论文信息
论文标题:Rumor Detection on Social Media with Graph AdversarialContrastive Learning 论文作者:Tiening Sun、Zhong Qian、Sujun Dong 论文来源:2022, WWW 论文地址:download 论文代码:download
Abstract 尽管基于GNN的方法在谣言检测领域取得了一些成功,但是这些基于交叉熵损失的方法常常导致泛化能力差,并且缺乏对一些带有噪声的或者对抗性的样本的鲁棒性,尤其是一些恶意谣言。有时,仅仅设置一个简单的扰动就会导致标签被高度置信地错误分类,这对谣言分类系统无疑是一个巨大的潜在危害。因此,现有的数据驱动模型需要变得更加健壮,以应对通常由正常用户无意识地产生和传播的错误信息或者由谣言制造者恶意设计的混乱对话结构。
在本文中,我们提出了一种新的图对抗对比学习(GACL)方法来对抗这些复杂的情况,其中引入对比学习作为损失函数的一部分,用于明确感知同类和不同类的会话线程之间的差异。同时,设计了一个对抗性特征变换(AFT)模块来产生相互冲突的样本,以加压模型以挖掘事件不变的特征。这些对抗性样本也被用作对比学习的硬负样本,使模型更鲁棒和有效。在三个公共基准数据集上的实验结果表明,我们的 GACL 方法比其他最先进的模型取得了更好的结果。
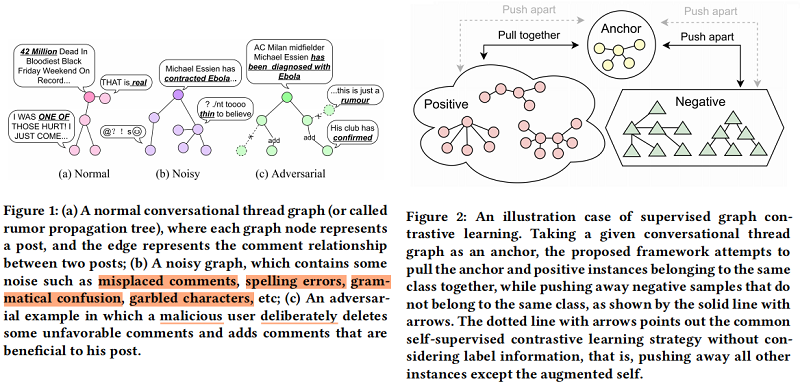
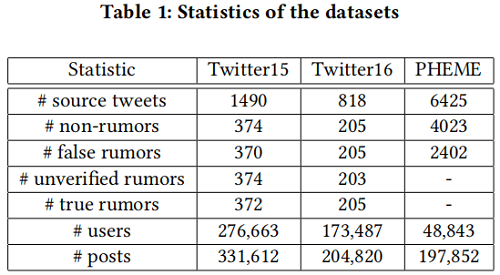
1 Introduction 本文提出一个图对抗对比学习(GACL)方法谣言检测。具体来说,首先采用 edge perturbation 和 dropout 等图数据增强策略掩模来模拟 Figure 1(b) 的情况,它为模型提供了丰富噪声的输入数据。然后,我们引入 Figure 2 所示的监督图对比学习 来训练 GNN 编码器 明确地感知增强数据的差异,并学习鲁棒表示。与自监督对比学习策略不同,本文的方法可以更有效地利用标签信息。这样,就可以防止在一些包含噪声的情况下,如错误的注释和混乱的字符被检测模型错误地分类。
有时,仅凭这一点是不够的。因为在现实世界中,除了由普通用户无意中创造和传播的错误信息外,还有一些由谣言生产者精心设计和故意推广的恶意谣言,如 Figure 1(c) 所示,这可能会使该模型失效。一些研究人员也注意到了这个问题。Ma等人[21]分析了一个关于“沙特阿拉伯斩首第一个女性机器人公民”的谣言案例,以说明谣言机器人如何使用高频和指示性词汇来掩盖事实。Yang等人 [32] 还提到,谣言生产者经常操纵由用户、消息来源和评论组成的关系网络,以逃避检测。无论是文本篡改还是网络操纵,谣言制作者的目的都是使谣言在高维空间中接近非谣言样本,从而混淆模型。因此,为了解决这个问题,我们开发了一个对抗性特征转换(AFT)模块,旨在利用对抗性训练来生成具有挑战性的特征。这些对抗性特征将作为对比学习中的硬负样本,帮助模型加强对这些困难样本的特征学习,实现鲁棒性和有效的检测。此外,我们直观地相信,这些对抗性的特征可以被解码成各种不同类型的扰动。
本文贡献:
据我们所知,这是第一个将对比学习引入谣言检测任务的研究,旨在通过感知同一标签和不同标签样本之间的差异来提高表征质量。 我们提出了GACL模型,它不仅考虑了谣言的传播结构信息,还模拟了噪声和对抗性情况,并利用对比学习捕获了事件不变特征。 在GACL框架下,我们开发了AFT模块来生成对抗性特征,这些特征作为对比学习中的硬负样本,以学习更鲁棒的表示。 我们通过实验证明,我们的模型在真实世界的数据集上优于最先进的基线。
2 Method 2.1 Definition 本文将谣言检测定义为一种分类任务,其目的是从一组带标签的训练事件中学习一个分类器, 然后用它来预测测试事件的标签。使用 C = { c 1 , c 2 , ⋯ , c n } C = { c 1 , c 2 , ⋯ , c n } C = { c 1 , c 2 , ⋯ , c n } c i c i c i i " role="presentation">i i n " role="presentation">n n c = ( y , G ) " role="presentation">c = ( y , G ) c = ( y , G ) y ∈ { R , N } " role="presentation">y ∈ { R , N } y ∈ { R , N } G = ( V , E ) " role="presentation">G = ( V , E ) G = ( V , E ) V " role="presentation">V V E " role="presentation">E E y ∈ { N , F , T , U } " role="presentation">y ∈ { N , F , T , U } y ∈ { N , F , T , U } G ^ G ^ G ^ G " role="presentation">G G f ( ⋅ ) " role="presentation">f ( ⋅ ) f ( ⋅ ) G " role="presentation">G G c i c i c i
2.2 Framework
2.3 Graph Data Augmentation GACL采用 Edge perturbation 策略进行数据增强。对于一个图 G = ( V , E ) " role="presentation">G = ( V , E ) G = ( V , E ) A " role="presentation">A A X " role="presentation">X X r " role="presentation">r r G " role="presentation">G G G ^ ′ G ^ ′ G ^ ′ A perturbation A perturbation A perturbation G ^ G ^ G ^ A ′ A ′ A ′
此外,对于谣言检测任务,上图中由 p o s t " role="presentation">p o s t p o s t
2.4 Graph Representation 本文使用 BERT 来获取事件的原文和评论的句子表示,以构建新的 X " role="presentation">X X
本文使用一个两层 G C N G C N G C N G k G k G k G ^ k G ^ k G ^ k G C N G C N G C N H k ( 2 ) H ( 2 ) k H k ( 2 )
h k = M E A N ( H k ( 2 ) ) h k = M E A N ( H ( 2 ) k ) h k = M E A N ( H k ( 2 ) )
2.5 AFT Component 即使 AFT module 不存在,由 GCN 生成的图表示 h " role="presentation">h h s o f t m a x " role="presentation">s o f t m a x s o f t m a x
如 Figure 3 所示,AFT 由 L = 2 " role="presentation">L = 2 L = 2 h k h k h k z k z k z k
z k = D N ( max ( 0 , h k W 1 A F T + b 1 ) W 2 A F T + b 2 ) z k = D N ( max ( 0 , h k W A F T 1 + b 1 ) W A F T 2 + b 2 ) z k = D N ( max ( 0 , h k W 1 A F T + b 1 ) W 2 A F T + b 2 )
将得到的 z k z k z k
现在,对于 batch 中的每一个 post,我们得到了 GCN 编码的相应图表示 h k h k h k z k z k z k
m k = concat ( h k , z k ) m k = concat ( h k , z k ) m k = concat ( h k , z k )
接下来,将 m k m k m k
y ^ k = softmax ( W k F m k + b k F ) y ^ k = softmax ( W F k m k + b F k ) y ^ k = softmax ( W k F m k + b k F )
其中,y ^ ∈ R 1 × C y ^ ∈ R 1 × C y ^ ∈ R 1 × C W F W F W F b F b F b F
2.6 Adversarial Contrastive Learning 本文采用的损失函数旨在给定标签信息的条件下最大化正样本之间的一致性同时拉远负样本。 如 Figure 3 ,以 m k m k m k m k m k m k m p m p m p m k m k m k m a m a m a
L = L c e + α L s u p L = L c e + α L s u p L = L c e + α L s u p
这两部分损失分别是:
L c e = − 1 N ∑ N ∑ M y k , c log ( y ^ k , c ) L c e = − 1 N ∑ N ∑ M y k , c log ( y ^ k , c ) L c e = − 1 N ∑ N ∑ M y k , c log ( y ^ k , c )
L s u p = − ∑ k ∈ K log { 1 | P ( k ) | ∑ p ∈ P ( k ) exp ( sim ( m k , m p ) τ ) ∑ a ∈ A ( k ) exp ( sim ( m k , m a ) τ ) } L s u p = − ∑ k ∈ K log { 1 | P ( k ) | ∑ p ∈ P ( k ) exp ( sim ( m k , m p ) τ ) ∑ a ∈ A ( k ) exp ( sim ( m k , m a ) τ ) } L s u p = − ∑ k ∈ K log { 1 | P ( k ) | ∑ p ∈ P ( k ) exp ( sim ( m k , m p ) τ ) ∑ a ∈ A ( k ) exp ( sim ( m k , m a ) τ ) }
k " role="presentation">k k c " role="presentation">c c A ( k ) = { a ∈ K : y a ≠ y k } A ( k ) = { a ∈ K : y a ≠ y k } A ( k ) = { a ∈ K : y a ≠ y k } P ( k ) = { p ∈ K : y p = y k } P ( k ) = { p ∈ K : y p = y k } P ( k ) = { p ∈ K : y p = y k } sim ( ⋅ ) " role="presentation">sim ( ⋅ ) sim ( ⋅ ) sim ( m k , m p ) = m k T m p / ‖ m k ‖ ‖ m p ‖ sim ( m k , m p ) = m T k m p / ∥ m k ∥ ∥ m p ∥ sim ( m k , m p ) = m k T m p / ‖ m k ‖ ‖ m p ‖ τ ∈ R † τ ∈ R † τ ∈ R †
一部分研究表明BERT驱动的句子表示容易造成坍塌现象,这是由于句子的语义信息由高频词主导。在谣言检测中,高频词经常被谣言制造者利用来逃避检测。因此采用对比学习的方式能够 平滑化句子的语义信息,并且理论上能够增加低频但重要的词的权重。本文通过最小化 L L L
AFT 基于对抗学习单独训练。模型中 AFT 的参数记作 θ a θ a θ a θ s θ s θ s L L L θ s θ s θ s
3 Experiment Datasets
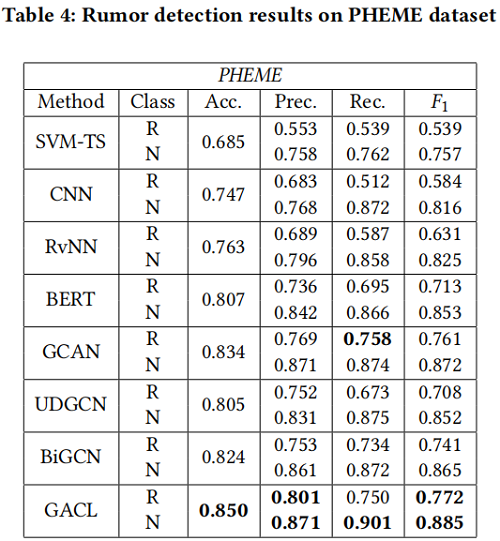
Results
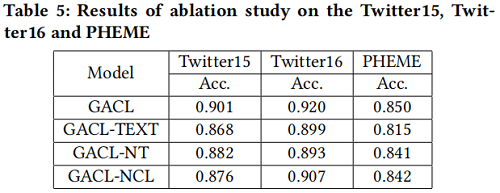
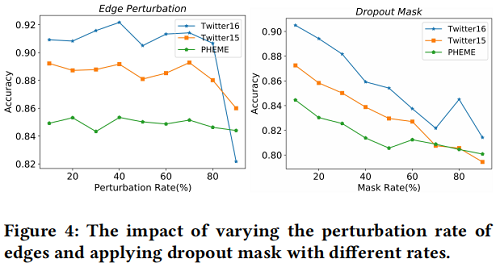
Ablation study
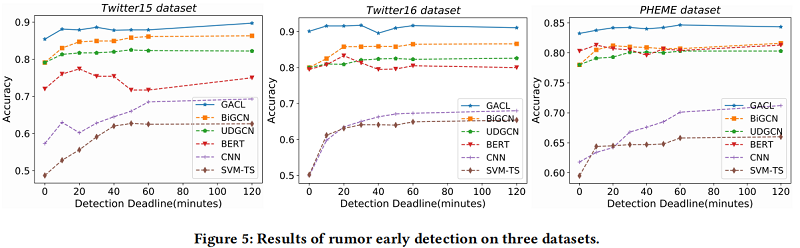
Early Rumor Detection
4 Conclusion 本文提出了一种新的谣言检测模型,即GACL。首先,采用训练前模型BERT获得GACL中每个帖子的表示,然后使用GCN对谣言传播的结构信息进行编码。其次,引入对比学习,通过捕获同一类实例之间的共性和不同类实例之间的差异来提高表示的质量。最后,将AFT模块加载到模型中,采用对抗性学习策略进行训练,以生成对抗性特征。这些对抗性特征在对比学习中作为硬负样本,并在训练阶段作为输入向量的一部分输入到softmax模块中,有利于捕获事件不变特征。实验结果表明,我们的GACL方法对三个公共真实数据集的谣言检测具有良好的有效性和鲁棒性,并且在早期谣言检测任务中显著优于其他最先进的模型。
我们未来的工作将集中于多模态信息的融合和提取、偏见检测和模型决策的可解释性。
__EOF__
-
本文作者: Blair 本文链接: https://www.cnblogs.com/BlairGrowing/p/16737902.html 关于博主: I am a good person 版权声明: 本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处! 声援博主: 如果您觉得文章对您有帮助,可以点击文章右下角【推荐 】