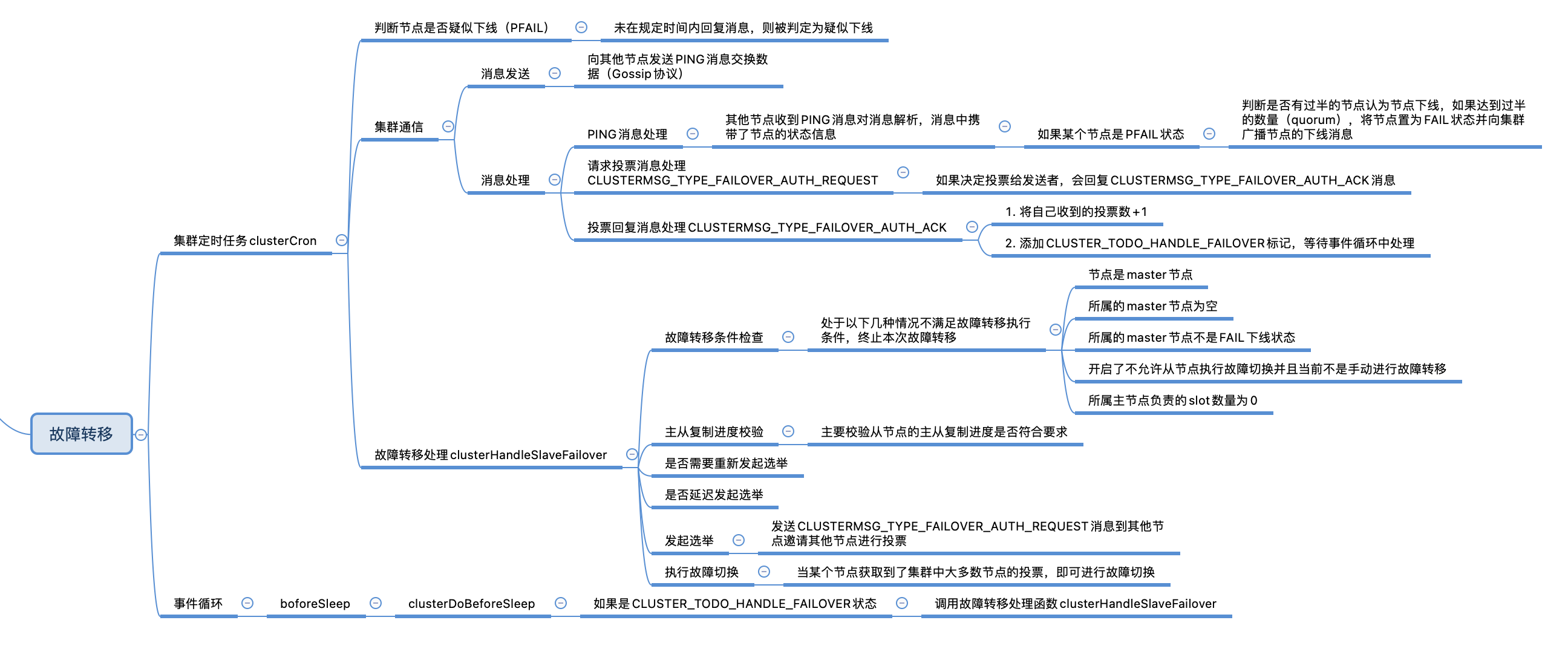
集群故障转移
节点下线
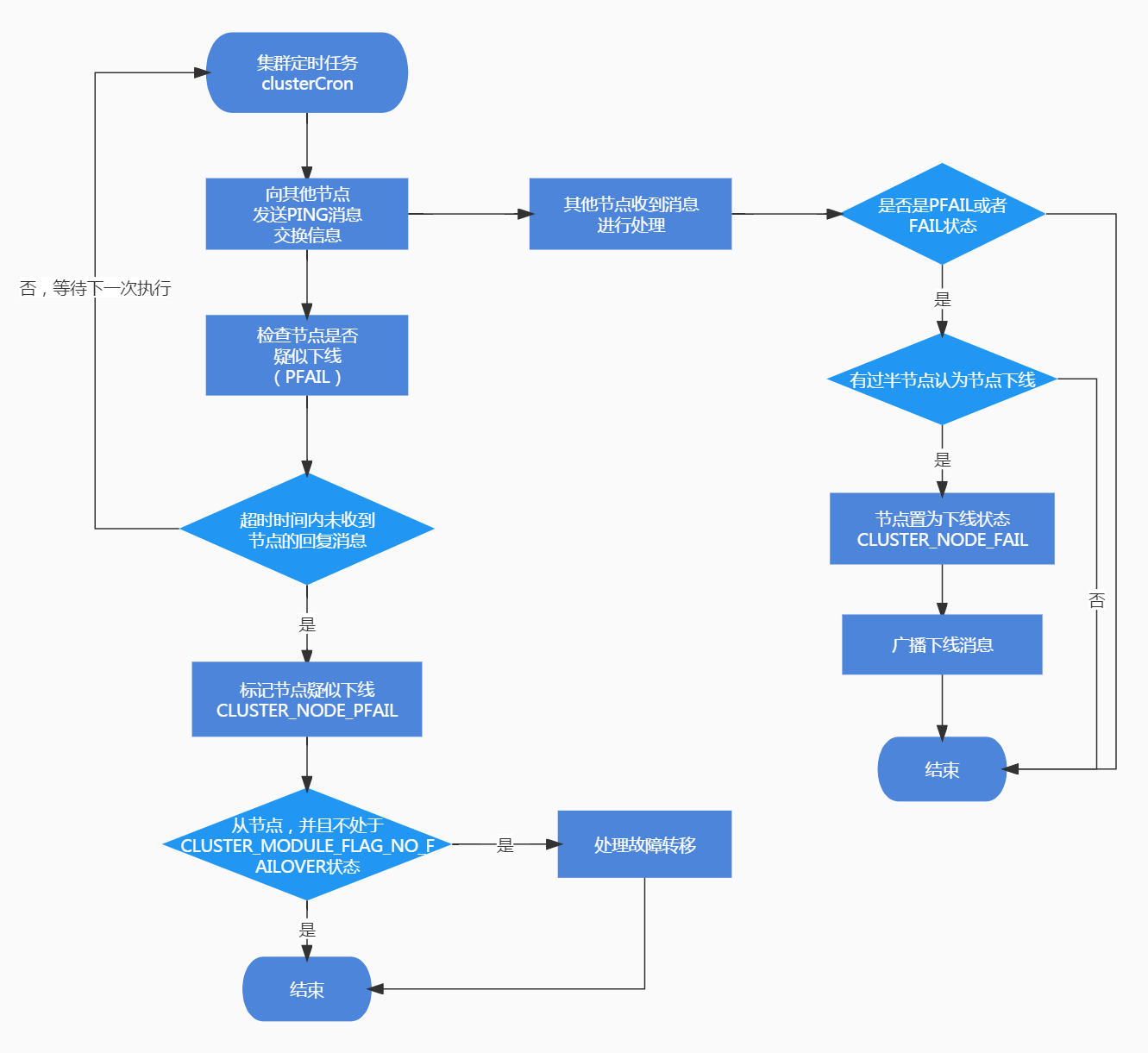
在集群定时任务clusterCron中,会遍历集群中的节点,对每个节点进行检查,判断节点是否下线。与节点下线相关的状态有两个,分别为CLUSTER_NODE_PFAIL和CLUSTER_NODE_FAIL。
CLUSTER_NODE_PFAIL:当前节点认为某个节点下线时,会将节点状态改为CLUSTER_NODE_PFAIL,由于可能存在误判,所以需要根据集群中的其他节点共同决定是否真的将节点标记为下线状态,CLUSTER_NODE_PFAIL可以理解为疑似下线,类似哨兵集群中的主观下线。
CLUSTER_NODE_FAIL:集群中有过半的节点标认为节点已下线,此时将节点置为CLUSTER_NODE_FAIL标记节点下线,CLUSTER_NODE_FAIL表示节点真正处于下线状态,类似哨兵集群的客观下线。
#define CLUSTER_NODE_PFAIL 4 /* 疑似下线,需要根据其他节点的判断决定是否下线,类似主观下线 */
#define CLUSTER_NODE_FAIL 8 /* 节点处于下线状态,类似客观下线 */
疑似下线(PFAIL)
在集群定时任务遍历集群中的节点进行检查时,遍历到的每个节点记为node,当前节点记为myself,检查的内容主要有以下几个方面:
一、判断孤立主节点的个数
如果当前节点myself是从节点,正在遍历的节点node是主节点,并且node节点不处于下线状态,会判断孤立节点的个数,满足以下三个条件时,认定node是孤立节点,孤立节点个数增1:
node的从节点中处于非下线状态的节点个数为0node负责的slot数量大于0,node节点处于CLUSTER_NODE_MIGRATE_TO状态
二、检查连接
这一步主要检查和节点间的连接是否正常,有可能节点处于正常状态,但是连接有问题,此时需要释放连接,在下次执行定时任务时会进行重连,释放连接需要同时满足以下几个条件:
- 与节点
node之间的连接不为空,说明之前进行过连接 - 当前时间距离连接创建的时间超过了超时时间
- 距离向
node发送PING消息的时间已经超过了超时时间的一半 - 距离收到
node节点发送消息的时间超过了超时时间的一半
三、疑似下线判断
ping_delay记录了当前时间距离向node节点发送PING消息的时间,data_delayd记录了node节点向当前节点最近一次发送消息的时间,从ping_delay和data_delay中取较大的那个作为延迟时间。
如果延迟时间大于超时时间,判断node是否已经处于CLUSTER_NODE_PFAIL或者CLUSTER_NODE_FAIL状态,如果都不处于,将节点状态置为CLUSTER_NODE_PFAIL,认为节点疑似下线。
从代码中可以看出,走到这个判断的时候说明
node->ping_sent不为0,表示当前节点向node发送了PING消息但是还未收到回复(收到回复时会将置为0),ping_delay大于超时时间说明在规定的时间内未收到node发送的PONG消息,data_delayd大于超时时间说明在规定的时间内未收到node发送的任何消息(当前节点只要收到其他节点发送的消息就会在处理消息的函数中记录收到消息的时间),所以不论哪个值大,只要超过超时时间,都说明在一定的时间内,当前节点未收到node节点发送的消息,所以认为node疑似下线。
上述检查完成之后,会判断当前节点是否是从节点,如果不处于CLUSTER_MODULE_FLAG_NO_FAILOVER状态,调用clusterHandleSlaveFailover处理故障转移,不过需要注意此时只是将节点置为疑似下线,并不满足故障转移条件,需要等待节点被置为FAIL下线状态之后,再次执行集群定时任务进入到clusterHandleSlaveFailover函数中才可以开始处理故障转移。
void clusterCron(void) {
// ...
orphaned_masters = 0;
max_slaves = 0;
this_slaves = 0;
di = dictGetSafeIterator(server.cluster->nodes);
// 遍历集群中的节点
while((de = dictNext(di)) != NULL) {
// 获取节点
clusterNode *node = dictGetVal(de);
now = mstime(); /* 当前时间 */
if (node->flags &
(CLUSTER_NODE_MYSELF|CLUSTER_NODE_NOADDR|CLUSTER_NODE_HANDSHAKE))
continue;
/* 如果当前节点myself是从节点,正在遍历的节点node是主节点,并且node节点不处于下线状态 */
if (nodeIsSlave(myself) && nodeIsMaster(node) && !nodeFailed(node)) {
// 获取不处于下线状态的从节点数量
int okslaves = clusterCountNonFailingSlaves(node);
/* 如果处于正常状态的从节点数量为0、node负责的slot数量大于0, 并且节点处于CLUSTER_NODE_MIGRATE_TO状态 */
if (okslaves == 0 && node->numslots > 0 &&
node->flags & CLUSTER_NODE_MIGRATE_TO)
{
orphaned_masters++; // 孤立主节点数量加1
}
// 更新最大从节点数量
if (okslaves > max_slaves) max_slaves = okslaves;
// 如果myself是从节点 并且myself是node的从节点
if (nodeIsSlave(myself) && myself->slaveof == node)
this_slaves = okslaves; // 记录处于正常状态的从节点数量
}
/* 这一步主要检查连接是否出现问题 */
mstime_t ping_delay = now - node->ping_sent; // 当前时间减去向node发送PING消息时间
mstime_t data_delay = now - node->data_received; // 当前时间减去收到node向当前节点发送消息的时间
if (node->link && /* 如果连接不为空 */
now - node->link->ctime >
server.cluster_node_timeout && /* 距离连接创建的时间超过了设置的超时时间 */
node->ping_sent && /* 已经发送了PING消息暂未收到回复 */
/* 距离发送PING消息的时间已经超过了超时时间的一半 */
ping_delay > server.cluster_node_timeout/2 &&
/* 距离收到node节点发送消息的时间超过了超时时间的一半
*/
data_delay > server.cluster_node_timeout/2)
{
/* 断开连接,在下次执行定时任务时会重新连接 */
freeClusterLink(node->link);
}
/* 如果连接不为空、ping_sent为0(收到PONG消息后会将ping_sent置为0),并且当前时间减去收到node的PONG消息的时间大于超时时间的一半 */
if (node->link &&
node->ping_sent == 0 &&
(now - node->pong_received) > server.cluster_node_timeout/2)
{
// 立即发送PING消息,保持连接
clusterSendPing(node->link, CLUSTERMSG_TYPE_PING);
continue;
}
if (server.cluster->mf_end && // 手动执行故障转移时间限制不为0,表示正在执行手动故障转移
nodeIsMaster(myself) && // 如果myself是主节点
server.cluster->mf_slave == node && // 如果node是myself从节点并且正在执行手动故障转移
node->link)
{
// 发送PING消息,保持连接
clusterSendPing(node->link, CLUSTERMSG_TYPE_PING);
continue;
}
/* 如果没有活跃的PING消息,说明当前节点暂未向node发起新的PING消息,跳过,处理下一个节点 */
if (node->ping_sent == 0) continue;
/* 校验节点是否主观下线 */
// ping_delay记录了当前时间距离向node节点发送PING消息的时间,发送PING消息node->ping_sent会置为1,走到这里说明向node节点发送过PING消息,但是暂未收到回复
// data_delay记录了node节点向当前节点最近一次发送消息的时间
// 从ping_delay和data_delay中取较大的那个作为延迟时间
mstime_t node_delay = (ping_delay < data_delay) ? ping_delay :
data_delay;
// 如果节点的延迟时间大于超时时间
if (node_delay > server.cluster_node_timeout) {
/* 如果不处于CLUSTER_NODE_PFAIL或者CLUSTER_NODE_FAIL状态*/
if (!(node->flags & (CLUSTER_NODE_PFAIL|CLUSTER_NODE_FAIL))) {
serverLog(LL_DEBUG,"*** NODE %.40s possibly failing",
node->name);
// 将节点标记为故障状态CLUSTER_NODE_PFAIL,标记疑似下线
node->flags |= CLUSTER_NODE_PFAIL;
update_state = 1;
}
}
}
// ...
// 如果是从节点
if (nodeIsSlave(myself)) {
clusterHandleManualFailover();
// 如果不处于CLUSTER_MODULE_FLAG_NO_FAILOVER状态
if (!(server.cluster_module_flags & CLUSTER_MODULE_FLAG_NO_FAILOVER))
clusterHandleSlaveFailover(); // 处理故障转移
if (orphaned_masters && max_slaves >= 2 && this_slaves == max_slaves &&
server.cluster_allow_replica_migration)
clusterHandleSlaveMigration(max_slaves);
}
// ...
}
下线(FAIL)
当前节点认为某个node下线时,会将node状态置为CLUSTER_NODE_PFAIL疑似下线状态,在定时向集群中的节点交换信息也就是发送PING消息时,消息体中记录了node的下线状态,其他节点在处理收到的PING消息时,会将认为node节点下线的那个节点加入到node的下线链表fail_reports中,并调用markNodeAsFailingIfNeeded函数判断是否有必要将节点置为下线FAIL状态:
void clusterProcessGossipSection(clusterMsg *hdr, clusterLink *link) {
uint16_t count = ntohs(hdr->count);
// 获取clusterMsgDataGossip数据
clusterMsgDataGossip *g = (clusterMsgDataGossip*) hdr->data.ping.gossip;
// 发送消息的节点
clusterNode *sender = link->node ? link->node : clusterLookupNode(hdr->sender);
while(count--) {
/* 根据nodename查找节点,node指向当前收到消息节点中维护的节点*/
node = clusterLookupNode(g->nodename);
// 如果节点已知
if (node) {
/* 如果发送者是主节点 */
if (sender && nodeIsMaster(sender) && node != myself) {
// 如果gossip节点是FAIL或者PFAIL状态
if (flags & (CLUSTER_NODE_FAIL|CLUSTER_NODE_PFAIL)) {
// 将sender加入到node节点的下线链表fail_reports中
if (clusterNodeAddFailureReport(node,sender)) {
serverLog(LL_VERBOSE,
"Node %.40s reported node %.40s as not reachable.",
sender->name, node->name);
}
// 判断是否需要将节点置为下线
markNodeAsFailingIfNeeded(node);
} else {
// 校验sender是否在下线节点链表fail_reports中,如果在需要移除恢复在线状态
if (clusterNodeDelFailureReport(node,sender)) {
serverLog(LL_VERBOSE,
"Node %.40s reported node %.40s is back online.",
sender->name, node->name);
}
}
}
// ...
} else { // 如果节点未知
// ...
}
/* 遍历下一个节点 */
g++;
}
}
markNodeAsFailingIfNeeded
markNodeAsFailingIfNeeded用于判断是否有必要将某个节点标记为FAIL状态:
- 计算quorum,为集群节点个数一半 + 1,记为
needed_quorum - 如果节点已经被置为FAIL状态,直接返回即可
- 调用
clusterNodeFailureReportsCount函数,获取节点下线链表node->fail_reports中元素的个数,node->fail_reports链表中记录了认为node下线的节点个数,节点个数记为failures - 如果当前节点是主节点,
failures增1,表示当前节点也认为node需要置为下线状态 - 判断是否有过半的节点认同节点下线,也就是
failures大于等于needed_quorum,如果没有过半的节点认同node需要下线,直接返回即可 - 如果有过半的节点认同
node需要下线,此时取消节点的疑似下线标记PFAIL状态,将节点置为FAIL状态 - 在集群中广播节点的下线消息,以便让其他节点知道该节点已经下线
void markNodeAsFailingIfNeeded(clusterNode *node) {
int failures;
// 计算quorum,为集群节点个数一半 + 1
int needed_quorum = (server.cluster->size / 2) + 1;
if (!nodeTimedOut(node)) return; /* We can reach it. */
// 如果节点已经处于下线状态
if (nodeFailed(node)) return; /* Already FAILing. */
// 从失败报告中获取认为节点已经下线的节点数量
failures = clusterNodeFailureReportsCount(node);
/* 如果当前节点是主节点 */
if (nodeIsMaster(myself)) failures++; // 认定下线的节点个数+1
// 如果没有过半的节点认同节点下线,返回即可
if (failures < needed_quorum) return;
serverLog(LL_NOTICE,
"Marking node %.40s as failing (quorum reached).", node->name);
/* 标记节点下线 */
// 取消CLUSTER_NODE_PFAIL状态
node->flags &= ~CLUSTER_NODE_PFAICLUSTER_NODE_PFAIL;
// 设置为下线状态
node->flags |= CLUSTER_NODE_FAIL;
node->fail_time = mstime();
/* 广播下线消息到集群中的节点,以便让其他节点知道该节点已经下线 */
clusterSendFail(node->name);
clusterDoBeforeSleep(CLUSTER_TODO_UPDATE_STATE|CLUSTER_TODO_SAVE_CONFIG);
}
/* 返回下线报告链表中*/
int clusterNodeFailureReportsCount(clusterNode *node) {
clusterNodeCleanupFailureReports(node);
// 返回认为node下线的节点个数
return listLength(node->fail_reports);
}
故障转移处理
clusterHandleSlaveFailover
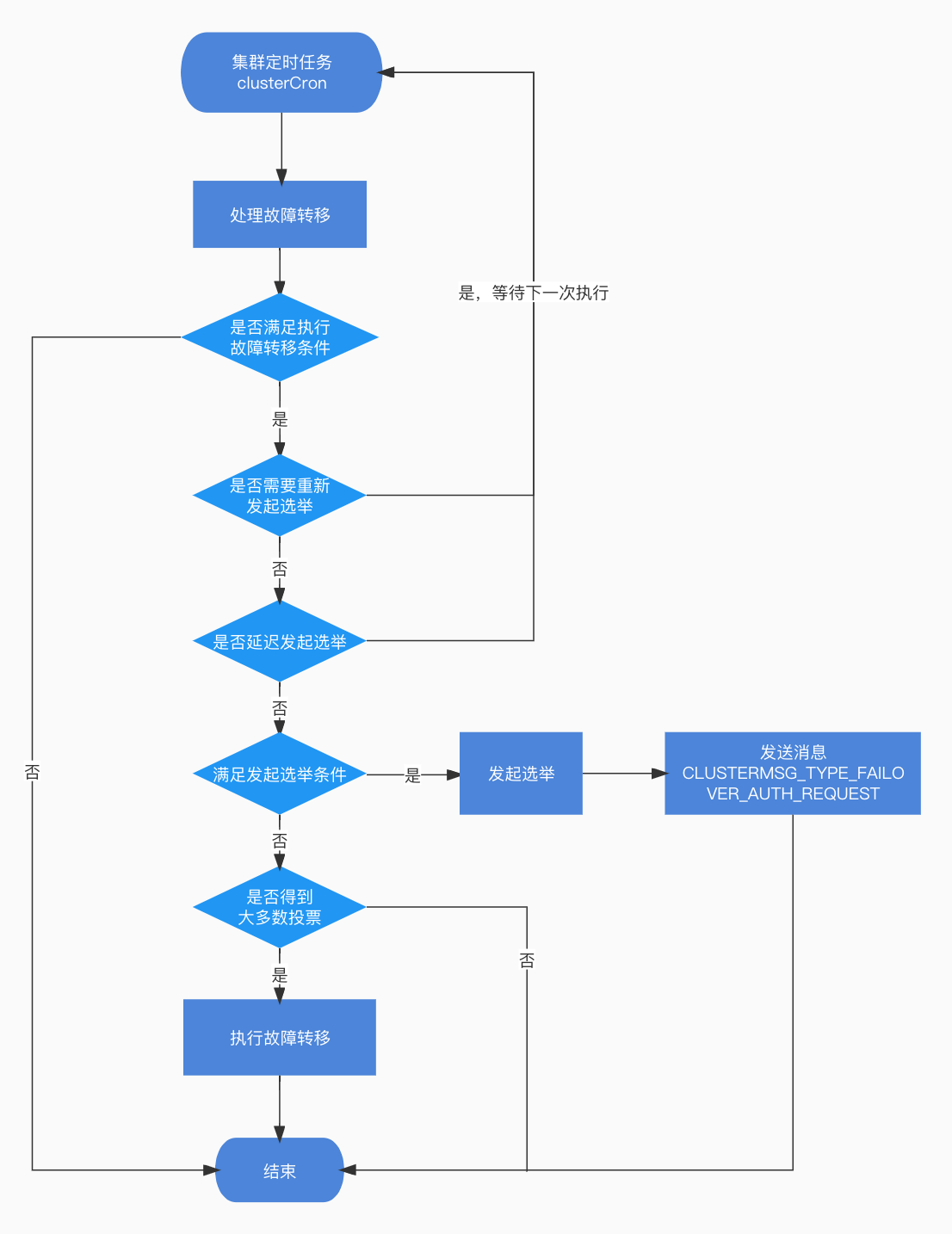
由上面的内容可知,节点客观下线时会被置为CLUSTER_NODE_FAIL状态,下次执行集群定时任务时,在故障转移处理函数clusterHandleSlaveFailover中,就可以根据状态来检查是否需要执行故障转移。
不过在看clusterHandleSlaveFailover函数之前,先看一下clusterState中和选举以及故障切换相关的变量定义:
typedef struct clusterState {
// ...
mstime_t failover_auth_time; /* 发起选举的时间 */
int failover_auth_count; /* 目前为止收到投票的数量 */
int failover_auth_sent; /* 是否发起了投票,如果已经发起,值大于0 */
int failover_auth_rank; /* 从节点排名 */
uint64_t failover_auth_epoch; /* 当前选举的纪元 */
int cant_failover_reason; /* 从节点不能执行故障转移的原因 */
mstime_t mf_end; /* 手动执行故障转移时间限制,如果未设置值为0 */
clusterNode *mf_slave; /* 执行手动故障切换的从节点 */
//...
} clusterState;
clusterHandleSlaveFailover函数中的一些变量
data_age:记录从节点最近一次与主节点进行数据同步的时间。如果与主节点处于连接状态,用当前时间减去最近一次与master节点交互的时间,否则使用当前时间减去与master主从复制中断的时间。
auth_age:当前时间减去发起选举的时间,也就是距离发起选举过去了多久,用于判断选举超时、是否重新发起选举使用。
needed_quorum:quorum的数量,为集群中节点的数量的一半再加1。
auth_timeout:等待投票超时时间。
auth_retry_time:等待重新发起选举进行投票的时间,也就是重试时间。
发起选举
一、故障转移条件检查
首先进行了一些条件检查,用于判断是否有必要执行故障转移,如果处于以下几个条件之一,将会跳出函数,结束故障转移处理:
-
当前节点
myself是master节点,因为如果需要进行故障转移一般是master节点被标记为下线,需要从它所属的从节点中选举节点作为新的master节点,这个需要从节点发起选举,所以如果当前节点是主节点,不满足进行故障转移的条件。 -
当前节点
myself所属的主节点为空 -
当前节点
myself所属主节点不处于客观下线状态并且不是手动进行故障转移,可以看到这里使用的是CLUSTER_NODE_FAIL状态来判断的#define nodeFailed(n) ((n)->flags & CLUSTER_NODE_FAIL) -
如果开启了不允许从节点执行故障切换并且当前不是手动进行故障转移
-
当前节点
myself所属主节点负责的slot数量为0
二、主从复制进度校验
cluster_slave_validity_factor设置了故障切换最大主从复制延迟时间因子,如果不为0需要校验主从复制延迟时间是否符合要求。
如果主从复制延迟时间data_age大于 mater向从节点发送PING消息的周期 + 超时时间 * 故障切换主从复制延迟时间因子并且不是手动执行故障切换,表示主从复制延迟过大,不能进行故障切换终止执行。
三、是否需要重新发起选举
如果距离上次发起选举的时间大于超时重试时间,表示可以重新发起投票。
-
设置本轮选举发起时间,并没有直接使用当前时间,而是使用了当前时间 + 500毫秒 + 随机值(0到500毫秒之间)进行了一个延迟,以便让上一次失败的消息尽快传播。
-
重置获取的投票数量
failover_auth_count和是否已经发起选举failover_auth_sent为0,等待下一次执行clusterHandleSlaveFailover函数时重新发起投票。 -
获取当前节点在所属主节点的所有从节点中的等级排名,再次更新发起选举时间,加上当前节点的rank * 1000,以便让等级越低(rank值越高)的节点,越晚发起选举,降低选举的优先级。
注意这里并没有恢复
CLUSTER_TODO_HANDLE_FAILOVER状态,因为发起投票的入口是在集群定时任务clusterCron函数中,所以不需要恢复。 -
如果是手动进行故障转移,不需要设置延迟时间,直接使用当前时间,rank设置为0,然后将状态置为
CLUSTER_TODO_HANDLE_FAILOVER,在下一次执行beforeSleep函数时,重新进行故障转移。 -
向集群中广播消息并终止执行本次故障切换。
四、延迟发起选举
- 如果还未发起选举投票,节点等级有可能在变化,所以此时需要更新等级以及发起投票的延迟时间。
- 如果当前时间小于设置的选举发起时间,需要延迟发起选举,直接返回,等待下一次执行。
- 如果距离发起选举的时间大于超时时间,表示本次选举已超时,直接返回。
五、发起投票
如果满足执行故障的条件,接下来需从节点想集群中的其他节点广播消息,发起投票,不过只有主节点才有投票权。failover_auth_sent为0表示还未发起投票,此时开始发起投票:
- 更新节点当前的投票纪元(轮次)
currentEpoch,对其进行增1操作 - 设置本次选举的投票纪元(轮次)
failover_auth_epoch,与currentEpoch一致 - 向集群广播,发送CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST消息到其他节点进行投票
failover_auth_sent置为1 ,表示已经发起了投票- 发起投票后,直接返回,等待其他节点的投票。
六、执行故障切换
当某个节点获取到了集群中大多数节点的投票,即可进行故障切换,这里先不关注,在后面的章节会讲。
void clusterHandleSlaveFailover(void) {
// 主从复制延迟时间
mstime_t data_age;
// 当前时间减去发起选举的时间
mstime_t auth_age = mstime() - server.cluster->failover_auth_time;
// 计算quorum的数量,为集群中节点的数量的一半再加1
int needed_quorum = (server.cluster->size / 2) + 1;
// 是否手动执行故障转移
int manual_failover = server.cluster->mf_end != 0 &&
server.cluster->mf_can_start;
// 等待投票超时时间,等待重试时间
mstime_t auth_timeout, auth_retry_time;
// 取消CLUSTER_TODO_HANDLE_FAILOVER状态
server.cluster->todo_before_sleep &= ~CLUSTER_TODO_HANDLE_FAILOVER;
// 等待投票超时时间为集群中设置的超时时间的2倍
auth_timeout = server.cluster_node_timeout*2;
// 如果等待投票超时的时间小于2000毫秒,设置为2000毫秒,也就是超时时间最少为2000毫秒
if (auth_timeout < 2000) auth_timeout = 2000;
// 等待重试时间为超时时间的2倍
auth_retry_time = auth_timeout*2;
/* 校验故障转移条件,处于以下条件之一不满足故障切换条件,跳出函数 */
if (nodeIsMaster(myself) || // myself是主节点
myself->slaveof == NULL || // myself是从节点但是所属主节点为空
(!nodeFailed(myself->slaveof) && !manual_failover) || // 所属主节点不处于下线状态并且不是手动进行故障转移
(server.cluster_slave_no_failover && !manual_failover) || // 如果不允许从节点执行故障切换并且不是手动进行故障转移
myself->slaveof->numslots == 0) // 所属主节点负责的slot数量为0
{
/* 不进行故障切换 */
server.cluster->cant_failover_reason = CLUSTER_CANT_FAILOVER_NONE;
return;
}
/* 如果主从复制状态为连接状态 */
if (server.repl_state == REPL_STATE_CONNECTED) {
// 设置距离最近一次复制数据的时间,由于和master节点还处于连接状态,使用当前时间减去最近一次与master节点交互的时间
data_age = (mstime_t)(server.unixtime - server.master->lastinteraction)
* 1000;
} else { // 其他状态时
// 使用当前时间减去与master主从复制中断的时间
data_age = (mstime_t)(server.unixtime - server.repl_down_since) * 1000;
}
/* 如果data_age大于超时时间,减去超时时间 */
if (data_age > server.cluster_node_timeout)
data_age -= server.cluster_node_timeout;
/* cluster_slave_validity_factor设置了故障切换最大主从复制延迟时间因子,如果不为0需要校验主从复制延迟时间是否符合要求 */
/* 如果主从复制延迟时间 大于(master向从节点发送PING消息的周期 + 超时时间 * 故障切换主从复制延迟时间因子) ,表示主从复制延迟过大,不能进行故障切换 */
if (server.cluster_slave_validity_factor &&
data_age >
(((mstime_t)server.repl_ping_slave_period * 1000) +
(server.cluster_node_timeout * server.cluster_slave_validity_factor)))
{
// 如果不是手动执行故障切换
if (!manual_failover) {
// 设置不能执行故障切换的原因,主从复制进度不符合要求
clusterLogCantFailover(CLUSTER_CANT_FAILOVER_DATA_AGE);
return;
}
}
/* 如果距离上次发起选举的时间大于超时重试时间,表示可以重新发起投票 */
if (auth_age > auth_retry_time) {
// 设置本轮选举发起时间,使用了当前时间 + 500毫秒 + 随机值(0到500毫秒之间),以便让上一次失败的消息尽快传播
server.cluster->failover_auth_time = mstime() +
500 +
random() % 500;
// 初始化获取的投票数量
server.cluster->failover_auth_count = 0;
// 初始化failover_auth_sent为0
server.cluster->failover_auth_sent = 0;
// 获取当前节点的等级
server.cluster->failover_auth_rank = clusterGetSlaveRank();
// 再次更新发起选举时间,加上当前节点的rank * 1000,以便让等级越低的节点,越晚发起选举,降低选举的优先级
server.cluster->failover_auth_time +=
server.cluster->failover_auth_rank * 1000;
/* 如果是手动进行故障转移,不需要设置延迟 */
if (server.cluster->mf_end) {
// 设置发起选举时间为当前时间
server.cluster->failover_auth_time = mstime();
// rank设置为0,等级最高
server.cluster->failover_auth_rank = 0;
// 设置CLUSTER_TODO_HANDLE_FAILOVER状态
clusterDoBeforeSleep(CLUSTER_TODO_HANDLE_FAILOVER);
}
serverLog(LL_WARNING,
"Start of election delayed for %lld milliseconds "
"(rank #%d, offset %lld).",
server.cluster->failover_auth_time - mstime(),
server.cluster->failover_auth_rank,
replicationGetSlaveOffset());
/* 广播消息 */
clusterBroadcastPong(CLUSTER_BROADCAST_LOCAL_SLAVES);
return;
}
if (server.cluster->failover_auth_sent == 0 && // 如果还未发起选举
server.cluster->mf_end == 0) // 如果不是手动执行故障转移
{
// 获取节点等级,节点等级有可能在变化,需要更新等级
int newrank = clusterGetSlaveRank();
// 如果排名大于之前设置的等级
if (newrank > server.cluster->failover_auth_rank) {
long long added_delay =
(newrank - server.cluster->failover_auth_rank) * 1000;
// 更新发起选举时间
server.cluster->failover_auth_time += added_delay;
// 更新节点等级
server.cluster->failover_auth_rank = newrank;
serverLog(LL_WARNING,
"Replica rank updated to #%d, added %lld milliseconds of delay.",
newrank, added_delay);
}
}
/* 如果当前时间小于设置的选举发起时间,需要延迟发起选举 */
if (mstime() < server.cluster->failover_auth_time) {
// 记录延迟发起选举日志
clusterLogCantFailover(CLUSTER_CANT_FAILOVER_WAITING_DELAY);
return;
}
/* 如果距离发起选举的时间大于超时时间,表示已超时 */
if (auth_age > auth_timeout) {
// 记录选举已过期日志
clusterLogCantFailover(CLUSTER_CANT_FAILOVER_EXPIRED);
return;
}
/* 如果failover_auth_sent为0表示还未发起投票 */
if (server.cluster->failover_auth_sent == 0) {
// 纪元加1
server.cluster->currentEpoch++;
// 设置当前选举纪元failover_auth_epoch
server.cluster->failover_auth_epoch = server.cluster->currentEpoch;
serverLog(LL_WARNING,"Starting a failover election for epoch %llu.",
(unsigned long long) server.cluster->currentEpoch);
// 广播发送CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST消息,发起投票
clusterRequestFailoverAuth();
// failover_auth_sent置为1 ,表示已经发起了投票
server.cluster->failover_auth_sent = 1;
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG|
CLUSTER_TODO_UPDATE_STATE|
CLUSTER_TODO_FSYNC_CONFIG);
return; /* Wait for replies. */
}
/* 校验是否获取了大多数的投票,执行故障切换 */
if (server.cluster->failover_auth_count >= needed_quorum) {
// ...
} else {
clusterLogCantFailover(CLUSTER_CANT_FAILOVER_WAITING_VOTES);
}
}
/* 发送FAILOVER_AUTH_REQUEST消息到每个节点 */
void clusterRequestFailoverAuth(void) {
clusterMsg buf[1];
clusterMsg *hdr = (clusterMsg*) buf;
uint32_t totlen;
// 设置消息头,发送CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST消息
clusterBuildMessageHdr(hdr,CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST);
/* 如果是手动转移,设置CLUSTERMSG_FLAG0_FORCEACK标记 */
if (server.cluster->mf_end) hdr->mflags[0] |= CLUSTERMSG_FLAG0_FORCEACK;
totlen = sizeof(clusterMsg)-sizeof(union clusterMsgData);
hdr->totlen = htonl(totlen);
// 发送广播
clusterBroadcastMessage(buf,totlen);
获取节点等级
clusterGetSlaveRank用于计算当前节点的等级,遍历所属主节点的所有从节点,根据主从复制进度repl_offset计算,repl_offset值越大表示复制主节点的数据越多,所以等级越高,对应的rank值就越低。
从节点在发起选举使用了rank的值作为延迟时间,值越低延迟时间越小,意味着选举优先级也就越高。
int clusterGetSlaveRank(void) {
long long myoffset;
// rank初始化为0
int j, rank = 0;
clusterNode *master;
serverAssert(nodeIsSlave(myself));
// 获取当前节点所属的主节点
master = myself->slaveof;
if (master == NULL) return 0; /* 返回0 */
// 获取主从复制进度
myoffset = replicationGetSlaveOffset();
// 变量master的所有从节点
for (j = 0; j < master->numslaves; j++)
// 如果不是当前节点、节点可以用来执行故障切换并且节点的复制进度大于当前节点的进度
if (master->slaves[j] != myself &&
!nodeCantFailover(master->slaves[j]) &&
master->slaves[j]->repl_offset > myoffset) rank++; // 将当前节点的排名后移,等级越低
return rank;
}
主节点进行投票
当从节点认为主节点故障需要发起投票,重新选举主节点时,在集群中广播了CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST消息,对应的处理在clusterProcessPacket函数中,里面会调用clusterSendFailoverAuthIfNeeded函数进行投票:
int clusterProcessPacket(clusterLink *link) {
// ...
/* PING, PONG, MEET消息处理 */
if (type == CLUSTERMSG_TYPE_PING || type == CLUSTERMSG_TYPE_PONG ||
type == CLUSTERMSG_TYPE_MEET)
{
// ...
}
// ...
else if (type == CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST) {// 处理CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST消息
if (!sender) return 1;
// 进行投票,sender为发送消息的节点,hdr为请求体
clusterSendFailoverAuthIfNeeded(sender,hdr);
}
// ...
}
clusterSendFailoverAuthIfNeeded
clusterSendFailoverAuthIfNeeded函数用于进行投票,处理逻辑如下:
- 由于只有主节点才可以投票,如果当前节点不是主节点或者当前节点中负责slot的个数为0,当前节点没有权限投票,直接返回。
- 需要保证发起请求的投票轮次要等于或者大于当前节点中记录的轮次,所以如果请求的纪元(轮次)小于当前节点中记录的纪元(轮次) ,直接返回。
- 如果当前节点中记录的上次投票的纪元(轮次)等于当前投票纪元(轮次),表示当前节点已经投过票,直接返回。
- 如果发起请求的节点是主节点或者发起请求的节点所属的主节点为空,或者主节点不处于下线状态并且不是手动执行故障转移,直接返回。
- 如果当前时间减去节点投票时间
node->slaveof->voted_time小于超时时间的2倍,直接返回。node->slaveof->voted_time记录了当前节点的投票时间,在未超过2倍超时时间之前不进行投票。 - 处理slot,需要保证当前节点中记录的slot的纪元小于等于请求纪元,如果不满足此条件,终止投票,直接返回。
以上条件校验通过,表示当前节点可以投票给发送请求的节点,此时更新lastVoteEpoch,记录最近一次投票的纪元(轮次),更新投票时间node->slaveof->voted_time,然后向发起请求的节点回复CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK消息。
void clusterSendFailoverAuthIfNeeded(clusterNode *node, clusterMsg *request) {
// 发起请求的节点所属主节点
clusterNode *master = node->slaveof;
// 从请求中获取投票纪元(轮次)
uint64_t requestCurrentEpoch = ntohu64(request->currentEpoch);
//
uint64_t requestConfigEpoch = ntohu64(request->configEpoch);
// 从请求中获取节点负责的slot
unsigned char *claimed_slots = request->myslots;
// 是否是手动故障执行故障转移
int force_ack = request->mflags[0] & CLUSTERMSG_FLAG0_FORCEACK;
int j;
/* 如果当前节点不是主节点或者当前节点中负责slot的个数为0,当前节点没有权限投票,直接返回*/
if (nodeIsSlave(myself) || myself->numslots == 0) return;
/* 如果请求的纪元(轮次)小于当前节点中记录的纪元(轮次) */
if (requestCurrentEpoch < server.cluster->currentEpoch) {
serverLog(LL_WARNING,
"Failover auth denied to %.40s: reqEpoch (%llu) < curEpoch(%llu)",
node->name,
(unsigned long long) requestCurrentEpoch,
(unsigned long long) server.cluster->currentEpoch);
return;
}
/* 如果当前节点中记录的上次投票的纪元等于当前纪元,表示当前节点已经投过票,直接返回 */
if (server.cluster->lastVoteEpoch == server.cluster->currentEpoch) {
serverLog(LL_WARNING,
"Failover auth denied to %.40s: already voted for epoch %llu",
node->name,
(unsigned long long) server.cluster->currentEpoch);
return;
}
/* 如果发起请求的节点是主节点或者发起请求的节点所属的主节点为空,或者主节点不处于下线状态并且不是手动执行故障转移,直接返回 */
if (nodeIsMaster(node) || master == NULL ||
(!nodeFailed(master) && !force_ack))
{
if (nodeIsMaster(node)) {
serverLog(LL_WARNING,
"Failover auth denied to %.40s: it is a master node",
node->name);
} else if (master == NULL) {
serverLog(LL_WARNING,
"Failover auth denied to %.40s: I don't know its master",
node->name);
} else if (!nodeFailed(master)) {
serverLog(LL_WARNING,
"Failover auth denied to %.40s: its master is up",
node->name);
}
return;
}
/* 如果当前时间减去投票时间小于超时时间的2倍,直接返回 */
/* node->slaveof->voted_time记录了当前节点的投票时间,在未过2倍超时时间之前,不进行投票 */
if (mstime() - node->slaveof->voted_time < server.cluster_node_timeout * 2)
{
serverLog(LL_WARNING,
"Failover auth denied to %.40s: "
"can't vote about this master before %lld milliseconds",
node->name,
(long long) ((server.cluster_node_timeout*2)-
(mstime() - node->slaveof->voted_time)));
return;
}
/* 处理slot,需要保证当前节点中记录的slot的纪元小于等于请求纪元 */
for (j = 0; j < CLUSTER_SLOTS; j++) {
// 如果当前的slot不在发起请求节点负责的slot中,继续下一个
if (bitmapTestBit(claimed_slots, j) == 0) continue;
// 如果当前节点不负责此slot或者slot中记录的纪元小于等于请求纪元,继续下一个
if (server.cluster->slots[j] == NULL ||
server.cluster->slots[j]->configEpoch <= requestConfigEpoch)
{
continue;
}
serverLog(LL_WARNING,
"Failover auth denied to %.40s: "
"slot %d epoch (%llu) > reqEpoch (%llu)",
node->name, j,
(unsigned long long) server.cluster->slots[j]->configEpoch,
(unsigned long long) requestConfigEpoch);
return;
}
/* 走到这里表示可以投票给从节点 */
/* 将当前节点的lastVoteEpoch设置为currentEpoch */
server.cluster->lastVoteEpoch = server.cluster->currentEpoch;
/* 更新投票时间 */
node->slaveof->voted_time = mstime();
clusterDoBeforeSleep(CLUSTER_TODO_SAVE_CONFIG|CLUSTER_TODO_FSYNC_CONFIG);
/* 发送CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK消息 */
clusterSendFailoverAuth(node);
serverLog(LL_WARNING, "Failover auth granted to %.40s for epoch %llu",
node->name, (unsigned long long) server.cluster->currentEpoch);
}
/* 发送CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK消息到指定节点. */
void clusterSendFailoverAuth(clusterNode *node) {
clusterMsg buf[1];
clusterMsg *hdr = (clusterMsg*) buf;
uint32_t totlen;
if (!node->link) return;
// 设置请求体,发送CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK消息
clusterBuildMessageHdr(hdr,CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK);
totlen = sizeof(clusterMsg)-sizeof(union clusterMsgData);
hdr->totlen = htonl(totlen);
// 发送消息
clusterSendMessage(node->link,(unsigned char*)buf,totlen);
}
投票回复消息处理
主节点对发起投票请求节点的回复消息CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK同样在消息处理函数clusterProcessPacket中,会对发送回复消息的节点进行验证:
- 发送者是主节点
- 发送者负责的slot数量大于0
- 发送者记录的投票纪元(轮次)大于或等于当前节点发起故障转移投票的轮次
同时满足以上三个条件时,表示发送者对当前节点进行了投票,更新当前节点记录的收到投票的个数,failover_auth_count加1,此时有可能获取了大多数节点的投票,先调用clusterDoBeforeSleep设置一个CLUSTER_TODO_HANDLE_FAILOVER标记,在周期执行的时间事件中会调用对状态进行判断决定是否执行故障转移。
int clusterProcessPacket(clusterLink *link) {
// ...
/* PING, PONG, MEET: process config information. */
if (type == CLUSTERMSG_TYPE_PING || type == CLUSTERMSG_TYPE_PONG ||
type == CLUSTERMSG_TYPE_MEET)
{
// 省略...
}
// 省略其他else if
// ...
else if (type == CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST) { // 处理CLUSTERMSG_TYPE_FAILOVER_AUTH_REQUEST消息
if (!sender) return 1;
clusterSendFailoverAuthIfNeeded(sender,hdr);
} else if (type == CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK) { // 处理CLUSTERMSG_TYPE_FAILOVER_AUTH_ACK消息
if (!sender) return 1;
/* 如果发送者是主节点并且负责的slot数量大于0,并且CurrentEpoch大于或等于当前节点的failover_auth_epoch*/
if (nodeIsMaster(sender) && sender->numslots > 0 &&
senderCurrentEpoch >= server.cluster->failover_auth_epoch)
{
/* 当前节点的failover_auth_count加1 */
server.cluster->failover_auth_count++;
/* 有可能获取了大多数节点的投票,先设置一个CLUSTER_TODO_HANDLE_FAILOVER标记 */
clusterDoBeforeSleep(CLUSTER_TODO_HANDLE_FAILOVER);
}
}
// 省略其他else if
// ...
}
void clusterDoBeforeSleep(int flags) {
// 设置状态
server.cluster->todo_before_sleep |= flags;
}

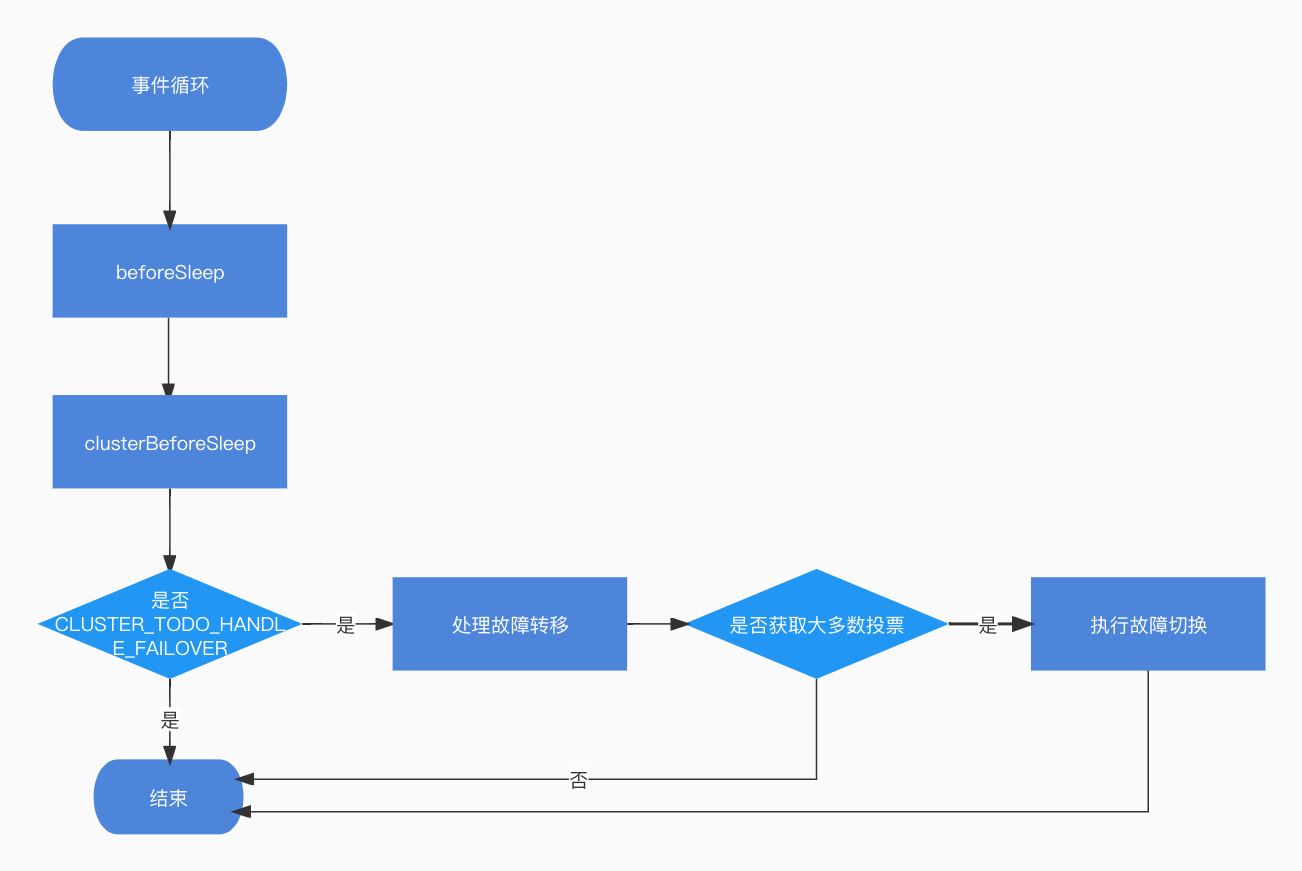
等待处理故障转移
从节点收到投票后,会添加CLUSTER_TODO_HANDLE_FAILOVER标记,接下来看下对CLUSTER_TODO_HANDLE_FAILOVER状态的处理。
在beforeSleep函数(server.c文件中),如果开启了集群,会调用clusterBeforeSleep函数,里面就包含了对CLUSTER_TODO_HANDLE_FAILOVER状态的处理:
void beforeSleep(struct aeEventLoop *eventLoop) {
// ...
/* 如果开启了集群,调用clusterBeforeSleep函数 */
if (server.cluster_enabled) clusterBeforeSleep();
// ...
}
beforeSleep函数是在Redis事件循环aeMain方法中被调用的,详细内容可参考事件驱动框架源码分析 文章。
void aeMain(aeEventLoop *eventLoop) {
eventLoop->stop = 0;
while (!eventLoop->stop) {
if (eventLoop->beforesleep != NULL)
eventLoop->beforesleep(eventLoop);
// 调用了aeProcessEvents处理事件
aeProcessEvents(eventLoop, AE_ALL_EVENTS|AE_CALL_AFTER_SLEEP);
}
}
clusterBeforeSleep
在clusterBeforeSleep函数中,如果节点带有CLUSTER_TODO_HANDLE_FAILOVER标记,会调用clusterHandleSlaveFailover函数进行处理:
void clusterBeforeSleep(void) {
// ...
if (flags & CLUSTER_TODO_HANDLE_MANUALFAILOVER) { // 处理CLUSTER_TODO_HANDLE_FAILOVER
// 手动执行故障转移
if(nodeIsSlave(myself)) {
clusterHandleManualFailover();
if (!(server.cluster_module_flags & CLUSTER_MODULE_FLAG_NO_FAILOVER))
clusterHandleSlaveFailover(); // 故障转移
}
} else if (flags & CLUSTER_TODO_HANDLE_FAILOVER) { // 如果是CLUSTER_TODO_HANDLE_FAILOVER状态
/* 处理故障转移 */
clusterHandleSlaveFailover();
}
// ...
}
故障转移处理
clusterHandleSlaveFailover函数在上面我们已经见到过,这次我们来关注集群的故障转移处理。
如果当前节点获取了大多数的投票,也就是failover_auth_count(得到的投票数量)大于等于needed_quorum,needed_quorum数量为集群中节点个数的一半+1,即可执行故障转移,接下来会调用clusterFailoverReplaceYourMaster函数完成故障转移。
void clusterHandleSlaveFailover(void) {
// 主从复制延迟时间
mstime_t data_age;
// 当前时间减去发起选举的时间
mstime_t auth_age = mstime() - server.cluster->failover_auth_time;
// 计算quorum的数量,为集群中节点的数量的一半再加1
int needed_quorum = (server.cluster->size / 2) + 1;
// ...
/* 校验是否获取了大多数的投票,failover_auth_count大于等于needed_quorum,needed_quorum数量为集群中节点个数的一半+1 */
if (server.cluster->failover_auth_count >= needed_quorum) {
/* 如果取得了大多数投票,从节点被选举为主节点*/
serverLog(LL_WARNING,
"Failover election won: I'm the new master.");
/* 更新configEpoch为选举纪元failover_auth_epoch */
if (myself->configEpoch < server.cluster->failover_auth_epoch) {
myself->configEpoch = server.cluster->failover_auth_epoch;
serverLog(LL_WARNING,
"configEpoch set to %llu after successful failover",
(unsigned long long) myself->configEpoch);
}
/* 负责master的slot */
clusterFailoverReplaceYourMaster();
} else {
clusterLogCantFailover(CLUSTER_CANT_FAILOVER_WAITING_VOTES);
}
}
执行故障转移
clusterFailoverReplaceYourMaster
如果从节点收到了集群中过半的投票,就可以成为新的master节点,并接手下线的master节点的slot,具体的处理在clusterFailoverReplaceYourMaster函数中,主要处理逻辑如下:
- 将当前节点设为主节点
- 将下线的master节点负责的所有slots设置到新的主节点中
- 更新相关状态并保存设置
- 广播PONG消息到其他节点,通知其他节点当前节点成为了主节点
- 如果是手动进行故障转移,清除手动执行故障状态
void clusterFailoverReplaceYourMaster(void) {
int j;
// 旧的主节点
clusterNode *oldmaster = myself->slaveof;
if (nodeIsMaster(myself) || oldmaster == NULL) return;
/* 将当前节点设为主节点 */
clusterSetNodeAsMaster(myself);
replicationUnsetMaster();
/* 将下线的master节点负责的所有slots设置到新的主节点中 */
for (j = 0; j < CLUSTER_SLOTS; j++) {
if (clusterNodeGetSlotBit(oldmaster,j)) {
clusterDelSlot(j);
clusterAddSlot(myself,j);
}
}
/* 更新状态并保存设置*/
clusterUpdateState();
clusterSaveConfigOrDie(1);
/* 广播PONG消息到其他节点,通知其他节点当前节点成为了主节点 */
clusterBroadcastPong(CLUSTER_BROADCAST_ALL);
/* 如果是手动进行故障转移,清除状态 */
resetManualFailover();
}
总结