-
【进程和线程】
目录
用户态(user space) 和 内核态(kernel space)
进程通信IPC(Inter Process Communication)
(2)进程(process) 和线程(thread) 的关系
(4)获取当前线程引用——Thread.currentThread()
进程的五大状态
- 新建:进程处于正在创建中
- 就绪:万物具备,只欠CPU
- 运行:进程的指令真正在CPU运行着
- 阻塞:进程由于等待外部条件,所以暂时无法继续
- 结束:进程的所有指令执行结束,但PCB暂时保留,OS还需要做一些其他工作的时候
进程状态转移图:
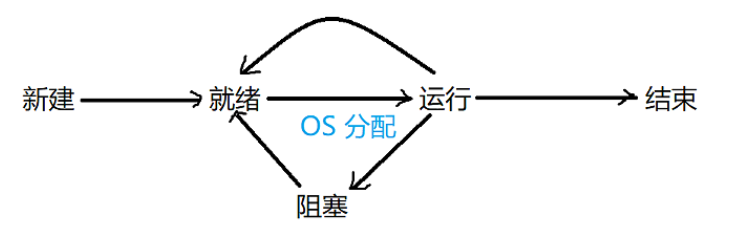
所有运行状态必须是从就绪状态变过去的,因为进程的CPU必须经过OS系统分配才能得到。
进程状态如何转移
- ->新建 : 随着程序的启动运行
- 新建->就绪 : 进程的初始化工作完全完成,这个工作是由OS的指令完成的
- 就绪->运行 : 进程被OS选中,并分配了CPU之后
- 运行->结束 : 进程的最后一条指令执行结束,可粗略地理解为就是main方法执行结束了
- 运行->就绪 : 1.被高优先级的进程抢占了;2. 时间片耗尽;3. 进程可以执行一些OS提供的系统调用,主动放弃
- 运行->阻塞:等待一些外部条件,如等待I0设备;进程休眠一段时间等
- 阻塞->就绪 : 外部条件满足,如 I0数据来了、休眠时间到了...
- 结束-> : 进程PCB彻底被OS回收了
在同一时刻,处于不同状态下的进程不止一个。处于新建、就绪、堵塞、结束状态的可以有多个,但单核cpu情况下,同一时刻运行状态的只能有一个。
OS具体怎样进行进程切换
通过上下文切换:保护上一个进程的上下文 + 恢复下一个进程的上下文
上下文:以PC寄存器所代表的一组寄存器中的值。
保护上下文:把寄存器中的值,保存到内存的某个位置。 恢复上下文:把内存中之前保护的值,写入寄存器中
并行(parallel) 和 并发(concurrent)
并行:进程真的同时在执行,既微观角度的同一时刻,是有多个指令在执行的,所以只会在多CPU多核场景下
并发:进程假的同时在执行,微观上,表现为一次只执行一个进程,但宏观上,多个进程在“同时"执行
用户态(user space) 和 内核态(kernel space)
当CPU正在执行的是OS的指令时,就认为进入到内核态。反之,正在执行的是普通进程的指令时,就在用户态。 内核态的指令权限高,基本上所有的硬件都能访问;用户态的指令权限低,只能访问OS规定的资源。这是因为CPU本身就有权限开关。 一般来说,用户态的性能较好,内核态的性能较差。
执行流(executionflow)
各执行流拥有独立pc的一套指令,不同的执行流从现象上看起来是完全独立的。
内存管理
和cpu不同,cpu更注重在时间上的划分,而操作系统对内存资源的分配,采用的是空间模式 —— 不同进程使用内存中的不同区域,互相之间不会干扰。
内存大体分为:内核使用的内存、分配给普通进程使用的内存、空闲空间。要注意空间划分不保证是连续的。
内存管理主要研究的问题
- 管理哪些内存已经被分配,哪些内存暂时末被分配
- 已经分配出去的内存,何时进行回收、如何进行回收
- 物理地址和线性地址转换
- 内存碎片
进程通信IPC(Inter Process Communication)
理论上进程是独立的,但实际中往往是多个进程相互配合,来完成复杂的工作。因为OS进行资源分配是以进程为基本单位分配的,包括内存。分配给A进程的内存不会分配给B进程。所以,进程A、B之间直接通过内存来进行数据交换的可能性完全不存在了。所以OS需要提供一套机制, 用于让A、B进程之间进行必要的数据交换一进程间通信。
进程间通信的常见方式
- 管道(pipe)
- 消息队列(message queue)
- 信号量(semaphore)
- 信号(signal)
- 共享内存(shared memory)
- 网络(network)
线程(Thread)
概念
(1)什么是线程
线程是OS进行调度(分配CPU)的基本单位。一个线程就是一个 "执行流". 每个线程之间都可以按照顺讯执行自己的代码. 多个线程之间 "同时" 执行着 多份代码.
(2)进程(process) 和线程(thread) 的关系
进程和线程是一对多的关系的关系。一个线程一定属于一个进程;一个进程下可以允许有多个线程。
一个进程内至少有一个线程, 通常被这个一开始就存在的线程,称为主线程(main thread)。主线程和其他线程之间地位是完全相等的,没有任何特殊性。(3)为什么OS要引入thread这一个概念。
由于进程这一个概念天生就是资源隔离的,所以进程之间进行数据通信注定是一个高成本的工作。
现实中,一个任务需要多个执行流一起配合完成,是非常常见的。所以,需要一种方便数据通信的执行流概念出来,线程就承担了这一职责。(4)线程和进程的区别
- 进程是资源分配的最小单位,线程是程序执行的最小单位(资源调度的最小单位)
- 进程是包含线程的, 每个进程至少有一个线程存在,即主线程。
- 进程有自己的独立地址空间,每启动一个进程,系统就会为它分配地址空间,建立数据表来维护代码段、堆栈段和数据段,这种操作非常昂贵。而线程是共享进程中的数据的,使用相同的地址空间,因此CPU切换一个线程的花费远比进程要小很多,同时创建一个线程的开销也比进程要小很多。
- 进程和进程之间不共享内存空间.,同一个进程的线程之间共享同一个内存空间。线程之间的通信更方便,同一进程下的线程共享全局变量、静态变量等数据,而进程之间的通信需要以通信的方式(IPC)进行。
- 多进程程序更健壮,多线程程序只要有一个线程死掉,整个进程也死掉了,而一个进程死掉并不会对另外一个进程造成影响,因为进程有自己独立的地址空间。
线程的创建
方法一:继承 Thread 类
自定义线程类继承Thread类
重写run()方法,编写线程执行体
创建线程对象,调用start()方法启动线程- public class MyThread extends Thread{
- @Override
- public void run() {
- for (int i = 0; i < 200; i++) {
- System.out.println("good"+i);
- }
- }
- public static void main(String[] args) {
- //主线程
- MyThread myThread = new MyThread();
- //同时执行,主线程和上面的线程是同时执行的
- myThread.start();
- for (int i = 0; i < 200; i++) {
- System.out.println("我在学习"+i);
- }
- }
- }
运行结果:

可以看到主线程和上面的线程是同时执行的。
方法二: 实现 Runnable 接口
定义MyRunnable类实现Runnable接口
实现run()方法,编写线程执行体
创建线程对象
创建Thread类对象,将 Runnable 对象作为参数,调用start()方法- public class MyThread_II implements Runnable{
- @Override
- public void run() {
- for (int i = 0; i < 200; i++) {
- System.out.println("good"+i);
- }
- }
- public static void main(String[] args) {
- //创建runnable接口的实现类对象
- MyThread_II myThread = new MyThread_II();
- //创建线程对象,通过线程对象开启线程(代理)
- Thread thread = new Thread(myThread);
- //Thread thread = new Thread(new MyThread_II());
- thread.start();
- }
- }
对比上面两种方法:
- 继承 Thread 类,直接使用 this 就表示当前线程对象的引用。
- 实现 Runnable 接口,this 表示的是 MyRunnable 的引用,需要使用 Thread.currentThread()
怎么去理解t.start()做了什么?
t.start()只做了一件事情:把线程的状态从新建变成了就绪。也就是说它不负责分配CPU。
线程把加入到线程调度器的就绪队列中,等待被调度器选中分配CPU。从子线程进入到就绪队列这一刻起,子线程和主线程在地位上就完全平等了。
所以,哪个线程被选中去分配CPU,就完全听天由命了。先执行子线程中的语句还是主线程中的语句理论上都是可能的。这就是为什么我们看到主线程和自定义的线程交替执行。
观察我们创建的第一个线程结果,大概率是主线程中的打印先执行,不是说两个线程地位平等吗?
t.start()是在主线程的语句。换言之,这条语句被执行了,说明主线程现在正在CPU上。(主线程运行状态),所以,主线程刚刚执行完t.start() 就马上发生线程调度的概率不大,因此大概率还是t.start()的下一条语句就先执行了。
区分 start() 和 run()
不要错误使用成 run() 方法,使用这个方法会被最先执行,而且在主线程使用,就是一个简单的方法调用。
使用 start():
- public class MyThread extends Thread{
- @Override
- public void run() {
- System.out.println("我是"+Thread.currentThread().getName());
- }
- public static void main(String[] args) {
- MyThread myThread = new MyThread();
- myThread.start();
- //主线程
- System.out.println("我是"+Thread.currentThread().getName());
- }
- }
- //输出:
- 我是main
- 我是Thread-0
使用run():
- public class MyThread extends Thread{
- @Override
- public void run() {
- System.out.println("我是"+Thread.currentThread().getName());
- }
- public static void main(String[] args) {
- MyThread myThread = new MyThread();
- myThread.run();
- //主线程
- System.out.println("我是"+Thread.currentThread().getName());
- }
- }
- //输出:
- 我是main
- 我是main
我们写的无论是Thread的子类还是Runnable的实现类,只是给线程启动的“程序”。所以,同一个程序,可以启动多个线程。
示例:
- public class MyThread extends Thread{
- @Override
- public void run() {
- System.out.println("我是" + Thread.currentThread().getName());
- System.out.println("我的id是" + Thread.currentThread().getId());
- }
- public static void main(String[] args) {
- MyThread t1 = new MyThread();
- t1.start();
- MyThread t2 = new MyThread();
- t2.start();
- MyThread t3 = new MyThread();
- t3.start();
- MyThread t4= new MyThread();
- t4.start();
- }
- }
输出:

注意:每次输出的结果不是固定的哦
线程和方法调用栈的关系
每个线程都有自己独立的调用栈
- public class Add {
- public static int add(int a,int b){
- return a + b;
- }
- }
- public class MyThread extends Thread{
- @Override
- public void run() {
- System.out.println(Add.add(5,5));
- }
- }
- public class Main {
- public static void main(String[] args) {
- MyThread t = new MyThread();
- t.start();
- // 自己在主线程中也去调用 add 方法
- System.out.println(Add.add(10, 20));
- }
- }
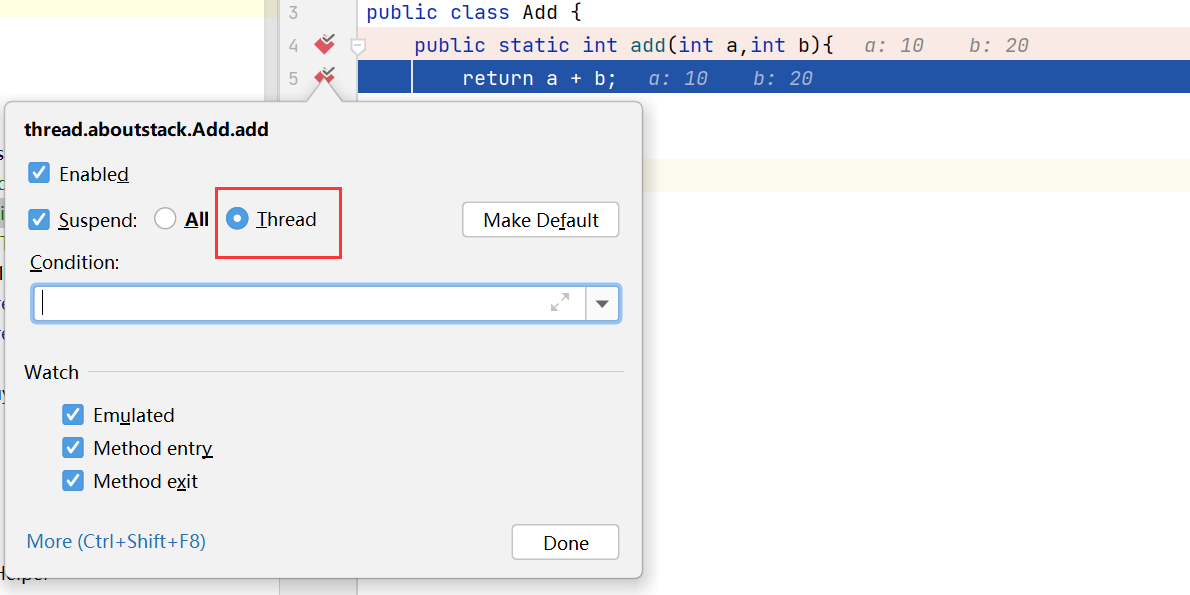
打上断点,右键选择 Thread。调试器中看到的方法调用栈每一行都是一个栈帧(frame),保存的就是运行方法时的临时数据,对于我们来说最主要的就是局部变量。

由于每个线程都是独立的执行流,A在调用过哪些方法,和B根本就没关系。表现为每个线程都有自己的独立的栈。上面是主线程的,下拉框可以选择别的线程
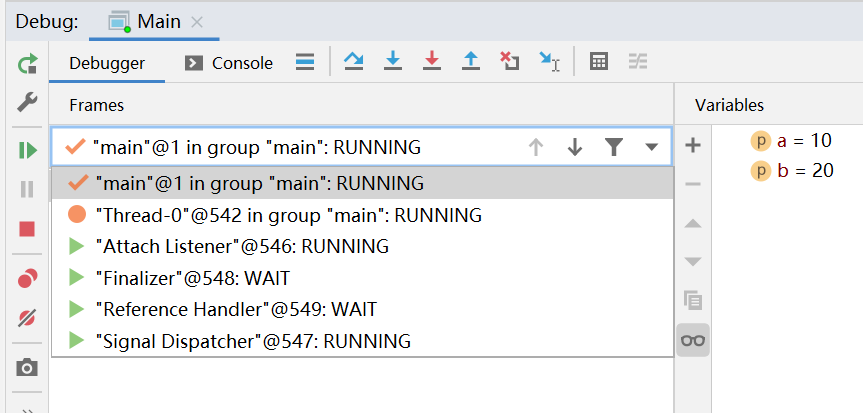

根据程序=指令+数据,此处我们调用的是同一个方法,说明执行的是同一批指令——把两个数相加并返回
因为栈不同(帧不同) :说明执行指令时,要处理的数据是不同。所以就可独立的对主线程和子线程,进行调试,二者互不影响。理解栈和栈帧
在没有多线程和外部输入的情况下,程序的运行其实就是一个状态机

在函数调用过程中,会产生新的状态,最后返回的结果依然是最初的状态,只是数据发生了变化
如果发生了多次嵌套调用,像下面这样:
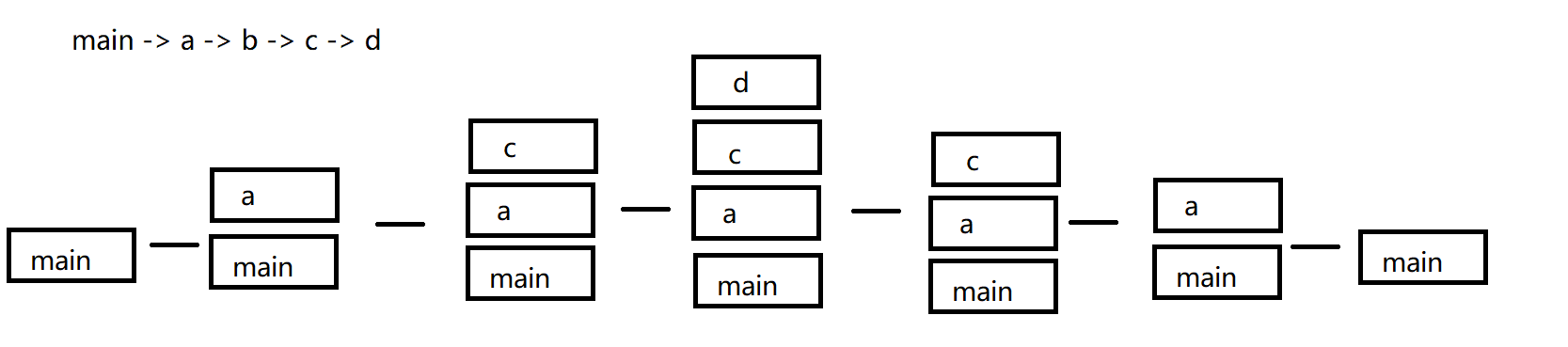 可以看到,这些框出现的顺序是 先进后出 因此,我们就可以使用栈去维护这些框。
可以看到,这些框出现的顺序是 先进后出 因此,我们就可以使用栈去维护这些框。
栈:当前执行流的当前时刻(时间停止状态时)的状态框有哪些(现实方法的调用次序)
框:栈帧(frame)装的就是运行该方法时需要的一些临时数据(主要就是具备变量)Thread的常见属性和方法
(1)常见属性
属性 获取方法 ID getId() 名称(name) getName() 状态 getState() 优先级 getPriority()
是否后台线程 isDaemon() 是否存活 isAlive() 是否被中断 isInterrupted() - 本进程(JVM进程)内部分配的唯一的,只能 get不能set
- 默认情况下,如果没有给线程名字,线程名字遵守Thread-..;第一个是Thread-0、Thread-1、 Thread-2,主线程默认为 main。可以get也可以set,也可以是重复的
- 状态表示线程当前所处的一个情况
- 优先级高的线程理论上来说更容易被调度到。线程也可以set自己的优先级,但是要注意,优先级的设置,只是给JVM一些建议,不能强制让哪个线程先被调度。优先级最低为 1 ,最高为 10,默认为 5
- 关于后台线程,需要记住一点:JVM会在一个进程的所有非后台线程结束后,才会结束运行。
- 是否存活,即简单的理解,为 run 方法是否运行结束了 线程的中断问题
设置name:
- public class SetNameThread extends Thread{
- //方法一
- // public SetNameThread(){
- // setName("我是张三");
- // }
- //方法二
- // public SetNameThread() {
- // super("我是张三"); // 调用父类(Thread)的构造方法
- // }
- @Override
- public void run() {
- System.out.println(this.getName());
- }
- public static void main(String[] args) {
- System.out.println(Thread.currentThread().getName());
- SetNameThread t1 = new SetNameThread();
- //方法三
- t1.setName("我是t1");
- t1.start();
- SetNameThread t2 = new SetNameThread();
- t2.setName("我是t2");
- t2.start();
- }
- }
或者也可以创建有参构造来设置名字:
- public class SetNameThread extends Thread{
- public SetNameThread(String name){
- super(name);
- }
- @Override
- public void run() {
- System.out.println(this.getName());
- }
- public static void main(String[] args) {
- System.out.println(Thread.currentThread().getName());
- SetNameThread t1 = new SetNameThread("我是t1");
- t1.start();
- SetNameThread t2 = new SetNameThread("我是t2");
- t2.start();
- }
- }
上面的方法一、二是该类将线程的名字全都设置为一致的。
(2)等待一个线程-join()
有时,我们需要等待一个线程完成它的工作后,才能进行自己的下一步工作。例如,A到饭店吃饭,发现没带钱包,于是让B回家拿钱包,那么A就必须等B把钱包拿来之后才能结账走人。
- public class Main {
- private static class B extends Thread {
- @Override
- public void run() {
- // 模拟 B 要做很久的工作
- try {
- TimeUnit.SECONDS.sleep(5);
- } catch (InterruptedException e) {
- e.printStackTrace();
- }
- println("B 说:我的任务已经完成");
- }
- }
- private static void println(String msg) {
- Date date = new Date();
- DateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
- System.out.println(format.format(date) + ": " + msg);
- }
- public static void main(String[] args) throws InterruptedException {
- B b = new B();
- b.start();
- println("A 自己先去吃饭");
- b.join();
- println("A 说:B 给我把钱送来了,结账走人");
- }
- }
- //输出:
- 2022-06-21 17:34:46: A 自己先去吃饭
- 2022-06-21 17:34:51: B 说:我的任务已经完成
- 2022-06-21 17:34:51: A 说:B 给我把钱送来了,结账走人
可以发现,一定是等B拿来了钱包之后A还能结账走人。使用b.join(); 后, 目前的线程会阻塞,直到B运行结束才返回,这个时候B一定已经结束了。
同时join方法也有重载形式:
- join(long millis)等待线程死去,但最多等millis毫秒
- join(long millis, int nanos)时间单位更精确
(3)休眠当前线程
- TimeUnit.SECONDS.sleep(秒数);——以秒为单位
- Thread.sleep(秒数);——以毫秒为单位
让线程休眠,就是让当前线程从 运行 -> 阻塞,等待要求时间过去之后,线程从 阻塞 -> 就绪
(4)获取当前线程引用——Thread.currentThread()
- public class Main {
- public static void main(String[] args) {
- Thread thread = Thread.currentThread();
- System.out.println(thread.getName());
- }
- }
- //输出:main
(5)让线程让出CPU——yield( )
让线程从运行状态变为就绪状态
- public class YieldTest extends Thread{
- @Override
- public void run() {
- while (true){
- System.out.println("我是"+Thread.currentThread().getName());
- }
- }
- public static void main(String[] args) {
- YieldTest t1 = new YieldTest();
- t1.setName("张三");
- YieldTest t2 = new YieldTest();
- t2.setName("李四");
- t1.start();
- t2.start();
- }
- }
观察运行结果我们能看到两个线程出现的概率是差不多的,如果这个时候,李四高风亮节,选择让出CPU,让我们看看结果如何
- public void run() {
- while (true){
- System.out.println("我是"+Thread.currentThread().getName());
- if(Thread.currentThread().getName().equals("李四")){
- Thread.yield();
- }
- }
- }
运行之后我们发现,基本上打印的都是张三,但不是完全没有出现李四哦。
yield主要用于执行一些耗时较久 的计算任务时,为让防止计算机处于“卡顿”的现象,时不时的让出一些CPU资源,给OS内的其他进程。
(6)中断一个线程
方法一:deprecate 暴力停止,直接kill掉线程,目前基本上已经不采用了。原因是不知道该线程把工作进行的如何了
方法二:interrupt();A想让B停止,A给B主动发一个信号,B在一段时间里,看到了停止信号之后,就可以主动,把手头的工作做到一个阶段完成,主动退出。
那么B怎样感知到有人让它停止:
- 通过interrupted()方法,检查当前线程是否被终止,true:有人让我们停止false: 没人让我们停止
- B可能正处于休眠状态,JVM的处理方式是,以异常形式,通知B : InterruptedException
要注意,B具体要不要停,什么时候停,怎么停,完全自己做主
线程的状态
- NEW: 安排了工作, 还未开始行动
- RUNNABLE: 可工作的, 又可以分成正在工作中和即将开始工作。
- BLOCKED: 排队等着其他事情
- WAITING: 排队等着其他事情
- TIMED_WAITING: 排队等着其他事情
- TERMINATED: 工作完成了
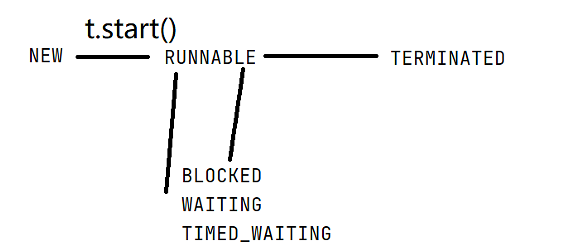
线程状态只能获取,不能设置。
前台线程和后台线程
前台线程一般是做一 -些有交互工作的,后台线程又称精灵线程或者守护线程,一般是做一 些支持工作的线程。
比如:一个音乐播放器1.线程响应用户点击动作(前台)2.线程去网络上下载歌曲(后台)

要注意:当所有的前台线程都退出了,JVM进程就退出了,即使后台线程还在工作,也正常退出
JDK中自带的观察线程的工具——jconsole
该工具可以用来观察JVM运行中的一些相关情况,比如内存、类加载情况、线程情况
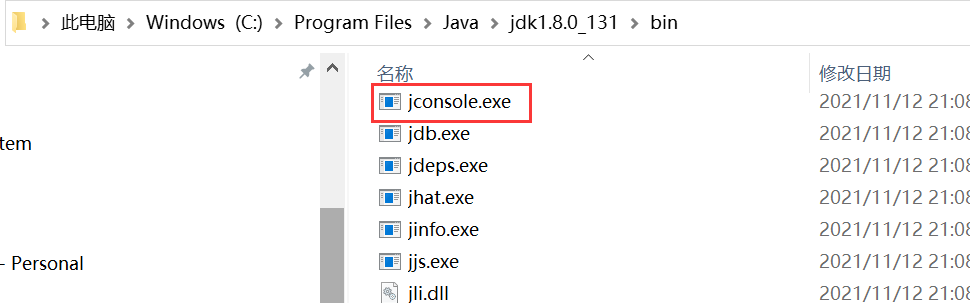
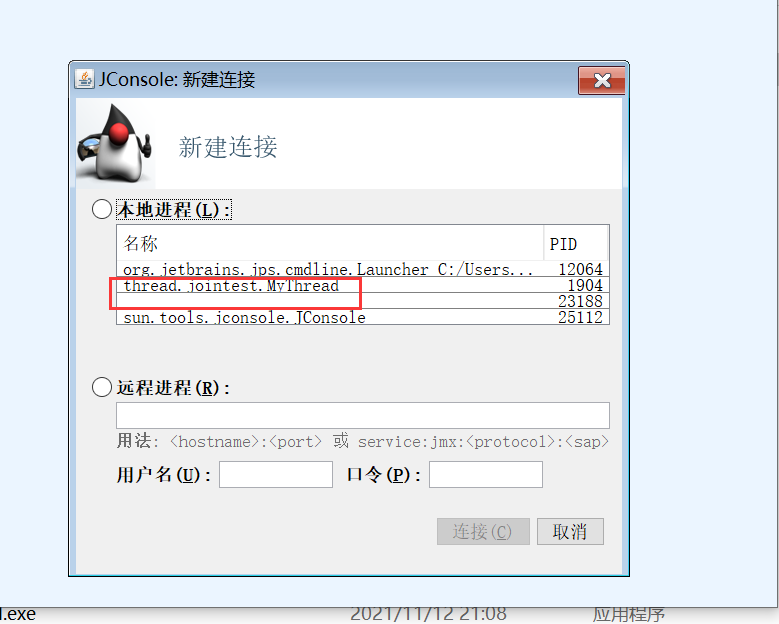
打开后找到idea启动的线程名称,双击进去,就可以观察了。
-
相关阅读:
Golang实现超时机制读取文件
网络请求(四)—Socket
java泛型fastjson阅读泛型解析乱谈一通
【面试高频】Java设计模式-代理模式
分类效果评价(机器学习)
汽车射频之基础
springboot实现支付宝支付功能
策略模式的应用——应对频繁的需求变更
Elasticsearch 分享
【广州华锐互动】VR综合布线虚拟实验教学系统
- 原文地址:https://blog.csdn.net/m0_58672924/article/details/125367471