-
Java面试-轻松搞定Java面试集合相关题目
集合是Java面试必考的高频知识点,虽然大家平时多少都会在用,但是对这个体系和底层实现很少有较全面的认知。
本文参考了《极客时间-Java核心技术36讲》和《牛客网-Java开发岗高频面试题全解析》,在较为系统的复习之后总结于此。希望对同样的正在准备找工作的同学有所帮助
快速到达看这里–>
- 关于Java中的集合类,你知道多少呢?
-
- Java中常见的集合类有哪些呢?
- 常见考题
关于Java中的集合类,你知道多少呢?
首先,放上一张整体分类图,从图中可以看出,Java的集合类起源于两个接口,一个是
Map,另一个是Collection。平时我们所能接触到的包括HashMap,ArrayList,HashSet等都直接或间接的实现了这两个接口中的一个。而Collection接口的分支包括了List接口和Set接口。这样一来,我们常见的Map,List和Set就都包含到了。
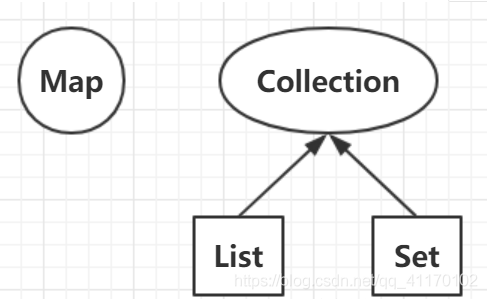
说到集合肯定大家都知道Collection接口,但是不一定知道Map接口是和Collection接口平级的,所以Map接口不是Collection接口的子接口。Java中常见的集合类有哪些呢?
下面我们就以
Map、Set、List作为三个分支来进行讲解Map接口的实现类主要有:HashMap、TreeMap、LinkedHashMap、Hashtable、ConcurentHashMap和Properties等Set接口的实现类主要有:HashSet、TreeSet、LinkedHashSet等List接口的实现类主要有:ArrayList、LinkedList、Stack、Vector等
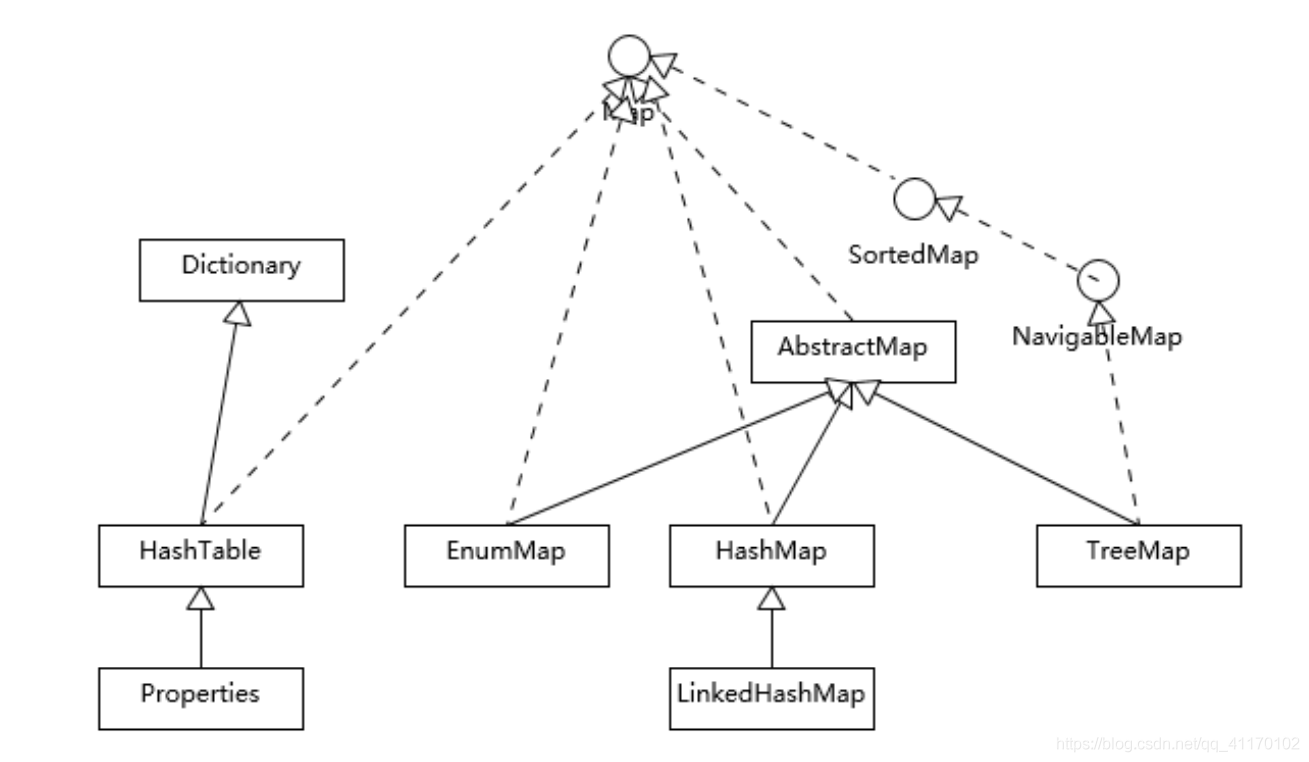
为了能更清楚的了解下他们之间的关系,我找了两张结构的图也放到这里
Collection接口及其分支的结构

Map接口及其分支的结构
常见考题
同一类下的各个实现类不但名字有点相似,功能也都大体一致,所以同一类型的实现类之间的比较就是面试的热点,下面,我们就把常用的分成几组进行比较吧
Hashtable、HashMap、TreeMap 有什么不同?(三个最相似)
1. Key值和Value值是否能为空
Hashtable的Key和Value均不能为nullHashMap的Key和Value允许为空,允许有一个null的Key和多个null的ValueTreeMap的Value允许为空
未实现Comparator接口时,key 不可以为null
实现Comparator接口时,若未对 null 情况进行判断,不能为空;若针对null实现了,可以为空,但是不能通过get()方法获取,只能遍历获得值。
2. 是否有序
Hashtable和HashMap是无序的TreeMap是有序的,TreeMap由红黑树实现,默认是升序排列,可自定义实现Comparator接口实现排序方式
3. 初始化和增长方式
Hashtable初始化默认容量为11,且不要求底层数组容量为2的整数次幂。
扩容时容量变为原来的2倍加1HashMap初始化默认容量为16,要求容量一定为2的整数次幂
扩容时容量变为原来的2倍TreeMap底层实现是红黑树,就不需要初始化默认大小和扩容了
4. 线程安全性
Hashtable的方法函数全部都是同步的(synchronized实现),保证了线程安全性。当多线程访问Hashtable时,效率极低,所以Hashtable现在已经不推荐使用了HashMap和TreeMap不支持线程同步,所以是线程不安全的
举例说明HashMap是线程不安全的
HashMap线程不安全主要是考虑到了多线程环境下进行扩容可能会出现HashMap死循环Hashtable的线程安全是由于内部实现put和remove操作时使用synchronized进行了同步,所以单个方法线程安全。而HashMap并没有,所以当一个线程执行remove操作时另一个线程执行get操作就可能出现越界现象
LinkedHashMap和TreeMap的区别(两个有序)
LinkedHashMap基于HashMap和双向链表实现,TreeMap基于红黑树实现TreeMap的有序是指基于Key进行内部排序LinkedHashMap的有序分为插入顺序和访问顺序,默认插入顺序
插入顺序:插入时是什么顺序,读取就是什么顺序
访问顺序:访问了之后,访问的元素就放到最后面
ConcurrentHashMap和Hashtable的区别?(两个线程安全)
Hashtable通过synchronized锁住整个结构实现线程同步,效率低ConcurrentHashMap采用分段锁实现线程同步,效率明显提高
关于ConcurrentHashMap你知道多少?
ConcurrentHashMap是面试的重点,篇幅较大,所以单独成篇
关于HashMap你了解多少?
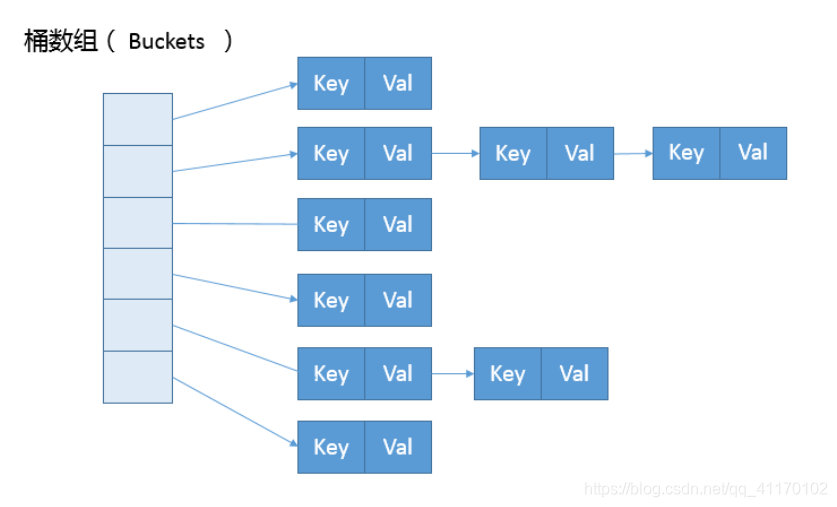
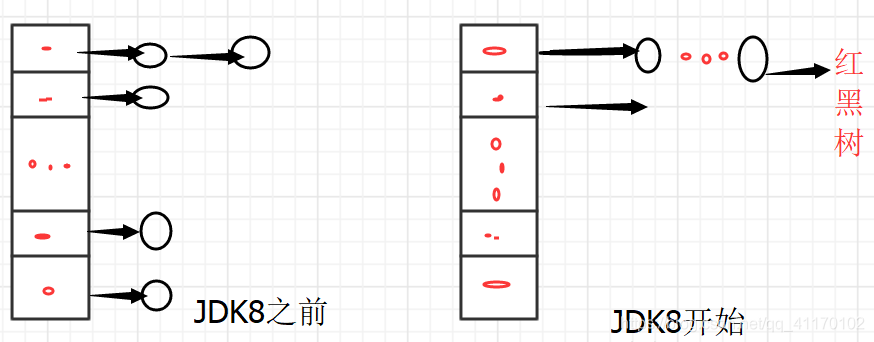
HashMap的底层实现结构是什么?
- JDK8之前,
HashMap的底层实现数据结构为数组+链表形式 - JDK8及之后,
HashMap的底层实现采用数组+链表+红黑树的形式,有效的解决了链表太长导致的查询速度变慢问题
HashMap 的初始容量,加载因子,扩容增量是多少?
HashMap的初始容量是16HashMap的加载因子是0.75HashMap的扩容增量是1倍
为什么初始容量是16而不是15:
因为Java要求的是2的整数幂值
加载因子0.75表达什么含义:
表示当存储容量超过当前容量的0.75倍事触发扩容,如第一次扩容当超过16*0.75=12之后,就开始扩容
为什么加载因子是0.75而不是0.5或1:
这其实是出于容量和性能之间平衡的结果:
- 当加载因子设置比较大的时候,扩容的门槛就被提高了,扩容发生的频率比较低,占用的空间会比较小,但此时发生Hash冲突的几率就会提升,因此需要更复杂的数据结构进行存储,这样对元素的操作时间就会增加,运行效率也会因此降低
- 而当加载因子值比较小的时候,扩容的门槛会比较低,因此会占用更多的空间,此时元素的存储就比较稀疏,发生哈希冲突的可能性就比较小,因此操作性能会比较高
所以综合了以上情况就取了一个 0.5 到 1.0 的平均数 0.75 作为加载因子
扩容增量1倍表达什么含义:
指每次扩容的容量是原来容量的一倍,即容量每次翻倍
HashMap的链表什么时候变为红黑树
- 当一个链表的长度达到8时,会先判断总容量是否小于64,如果小于64只进行扩容;如果大于64将链表转为红黑树
- 当红黑树的节点个数达到6时,退化为链表
HashMap的长度为什么是2的整数幂值?
2的N次幂有助于减少碰撞的几率,空间利用率大
对上面这句话做一个解释:
- 我们将一个键值对插入
HashMap中,通过key的hash值与length-1进行&运算,实现了key定位。 - 当
length为2的N次幂时,length-1的二进制为111…(全1)的形式,在于hash值进行&操作时会很快,而且没有空间浪费 - 当
length不是2的N次幂时,如length=15,那么length-1=14,二进制值为1110,进行&操作时,0001、0011、0101、0111、1011、1001、1101这几个位置就不能存放值,空间浪费巨大!!!
HashMap的存储和获取原理
- 当调用
put()方法传递键值对进行存储时,先对键调用hashCode()的方法,返回bucket的位置存储实体对象,当bucket位置发生冲突,也就是发生hash冲突时,会在每个bucket后面接上一个链表(JDK8及之后的版本如果冲突数超过MIN_TREEIFY_CAPACITY会使用红黑树)来解决,将新存储的键值对放在表头(bucket)中 - 当调用
get()方法时,首先根据hashCode()获取到bucket的值,然后再通过equals方法在链表或者红黑树中查找
HashMap进行添加的流程如图:

HashMap扩容的步骤
HashMap里面默认的负载因子大小为0.75,也就是说,当Map中的元素个数(包括数组,链表和红黑树中)超过了16*0.75=12之后开始扩容。将会创建原来HashMap大小的两倍的bucket数组,来重新调整map的大小,并将原来的对象放入新的bucket数组中。这个过程叫作rehashing,因为它调用hash方法找到新的bucket位置。在JDK 8中,新的下标位置等于原下标位置 + 原数组长度
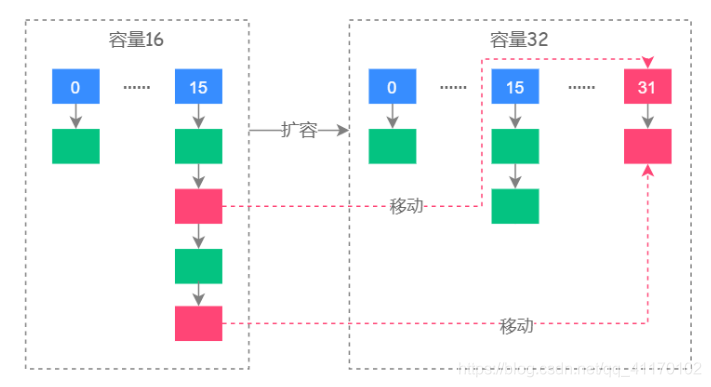
但是要注意,在JDK 7 环境下,在多线程环境下,HashMap扩容会导致死循环扩容死循环问题分析
在JDK7中,扩容会调用transfer方法,代码如下
void transfer(Entry[] newTable, boolean rehash) { int newCapacity = newTable.length; for (Entry<K, V> e : table) { while (null != e) { Entry<K, V> next = e.next; // 第5行 关键步骤1 if (rehash) { e.hash = null == e.key ? 0 : hash(e.key); } int i = indexFor(e.hash, newCapacity); e.next = newTable[i]; //关键步骤2 newTable[i] = e; //关键步骤3 e = next; //关键步骤4 } } }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
创建两个线程A,B,当线程A执行完了关键步骤1之后,失去时间片,线程B获得时间片完成扩容,然后当线程A再次获得时间片时,就会出现死循环现象。
分析:
单线程或者线程不冲突情况下,正常扩容如图所示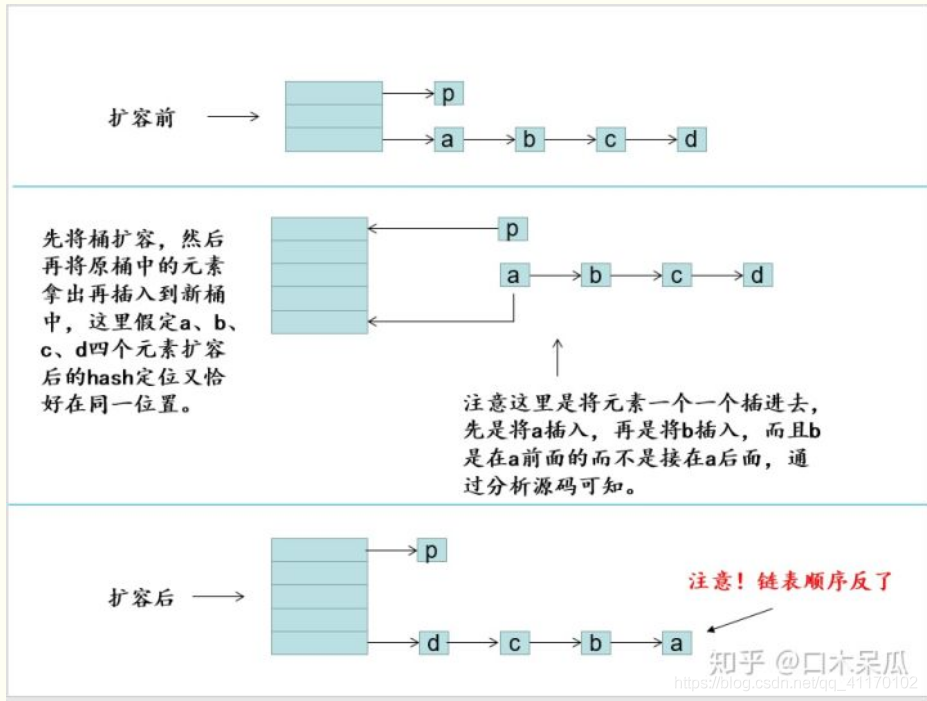
并发情况下当线程A执行完关键步骤1之后,将e指向了a、e.next指向了b
此时失去时间片,由线程B完成了扩容
当线程A再次获得时间片时,扩容实际已经完成了,但是e依然指向a、e.next指向了b,于是继续进行扩容,于是在a与b之间不断的发生循环,造成死循环
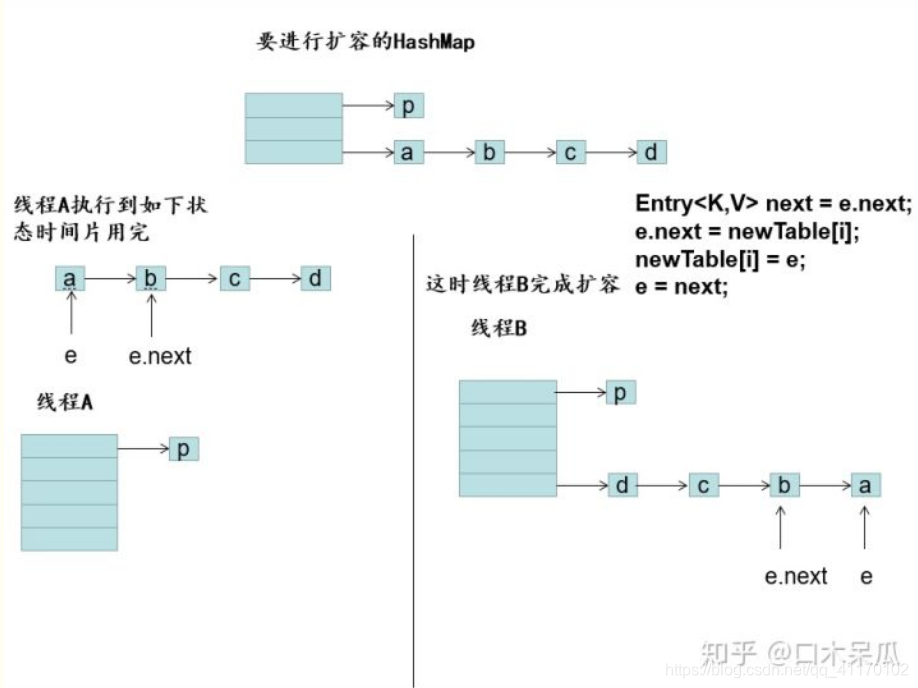
ps:此处图片引自知乎解决Hash冲突的方法有哪些?
- 开放定址法:当关键字
key的hash地址p=hase(key)出现冲突时,以某种探测技术递归的寻找空白地址,直到找到返回。如:以p为基础再产生另一个hash地址p1,如果p1也冲突了就继续找直到找到 - 拉链法:所有
hash地址相同的构成一个单链表,单链表的头指针放在hash表的第i个单元中。JDK8之前的HashMap就是使用的拉链法 - 线性补偿探测法:当发生冲突时,将线性探测的步长从 1 改为 Q ,将算法中的 j = (j + 1) % m 改为: j = (j + Q) % m ,而且要求 Q 与 m 是互质的,以便能探测到哈希表中的所有单元
哪些类适合作为HashMap的键?
String和Integer这样的包装类非常适合作为HashMap的键。因为他们都是final类型的类,而且重写了equals和hashCode方法,避免了键值对改写,有效提高HashMap性能
hashCode 和 equals 的一些基本约定equals相等,hashCode一定要相等- 重写了
hashCode也要重写equals hashCode需要保持一致性,状态改变返回的哈希值仍然要一致
TreeMap相关的Comparable接口和Comparator接口有哪些区别呢?
Comparable实现比较简单,但是当需要重新定义比较规则的时候,必须修改源代码,即修改User类里边的compareTo方法Comparator接口不需要修改源代码,只需要在创建TreeMap的时候重新传入一个具有指定规则的比较器即可
Vector、ArrayList和LinkedList有哪些区别?
底层实现
Vector和ArrayList底层使用动态数组实现
LinkedList底层使用双向链表实现,可当做堆栈、队列、双端队列使用线程安全性
Vector是线程安全的,效率较低,已经不推荐使用了,多线程环境下现在推荐使用CopyOnWriteArrayList替代ArrayListArrayList和LinkedList是线程不安全的
扩容增量
Vector和ArrayList当数组满的时候,会自动创建扩容后的数组,并拷贝原有数组数据Vector扩容增量是1倍ArrayList扩容增量是50%LinkedList采用双向链表不需要扩容
应用场景
Vector和ArrayList在随机存取方面效率高,适合随机访问较多的场景LinkedList在节点的增删方面效率高,适合于频繁对节点进行操作的场景
HashSet和TreeSet有哪些区别?
HashSet底层使用hash表实现
保证元素唯一性的原理:判断元素的hashCode值是否相同。如果相同,还会继续判断元素的equals方法,是否为true
HashSet的contains方法使用HashMap得containsKey方法实现TreeSet底层使用了红黑树来实现,其实底层实现还是TreeSet,只是用来其中的Key
保证元素唯一性是通过Comparable或者Comparator接口实现
Iterator和ListIterator的区别是什么?
Iterator可以遍历list和set集合;ListIterator只能用来遍历list集合Iterator前者只能前向遍历集合;ListIterator可以前向和后向遍历集合ListIterator其实就是实现了前者,并且增加了一些新的功能
数组与List之间的转换
- 数组转为List
通过Arrays.asList方法实现,转换之后不可以使用add/remove等修改集合的相关方法,因为该方法返回的其实是一个Arrays的在这里插入代码片内部私有的一个类ArrayList,本质上还是一个数组 - List转为数组
- 通过方法
List.toArray实现,这里最好传入一个类型一样的数组,大小为list.size()
如果入参分配的数组空间不够大,会重新分配内存空间返回新的数组
如果数组元素大于实际需要的,多余的数组元素会被置null
Collection和Collections有什么关系?
Collection是一个顶层集合接口,其子接口包括List和Set;Collections是一个集合工具类,可以操作集合,比如说排序,二分查找,拷贝集合,寻找最大最小值等。 总而言之:带s的大都是工具类。
以上就是我目前所掌握的Java面试相关的题目,后续发现有没有写到的比较重要的再补充上来。
有问题可以给我留言,看到了会及时的进行回复
更多Java面试复习笔记和总结可访问我的面试复习专栏《Java面试复习笔记》,或者访问我另一篇博客《Java面试核心知识点汇总》查看目录和直达链接
-
相关阅读:
20231103-黑马web进阶-动画
深度学习的炼金术:转化数据为黄金的秘密
Android逆向学习之Frida逆向与抓包实战学习笔记(持续更新中)
九号公司——高科技黑马的进击与困境
初步认识端口服务查询--netstat
量化交易:公司基本面的量化
OpenStack与CloudStack
【从零开始学习 SystemVerilog】11.4、SystemVerilog 断言—— $rose, $fell, $stable
视频下载软件 Downie4 mac中文介绍
现在Win11和Win10哪个好用?
- 原文地址:https://blog.csdn.net/web15085599741/article/details/125453431