-
2022-06-21 Java后端面试总结
一、八股文
1.一次es查询发生的事情
答:master接收到查询请求,根据负载均衡策略,并结合路由字段将查询请求转发到指定分片上,如果未指定路由字段则转发到所有索引分片(主分片和副本分片择一转发),分片上执行查询语句,从倒排索引上找到相应的document id, 然后所有分片将查询结果返回到master节点上做合并操作,拿到最终结果,最后根据文档id“回表”获取到全部文档。
注意:倒排索引上可以设置是否包含该字段值,类似于覆盖索引,这时候要判断是从倒排索引上取值更快,还是回表查询更快,这个地方涉及到一个考点:I/O次数,回表查询是一次I/O,从多个索引上取值也是多次I/O,哪种方案更快取决于I/O的次数,I/O次数少的方案更快。2.tair如何实现的分布式锁,中间有哪些问题?
2.1 实现逻辑:
答:
实现方式:利用SETNX原子指令,利用可以唯一确定一条记录的业务key组装成唯一key,利用SETNX向唯一key上赋值,如果能赋值成功则认为获取锁成功。
2.2 如果获取到锁的线程宕掉了,没释放掉锁怎么办?
答:对tair缓存的唯一key设置超时时间,比如10秒,如果超过10秒线程还未释放锁,则自动释放。
2.3 设置超时时间,如果线程执行慢了,超过了超时时间怎么办?
答:利用看门狗机制,额外创建一个观察线程,如果执行线程快到超时时间仍未执行完毕,则主动延长超时时间。
2.4 如何释放锁?
答:tair.del(key),删除缓存的key。
2.5 目前有A、B两个线程,如何防止B线程误释放掉A线程加的锁?
答:SETNX给唯一key赋值时,value设置为当前线程id,释放锁时检验当前value是否为当前线程id,如果不是则抛异常,如果是则删除key。check和删除这两个操作需要保证在一个事务内,实现事务可以使用lua脚本的方式,将check和删除操作写入同一个lua脚本中, tair执行lua脚本是原子性的,从而保证事务。
2.6 tair是否会有单点故障?
答:会有单点问题,要解决单点问题可以使用REDLOCK或者REDISSION这种基于redis的分布式锁实现框架,他们利用集群的方式解决单点问题,但上面两个框架依然没办法完全保证锁的互斥性,极端情况下还是会出现不一致问题(Redlock在主从切换的瞬间获取到节点的锁),如果要求绝对一致性可以选择zookeeper或者数据库事务来保证。
2.7 除了自己实现分布式锁, 现在外界有现成的分布式锁框架吗?
答:有的,如上面提到的redlock和redission
2.8 分布式锁唤醒等待线程会造成羊群效应,如何解决?
答:维护一个有序队列,每次只唤醒队列的前3个线程。
3. redis用过吗?
3.1 redis有哪些数据结构?
答:redis有五种基本的数据结构:string、list、hash、set、zset。
3.2 zset底层是用什么数据结构实现的,插入和查询的时间复杂度是多少?
答:跳表和散列表,散列表底层是数组。插入和查找的时间复杂度都是o(logn)。
3.3 redis里的string底层是怎么实现的?
答:SDS数组结构,底层为数据加一些基本属性:
struct sdshdr{ int len;//记录buf数组中已使用字节的数量 int free; //记录 buf 数组中未使用字节的数量 char buf[];//字符数组,用于保存字符串 }3.4 redis为什么快呢?
答:
- redis是基于内存的,支持随机读写,读写复杂度为O(1),
- redis是单线程的,没有多线程之间的切换和资源的同步、锁的竞争等耗时场景。
- redis支持的数据结构简洁,专门定制的高效的数据结构,例如压缩列表。
- 基于I/O多路复用,同步非阻塞I/O。
- 底层定制VM,零拷贝技术(MMap)减少操作系统内核态与用户态的转换。
3.5 零拷贝技术有哪些实现呢?
答:
- DMA+文件句柄拷贝(kafka)
- MMAP
3.6 redis实现一个滑动窗口可以使用什么样的数据结构?
答:
zset,利用score排序,score递增来实现窗口的滑动。
3.7 redis set结构是如何扩容的?
答:渐进式rehash,新增数据在新数组,删改查在老数组,然后根据服务器空闲状态,批量的进行数据迁移。
4.数据库知识
4.1MySQL数据库锁有哪些呢?
答:
有乐观锁和悲观锁两大类:乐观锁有mvcc,悲观锁有全局锁、表锁、行锁、间隙锁、意向锁等。另外还有排他锁和共享锁这种概念上的分类。
4.2 数据库事务有哪些特性?MySQL是通过什么方式来实现这些特性的呢?
答:事务有四大特性:原子性、隔离性、持久性、一致性。MySQL利用undo log 实现原子性,利用redo log实现持久性和一致性,利用mvcc实现隔离性。
4.3 数据库事务有哪些隔离级别?
答:有四个隔离级别,读未提交、读已提交、可重复读、串行。读未提交会有脏读问题,读已提交不能重复读,可重复读级别有幻读问题。
4.4 mvcc能完全解决幻读吗?
答:只靠mvcc是不能完全解决幻读的,还必须配合数据库的记录锁和间隙锁,才能完全实现可重复度。
如何加间隙锁? SELECT FOR UPDATE
如何加记录锁(共享锁模式)? SELECT * FROM table_name WHERE ... LOCK IN SHARE MODE
4.5 mvcc是怎么实现的呢?
答:在记录上增加两个版本号字段,查找记录时利用版本号来筛选记录,从而实现快照读, 具体实现细节是:在聚簇索引上增加隐藏字段:当前事务id、指向undo log的指针,在undo log中记录版本链,利用自己事务id到版本链中查找符合自己版本要求的数据,从而实现读视图。
4.6 MySQL行锁是如何实现的呢?
通过给索引上的索引项加锁来实现的
4.7 什么时候会出现表锁,什么时候出现行锁?
答:更新数据时未使用索引筛选数据,或者表小,更新的数据占表大部分这时候会用到表锁。如果更新的是特定的记录,比如id = 5,这个时候会用到行锁。
4.8 上面提到undo log,MySQL是如何保证undo log和bin log的一致性?
答:通过分布式事务来保证的,因为undo log是存储引擎层记录的日志,bin log是数据库服务层记录的日志,这两种日志分别属于不同的功能模块,要保证不能功能模块之间数据的一致性只能通过分布式事务,MySQL利用两段式提交的方式来实现分布式事务,利用一个协调节点向存储引擎和服务层发送信号,获取两个模块是否已就绪,如果全部就绪协调节点则发送提交信号,两个模块完成数据变更的提交动作,如果有模块未就绪,则协调节点发送回滚信号,两个模块完成数据回滚操作。
4.9 MySQL常用的存储引擎有哪些?
答:有innodb、myisam、memory、CSV等
4.10 innodb底层的数据结构是什么?
答:是B+ 树,B+ 树是一种多路查找树,同一层节点有序,兄弟叶子节点之间有双向链表,支持范围查找。非叶子存储的索引数据不存储实际数据,叶子节点存储实际数据地址。B+ 树和B树的区别是:B+树所有查询必须走到叶子节点,B树走到非叶子就能返回,B+树利用兄弟节点的双向链表支持高效的范围查询,B+树非叶子不存储数据所以一页内存可以放更多节点,减少磁盘IO。
4.11 什么是聚簇索引?
答:在同一个结构中保存索引值和数据行,并且相邻键值紧凑的存储在一起的索引结构。
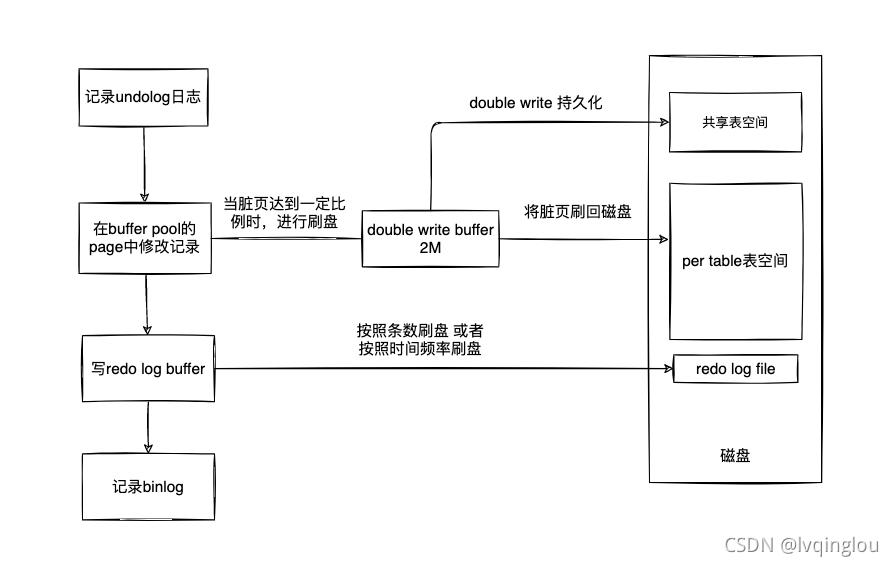
4.12 MySQL写入一条数据的过程
Mysql专栏(二)Innodb数据写入过程_lvqinglou的博客-CSDN博客_mysql数据写入流程
答:
4.13 UUID适合做MySQL的主键id吗?为什么
答:UUID不适合做主键id,因为:
- UUID要占128位,占用太多存储空间,相比于long型字段,一页内存只能放下50%的数据,这就导致两倍的磁盘I/O,查询性能低。
- UUID是无序的,这数据写入时需要随机寻址,随机寻址对于磁盘来说是性能最低的,另外无序也会导致索引树的结构剧烈变动,不断的调整节点位置,也会导致多次I/O从而降低性能。
- 信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露。
4.14 MySQL如何开启死锁检测? 底层实现原理是什么?线上如何排查死锁?
答:
innodb_deadlock_detect=on 这个语句可以开启死锁检测,死锁检测的原理是构建一个资源的等待图,然后深度优先搜索该图,如果图中存在环则任务存在死锁。线上排查死锁的方法:select * from information_schema.innodb_trx lock waits和 show innodb status语句可以打印出当前事务的执行状态,通过分析这些信息可以得出死锁卡在哪一点上。4.15 MySQL SELECT语句使用的两个字段都有索引,存储引擎如何选择使用哪一个呢?
答:查询优化器根据需要扫描的行数,是否使用临时表,是否排序等因素来选择具体使用的索引。优化器统计扫描行数的方法,统计索引基数,利用采样查几个页然后用平均值推算出总体数据量,选择扫描行数少的索引。如果order by 后的字段是索引,那么会选择这个索引,因为查询出的数据直接是有序的,不需要额外排序了。另外就是查询过程是否使用到临时表等场景。
4.16 MySQL 深翻页对性能有什么影响?如何解决?
答:深翻页会降低数据库性能,因为数据库会把前面所有的数据拉出来,然后再丢弃前n- 1页数据,最终返回第n页的数据,这个过程涉及到多次索引页的I/O,所以性能低。解决深翻页有多种方式:
- 每次查询记录上一次查询结果的最大id,然后利用这个id来筛选数据,减少页数。
- 单独建一张表,这种表里存储数据页跟id的关系,分页查询时先查关系表拿到id范围,然后再查数据
-
延迟关联inner join,利用覆盖索引来缩小数据范围。
5. Java基础知识
5.1 解释下什么是双亲委托模型?
答:类在加载时,系统会判断当前类是否已加载,如果已加载则直接返回,如果未加载则尝试加载,在加载时,当前系统会把类加载任务委托给其父类loadClass方法进行处理,整个过程是一个递归处理的过程,最终都会交给顶层BootstrapClassLoader 加载器来加载类,之前父类无法加载相应类时才交给下一层子类来加载。
5.2 为什么要用这种方式来加载类呢?
答:利用这种方式保证Java核心类正确加载,防止用户私自篡改Java核心类。
5.3 有办法打破这种委托加载模型吗?
答:有的,
- 自己定义一个类加载器,重写里面的loadClass()方法。
- 在用户线程里面调用java.lang.Thread类的setContext-ClassLoader()方法,利用线程上下文类加载器来加载类。
- OSGi自定义了类加载器,当需要动态地更换一个模块的时候,就把模块连通这个模块的类加载器一起替换,从而实现了热替换
5.4 Java反射是什么含义?有哪些应用场景?
答:在运行时,任何一个类都能知道自身所有的属性和方法,将相应的字节码映射为可执行的方法和可访问的属性。应用场景有:开发通用框架、动态代理、自定义注解。
5.5 currenthashmap底层实现
答:JDK 1.7版本currenthashmap是通过分段的数组+链表实现的,整个数组分为16个段,段继承自Retrantlock,实现多线程之间修改的互斥,利用分段锁提高并发度。JDK1.8 修改了currenthashmap的底层实现,使用node数组+链表,并结合Synchronized 和CAS来保证线程安全。
5.6 CAS是什么?
答:CAS是 compare and set的缩写,是一种无锁算法,可以在不加锁的情况下实现线程间同步,不会使线程阻塞。CAS涉及到三个操作,需要操作的内存V,要比较的值A,要设置的值B,当且仅当V处的值等于A时,才将V处设置为新值B,失败后通过自旋来重试。
5.7 CAS有什么问题呢?
答:
- ABA问题。
- 自旋消耗CPU资源。
- 只能保证单个变量操作的原子性,无法保证多个变量操作的原子性。
5.8 CAS底层是如何实现的?
答:有两种方式:锁总线和锁内存
-
相关阅读:
SpringBoot整合Redis数据库-小白也能轻松上手-自带云Redis数据库
网络安全运维流量攻击分析需要掌握的核心能力有什么
JVM内部结构图及各模块运行机制总结
js——高阶函数、闭包、递归以及浅拷贝和深拷贝
Flutter项目开发模版,开箱即用
来围观 WasmEdge 7月社区会议都说了些啥
css第八课:文本属性(字体,颜色属性)
[NPUCTF2020]Mersenne twister
【洛谷】P2082 区间覆盖(加强版)
Java的JDBC编程
- 原文地址:https://blog.csdn.net/yums467/article/details/125392715