-
Prometheus集成springboot(六)
添加altermanager报警
Alertmanager处理从客户端发来的警报,客户端通常是Prometheus服务器如图6-1所示。它还可以接收来自其他工具的警报,但此处不做说明。Alertmanager对警报进行去重、分组,然后路由到不同的接收器,如电子邮件、短信或SaaS服务(PagerDuty等)。你还可以使用Alertmanager管理维护。

我们将在Prometheus服务器上编写警报规则(https://prometheus.io/docs/prometheus/latest/configuration/alerting_rules/),这些规则将使用我们收集的指标并在指定的阈值或标准上触发警报。我们还将看到如何为警报添加一些上下文。当指标达到阈值或标准时,会生成一个警报并将其推送到Alertmanager。警报在Alertmanager上的HTTP端点上接收。一个或多个Prometheus服务器可以将警报定向到单个Alertmanager,或者你可以创建一个高可用的Alertmanage,收到警报后,Alertmanager会处理警报并根据其标签进行路由。一旦路径确定,它们将由Alertmanager发送到外部目的地,如电子邮件、短信或聊天工具altermanager安装
wget https://github.com/prometheus/alertmanager/releases/download/v0.24.0/alertmanager-0.24.0.linux-amd64.tar.gz tar -zxf alertmanager-0.24.0.linux-amd64.tar.gz- 1
- 2
可用通过 查看版本来检测是否安装成功
[root@iZuf6bm702o3rrjlhq9xt5Z altermanager]# ./alertmanager --version alertmanager, version 0.24.0 (branch: HEAD, revision: f484b17fa3c583ed1b2c8bbcec20ba1db2aa5f11) build user: root@265f14f5c6fc build date: 20220325-09:31:33 go version: go1.17.8 platform: linux/amd64 [root@iZuf6bm702o3rrjlhq9xt5Z altermana- 1
- 2
- 3
- 4
- 5
- 6
- 7
如上所示已经安装成功
启动altermamangernohup ./alertmanager --config.file=alertmanager.yml &- 1
alert默认端口是9093,如下图所示
alert的配置
Alertmanager处理由 Prometheus 服务器等客户端应用程序发送的警报。它负责对它们进行重复数据删除、分组并将它们路由到正确的接收器集成,例如电子邮件、PagerDuty 或 OpsGenie。它还负责警报的静音和抑制。
下面介绍 Alertmanager 实现的核心概念。请查阅配置文档以了解如何更详细地使用它们。
route: group_by: ['alertname'] group_wait: 30s group_interval: 5m repeat_interval: 1h receiver: 'web.hook' receivers: - name: 'web.hook' webhook_configs: - url: 'http://127.0.0.1:5001/' inhibit_rules: - source_match: severity: 'critical' target_match: severity: 'warning' equal: ['alertname', 'dev', 'instance']- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
Grouping
分组将类似性质的警报分类为单个通知。当许多系统同时发生故障并且可能同时触发数百到数千个警报时,这在较大的中断期间特别有用。示例:发生网络分区时,集群中正在运行数十或数百个服务实例。您的一半服务实例无法再访问数据库。Prometheus 中的警报规则配置为在每个服务实例无法与数据库通信时发送警报。因此,数百个警报被发送到 Alertmanager。
作为用户,您只想获得一个页面,同时仍然能够准确查看哪些服务实例受到了影响。因此,可以将 Alertmanager 配置为按其集群和警报名称对警报进行分组,以便发送单个紧凑通知。
警报的分组、分组通知的时间以及这些通知的接收者由配置文件中的路由树配置。
Inhibition
抑制是在某些其他警报已经触发时抑制某些警报通知的概念。示例:正在触发通知整个集群不可访问的警报。如果该特定警报正在触发,Alertmanager 可以配置为静音有关此集群的所有其他警报。这可以防止通知与实际问题无关的数百或数千个触发警报。
Inhibition是通过 Alertmanager 的配置文件配置的。
Silences
Silences是在给定时间内简单地将警报静音的简单方法。静音是基于匹配器配置的,就像路由树一样。检查传入警报是否匹配活动静音的所有相等或正则表达式匹配器。如果他们这样做,则不会针对该警报发送任何通知。静音在 Alertmanager 的 Web 界面中配置。
Client behavior
Alertmanager 对其客户的行为有特殊要求。这些仅与 Prometheus 不用于发送警报的高级用例相关。高可用性
Alertmanager 支持配置以创建集群以实现高可用性。这可以使用–cluster-*标志进行配置。重要的是不要在 Prometheus 和它的 Alertmanagers 之间对流量进行负载平衡,而是将 Prometheus 指向所有 Alertmanagers 的列表。
prometheus配置altermanager
alter安装好了我们现在要作的是配置prometheus,
# Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: - alertmanager:9093 # Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: - "rules/*_rules.yml" - "rules/*_alerts.yml"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
alerting块包含允许Prometheus识别一个或多个Alertmanager的配置。为此,Prometheus使用与查找抓取目标时相同的发现机制,在默认配置中是static_configs。与监控作业一样,它指定目标列表,此处是主机名alertmanager加端口9093(Alertmanager默认端口)的形式。该列表假定你的Prometheus服务器可以解析alertmanager主机名为IP地址,并且Alertmanager在该主机的端口9093上运行。提示 你还可以在Prometheus Web界面上的状态页面http://localhost:9090/status中查看任何已配置的Alertmanager。
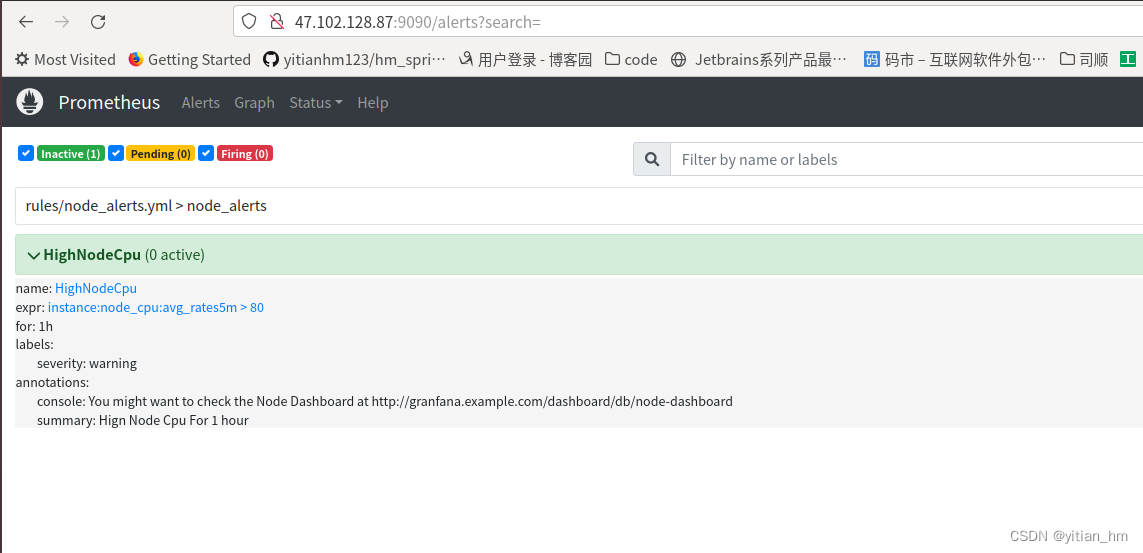
可以发现当配置好了报警的规则,重新启动之后会发现这边已经有了报警规则,在alter的菜单里,具体如上图所示
笔者在prometheus下面创建了rules文件夹存放rule规则,同时创建了两个文件如图所示,下面node_alerts文件配置如下groups: - name: node_alerts rules: - alert: HighNodeCpu expr: instance:node_cpu:avg_rates5m >80 for: 60m labels: severity: warning annotations: summary: Hign Node Cpu For 1 hour console: You might want to check the Node Dashboard at http://granfana.example.com/dashboard/db/node-dashboard- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
告警规则::一个CPU警报规则。我们将创建一个警报,如果我们创建的CPU查询(5分钟内的节点平均CPU使用率)在至少60分钟内超过80%,则会触发警报。
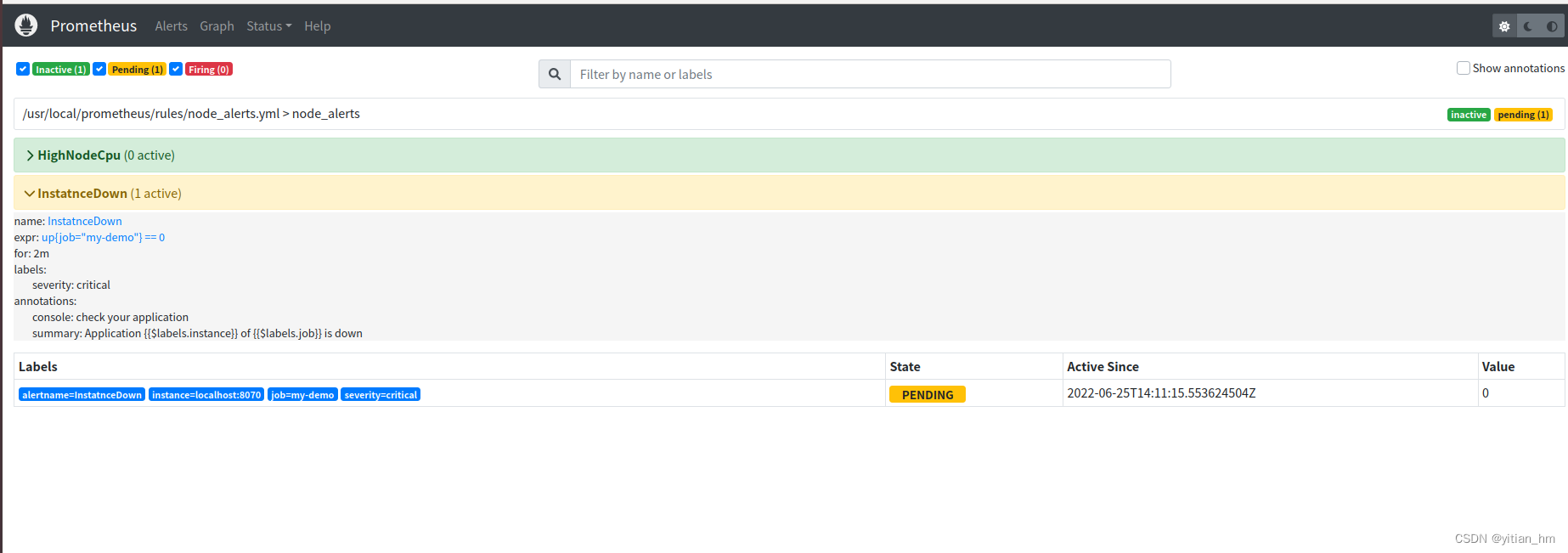
笔者这边为了测试方便有加了一条规则,如果应用挂了,持续2分钟就触发报警
-
相关阅读:
Day08--自定义组件的数据监听器案例
【OpenCV-Python】教程:3-8 图像金字塔
RTT学习笔记12-串口外设和串口驱动框架
yolov7增加mobileone
windows安装mysql时卡write configuration file曲线救国 mysql 5.7.39 免安装(ZIP压缩包)版本安装配置
数据结构--选择排序
Handler机制实现原理总结
东盟与中日韩(10+3)中小企业人工智能产业论坛
muduo源码剖析之Socket类
windows 常用快捷键
- 原文地址:https://blog.csdn.net/yitian881112/article/details/125453209