-
《MATLAB 神经网络43个案例分析》:第28章 决策树分类器的应用研究——乳腺癌诊断
《MATLAB 神经网络43个案例分析》:第28章 决策树分类器的应用研究——乳腺癌诊断
1. 前言
《MATLAB 神经网络43个案例分析》是MATLAB技术论坛(www.matlabsky.com)策划,由王小川老师主导,2013年北京航空航天大学出版社出版的关于MATLAB为工具的一本MATLAB实例教学书籍,是在《MATLAB神经网络30个案例分析》的基础上修改、补充而成的,秉承着“理论讲解—案例分析—应用扩展”这一特色,帮助读者更加直观、生动地学习神经网络。
《MATLAB神经网络43个案例分析》共有43章,内容涵盖常见的神经网络(BP、RBF、SOM、Hopfield、Elman、LVQ、Kohonen、GRNN、NARX等)以及相关智能算法(SVM、决策树、随机森林、极限学习机等)。同时,部分章节也涉及了常见的优化算法(遗传算法、蚁群算法等)与神经网络的结合问题。此外,《MATLAB神经网络43个案例分析》还介绍了MATLAB R2012b中神经网络工具箱的新增功能与特性,如神经网络并行计算、定制神经网络、神经网络高效编程等。
近年来随着人工智能研究的兴起,神经网络这个相关方向也迎来了又一阵研究热潮,由于其在信号处理领域中的不俗表现,神经网络方法也在不断深入应用到语音和图像方向的各种应用当中,本文结合书中案例,对其进行仿真实现,也算是进行一次重新学习,希望可以温故知新,加强并提升自己对神经网络这一方法在各领域中应用的理解与实践。自己正好在多抓鱼上入手了这本书,下面开始进行仿真示例,主要以介绍各章节中源码应用示例为主,本文主要基于MATLAB2015b(32位)平台仿真实现,这是本书第二十八章决策树分类器的应用研究实例,话不多说,开始!
2. MATLAB 仿真示例
打开MATLAB,点击“主页”,点击“打开”,找到示例文件
选中main_2009a.m,点击“打开”main_2009a.m源码如下:
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %功能:决策树分类器在乳腺癌诊断中的应用研究(2009a版本) %环境:Win7,Matlab2015b %Modi: C.S %时间:2022-06-20 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %% 决策树分类器在乳腺癌诊断中的应用研究(2009a版本) %% 清空环境变量 clear all clc warning off tic %% 导入数据 load data.mat % 随机产生训练集/测试集 a = randperm(569); Train = data(a(1:500),:); Test = data(a(501:end),:); % 训练数据 P_train = Train(:,3:end); T_train = Train(:,2); % 测试数据 P_test = Test(:,3:end); T_test = Test(:,2); %% 创建决策树分类器 ctree = classregtree(P_train,T_train); % 查看决策树视图 view(ctree); %% 仿真测试 T_sim = eval(ctree,P_test); %% 结果分析 count_B = length(find(T_train == 1)); count_M = length(find(T_train == 2)); rate_B = count_B / 500; rate_M = count_M / 500; total_B = length(find(data(:,2) == 1)); total_M = length(find(data(:,2) == 2)); number_B = length(find(T_test == 1)); number_M = length(find(T_test == 2)); number_B_sim = length(find(T_sim == 1 & T_test == 1)); number_M_sim = length(find(T_sim == 2 & T_test == 2)); disp(['病例总数:' num2str(569)... ' 良性:' num2str(total_B)... ' 恶性:' num2str(total_M)]); disp(['训练集病例总数:' num2str(500)... ' 良性:' num2str(count_B)... ' 恶性:' num2str(count_M)]); disp(['测试集病例总数:' num2str(69)... ' 良性:' num2str(number_B)... ' 恶性:' num2str(number_M)]); disp(['良性乳腺肿瘤确诊:' num2str(number_B_sim)... ' 误诊:' num2str(number_B - number_B_sim)... ' 确诊率p1=' num2str(number_B_sim/number_B*100) '%']); disp(['恶性乳腺肿瘤确诊:' num2str(number_M_sim)... ' 误诊:' num2str(number_M - number_M_sim)... ' 确诊率p2=' num2str(number_M_sim/number_M*100) '%']); toc- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
添加完毕,点击“运行”,开始仿真,输出仿真结果如下:
病例总数:569 良性:357 恶性:212 训练集病例总数:500 良性:313 恶性:187 测试集病例总数:69 良性:44 恶性:25 良性乳腺肿瘤确诊:40 误诊:4 确诊率p1=90.9091% 恶性乳腺肿瘤确诊:22 误诊:3 确诊率p2=88% 时间已过 0.989542 秒。- 1
- 2
- 3
- 4
- 5
- 6
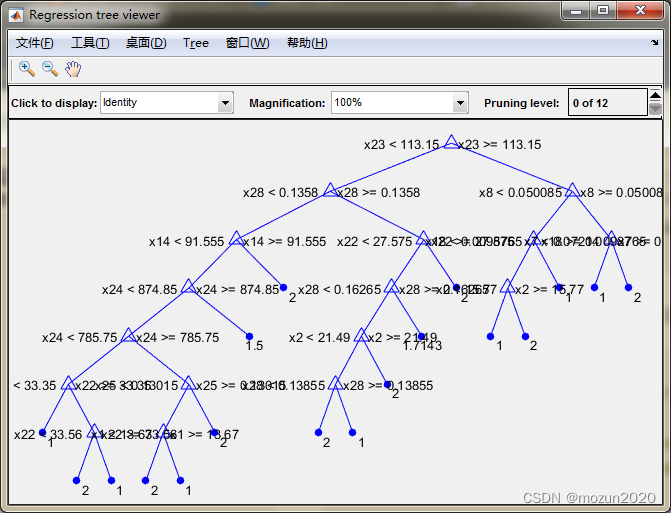
点击当前文件夹视图框中的main_2012b.m

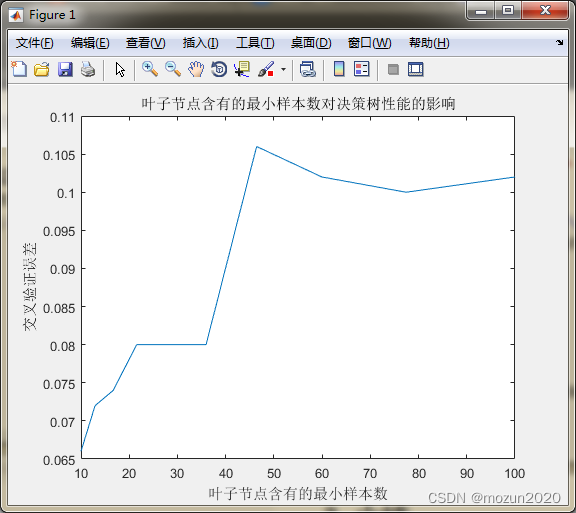
打开main_2012b.m源码如下:%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %功能:决策树分类器在乳腺癌诊断中的应用研究(2012b版本) %环境:Win7,Matlab2015b %Modi: C.S %时间:2022-06-20 %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%% %% 决策树分类器在乳腺癌诊断中的应用研究(2012b版本) %% 清空环境变量 clear all clc warning off tic %% 导入数据 load data.mat % 随机产生训练集/测试集 a = randperm(569); Train = data(a(1:500),:); Test = data(a(501:end),:); % 训练数据 P_train = Train(:,3:end); T_train = Train(:,2); % 测试数据 P_test = Test(:,3:end); T_test = Test(:,2); %% 创建决策树分类器 ctree = ClassificationTree.fit(P_train,T_train); % 查看决策树视图 view(ctree); view(ctree,'mode','graph'); %% 仿真测试 T_sim = predict(ctree,P_test); %% 结果分析 count_B = length(find(T_train == 1)); count_M = length(find(T_train == 2)); rate_B = count_B / 500; rate_M = count_M / 500; total_B = length(find(data(:,2) == 1)); total_M = length(find(data(:,2) == 2)); number_B = length(find(T_test == 1)); number_M = length(find(T_test == 2)); number_B_sim = length(find(T_sim == 1 & T_test == 1)); number_M_sim = length(find(T_sim == 2 & T_test == 2)); disp(['病例总数:' num2str(569)... ' 良性:' num2str(total_B)... ' 恶性:' num2str(total_M)]); disp(['训练集病例总数:' num2str(500)... ' 良性:' num2str(count_B)... ' 恶性:' num2str(count_M)]); disp(['测试集病例总数:' num2str(69)... ' 良性:' num2str(number_B)... ' 恶性:' num2str(number_M)]); disp(['良性乳腺肿瘤确诊:' num2str(number_B_sim)... ' 误诊:' num2str(number_B - number_B_sim)... ' 确诊率p1=' num2str(number_B_sim/number_B*100) '%']); disp(['恶性乳腺肿瘤确诊:' num2str(number_M_sim)... ' 误诊:' num2str(number_M - number_M_sim)... ' 确诊率p2=' num2str(number_M_sim/number_M*100) '%']); %% 叶子节点含有的最小样本数对决策树性能的影响 leafs = logspace(1,2,10); N = numel(leafs); err = zeros(N,1); for n = 1:N t = ClassificationTree.fit(P_train,T_train,'crossval','on','minleaf',leafs(n)); err(n) = kfoldLoss(t); end plot(leafs,err); xlabel('叶子节点含有的最小样本数'); ylabel('交叉验证误差'); title('叶子节点含有的最小样本数对决策树性能的影响') %% 设置minleaf为28,产生优化决策树 OptimalTree = ClassificationTree.fit(P_train,T_train,'minleaf',28); view(OptimalTree,'mode','graph') % 计算优化后决策树的重采样误差和交叉验证误差 resubOpt = resubLoss(OptimalTree) lossOpt = kfoldLoss(crossval(OptimalTree)) % 计算优化前决策树的重采样误差和交叉验证误差 resubDefault = resubLoss(ctree) lossDefault = kfoldLoss(crossval(ctree)) %% 剪枝 [~,~,~,bestlevel] = cvLoss(ctree,'subtrees','all','treesize','min') cptree = prune(ctree,'Level',bestlevel); view(cptree,'mode','graph') % 计算剪枝后决策树的重采样误差和交叉验证误差 resubPrune = resubLoss(cptree) lossPrune = kfoldLoss(crossval(cptree)) toc- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
点击“运行”,开始仿真,输出仿真结果如下:
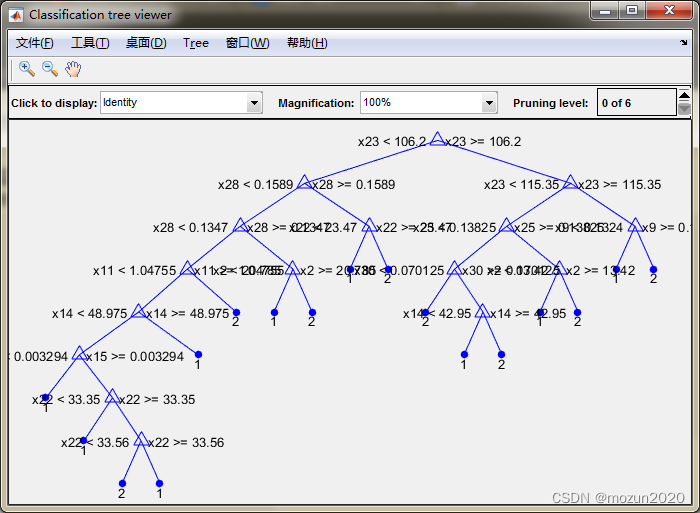
Decision tree for classification 1 if x23<106.2 then node 2 elseif x23>=106.2 then node 3 else 1 2 if x28<0.1589 then node 4 elseif x28>=0.1589 then node 5 else 1 3 if x23<115.35 then node 6 elseif x23>=115.35 then node 7 else 2 4 if x28<0.1347 then node 8 elseif x28>=0.1347 then node 9 else 1 5 if x22<23.47 then node 10 elseif x22>=23.47 then node 11 else 2 6 if x25<0.13825 then node 12 elseif x25>=0.13825 then node 13 else 2 7 if x9<0.1324 then node 14 elseif x9>=0.1324 then node 15 else 2 8 if x11<1.04755 then node 16 elseif x11>=1.04755 then node 17 else 1 9 if x2<20.785 then node 18 elseif x2>=20.785 then node 19 else 1 10 class = 1 11 class = 2 12 if x30<0.070125 then node 20 elseif x30>=0.070125 then node 21 else 1 13 if x2<13.42 then node 22 elseif x2>=13.42 then node 23 else 2 14 class = 1 15 class = 2 16 if x14<48.975 then node 24 elseif x14>=48.975 then node 25 else 1 17 class = 2 18 class = 1 19 class = 2 20 class = 2 21 if x14<42.95 then node 26 elseif x14>=42.95 then node 27 else 1 22 class = 1 23 class = 2 24 if x15<0.003294 then node 28 elseif x15>=0.003294 then node 29 else 1 25 class = 1 26 class = 1 27 class = 2 28 class = 1 29 if x22<33.35 then node 30 elseif x22>=33.35 then node 31 else 1 30 class = 1 31 if x22<33.56 then node 32 elseif x22>=33.56 then node 33 else 1 32 class = 2 33 class = 1 病例总数:569 良性:357 恶性:212 训练集病例总数:500 良性:317 恶性:183 测试集病例总数:69 良性:40 恶性:29 良性乳腺肿瘤确诊:36 误诊:4 确诊率p1=90% 恶性乳腺肿瘤确诊:27 误诊:2 确诊率p2=93.1034% resubOpt = 0.0720 lossOpt = 0.0820 resubDefault = 0.0080 lossDefault = 0.0740 bestlevel = 1 resubPrune = 0.0100 lossPrune = 0.0880 时间已过 4.620338 秒。- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
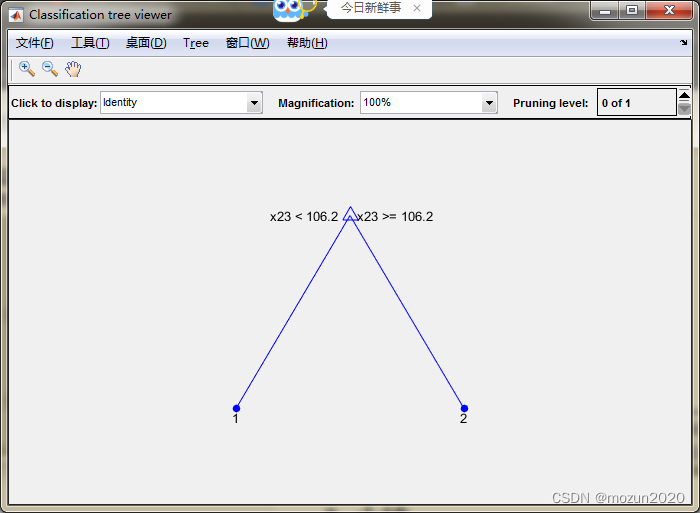

3. 小结
决策树是一种树型结构,其中每个内部节结点表示在一个属性上的测试,每一个分支代表一个测试输出,每个叶结点代表一种类别。决策树学习是以实例为基础的归纳学习。决策树学习采用的是自顶向下的递归方法,其基本思想是以信息熵为度量构造一棵熵值下降最快的树。到叶子节点的处的熵值为零,此时每个叶结点中的实例都属于同一类。本章介绍了决策树字matlab2009a版本与matlab2012b版本中进行仿真时的输出效果,在视觉机器学习20讲的专栏中也有介绍到决策树的其他仿真示例,具体链接在文末,大家也可以参考学习。对本章内容感兴趣或者想充分学习了解的,建议去研习书中第二十八章节的内容。后期会对其中一些知识点在自己理解的基础上进行补充,欢迎大家一起学习交流。
-
相关阅读:
如何通过编码器信号计算输送线/输送带线速度(飞剪、追剪算法基础)
React---简单原理
凉鞋的 Unity 笔记 106. 第二轮循环&场景视图&Sprite Renderer
云原生技术 --- k8s配置组件之ConfigMap的学习与使用
【编码译码】基于matlab QC-LDPC码编码和译码【含Matlab译码 2194期】
话题通讯自定义msg
千万不要搞生态啊,除非...
断点是什么,断点有哪几种类型?
计算机SCI论文的摘要怎么写? - 易智编译EaseEditing
JAVA在线作业提交系统计算机毕业设计Mybatis+系统+数据库+调试部署
- 原文地址:https://blog.csdn.net/sinat_34897952/article/details/125288156