-
A/B 测试:Python 分步指南
1、A/B test是什么
A / B测试(也称为分割测试或桶测试)是一种将网页或应用程序的两个版本相互比较以确定哪个版本的性能更好的方法。AB测试本质上是一个实验,其中页面的两个或多个变体随机显示给用户,统计分析确定哪个变体对于给定的转换目标(指标如CTR)效果更好。在本文中,我们将介绍分析 A/B 实验的过程,从提出假设、测试到最终解释结果。对于我们的数据,我们将使用来自 Kaggle 的数据集,其中包含对似乎是网站页面的 2 种不同设计(old_page 与 new_page)的 A/B 测试的结果。
这是我们要做的:
1,设计我们的实验
(选定指标,建立假设,选择实验单位,计算样本量,流量分割,实验周期计算,线上验证策略是否已实施)
2,收集和准备数据
3,可视化结果
4,检验假设
5,得出结论为了使它更现实一点,这里有一个我们研究的潜在场景
假设您在一家中型在线电子商务企业的产品团队工作。UI 设计师在新版本的产品页面上非常努力,希望它能带来更高的转化率。产品经理(PM)告诉你,目前的转化率全年平均在13%左右,如果提高2% ,团队会很高兴,也就是说,新设计如果提高了,就被认为是成功的。转化率15%。 在推出更改之前,团队会更愿意在少数用户上对其进行测试以了解其性能,因此您建议对一部分用户群用户进行A/B 测试。- 1
- 2
- 3
设计我们的实验
选定我们的指标,相对值指标:转化率。
选实验单位:用户粒度,一个user_id作为唯一标识提出假设:
鉴于我们不知道新设计的性能是否会与我们当前的设计更好或更差(或相同?),我们将选择双尾实验:
Hₒ:p = p ₒ
Hₐ :p ≠ pₒ
其中p和p ₒ分别代表新旧设计的转化率。我们还将设置95% 的置信水平:
α = 0.05
α值是我们设置的阈值,我们说“如果观察到极端或更多结果的概率(p值)低于α,那么我们拒绝 Null 假设”。由于我们的α=0.05(表示概率为 5%),我们的置信度 (1- α ) 为 95%。
如果您不熟悉上述内容,请不要担心,这实际上意味着无论我们在测试中观察到新设计的转化率如何,我们都希望有 95% 的把握它与我们旧设计的转化率在统计上有所不同设计,在我们决定拒绝零假设 Hₒ 之前。
选择样本量
重要的是要注意,由于我们不会测试整个用户群(我们的人口),我们将获得的转化率不可避免地只是对真实转化率的估计。
我们决定在每个组中捕获的人数(或用户会话)将影响我们估计的转化率的精度: 样本量越大,我们的估计越精确(即我们的置信区间越小),发现差异的机会越高在两组中,如果存在的话。
另一方面,我们的样本数越大,我们的研究就越昂贵(和不切实际),通常来说都是选择最低满足的样本数。
那么我们每个组应该有多少人呢?
我们需要的样本量是通过一种叫做Power analysis的东西来估计的,它取决于几个因素:
检验的功效(1 - β) — 这表示当实际存在差异时,在我们的检验中发现组之间的统计差异的概率。按照惯例,这通常设置为 0.8
Alpha 值(α) — 我们之前设置为 0.05 的临界值
效果大小——我们预计转化率之间的差异有多大
由于我们的团队会对 2% 的差异感到满意,因此我们可以使用 13% 和 15% 来计算我们预期的效果大小。Python 为我们处理了所有这些计算:
# 包导入 import numpy as np import pandas as pd import scipy.stats as stats import statsmodels.stats.api as sms import matplotlib as mpl import matplotlib.pyplot as plt import seaborn as sns from math import ceil %matplotlib inline # 一些绘图样式偏好 plt.style.use('seaborn-whitegrid') font = {'family' : 'Helvetica', 'weight' : 'bold', 'size' : 14} mpl.rc('font', **font) effect_size = sms.proportion_effectsize(0.13, 0.15) # 根据我们的预期比率计算效果大小 required_n = sms.NormalIndPower().solve_power( effect_size, power=0.8, alpha=0.05, ratio=1 ) # 计算所需样本量 required_n = ceil(required_n) # 四舍五入到下一个整数 print(required_n)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
输出:4720
在实践中将power参数设置为 0.8 意味着如果我们的设计之间的转化率存在实际差异,假设差异是我们估计的差异(13% 对 15%),我们有大约 80% 的机会将其检测为在我们计算的样本量的测试中具有统计学意义。
当然,你也可以用:
这个近似公式进行评估样本量

按照绝对值指标赫相对值指标去定义,标准差值计算会有所不同:

开始查看我们的数据:df = pd.read_csv('ab_data.csv') df.head()- 1
- 2
- 3
输出:

df.info()- 1
输出:

DataFrame 中有294478 行,每行代表一个用户会话,以及5 列:
user_id- 每个会话的用户 ID
timestamp- 会话的时间戳
group- 用户被分配到该会话的哪个组 { control组, treatment组}
landing_page- 每个用户在该会话中看到的设计 { old_page(老页面), new_page}(新页面)
converted- 会话是否转化(0=未转化,1=转化)
我们实际上只会使用group和converted列进行分析。在我们继续对数据进行采样以获得我们的子集之前,让我们确保没有用户被多次采样。
有 3894 个用户出现了不止一次。由于数量非常少,我们将继续将它们从 DataFrame 中删除,以避免对相同的用户进行两次采样。
sers_to_drop = session_counts[session_counts > 1].index df = df[~df['user_id'].isin(users_to_drop)] print(f'更新的数据集现在有{df.shape[0]}个条目')- 1
- 2
- 3
- 4
采样
现在我们的 DataFrame 干净整洁,我们可以继续并n=4720为每个组采样条目。我们可以使用 pandas 的DataFrame.sample()方法来执行此操作,它将为我们执行简单随机抽样。注意random_state=22:如果您想在自己的笔记本上进行操作,我已设置为可重现结果:只需random_state=22在您的函数中使用,您应该得到与我相同的示例。
control_sample = df[df['group'] == 'control'].sample(n=required_n, random_state=22) treatment_sample = df[df['group'] == 'treatment'].sample(n=required_n, random_state=22) ab_test = pd.concat([control_sample, treatment_sample], axis=0) ab_test.reset_index(drop=True, inplace=True) ab_test- 1
- 2
- 3
- 4
- 5
- 6

ab_test.info()- 1

看看实验组和对照组的分割情况
ab_test['group'].value_counts()- 1

很棒!
3. 可视化结果conversion_rates = ab_test.groupby('group')['converted'] std_p = lambda x: np.std(x, ddof=0) # Std. 比例偏差 se_p = lambda x: stats.sem(x, ddof=0) # Std. 比例误差 (std / sqrt(n)) conversion_rates = conversion_rates.agg([np.mean, std_p, se_p]) conversion_rates.columns = ['conversion_rate', 'std_deviation', 'std_error'] conversion_rates.style.format ('{:.3f}')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13

从上面的统计数据来看,看起来我们的两个设计的表现非常相似,我们的新设计表现得稍微好一些,大约。12.3% 对 12.6% 的转化率。
可视化代码:
plt.figure(figsize=(8,6)) sns.barplot(x=ab_test['group'], y=ab_test['converted'], ci=False) plt.ylim(0, 0.17) plt.title( '按组的转化率', pad=20) plt.xlabel('Group', labelpad=15) plt.ylabel('Converted (proportion)', labelpad=15);- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
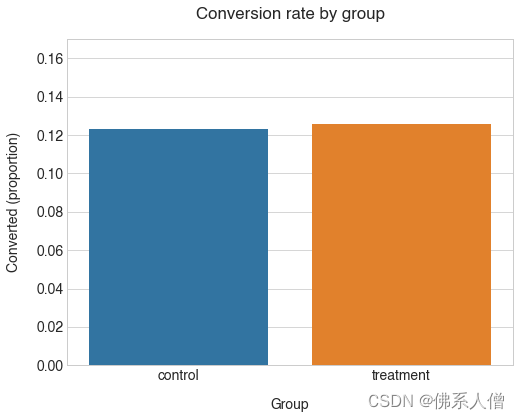
我们组的转化率确实非常接近。另请注意,control考虑到我们对平均值的了解,该组的转化率低于我们的预期。转化率(12.3% 对 13%)。这表明从总体中抽样时结果存在一些差异。
所以treatment团体的价值更高。这种差异在统计学上是否显著?
4. 检验假设
我们分析的最后一步是检验我们的假设。由于我们有一个非常大的样本,我们可以使用正态近似来计算我们的p值(即 z 检验)。同样,Python 使所有计算变得非常容易。我们可以使用该statsmodels.stats.proportion模块来获取p值和置信区间:
from statsmodels.stats.proportion import ratios_ztest, ratio_confint control_results = ab_test[ab_test['group'] == 'control']['converted'] treatment_results = ab_test[ab_test['group'] == 'treatment']['converted'] n_con = control_results.count() n_treat = treatment_results.count() 成功 = [control_results.sum(),treatment_results.sum()] nobs = [n_con, n_treat] z_stat, pval = ratios_ztest(successes, nobs=nobs) (lower_con , lower_treat), (upper_con, upper_treat) = ratio_confint(successes, nobs=nobs, alpha=0.05) print(f'z statistic: {z_stat:.2f}') print(f'p-value: {pval:.3f }') print(f'ci 95% for control group: [{lower_con:.3f}, {upper_con:.3f}]') print(f'ci 95% for treatment group: [{lower_treat:.3f}, {upper_treat:.3f}]')- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15

5. 得出结论
由于我们的p -value=0.732 远高于我们的 α=0.05阈值,我们不能拒绝零假设 Hₒ,这意味着我们的新设计与旧设计相比并没有显着不同(更不用说更好了)此外,如果我们查看该treatment组的置信区间([0.116, 0.135] 或 11.6-13.5%),我们会注意到:
它包括我们 13% 转化率的基准值
它不包括我们 15% 的目标值(我们的目标是 2% 的提升)
这意味着新设计的真实转化率更有可能与我们的基线相似,而不是我们希望的 15% 的目标。这进一步证明了我们的新设计不太可能是对旧设计的改进。 -
相关阅读:
[羊城杯 2022]LRSA
iptables
SpringBoot基础(五)-- 引导类
剑指offer——JZ24 反转链表 解题思路与具体代码
作业2 计算文件长度和行数
【Java加密算法】常见的五种加密算法案例整理(143)
javaEE高阶---Spring MVC
Android 错把setLayerType当成硬件加速
基于javaweb+mysql的电影票售票管理系统
Docker 的数据管理与Docker 镜像的创建
- 原文地址:https://blog.csdn.net/foxirensheng/article/details/125417400