-
基于HTML5+JavaScript实现的网页录屏器设计
资源下载地址:https://download.csdn.net/download/sheziqiong/85773105
资源下载地址:https://download.csdn.net/download/sheziqiong/85773105基于HTML5实现的录屏器
1.项目简介
如果你爱打游戏,一定打过魔兽争霸3(暴露年纪),你也许会游戏导出的录像文件感到好奇,明明打了一个小时游戏,为什么录像才几百KB而已。不过很快你又发现另一个问题,在每次导入录像的时候需要重新加载一次地图,否则就不能播放。
录像记录的数据不是一个视频文件,而是带着时间戳的一系列动作,导入地图的时候,实际相当于初始了一个状态,在这个状态的基础上,只需要对之前的动作进行还原,也就还原了之前的游戏过程,这就是repl的基本原理了
但是这样有什么好处呢?
首先是对于一个录像,这样的方式极大程度的减小了体积,假设我们需要录一个小时的1080p24f视频,在视频未压缩的情况下
总帧数 = 3600s * 24 = 86400frame 假设每个逻辑像素用RGB三基色表示,每个基色8bits(256色) 帧大小 = (1920 * 1080)pixels * 8bits * 3 = 49766400bits 换算成KB是 49766400bits / 8 / 1024 = 6075KB 总视频体积 = 6075KB * 86400 = 524880000KB ≈ 500GB- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
所以对比传统的视频录像方法,假设录像是500KB,那么理论上体积上缩小了大约 524880000KB / 500KB ≈ 1000000倍
Web录屏器其实也借鉴这样的一种思路,工程上一般称之为Operations Log, 本质上他的实现也是通过记录一系列的浏览器事件数据,利用浏览器引擎重新渲染,还原了之前的操作过程,也就达到了“录屏器”的效果
从实际来看,即使对比采用H.265压缩比达到几百倍的压缩视频,体积上至少也能节省200倍以上
对比传统的视频流,它的优势也是显而易见的
1. 极大程度减小录像文件体积 2. 极低的CPU与内存占用比率 3. 无损显示,可以进行无极缩放,窗口自适应等 4. 非常灵活的时间跳转,几乎无法感知的缓冲时间 5. 所有信息都是活的,文本图片可以复制,链接可以点击,鼠标可以滚动 6. 可以方便的录制声音,并让声音和画面同步,还以类似YouTube那样把声音翻译成字幕 7. 方便进行视频细节的修改,例如显示的内容进行脱敏,生成热力图等 8. 记录的序列化数据,十分利于知乎进行数据分析 ...- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
那么问题来了:为什么要对网页录像?有哪些应用场景?
我能想到的主要有以下几个方面
- 异常监控系统,例如LogRocket,可以理解他是一个整合了Sentry + 录屏器的工具,能回放网页错误时的图形界面与数据日志,从而帮助Debug
- 记录用户的行为进行分析,例如MouseFlow。甚至还可以是直播的方式LiveSession,“连接”到用户的浏览中,看看用户是怎么使用网站的
- 对客服人员的监控,例如阿里的有十万级别的客服小二人员分散在全国各地,需要对他们的服务过程进行7x24小时的录屏,在这个数量级上的对监控的性能要求就非常高了,阿里内部的工具叫
XReplay - 协同工具,例如协同文档和协同编辑器等,会涉及类似的技术
…
2.Web录屏器的技术细节
对DOM进行快照
通过DOM的API可以很轻易的拿到页面的节点数据,但是对于我们的需求而言,显而DOM Node提供的数据太冗余了,这一步通过参考VirtualDom的设计,把信息精简一下
interface VNode{ id: number tag: string attrs: { [key: string]: string } children: (VNode | string )[] }- 1
- 2
- 3
- 4
- 5
- 6
对DOM进行深度遍历后,DOM被映射成了VNode类型节点,需要记录的 Node 主要是三种类型
ELEMENT_NODE,COMMENT_NODE和TEXT_NODE,之后在播放时,只需要对VNode进行解析,就可以还原成记录时的状态了在这过程中,有一些节点和属性需要特殊处理,例如
InputElement等类型的Value是从DOM无法获取的,需要从节点中对象中获取script标签的内容由于之后不会去执行,所以可以直接skip或者标记为noscriptSVG可以直接获取,但是它本身以及它的子元素重新转换为DOM的时候需要使用createElementNS("http://www.w3.org/2000/svg", tagName)的方法创建元素src或href属性如果是相对路径,需要把他们转换为绝对路径
…
2.1记录影响页面元素变化的Action
DOM的变化可以使用
MutationObserver, 监听到attributes,characterData,childList三种类型的变化const observer = new MutationObserver((mutationRecords, observer) => { // Record the data }) observer.observe(target, options)- 1
- 2
- 3
- 4
再借助
WindowEventHandlersaddEventListener等的能力组合,就可以监听到页面一系列的操作事件了- Add Node Action - Delete Node Action - Change Attribute Action - Scroll Action - Change Location Action ...- 1
- 2
- 3
- 4
- 5
- 6
通过
mouseMove和click事件记录鼠标动作对于
mouseMove事件,在移动的过程中会频繁的触发,产生很容冗余的数据,这样的数据会浪费很多的空间,因此对于鼠标的轨迹,我们只采集少量的关键点,最简单的办法是使用节流来减小事件产生的数据量,但是也有一些缺点:
1. 截流的间隔中可能会丢失关键的鼠标坐标数据
2. 即时通过截流在移动距离足够长的时候任然会产生巨大的数据量,更好的办法是通过Spline Curves(样条曲线)函数来计算得出移动轨迹、抖动、加速度等生成一条路径曲线用来控制鼠标的移动Input的变换我们可以通过
Node.addEventListener的inputblurfocus事件监听,不过这只能监听到用户的行为,如果是通过JavaScript对标签进行赋值,我们是监听不到数据的变化的,这时我们可以通过Object.defineProperty来对一些表单对象的特殊属性进行劫持,在不影响目标赋值的情况下,把value新值转发到自定的handle上,统一处理状态变化const elementList: [HTMLElement, string][] = [ [HTMLInputElement.prototype, 'value'], [HTMLInputElement.prototype, 'checked'], [HTMLSelectElement.prototype, 'value'], [HTMLTextAreaElement.prototype, 'value'] ] elementList.forEach(item => { const [target, key] = item const original = Object.getOwnPropertyDescriptor(target, key) Object.defineProperty(target, key, { set: function(value: string | boolean) { setTimeout(() => { handleEvent.call(this, key, value) }) if (original && original.set) { original.set.call(this, value) } } }) })- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
2.2通过样条曲线模拟鼠标轨迹
用户在网页中移动鼠标会产生很多
mouseMove事件,通过const {x,y} = event.target获取到了轨迹的坐标与时间戳假如我在页面上用鼠标划过一个的轨迹,可能会得到下图这样的坐标点
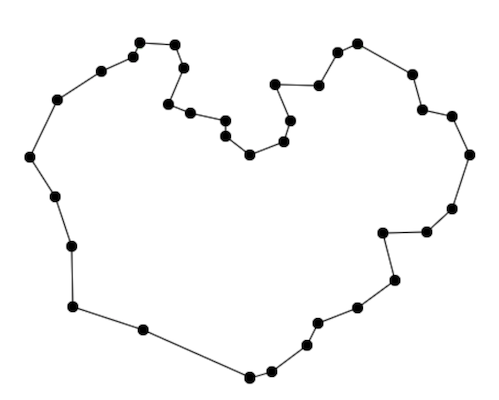
但是对于录屏这个业务场景来说,大部分场合我们并不要求100%还原精确的鼠标轨迹,我门只会关心两种情况:
1. 鼠标在哪里点击? 2. 鼠标在哪里停留?- 1
- 2
那么通过这个两个策略对鼠标轨迹进行精简后,画一个大约只需要6个点,通过样条曲线来模拟鼠标的虚拟轨迹,当 t = 0.2 的时候,就可以得到一个下图这样带着弧度的轨迹了
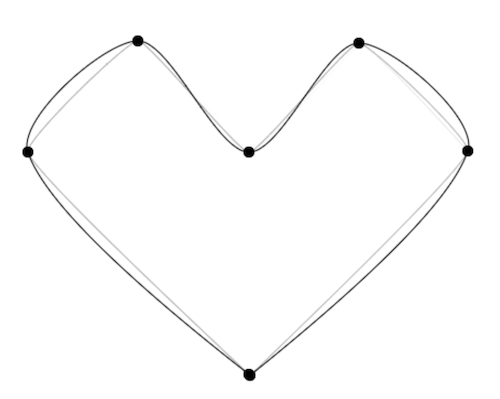
通过规则筛选出关键点后,利用B样条曲线计算函数,按照最小间隔进行取样并插入我们的鼠标路径队执行列里,当渲染时重绘鼠标位置的时候,就可以得到一个近似曲线的鼠标轨迹了
2.3通过鼠标数据生成热力图
之前已经通过鼠标事件记录了完整的坐标信息,通过heatmap.js可以很方便的生成热力图,用于对用户的行为数据进行分析。
这里需要注意的地方是当页面切换的时候我们需要重置热力图,如果是单页应用,通过
History的popstate与hashchange可以监听页面的变化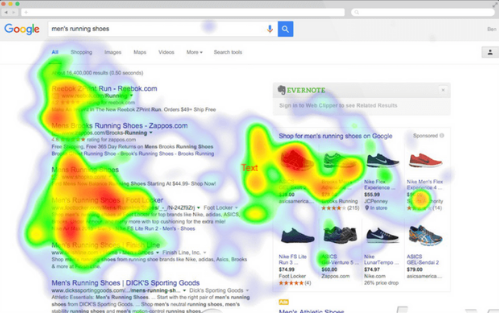
2.4对于用户隐私的脱敏
对于一些客户个人隐私数据,通过在开发时DOM进行标注的
Node.COMMENT_NODE(例如:<!-- ... -->)信息申明,我们是可以获取并加工的。通过约定好的声明对需要脱敏的DOM块进行处理,在渲染的时候通过CSS打上马赛克或模糊处理即可2.5沙箱化提升安全
录制的内容有可能属于第三方提供,这意味着可能存在一定的风险,网站中可能有一些恶意的脚本并没有被我们完全过滤掉,例如:
<div onload="alert('something'); script..."></div>,或者我们的播放器中的一些事件也可能对播放内容产生影响,这时候我们需要一个沙盒来隔离播放内容的环境,HTML5 提供的 iframe sandbox是不错的选择,这可以帮助我们轻易的隔离环境:- script脚本不能执行 - 不能发送ajax请求 - 不能使用本地存储,即localStorage,cookie等 - 不能创建新的弹窗和window, 比如window.open or target="_blank" - 不能发送表单 - 不能加载额外插件比如flash等 - 不能执行自动播放的tricky. 比如: autofocused, autoplay- 1
- 2
- 3
- 4
- 5
- 6
- 7
2.6基于视频GOP(I/B/P帧)算法的压缩技术
// TODO
2.7播放、跳转与快进
播放:播放器会内置一个精确的计时器,动作的数据存储在一个栈中,栈中的每一个对象就是一帧,通过RAF(requestAnimationFrame) 对数据帧的时间戳进行扫描从而得知下一帧在什么时间发生
暂停:通过cancelAnimationFrame暂停计时器
快进:加速采集速率的倍速
跳转:跳转相当于一个最快速的快进功能,但是如果跳转的距离太远,性能会非常差,这时需要按一定的距离对播放轴插入预先的snapshot,再从最近的snapshot进行跳转
2.8在客户端进行的Gzip压缩
Gzip一般是在网络应用层里对传输数据进行压缩,但是我们的数据不一定只存在数据库里,可能会有三种储存方式
- 服务器存储 TCP => DB
- 本地储存 localStorage、indexDB、web SQL
- 保存为本地文件,例如直接导出可运行的HTML文件
利用客户端的运算能力,在进行导出或者传输之前,可以对数据进行压缩,极大程度的减小体积
在客户端可以进行基于
Gzip的数据包压缩,Gzip是基于哈夫曼二叉树的2.9数据上传
对于客户端的数据,可以利用浏览器提供的IndexDB进行存储,毕竟IndexDB会比LocalStorage容量大得多,一般来说不少于 250MB,甚至没有上限,此外它使用object store存储,而且支持transaction,另外很重要的一点它是异步的,意味着不会阻塞录屏器的运行
之后数据可以通过WebSocket或其他方式持续上传到OSS服务器中,由于数据是分块进行传输的,在同步之后还可以增加数据校验码来保证一致性避免错误。资源下载地址:https://download.csdn.net/download/sheziqiong/85773105
资源下载地址:https://download.csdn.net/download/sheziqiong/85773105 -
相关阅读:
VSCode remote无法链接
01背包和完全背包区别
.NET性能优化-使用ValueStringBuilder拼接字符串
2024-2-22 学习笔记(Yolo-World, Yolov8-OBB,小样本分类,CNN/Transfomer选择)
论文写作--30条总结
y131.第七章 服务网格与治理-Istio从入门到精通 -- Istio Security基础(十七)
11.20二叉树基础题型
【JavaScript】-----初始JavaScript
A_A02_001 CH340驱动安装
java毕业设计房产销售平台Mybatis+系统+数据库+调试部署
- 原文地址:https://blog.csdn.net/sheziqiong/article/details/125460033