-
Java时间复杂度和空间复杂度(详解)
目录
1.复杂度分析
当我们设计一个算法时,怎样衡量其好坏?
算法在编写为可执行程序后,运行时需要耗费时间资源和空间(内存)资源。因此,衡量一个算法的好坏,一般是从时间和空间两个方面来衡量。
2.时间复杂度
一个算法执行所需要的时间,我们可以将代码跑一遍得到具体的时间,但是如果每一个算法都测试一遍的话,十分耗费时间和精力,而且,其测试的结果高度依赖于测试环境,测试环境中的硬件不同会影响测试结果,测试数据的规模也会影响测试结果。
如果我们假设每行代码执行的时间都相同,那么此时影响时间的因素为语句的执行次数,即时间与其语句的执行次数成正比例
时间复杂度:算法中的基本操作的执行次数
- public static int factorial(int N){
- int ret = 1;
- for (int i = 2; i <= N; i++) {
- ret *= i;
- }
- return ret;
- }
上述代码用来求n的阶乘,其中,在for前的代码每行执行了一次,在for循环(i++)及其中的代码(ret *= i)每行执行了N-1次,那么该代码总执行了(1+2*(N-1))次,即(2*N-1)次,代码具体执行了多少次,与传入数据n相关。
当 N = 100 时,代码执行 199 次
当 N = 1000时,代码执行 1999次
当 N = 10000时,代码执行 19999次
……
N越大,常数 -1,系数2对执行次数的影响越小。
因此,我们在计算时间复杂度时,并不需要计算精确的执行次数,只需要计算出其大概执行的次数,我们用大O的渐进表示法来表示
大O的渐进表示法
大O符号(Big O notation):用于描述函数渐进行为的数学符号
推导大O阶方法:
1.用常数1取代运行时间中所有的加法常数
2.在修改后的运行次数函数中,只保留最高阶项
3.如果最高阶项存在且不是1,则去除与这个项目相乘的常数
例如,上述求阶乘的代码中,其执行次数为 2*N-1,用大O的渐进表示法,去掉对结果影响不大的项 -1,最高阶项去除与其相乘的常数,即为O(N)
在算法中,存在不同的执行情况,
例如在长度为N的数组中查找数据x时,可能执行一次就找到,也可能执行n次也找不到
我们将其分为最好、平均和最坏情况
最好情况:任意输入规模的最小运行次数
平均情况:任意输入规模的期望运行次数
最坏情况:任意输入规模的最大运行次数
而我们一般关注的是算法的最坏运行情况
我们通过一些例子来进一步熟悉大O的渐进表示法:
由于我们需要去掉对结果影响不大的项,因此我们可以不再分析对结果影响较小的语句。
例1:
- public static int add(int a, int b){
- int ret = a+b;
- return ret;
- }
上述代码一共执行两次,用常数1取代其中的常数,即为 O(1)
例2:
- int fun(int N,int M){
- int count = 0;
- for (int i = 0; i < N; i++) {
- count++;
- }
- for (int i = 0; i < M; i++) {
- count++;
- }
- return count;
- }
上述代码一共有两个for循环,其中对执行次数影响最大(即执行次数最多)的语句为count++,共共执行了 N+M 次,
当 N 远大于 M时,时间复杂度为 O(N)
当 M 远大于 N时,时间复杂度为 O(M)
当 M 与 N 差不多大时,时间复杂度为 O(M+N)
由于没有说明N与M的大小关系,时间复杂度为 O(N+M)
例3:
- void fun(int N){
- int count = 0;
- for (int i = 0; i < N; i++) {
- for (int j = 0; j < i; j++) {
- count += j;
- }
- }
- }
上述代码中有一个嵌套循环,其中对执行次数影响最大的语句为 count += j,我们对其进行分析
当 i = 0 时,语句执行 0 次,
当 i = 1 时,语句执行 1 次,
当 i = 2 时,语句执行 2 次,
……
当 i = N-1时,语句执行 N-1次
则总执行次数为 0 + 1 + 2 + …… + N-1,利用等差数列求和公式,可得结果为
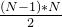 ,最高阶项为
,最高阶项为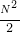 ,去掉系数,时间复杂度为 O(N^2)
,去掉系数,时间复杂度为 O(N^2)例4:
- void fun(int M){
- int count = 0;
- for (int i = 0; i < 10; i++) {
- count++;
- }
- }
时间复杂度为O(1)
注意!count++ 语句一共执行了10次,与M没有关系
例5:
- public static int binarySearch(int[] arr, int x){
- if(arr.length == 0){
- return -1;
- }
- int left = 0;
- int right = arr.length-1;
- while(left <= right){
- int mid = left + ((right-left)>>1);
- if(arr[mid] == x){
- return mid;
- }else if(arr[mid] > x){
- right = mid;
- }else{
- left = mid+1;
- }
- }
- return -1;
- }
上述代码为二分查找,考虑最坏的情况,即查找不到:
我们先分析二分查找是如何查找数据的:
二分查找的前提是被查找的数组arr有序,通过确定中间位置mid,将数组分为两个部分,若被查找值x < arr[mid],则排除右边部分值,在左边继续进行二分查找;若x > arr[mid],则排除左边部分值,在右边继续进行二分查找;若 x = arr[mid],则找到被查找值,返回即可。
过程如下图所示:
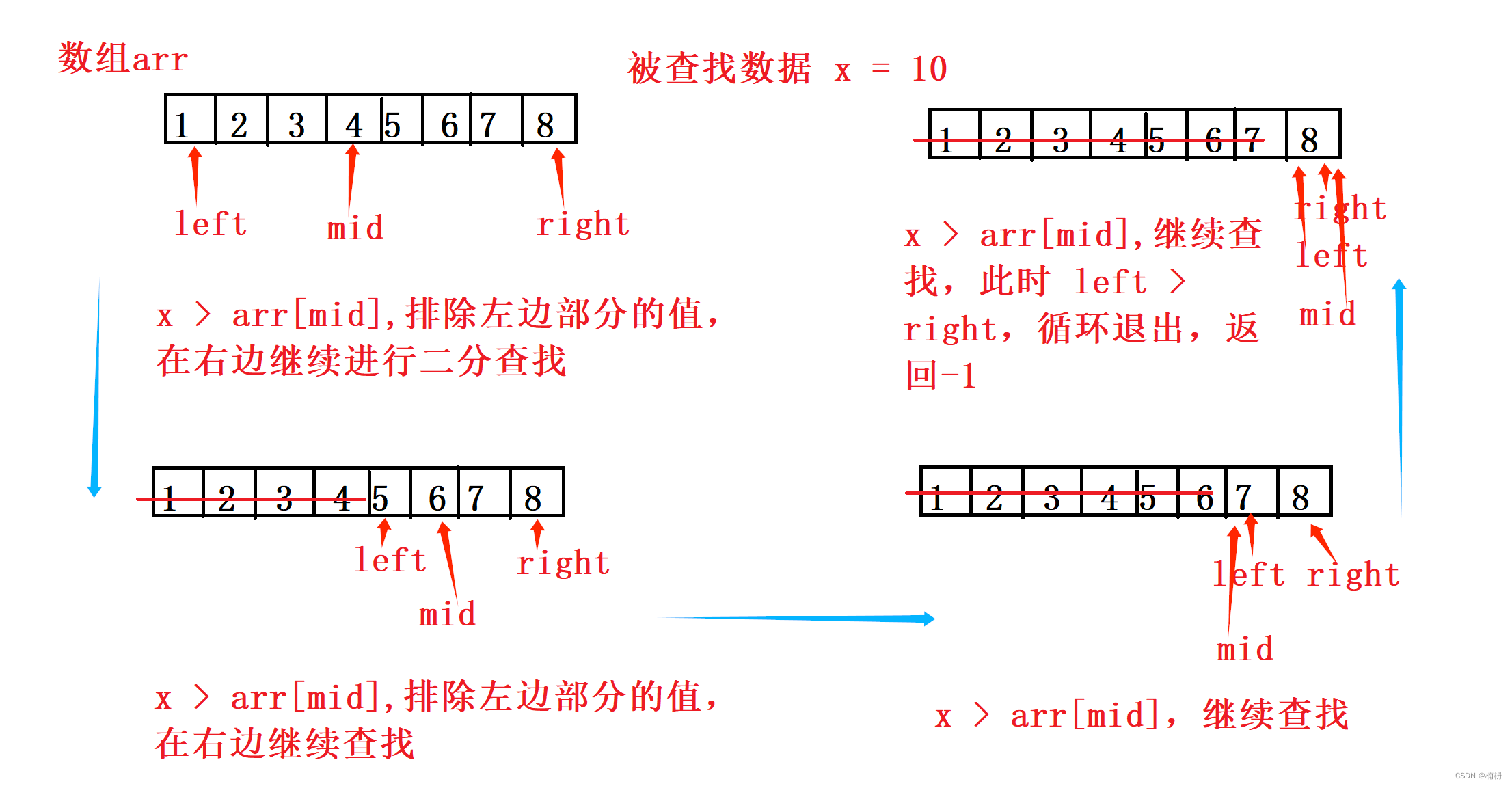
由于一次二分查找会排除数组一半的元素,即
N/2
N/4
N/8
……
1 当结果为1时循环结束
因此 1*2*2*……*2 = N,即 2^x = N,则执行次数x =
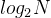 ,
,时间复杂度为
例6:
- long factorial(int N){
- return N < 2? N: factorial(N-1)*N;
- }
上述递归的结束条件为 N < 2,当N >= 2时,会一直递归下去:
N
N-1
N-2
……
2
1 此时递归结束
递归的次数为N,因此时间复杂度为O(N)
例7:
- int fibonacci(int N){
- return N < 2? N: fibonacci(N-1)+ fibonacci(N-2);
- }
斐波那契递归,可将其看成一个二叉树,将其递归时开辟的栈帧看作一个节点,每一个节点就是一次函数调用,则递归的时间复杂度为二叉树结点个数,具体递归过程为:
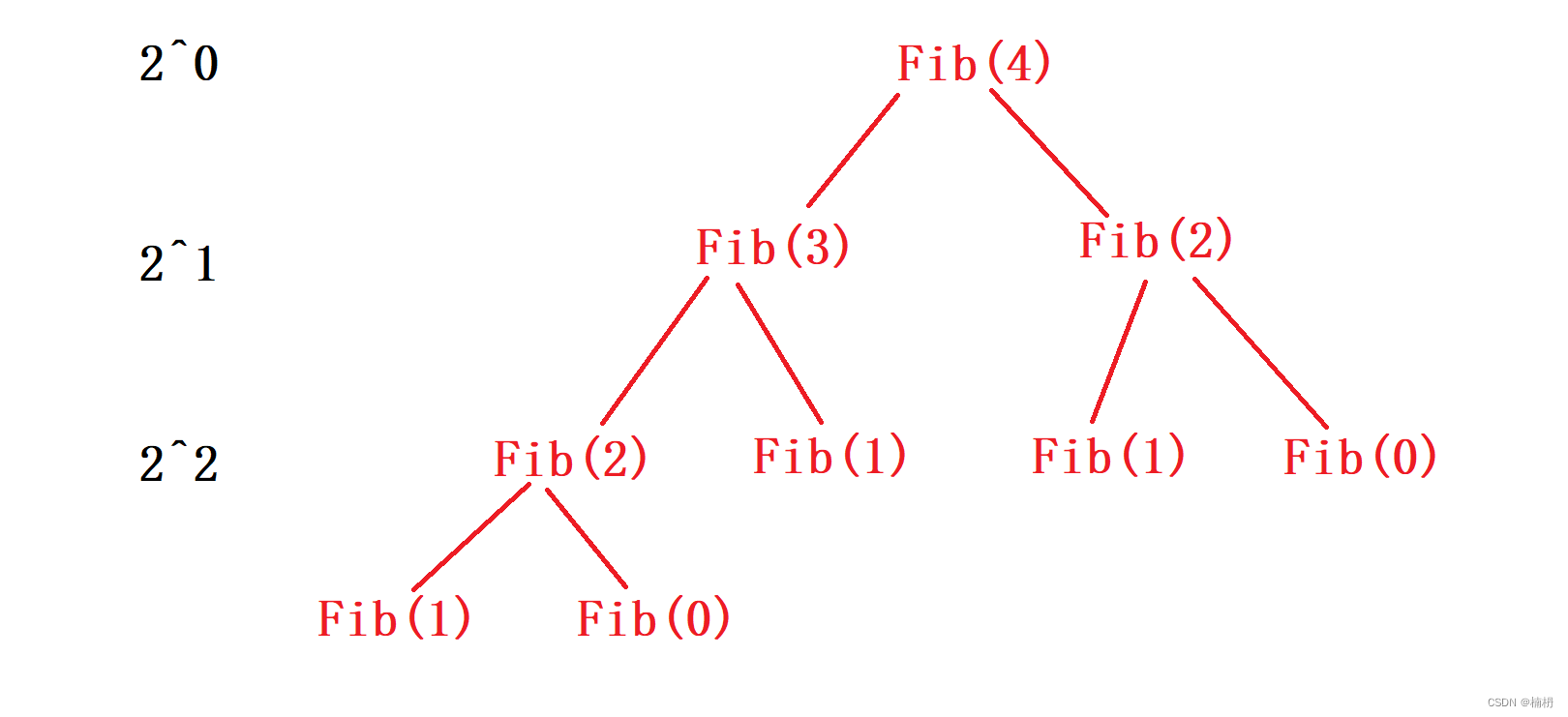
其中最后一层可能不满,由于计算时间复杂度只需要计算出其大概执行的次数,最后一层的空缺对计算的影响可以忽略不计
则递归的次数为Fib(N) = 2^0 + 2^1 + ……+ 2^(N-1)
利用等比数列求和公式,可得2^n - 1,则时间复杂度为O(2^N)
3.空间复杂度
空间复杂度是对一共算法在运行过程中临时占用存储空间大小的量度。空间复杂度计算的是变量的个数,其计算规则基本与时间复杂度类似,也使用大O的渐进表示法
例1:
- void fun(int N){
- int count = 0;
- for (int i = 0; i < N; i++) {
- for (int j = 0; j < i; j++) {
- count += j;
- }
- }
- }
其中开辟了常数个额外的变量(count、i、j),因此空间复杂度为O(1)
例2:
- int[] fun(int N){
- int[] arr = new int[N];
- for (int i = 0; i < N; i++) {
- arr[i] = i;
- }
- return arr;
- }
开辟了一共大小为N的整形数组和常数个额外的变量,因此空间复杂度为O(N)
例3:
- long factorial(int N){
- return N < 2? N: factorial(N-1)*N;
- }
上述代码递归调用了N次,开辟了N个栈帧,每个栈帧使用了常数个空间,因此空间复杂度为O(N)
-
相关阅读:
12-JavaSE基础巩固练习:字符串练习
CAD Exchanger SDK for Win and Linux Crack
恒生电子:护航金融行业自主创新
PostgreSQL - tutorial
在Go中如何正确重试请求
胡编乱造的自我介绍
Python 全栈系列200 Redis Agent
【计算机】CPU,芯片以及操作系统概述
SQL语句,存储过程,触发器
[第一篇]——跟我学习Docker 教程
- 原文地址:https://blog.csdn.net/2301_76161469/article/details/132646916
