-
推荐系统之BRP
1: 通过import_module函数获取数据集
dataset_module = importlib.import_module('rec.data.dataset')- 1

2:加载数据self._load_data(self.dataset_name, self.dataset_path)- 1
首先加载交互功能数据。
self._load_inter_feat(token, dataset_path)- 1
将数据集名称和数据集拼接在一起。
inter_feat_path = os.path.join(dataset_path, f'{token}.inter')- 1


在inter数据集合中的数据形式:
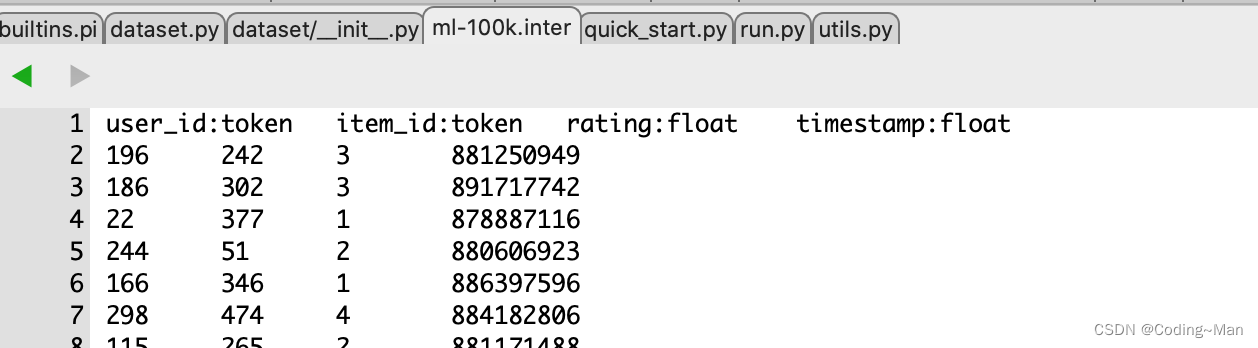
用pandas 读取数据inter_feat = self._load_feat(inter_feat_path, FeatureSource.INTERACTION)- 1
with open(filepath, 'r') as f: #读数据真正的开始 head = f.readline()[:-1]- 1
- 2

根据转义字符“\t"将head中的数据名称和数据类型分别存储在数组中。for field_type in head.split(field_separator): field, ftype = field_type.split(':')- 1
- 2
columns.append(field) usecols.append(field_type)- 1
- 2

用Pandas 读取 CSV数据df = pd.read_csv(filepath, delimiter=self.config['field_separator'], usecols=usecols, dtype=dtype)- 1
读完的数据,为数据加上索引:
如下图所示:

3:数据处理(删除操作)
过滤 掉 缺失user_id 和 item_id
def _filter_nan_user_or_item(self):- 1
for field, name in zip([self.uid_field, self.iid_field], ['user', 'item']): feat = getattr(self, name + '_feat')- 1
- 2
获取user或者item所在的一行的值为空,则将所在一行的删除。
dropped_feat = feat.index[feat[field].isnull()] feat.drop(feat.index[dropped_feat], inplace=True) self.inter_feat.drop(self.inter_feat.index[dropped_inter], inplace=True)- 1
- 2
- 3
删除重复的行数
self._remove_duplication()- 1
根据特征值过滤特征
def _filter_by_field_value(self):- 1
删除 inter_feat 中用户或项目不在 user_feat 或 item_feat 中的交互。
def _filter_inter_by_user_or_item(self):- 1
对处理后的数据进行索引重置,在这里数据的处理,主要指的是删除各种不符合条件的数据值。
def _reset_index(self): feat.reset_index(drop=True, inplace=True)- 1
- 2
- 3
4:数据处理二
从新索引ID,为每个ID从新索引。def _remap_ID_all(self):- 1
new_ids_list, mp = pd.factorize(tokens)- 1
这里的token是userID。

之后用新生成的new_ids_list替换tokens 所在的一列if ftype == FeatureType.TOKEN: feat[field] = new_ids- 1
- 2
缺失值操作
def _fill_nan(self):- 1
缺失值插补:将缺失插入0或者是所在列的平均数
if ftype == FeatureType.TOKEN: feat[field].fillna(value=0, inplace=True) elif ftype == FeatureType.FLOAT: feat[field].fillna(value=feat[field].mean(), inplace=True)- 1
- 2
- 3
- 4
正则化float类型的值
if ftype == FeatureType.FLOAT: lst = feat[field].values mx, mn = max(lst), min(lst) feat[field] = (lst - mn) / (mx - mn)- 1
- 2
- 3
- 4


5:将数据分为训练集,验证集和测试集排序和拆分方法有下面几种:
RO:随机排序
TO:时间顺序
RS:split_ratio 通过比例分割
LS:leave_one_num
RO_RS:
RO_LS:
TO_RS:
TO_LS:train_data, valid_data, test_data = data_preparation(config, dataset)- 1
pairwise思想是将正负实体样本的分数拉开。
6:模型训练 -
相关阅读:
SpringMVC学习笔记(十一)—— 拦截器
[Java]注释——注释真的需要么?
mmdet3D中文注释
Splay
【复现】蓝凌OA SQL注入漏洞_61
Kotlin高仿微信-第28篇-朋友圈-预览图片、预览小视频
php 对接IronSource海外广告平台收益接口Reporting API
金仓数据库KingbaseES客户端应用参考手册--3. createdb
MyBatisplus使用报错--Invalid bound statement
API First——微服务架构下API接口驱动设计与开发
- 原文地址:https://blog.csdn.net/qq_40341502/article/details/125118903