-
【mysql学习笔记22】索引
优缺点
优势 劣势 提高数据检索效率,降低数据库的io成本 索引列需要占用空间 通过对索引列对数据进行排序,降低数据排序的成本,降低CPU的消耗 索引大大提高了查询效率,同时也降低了更新表的效率,因为更新表的同时也需要更新索引 索引结构
索引结构 描述 B+Tree索引(默认) 最常见的索引类型,大部分引擎都支持 Hash索引 底层原理是哈希表,不支持范围查询,只能够精确匹配 R-Tree 常用于地理空间数据类型 Full-text(全文索引) 是一种通过建立倒排索引,快速匹配文档的方式 各引擎对索引的支持
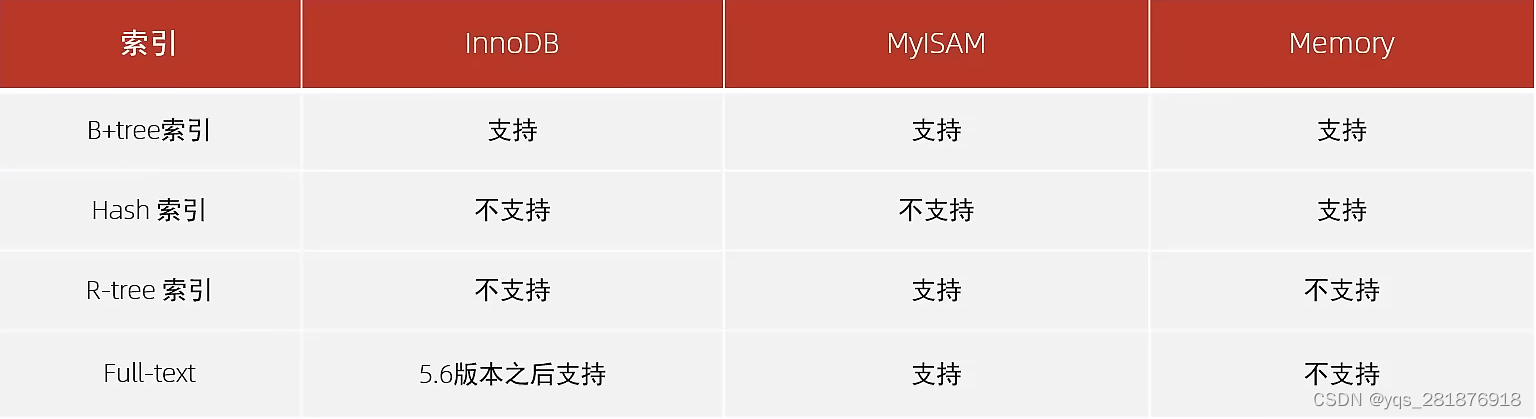
索引分类
分类 含义 特点 关键字 主键索引 针对于表中主键创建的索引 默认自动创建,只能有一个 PRIMARY 唯一索引 避免一个列有重复值 可以有多个 UNIQUE,可以在建表的时候就指定,也可以后期手动添加 常规索引 快速定位数据 可以有多个 无,需手动创建 全文索引 快速进行文本检索 可以有多个 FULLTEXT 拓展:列值唯一就是依靠唯一索引实现的。
分类 含义 特点 聚集索引 将数据存储与所以放到一块,索引结构的叶子节点保存了行数据 必须有,且只有一个,创建表时会自动将主键作为聚集索引,如果没有主键,使用第一个唯一索引作为聚集索引,如果都没有,InnoDB会自动一个隐藏的rowid作为聚集索引 二级索引 将数据与索引分开存储,索引结构的叶子节点存的是对应的主键 可以存在多个 实例
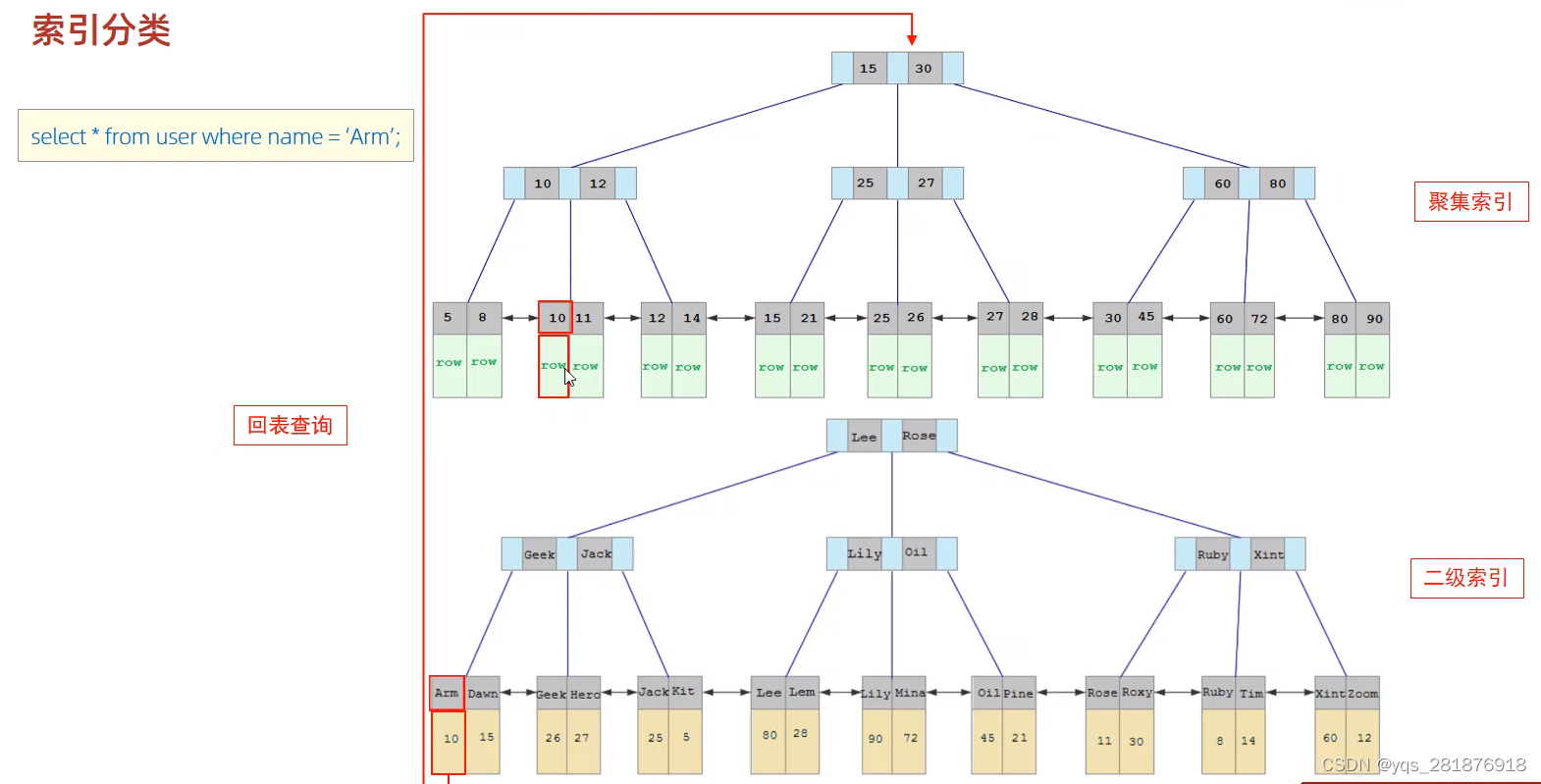
比如执行select * from user where name =‘Arm’;
那么就会先去name索引里面检索Arm,查询到Arm里面对应的id是10,那么就会拿着这个10去聚集索引里面查找具体数据,然后返回。这个过程叫做“回表查询”。创建索引
create [unique|fulltext] index index_name on table_name (index_col_name1,…);
查看索引
show index from table_name;
删除索引
drop index index_name on table_name;
-
相关阅读:
dcase_util教程
SpringBoot使用
绿联USB3.0扩展坞网卡:显示未连接;及Mac共享wifi
静态代码分析是如何工作的
【RocketMQ】RocketMQ 5.0新特性(三)- Controller模式
22.cuBLAS开发指南中文版--cuBLAS中的Level-2函数spmv()
号称年薪30万占比最多的专业,你知道是啥嘛?
ARMday06(总线、串口、RCC章节分析)
layui的一些问题
Spark性能调优案例-优化spark估计表大小失败 和 小表关联 走 broadcast join
- 原文地址:https://blog.csdn.net/qq_31618549/article/details/125417837