
在索引列上使用mysql的内置函数,索引失效。
-
对索引列运算(如,+、-、*、/),索引失效。
-
索引字段上使用(!= 或者 < >,not in)时,可能会导致索引失效。
-
索引字段上使用
is null, is not null,可能导致索引失效。 -
左连接查询或者右连接查询查询关联的字段编码格式不一样,可能导致索引失效。
-
mysql 估计使用全表扫描要比使用索引快,则不使用索引。
2.MySql的存储引擎InnoDB与MyISAM的区别
InnoDB支持事务、外键、行级锁。
3.Mysql在项目中的优化场景,慢查询解决等
加索引。你可以给面试官描述一下,一个加了索引的SQL,是怎么执行查找的。
还有就是order by,group by原理,深分页等等,都跟慢查询息息相关,都比较经典:
最后就是慢查询的排查解决手段:
打开慢查询日志
slow_query_log,确认SQL语句是否占用过多资源,用explain查询执行计划、对group by、order by、join等语句优化,如果数据量实在太大,是否考虑分库分表等等。4.Mysql有什么索引,索引模型是什么

5.B-树与B+树的区别?为什么不用红黑树
🍒为什么索引结构默认使用B+树,而不是B-Tree,Hash哈希,二叉树,红黑树?
-
Hash哈希,只适合等值查询,不适合范围查询。
-
一般二叉树,可能会特殊化为一个链表,相当于全表扫描。
-
红黑树,是一种特化的平衡二叉树,MySQL 数据量很大的时候,索引的体积也会很大,内存放不下的而从磁盘读取,树的层次太高的话,读取磁盘的次数就多了。
-
B-Tree,叶子节点和非叶子节点都保存数据,相同的数据量,B+树更矮壮,也是就说,相同的数据量,B+树数据结构,查询磁盘的次数会更少。

6.MySQL主从同步怎么做?
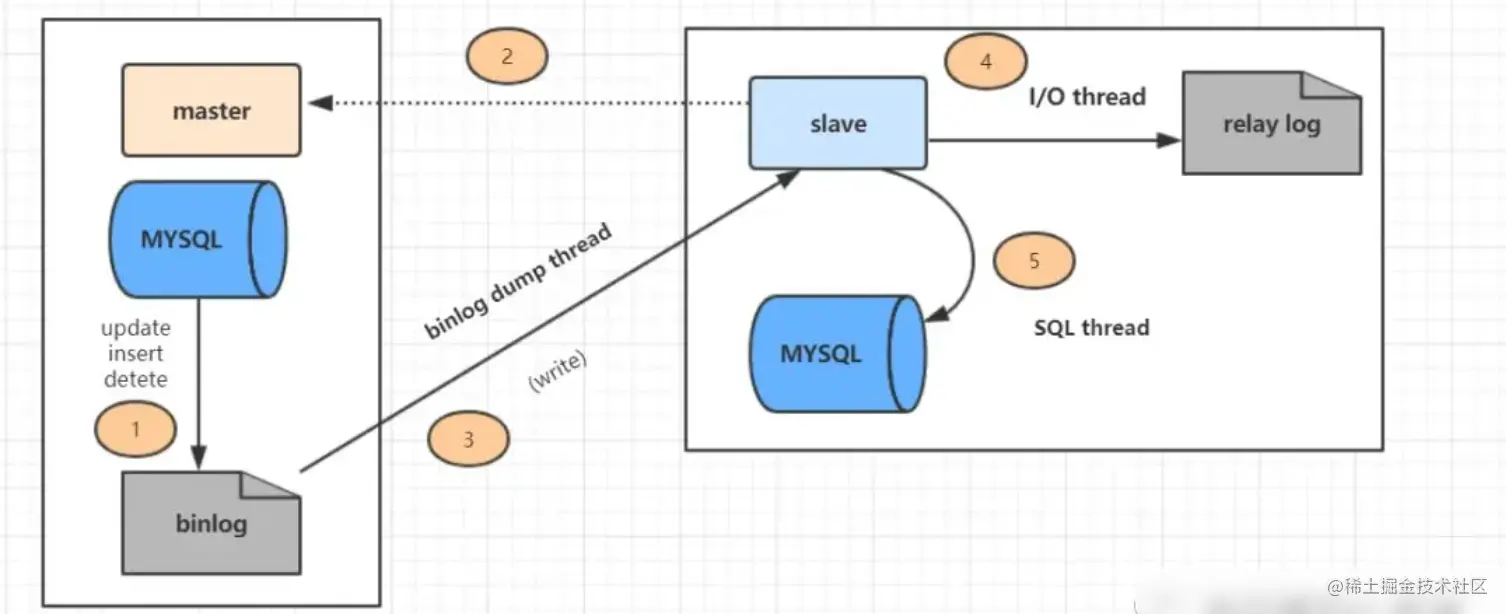
上图主从复制过程分了五个步骤进行:
-
1 主库的更新SQL(update、insert、delete)被写到binlog
-
2 从库发起连接,连接到主库。
-
3 此时主库创建一个
binlog dump thread,把binlog的内容发送到从库。 -
4 从库启动之后,创建一个
I/O线程,读取主库传过来的bin log内容并写入到relay log -
5 从库还会创建一个SQL线程,从
relay log里面读取内容,从ExecMasterLog_Pos位置开始执行读取到的更新事件,将更新内容写入到slave的db
主从同步这块呢,还涉及到如何保证主从一致的、数据库主从延迟的原因与解决方案、数据库的高可用方案。
7.乐观锁和悲观锁的区别?
悲观锁
悲观锁她专一且缺乏安全感了,她的心只属于当前事务,每时每刻都担心着它心爱的数据可能被别的事务修改,所以一个事务拥有(获得)悲观锁后,其他任何事务都不能对数据进行修改啦,只能等待锁被释放才可以执行。
select ...for update就是悲观锁一种实现。
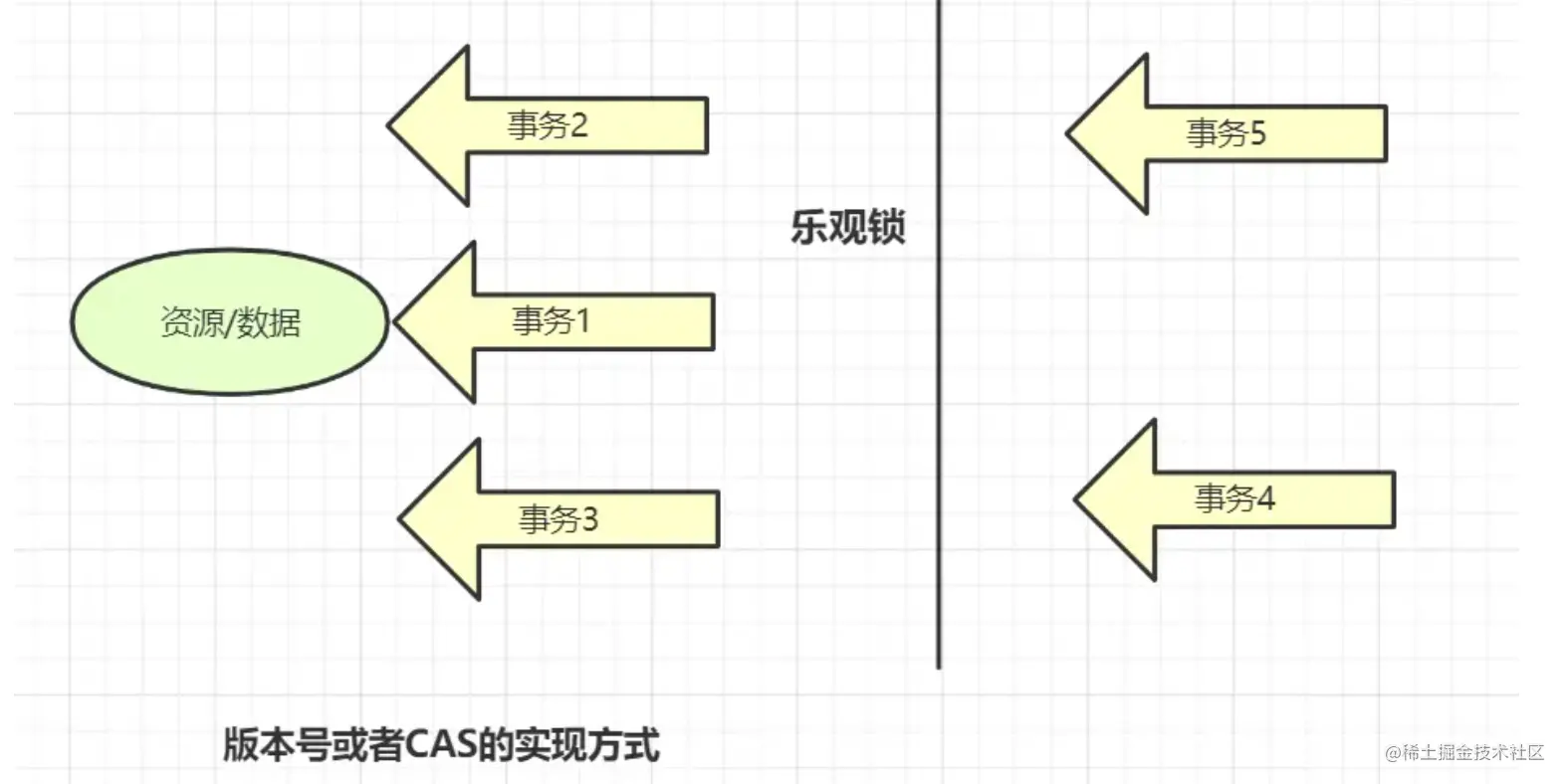
乐观锁
乐观锁的“乐观情绪”体现在,它认为数据的变动不会太频繁。因此,它允许多个事务同时对数据进行变动。
实现方式:乐观锁一般会使用版本号机制或CAS算法实现。
8.聊聊binlog日志
binlog是归档日志,属于MySQL Server层的日志。可以实现主从复制和数据恢复两个作用。
当需要恢复数据时,可以取出某个时间范围内的binlog进行重放恢复即可。
9. Redis 持久化有哪几种方式,怎么选?
既然它是基于内存的,如果Redis服务器挂了,数据就会丢失。为了避免数据丢失了,Redis提供了两种持久化方式,RDB和AOF。
AOF
RDB
如何选择?
- 如果数据不能丢失,RDB和AOF混用
- 如果只作为缓存使用,可以承受几分钟的数据丢失的话,可以只使用RDB。
- 如果只使用AOF,优先使用everysec的写回策略。
10. Redis 主从同步是怎样的过程?

Redis主从同步包括三个阶段。
11. 聊聊Redis的zset,它是怎么实现的?
zset是Redis常用数据类型之一,它的成员是有序排列的,一般用于排行榜类型的业务场景,比如 QQ 音乐排行榜、礼物排行榜等等。12. Redis 过期策略和内存淘汰策略
过期策略
内存淘汰策略
-
volatile-lru:当内存不足以容纳新写入数据时,从设置了过期时间的key中使用LRU(最近最少使用)算法进行淘汰;
-
allkeys-lru:当内存不足以容纳新写入数据时,从所有key中使用LRU(最近最少使用)算法进行淘汰。
-
volatile-lfu:4.0版本新增,当内存不足以容纳新写入数据时,在过期的key中,使用LFU算法进行删除key。
-
allkeys-lfu:4.0版本新增,当内存不足以容纳新写入数据时,从所有key中使用LFU算法进行淘汰;
-
volatile-random:当内存不足以容纳新写入数据时,从设置了过期时间的key中,随机淘汰数据;。
-
allkeys-random:当内存不足以容纳新写入数据时,从所有key中随机淘汰数据。
-
volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的key中,根据过期时间进行淘汰,越早过期的优先被淘汰;
-
noeviction:默认策略,当内存不足以容纳新写入数据时,新写入操作 会报错。

13. Hashmap 是怎样实现的?为什么要用红黑树,而不用平衡二叉树?为什么在1.8中链表大于8时会转红黑树?HashMap是线性安全的嘛?如何保证安全?
怎么实现的?
- JDK1.7 Hashmap 的底层数据结构是 数组+链表
- JDK1.8 Hashmap 的底层数据结构是 数组+链表+红黑树
为什么要用红黑树,为什么不用二叉树?为什么不用平衡二叉树?
红黑树是一种平衡的二叉树,其插入、删除、查找的最坏时间复杂度都为
O(logn),避免了二叉树最坏情况下的O(n)时间复杂度。为什么在1.8中链表大于8时会转红黑树?
红黑树的平均查找长度是log(n),如果长度为8,平均查找长度为log(8)=3,
链表的平均查找长度为n/2,当长度为8时,平均查找长度为8/2=4,
这才有转换成树的必要。
HashMap是线性安全的嘛?如何保证安全?
HashMap不是线程安全的,多线程下扩容死循环。
可以使用
HashTable、Collections.synchronizedMap、以及ConcurrentHashMap实现线程安全。-
HashTable 是在每个方法加上 synchronized 关键字,粒度比较大;
-
Collections.synchronizedMap 是使用 Collections 集合工具的内部类,通过传入 Map 封装出一个 SynchronizedMap 对象,内部定义了一个对象锁,方法内通过对象锁实现;
-
ConcurrentHashMap 在jdk1.7中使用分段锁,在jdk1.8中使用
CAS+synchronized。
14. select 和 epoll的区别
15. http与https的区别,https的原理,如何加密的?
HTTPS= HTTP+SSL/TLS,可以理解Https是身披SSL(Secure Socket Layer,安全套接层)的HTTP。

https的原理,如何加密的
16. Raft算法原理
17.消息中间件如何做到高可用
消息中间件如何保证高可用呢? 单机是没有高可用可言的,高可用都是对集群来说的,一起看下kafka的高可用吧。
Kafka 的基础集群架构,由多个
broker组成,每个broker都是一个节点。当你创建一个topic时,它可以划分为多个partition,而每个partition放一部分数据,分别存在于不同的 broker 上。也就是说,一个 topic 的数据,是分散放在多个机器上的,每个机器就放一部分数据。有些伙伴可能有疑问,每个
partition放一部分数据,如果对应的broker挂了,那这部分数据是不是就丢失了?那还谈什么高可用呢?直接读 leader 上的数据即可。如何保证高可用的?就是假设某个 broker 宕机,这个broker上的partition 在其他机器上都有副本的。如果挂的是leader的broker呢?其他follower会重新选一个leader出来。
18.消息队列怎么保证不丢消息的
一个消息从生产者生产,到被消费者消费,主要经过这3个过程:

因此如何保证MQ不丢失消息,可以从这三个阶段阐述:
- 生产者保证不丢消息
- 存储端不丢消息
- 消费者不丢消息
18.1生产者不丢消息
生产端如何保证不丢消息呢?确保生产的消息能到达存储端。
如果是RocketMQ消息中间件,Producer生产者提供了三种发送消息的方式,分别是:
- 同步发送
- 异步发送
- 单向发送
生产者要想发消息时保证消息不丢失,可以:
- 采用同步方式发送,send消息方法返回成功状态,就表示消息正常到达了存储端Broker。
- 如果send消息异常或者返回非成功状态,可以重试。
- 可以使用事务消息,RocketMQ的事务消息机制就是为了保证零丢失来设计的
18.2存储端不丢消息
如何保证存储端的消息不丢失呢? 确保消息持久化到磁盘。大家很容易想到就是刷盘机制。 刷盘机制分同步刷盘和异步刷盘:
- 生产者消息发过来时,只有持久化到磁盘,RocketMQ的存储端Broker才返回一个成功的ACK响应,这就是同步刷盘。它保证消息不丢失,但是影响了性能。
- 异步刷盘的话,只要消息写入PageCache缓存,就返回一个成功的ACK响应。这样提高了MQ的性能,但是如果这时候机器断电了,就会丢失消息。
Broker一般是集群部署的,有master主节点和slave从节点。消息到Broker存储端,只有主节点和从节点都写入成功,才反馈成功的ack给生产者。这就是同步复制,它保证了消息不丢失,但是降低了系统的吞吐量。与之对应的就是异步复制,只要消息写入主节点成功,就返回成功的ack,它速度快,但是会有性能问题。
18.3消费者不丢消息
消费者执行完业务逻辑,再反馈回Broker说消费成功,这样才可以保证消费阶段不丢消息。
19.Redis如何保证高可用?聊聊Redis的哨兵机制
主从模式中,一旦主节点由于故障不能提供服务,需要人工将从节点晋升为主节点,同时还要通知应用方更新主节点地址。
显然,多数业务场景都不能接受这种故障处理方式。Redis从2.8开始正式提供了
Redis Sentinel(哨兵)架构来解决这个问题。哨兵模式,由一个或多个Sentinel实例组成的Sentinel系统,它可以监视所有的Redis主节点和从节点,并在被监视的主节点进入下线状态时,自动将下线主服务器属下的某个从节点升级为新的主节点。
但是呢,一个哨兵进程对Redis节点进行监控,就可能会出现问题(单点问题),因此,可以使用多个哨兵来进行监控Redis节点,并且各个哨兵之间还会进行监控。
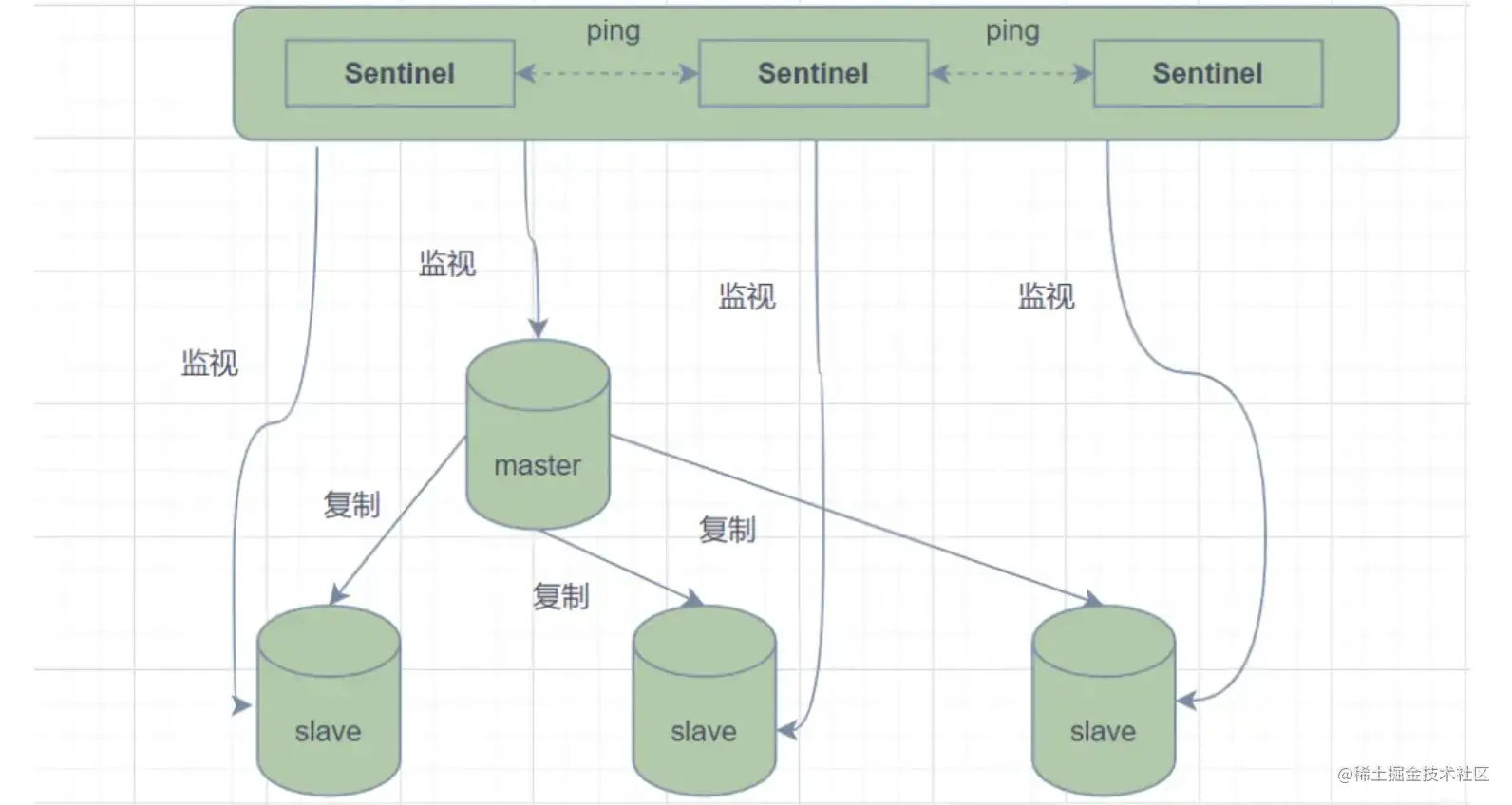
简单来说,哨兵模式就三个作用:
- 发送命令,等待Redis服务器(包括主服务器和从服务器)返回监控其运行状态;
- 哨兵监测到主节点宕机,会自动将从节点切换成主节点,然后通过发布订阅模式通知其他的从节点,修改配置文件,让它们切换主机;
- 哨兵之间还会相互监控,从而达到高可用。
20.无重复字符的最长子串
给定一个字符串 s ,请你找出其中不含有重复字符的 最长子串 的长度。
- 示例 1:
- 输入: s = "abcabcbb"
- 输出: 3
- 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
- 复制代码
- 示例 2:
- 输入: s = "bbbbb"
- 输出: 1
- 解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
这道题可以使用滑动窗口来实现。滑动窗口就是维护一个窗口,不断滑动,然后更新答案。
更多的java课程学习路线,笔记,面试等架构资料,需要的同学可以私信我(面试)即可免费获取!

-
-
相关阅读:
Python tkinter -- 第14章 列表框(Listbox)属性
系统架构设计师之软件概要设计
SpringBoot文件上传下载案例
Java时间复杂度和空间复杂度(详解)
Android 深入理解 Service 的启动和绑定
【flink报错】flink cdc无主键时的操作
servlet 教程 2:返回 jsp 页面
2785. 将字符串中的元音字母排序
CLIFF
LLM App ≈ 数据ETL管线
- 原文地址:https://blog.csdn.net/q66562636/article/details/125470795