-
论文阅读: A Unified Sequence Interface for Vision Tasks
A Unified Sequence Interface for Vision Tasks
- [2206.07669] A Unified Sequence Interface for Vision Tasks (arxiv.org)
- Google Research, Brain Team
- 想法直接,目标远大,论文易读,不易复现
- 学术挖坑阶段
他们的目标是追求一般的广泛的人工智能,是一种简单的人机交互接口,这就需要把各种视觉任务(detection, segmentation, keypoint, captioning)统一到一个框架里. 其实就是统一到captioning框架里。这篇文章可以看做是Pix2Segv2, 做的是输入图片和prompt(提示词),输出文字序列。序列可以是文本,可以是xmin=???,ymin=???, x=??, y=??, label=???这样的序列。该文建立一个35k的字典,包含32k的文本,1k的坐标,2k的类别,字典用于建立他们和token的隐射关系。

像上图左上角这样,输入图片和提示词[detect]的token, 经过Pix2SeqV2输出一串离散的tokens, 根据字典可以将tokens映射回人类可读的文字。他们的前作——Pix2Seq只是用在了检测任务上,本文PixSeqV2则拓展到了分割,关键点,图像描述任务中。它需要使用prompt提示网络要执行什么任务,但网络的结构是一样的,也是image encoder + sequence decoder架构, image encoder可以是ConvNet也可以是Transformer。 sequence decoder是transformers-based的语言模型, 以图片编码和前一个词为输入预测下一个词,第一个词就是prompt, 若预测出EOF表示句子结束。训练的目标是最大化图片和前一个token条件下,当前token的对数似然(likelihood)。
m a x i m i z e ∑ j = 1 L w j log P ( y j ∣ x , y 1 : j − 1 ) maximize\sum^L_{j=1}w_j\log{P(y_j|x,y_{1:j-1})} maximizej=1∑LwjlogP(yj∣x,y1:j−1)
x是输入图片,y是x的标注,即长为L的token序列,y1是已知的prompt, 权重wj被用于忽略一些特殊token。他们讨论了2种训练方法,1)Data mixing, 把所有任务的图片序列对混合起来训练,即便可以平衡各数据集的数量和难度,但是图像增强很难合并到一起做,因为不同任务需要的数据增强不同;2)Batch mixing,一个batch内只训一种任务,batch内部的数据增强是一致的,batch间是不同任务混合的。该文选择了Batch mixing, 但他们也希望未来可以用Data mixing, 因为可以简化流程,且便于加入更多新任务。意思是虽然现在方法很复杂,但他们以后会简化的,大家放心入坑吧。
在实验中,他们先在旷世的Objects365数据上预训练目标检测任务,输入是640x640,然后再在coco上训练100epoch, 输入是1024x1024,batch=128,(小壕)。他们认为如果他们在大尺度的image-text数据集上预训练,会极大提升captioning的性能。
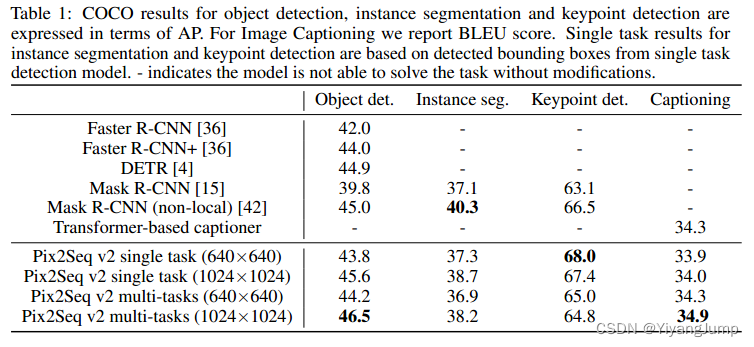
多个任务一起训练,需要平衡任务间的权重(loss?数据采样率?),对于检测,分割,描述,关键点的权重是0.1782, 0.7128, 0.099, 0.01,这组权重怎么得到的?是做了大量实验得到的(大壕):先检测+分割,看不同检测权重下检测和分割任务的评价指标变化,再加上图像描述,再看随着图像描述权重变化时检测分割描述三个任务的评价变化,再加上关键点,再看随着关键点权重变化这4个任务的评价指标变化。
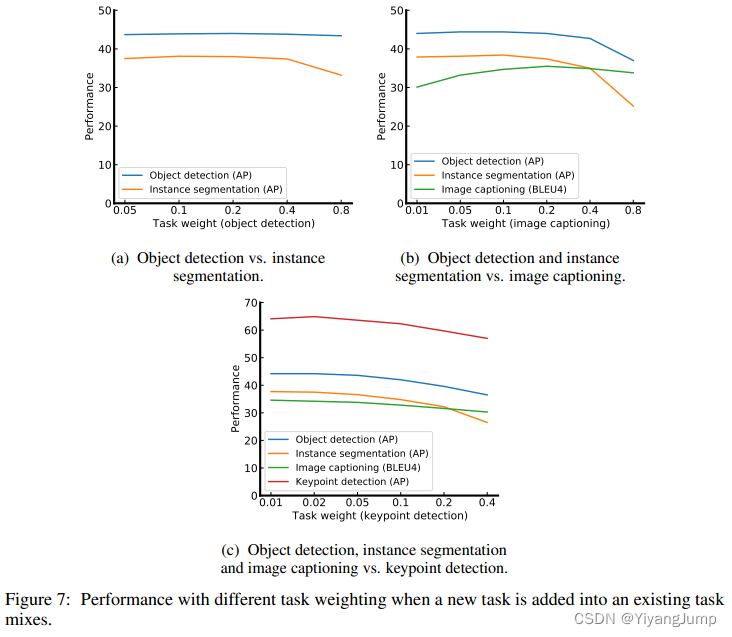
这也说明了三个任务的性能受这几个权重的影响还不小,如何平衡各个任务的训练仍是需要解决的问题。 -
相关阅读:
shell脚本之求和运算
ROS学习笔记05、ROS运行管理(元功能包、launch文件、空间覆盖与重名问题、分布式通信)
GitLab CI/CD关键词(十二):条件限定,only ,except,触发规则rules,工作流workflow
人计与机算:为什么AI距离智能越来越远?
Proxmox VE 近期有ARM 版本发布么?
《算法系列》之设计
Oracle查询固定时间间隔
Gd-DOTA,CAS:72573-82-1,钆特酸
npm报证书过期 certificate has expired问题(已解决)
怎么判断自己是否适合转行软件测试
- 原文地址:https://blog.csdn.net/q1w2e3r4470/article/details/125439620