-
使用 Databricks 进行营销效果归因分析的应用实践
本文介绍如何使用Databricks进行广告效果归因分析,完成一站式的部署机器学习,包括数据ETL、数据校验、模型训练/评测/应用等全流程。
内容要点:
- 在当下的信息化时代,用户每天都会收到媒体投放的广告信息,如何做到精准广告投放,可以通过分析广告产出结果来合理分配广告渠道。
- 归因分析(Attribution Analysis):通过归因分析模型,分析不同渠道的店铺客流量数据,量化评估影响客户消费的活动因子。
- 面对多且杂的数据,Databricks 如何通过一站式数据分析平台和 Delta Lake 架构简化执行过程。
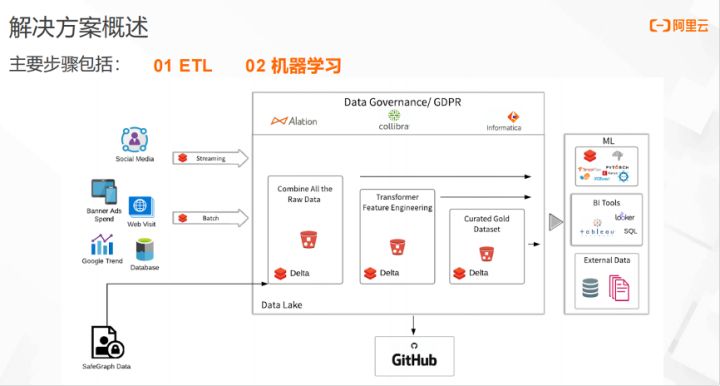
一、数据ETL
本文通过归因分析模型,分析不同渠道下的NewYork City快餐店的人流量数据,量化影响人们去快餐店消费的主要活动因子。
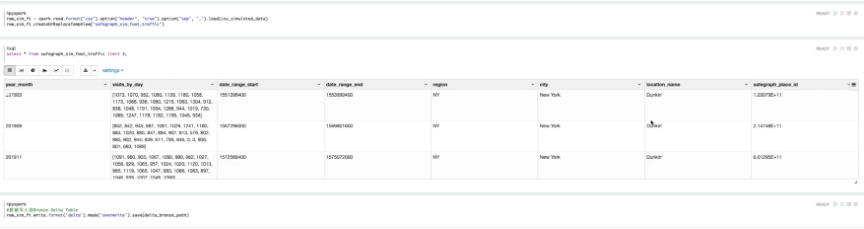
首先,从不同的媒体网站,获取分析需要的人流量的数据,模拟SafeGraph月度的人流量数,将数据存储到Bronze层。然后,进行数据清洗,将每月的时间序列数据,每日访问次数,存储到Silver层,将影响快餐店人流量的数据汇总至Gold层,进行进一步校验,确定是否满足要求。
接下来,对相关字段进行筛选,筛选出需要的字段,将店铺每日访问的人流量展示出来。
本文的数据是8月店铺的人流量,如果进行机器学习模型训练,还需要引入不同快餐店的人流量数据,来丰富该数据工程。
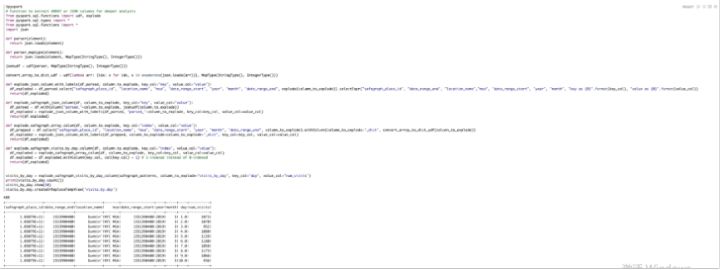
为了丰富数据工程,数据工程师创建了赛百味的fastfood数据集,模拟广告投放、社交媒体、门户网站的流量参数,将人流量的具体情况,默认到这个food traffic表中。
通过调用谷歌的Google Trends API,来丰富food traffic的数据。然后,将聚合后的数据写入delta gold table里,完成数据的ETL工作。
Google Trends,即常说的谷歌趋势,是谷歌基于搜索数据推出的一款分析工具。它通过分析谷歌搜索引挚每天数十亿的搜索数据,告诉用户某一关键词或者话题,各个时期在谷歌搜索引擎中展示的频率及其相关统计数据。
二、机器学习
完成ETL的相关工作之后,进入机器学习模块,将不同来源的人流量数据,统一到Data Lake架构里。通过数据清洗,得到需要的数据。然后,对数据进行校验,确定是否满足机器学习的模型训练需求。
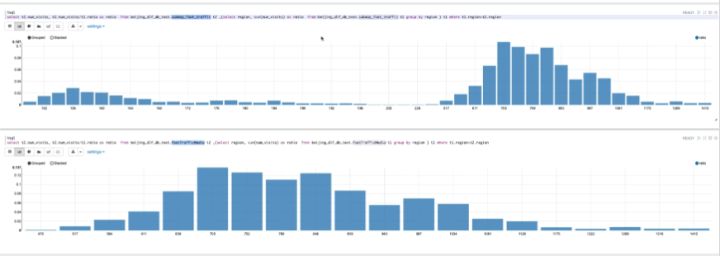
通过使用预测模型,量化不同渠道的人流量,对最终消费进行预测。
接下来,利用模型,整合各个媒介渠道影响客流量的百分比,对广告投放的优化提出可行性的见解。
如上图所示,第一张表是整个纽约州不同城市间的人流分布图,第二张表是New York City的人流分布图。通过上图,可以直观看到不同城市间的人流量差距较大,所以要对纽约州的每个城市进行单独的分析。
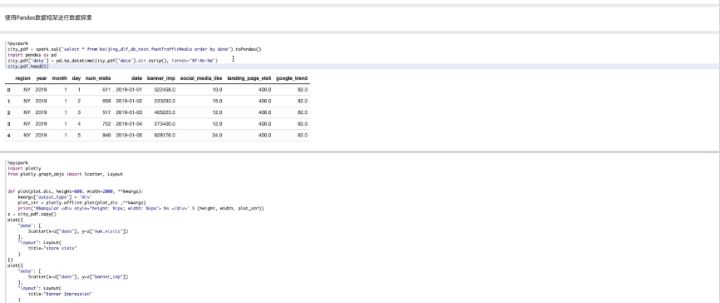
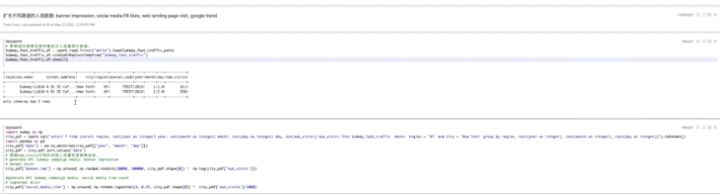
接下来,使用Plot features对数据进行校验,使用Pandas数据框进行数据搜索,数据解析。
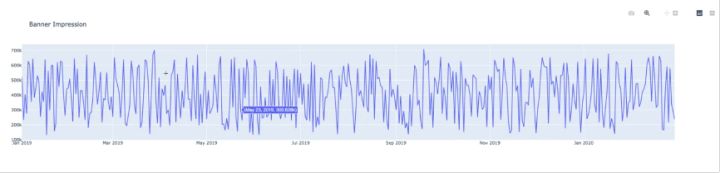
通过Python绘图,可以看到数据的分布情况,比如广告投放的连续情况,以及社交媒体网站的浏览情况。
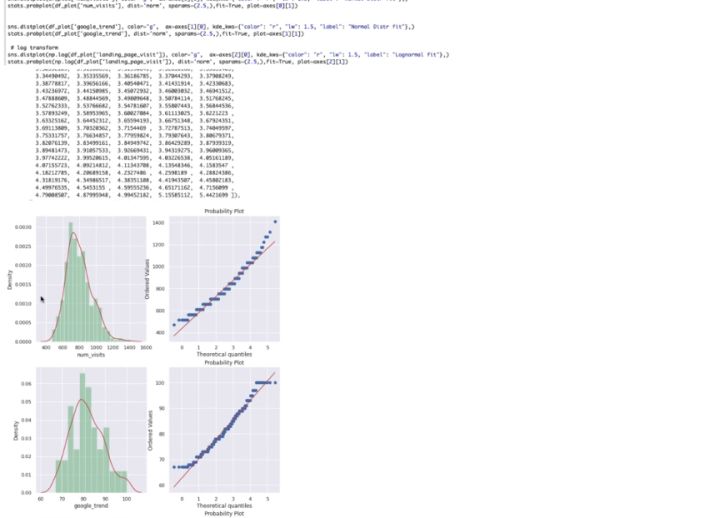
完成上述操作后,对数据集的整体分布进行校验,得出feature分布符合预期。综上所述,该数据集满足Xgboost学习训练的要求。
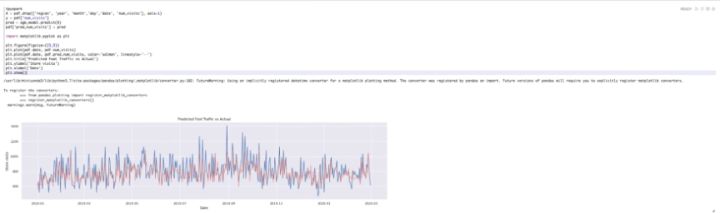
接下来,使用Xgboost机器学习框架进行训练。通过调整参数,选择一个相对损失较小的训练模型,对该模型进行实际预测,从上图可以看到,红色线是预测结果,蓝色线是真实的客户流量。
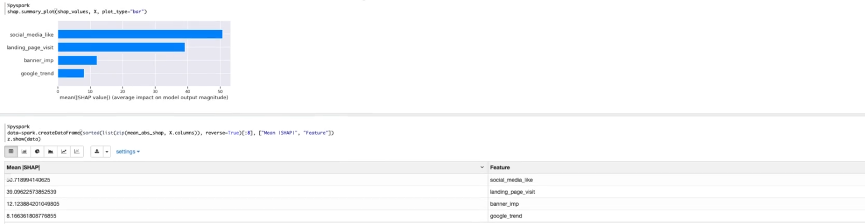
通过该模型进行实际预测,得出社交媒体对客流量的影响,占总体的50.7%,网页浏览对客流量的影响,占总体的39%。故得出,不同渠道的广告对客流的影响,真实有效。
综上所述,利用SHAP模型整合各媒介渠道客流的百分比,通过绘制图表,能够准确找到影响客流量最大的因子。社交媒体和home页面访问是推动客流量最有效的渠道,所以预算分配可以有的放失,从而提高整体销售或市场份额。
三、Demo演示
操作演示视频:https://developer.aliyun.com/live/249173
作者:冯加亮阿里云开源大数据平台技术工程师
本文为阿里云原创内容,未经允许不得转载。
-
相关阅读:
从零开始搭建一个springCloud项目
电脑通过串口助手和51单片机串口通讯
微擎模块 啦啦外卖跑腿小程序最新版14.3 带最新跑腿前端+教学视频 完整包
Scala基础【异常、隐式转换、泛型】
05-CSS溢出属性&文本溢出省略号
vue跨域问题解决:Access to XMLHttpRequest at‘httplocalhost
初识树结构和二叉树
sqllabs 1~6通关详解
【数据结构与算法】第十篇:二叉堆
Spring Cloud Alibaba Nacos 配置中心 (配置持久化与动态刷新) 实战
- 原文地址:https://blog.csdn.net/weixin_43970890/article/details/125409832