-
《Python 3网络爬虫开发实战 》崔庆才著 第五章笔记
文件存储
1.TXT文本存储
如果对检索和数据结构要求不高,追求方便为第一的话,可以采用TXT文本存储。
随便爬取一个漫画网站
import requests from lxml import etree url='https://www.maofly.com/' headers={ 'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Mobile Safari/537.36 Edg/102.0.1245.44' } html=requests.get(url,headers).content items=etree.HTML(html,etree.HTMLParser()) result_title = items.xpath('//div[@class="media-body"]/h4[@class="mt-0 mb-0"]/a/text()') for ti in result_title: file=open('explore.txt','a',encoding='utf-8') file.write(''.join(ti)) file.write('\n') file.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
这里open()方法的第一个参数即要保存的目标文件名称,第二个参数为a,代表以追加方式写入到文本。另外,我们还指定了文件的编码为utf-8。最后,写入完成后,还需要调用close()方法来关闭文件对象。

在刚才的实例中,open()方法的第二个参数设置成了a,这样在每次写入文本时不会清空源文件,而是在文件末尾写入新的内容,这是一种文件打开方式。关于文件的打开方式,其实还有其他几种,这里简要介绍一下。
方式 说明 r 以只读方式打开文件。文件的指针将会放在文件的开头。这是默认模式。 r+ 以读写方式打开一个文件。文件指针将会放在文件的开头。 rb 以二进制只读方式打开一个文件。文件指针将会放在文件的开头。 rb+ 以二进制读写方式打开一个文件。文件指针将会放在文件的开头。 w 以写入方式打开一个文件。如果该文件已存在,则将其覆盖。如果该文件不存在,则创建像文件。 w+ 以读写方式打开一个文件。如果该文件已存在,则将其覆盖。如果该文件不存在,则创建像文件。 wb 以二进制写入方式打开一个文件。如果该文件已存在,则将其覆盖。如果该文件不存在,则创建新文件。 wb+ 以二进制读写方式打开一个文件。如果该文件已存在,则将其覆盖。如果该文件不存在,则创建新文件。 a 以追加方式打开一个文件。如果该文件已存在,文件指针将会放在文件结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,则创建新文件来写入。 a+ 以读写方式打开一个文件。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,则创建新文件来读写。 ab 以二进制追加方式打开一个文件。如果该文件已存在,则文件指针将会放在文件结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,则创建新文件来写入。 ab+ 以二进制追加方式打开一个文件。如果该文件已存在,则文件指针将会放在文件结尾如果该文件不存在,则创建新文件用于读写。 简化写法,使用with as语法来处理文件,可以该语法自动关闭文件。
import requests from lxml import etree url='https://www.maofly.com/' headers={ 'User-Agent': 'Mozilla/5.0 (Linux; Android 6.0; Nexus 5 Build/MRA58N) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Mobile Safari/537.36 Edg/102.0.1245.44' } html=requests.get(url,headers).content items=etree.HTML(html,etree.HTMLParser()) result_title = items.xpath('//div[@class="media-body"]/h4[@class="mt-0 mb-0"]/a/text()') for ti in result_title: with open('explore.txt','a',encoding='utf-8') as file: file.write(''.join(ti)) file.write('\n') file.close()- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
2.JSON文件存储
JSON,全称为JavaScript Object Notation,也就是JavaScript对象标记,它通过对象和数组的组合来表示数据,构造简洁但是结构化程度非常高,是一种轻量级的数据交换格式。
在JavaScript语言中,一切都是对象。因此,任何支持的类型都可以通过JSON来表示,例如字符串、数字、对象、数组等,但是对象和数组是比较特殊且常用的两种类型,下面简要介绍一下它们。
- 对象:它在JavaScript中是使用花括号{}包裹起来的内容,数据结构为{key1:value1, key2:value2,…}的键值对结构。在面向对象的语言中,key为对象的属性,value为对应的值。键名可以使用整数和字符串来表示。值的类型可以是任意类型。
- 数组:数组在JavaScript 中是方括号[]包裹起来的内容,数据结构为[“java”, “javascript”,"vb ",…]的索引结构。在 JavaScript中,数组是一种比较特殊的数据类型,它也可以像对象那样使用键值对,但还是索引用得多。同样,值的类型可以是任意类型。
一个JSON对象形式:
[{ "name": "Dog", "gender": "male", "birthday"; "2000.11.11" },{ "name": "Cat", "gender": "female", "birthday"; "2001.11.11" }]- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
由中括号包围的就相当于列表类型,列表中的每个元素可以是任意类型,这个示例中它是字典类型,由大括号包围。
JSON可以由以上两种形式自由组合而成,可以无限次嵌套,结构清晰,是数据交换的极佳方式。
读取JSON数据
import json js=''' [{ "name": "Dog", "gender": "male", "birthday": "2000-11-11" },{ "name": "Cat", "gender": "female", "birthday": "2001-11-11" }] ''' print(type(js)) data=json.loads(js) print(data) print(type(data))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17

这里使用loads()方法将字符串转为JSON对象。由于最外层是中括号,所以最终的类型是列表类型。需要注意下,JSON的数据只能用双引号进行包围,不能使用单引号进行包围。
这样一来,我们就可以用索引来获取对应的内容了。例如,如果想取第一个元素里的name属性,就可以使用如下方式:
data=json.loads(js) print('性别:'+data[0].get('gender')) print(data[0].get('age',25)) #可以通过该方法对源JSON数据进行声明和赋值 print('性别:'+data[1].get('gender'))- 1
- 2
- 3
- 4

还可以直接读取json文件,这里data.json文件里面存放这和前面例子一样的json数据。
import json with open('data.json')as file: s=file.read() data=json.loads(s) print(data)- 1
- 2
- 3
- 4
- 5
- 6
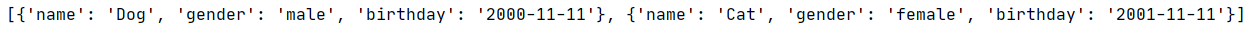
输出JSON
调用dumps的方法将JSON对象转化为字符串。
import json data=[{ 'name': 'Cat', 'gender': 'male', 'birthday': '2000-10-10' }] with open('data1.json','w')as file: file.write(json.dumps(data))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

如果想要保存JSON的格式,还可以在调用write函数的时候添加
indent=2参数,该参数代表缩进字符的个数。
但是需要注意的是,如果JSON包含中文的话会自动转化为Unicode编码,因此如果不希望出现Unicode的话需要添加
ensure_ascii=False参数。import json data=[{ 'name': '李四', 'gender': 'male', 'birthday': '2000-10-10' }] with open('data.json','w')as file: file.write(json.dumps(data,indent=2,ensure_ascii=False))- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

3.CSV文件存储
CSV文件以纯文本形式存储表格数据。
写入
这里的
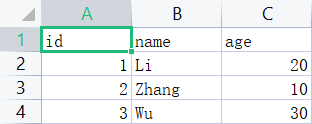
newline=' '是用来去除掉上下行之间数据的空行的。import csv with open('data.csv','w',newline='')as file: write=csv.writer(file) write.writerow(['id','name','age']) write.writerow(['1','Li','20']) write.writerow(['2','Zhang','10']) write.writerow(['3','Wu','30'])- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
除了使用
writerow方法进行一行一行地写入,我们还可以使用writerows方法一次性写入多行数据。import csv with open('data1.csv','w',newline='')as file: write=csv.writer(file) write.writerow(['id','name','age']) write.writerows([['1','Li','20'],['2','Zhang','10']])- 1
- 2
- 3
- 4
- 5
- 6
但是一般情况下,爬虫爬取的都是结构化数据,我们一般会用字典来表示。在csv库中也提供了字典的写人方式,即使是中文也不需要进行编码,示例如下:
import csv with open('data.csv','w',newline='')as csvfile: filenames=['id','name','age'] writer=csv.DictWriter(csvfile,fieldnames=filenames) writer.writeheader() writer.writerow({'id': '1','name': ' 李','age': '20'}) writer.writerow({'id': '2','name': 'Wan','age': '20'}) writer.writerow({'id': '3','name': 'qian','age': '20'})- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
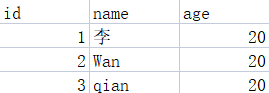
读取
在遇到中文数据的时候,他读取到的是Unicode编码,所以我们需要进行解码
import csv with open('data.csv','r',encoding='GBK')as csvfile: reader=csv.reader(csvfile) for row in reader: print(row)- 1
- 2
- 3
- 4
- 5
- 6

我们还可以使用pandas进行读取
import pandas as pd df=pd.read_csv('data.csv',encoding='GBK') print(df)- 1
- 2
- 3

下面部分都是数据库处理的部分,我感觉我用不上就不记笔记了。
-
相关阅读:
汇编:lea 需要注意的一点
Java SpringBoot VI
SpringMVC 学习(七)JSON
DES加解密
IO 能够保证在确定的时间回来吗?
使用Python调用Linux下的动态链接库
企业文件外发要如何管控?外发文件管理制度是重要基础
haproxy软件的日志输出到指定文件
Vue3.3指北(三)
C语言指针的详细概念
- 原文地址:https://blog.csdn.net/weixin_45715461/article/details/125446641