-
小红书SRE负责人陈鹏:云原生时代的跨云多活之路怎么走?

嘉宾 | 陈鹏 整理 | 张雨生
出品 | CSDN云原生
小红书近年来发展迅猛,已经到了一个比较大的体量,这对其技术架构提出了较高的挑战。因此,为了解决业务增长、技术架构迭代和容灾要求等方面的问题,小红书开启了跨云多活的建设。而随着云原生时代的到来,跨云多活之路怎么走已经不再只是“布道”了。
2022年4月12日,在CSDN云原生系列在线峰会第1期“SRE与智能运维峰会”上,小红书SRE业务运维组负责人陈鹏分享了在云原生时代,小红书跨云多活能力建设的三个主要阶段。要点简述
-
多活筹备阶段,包括服务梳理、可行性验证和技术招标三个步骤。服务梳理即需要进行业务梳理和数据梳理;可行性验证就是确定能不能做,以及贵不贵的问题;技术招标则依据不同的场景进行性价比比较,以选择合适的厂商或者机房。
-
多活建设阶段,包括东西向流量调度改造、南北向流量调度改造和业务改造三个方面。东西向流量调度改造需要设置服务层级上限,以及进行机房启用控制;南北向流量调度改造的目标即是要支持多云、多地域,并且提供不同层级的流量调度;业务改造主要就是升级中间件以支持新的跨云多活服务和进行可观测性支持。
-
多活治理阶段,包括预案建设、容量管理和加强巡检能力三项工作。预案建设即对客户端切流、RGW切流、东西向流量切流和服务算力降级进行选择与优化;容量管理包括区域级别容量管理和服务级别容量管理,并且需要进行区域单元化治理;加强巡检能力的原则就是保证环境、资源、流量和监控的对齐。

背景和目标
小红书业务的容器化程度较高,达到80%,包括Redis-KV服务和Flink实时流等都实现了容器化。
在业务增长速度快、大体量的要求下,技术架构也在不断迭代。而在这样一个迭代的技术业务架构中,小红书对于容灾要求非常高,因为一旦出现故障或者问题,会很容易上热搜。基于这样的背景,小红书想要做的就是避免服务是单云的。目前小红书的业务主要是基于单一公共云的,由于其容器化程度高的特点,想要做到避免单云还是比较简单的。因此,小红书提出了一个比较大的跨云多活能力建设的目标,即不仅要实现跨云,还要支持异地,以及将服务或者业务的场景组成单元化。

其实无论是小红书还是其他移动应用,技术架构都差不多。基本上都是由客户端请求发送到LB,然后再到网关,网关下面会有业务网关,最后由API网关将其分配到不同的业务上。对于小红书来讲,其核心业务还是比较清晰的,有搜索推荐和社区。其跨云多活建设的第一期目标就是希望能够在推荐场景把跨云多活落地,目前也实现了这个目标,并且已经稳定运行了数月。

阶段一:多活筹备
有了目标驱动,多活建设的筹备自然而然地被提上日程,而在多活筹备这个过程中,需要做哪些事情呢?
服务梳理首先,我们需要把目标分析透彻,定义清楚什么是单元化,明确怎么做单元化。对于小红书来说,单元化的概念就是要保证业务流量主流程控制在一个机房内闭环。
比如对于推荐场景,在用户的推荐请求进来之后,其召回阶段和推荐策略的流程涉及到一些在线服务,这本身是一个整体的推荐业务,将这些涉及的业务都划分到一个业务单元,这就是服务依赖的梳理。这些服务其实都算主流程,它们的依赖都属于S0依赖。

而推荐返回的笔记列表中可能带有一些广告,这就需要调用广告服务,而广告服务属于非主流程里的服务,它是可降级的,因此我们在单元划分时,会将其划分在推荐单元之外。
在业务梳理之后,要进行数据梳理,这是一个比较复杂的过程。对于数据而言,我们可以将其划分为三类:DB数据、Cache数据和索引模型数据,不同的数据有不同的关注点。-
对于DB数据,主要关注在线服务对它的访问是否是S0依赖、它的带宽是否敏感以及它的读写模式等。
-
对于Cache数据,其基本不需要做数据同步,因为它是在一个机房内读写的,也就是延迟敏感,所以我们只需要明确它的类型即可。
-
对于索引模型数据,它是以读为主的,数据生成基本都是离线的,因为读的数据索引比较大,在流量比较大的情况下,在线服务的副本会很多,所以如果我们不治理或者不关注,将会带来很大的带宽开销。
因此,我们需要基于这些关注点做相应的改造。如下图展示了我们可能会做到的改造。

比如DB数据,可能做一些数据的复制;比如Cache数据,由于其本身在一个机房内闭环,则无需复制,只需要部署即可;而索引模型数据也是在一个机房内写离线,但没有按常规进行数据同步,而是使用了P2P的模式。
可行性验证在做完上述服务梳理后,就需要对一些技术点做相应的验证。验证的目标其实就是验证能不能做以及贵不贵的问题。
由于小红书的容器化程度高,所以其容器化部署本身的成本较低,只需要在另外一个地域或者厂商开辟K8s集群就可以将服务部署起来。包括DB也可以如此去快速部署。
有了Demo单元之后,接下来会做白名单验证。白名单验证首先验证的是流程能否走完,在验证完功能之后,将会进行一个小流量的实验来确保实验指标或者推荐体验是没有问题的。
技术招标有了上述的验证之后,就可以做技术招标,通过技术招标可以判断各厂商或者机房的性价比。基于前面的可行性验证,可以把招标分为几类。
-
对于DB场景,需要高I/O的机型带本地SSD盘。
-
对于Cache场景,需要内存型机器。
-
对于计算场景,显然是需要计算型机器。
另外对于小红书这样使用公有云资源的平台,其资源隔离能力至关重要,比如带宽的隔离、操作系统的隔离、CPU的隔离,都会在招标中去做判断云厂商的技术能力,以试图寻找到满足性能要求且性价比高的厂商或者机房。

阶段二:多活建设
在做完多活筹备之后,就可以进入到真正实施建设的阶段。
东西向流量调度改造
在实施过程中,很多服务也在进行迭代,其中一个比较大的迭代就是在线业务的服务发现,或者叫东西向流量调度,它的服务注册和发现过程已经迁移到了云原生的服务发现。
该云原生的服务发现需要适配新的服务注册方式和新的服务发现方式,与此同时,新的服务注册中心也需要进行改造。比如在最核心的服务层级,由于在跨云多活场景下层级的差异,我们会进行四层的划分:Global、云、地域和机房,四个层级逐级缩小以控制服务发现的范围。
一个机房级别的服务只有在本机房才能够被发现,一个地域级别的服务则只要在该地域里注册的服务就能发现,云级别则不管它是哪个地域或者机房,只要同属于一个云(如阿里云或者腾讯云)就可以被发现,而跨云则无法被发现。Global级别即突破机房、地域和云的限制,可以被上游的服务发现。
有了这四个层级之后,还基于层级设定发现的上限和下限。当单元层级无可用实例时,可以fallback到上限层级,使之具备一定的容错能力。另外,机房启用控制理念同样不可忽略,当一个新的服务上线,这个服务怎么承接、怎么走一个正常的上线流程,就是由机房启用控制去控制它加入一个单元化的整体模块中。拥有这样一个开关控制流量承接,可以有效地防止上线过程中容量不足引起的服务崩溃。
其实服务层级治理的主要目标也是防止流量爆炸而引发的服务雪崩。比如某个机房出现了问题,如果自动化地让其调度到下一个机房,这很有可能会引起下一个机房的雪崩,尤其当上游有重试,这种情况更容易出现。而通过服务层级的控制,就可以把问题或者事故锁定在出问题的机房中,然后再通过切流或者其他应急手段,逐步把服务影响屏蔽,而不是直接走自动化方案把另外的机房服务也破坏掉。
南北向流量调度改造
南北向流量调度的改造同样重要。南北向流量调度的改造其实就是从客户端到LB,再到网关这个层面,主要的目标就是支持多云、支持多地域,并且可以提供不同层级的流量调度。
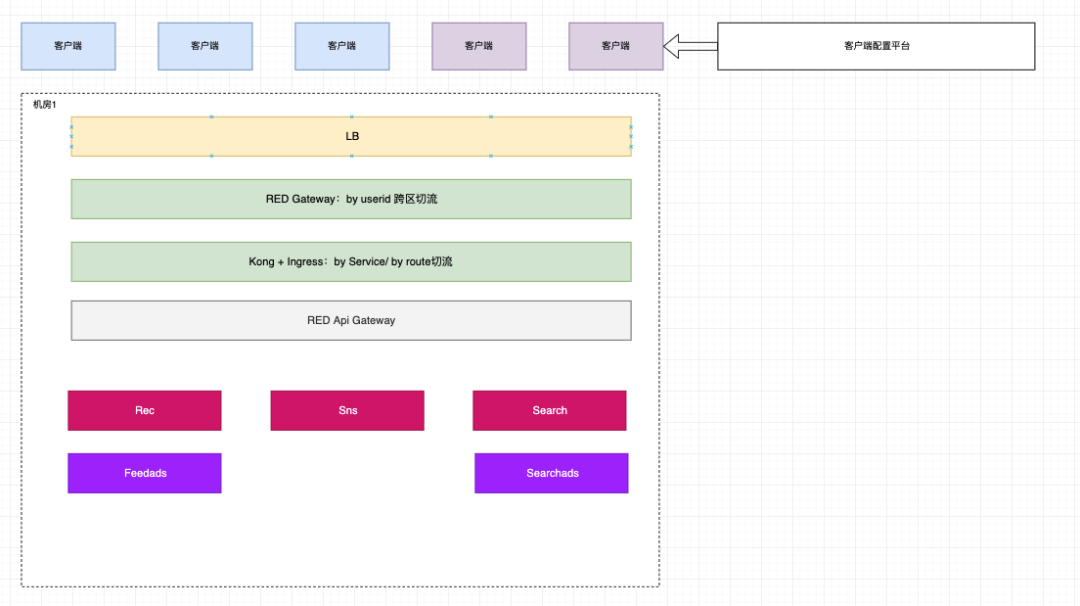
具体来讲,就是要做很多插件,比如提供跨区的切流插件,以及固定用户流量的插件。我们希望用户可以固定到某个机房访问,为什么要做这个事情呢?例如在推荐场景,推荐服务会把用户推荐历史存下来的,包括一些用户特征和读过的笔记,如果流量不固定,可能出现同步不及时的问题,即推荐重复笔记等,这是不可接受的。所以从网关层面需要具备把用户固定到某个机房的能力,同时能够基于固定的模式按照百分比切流。
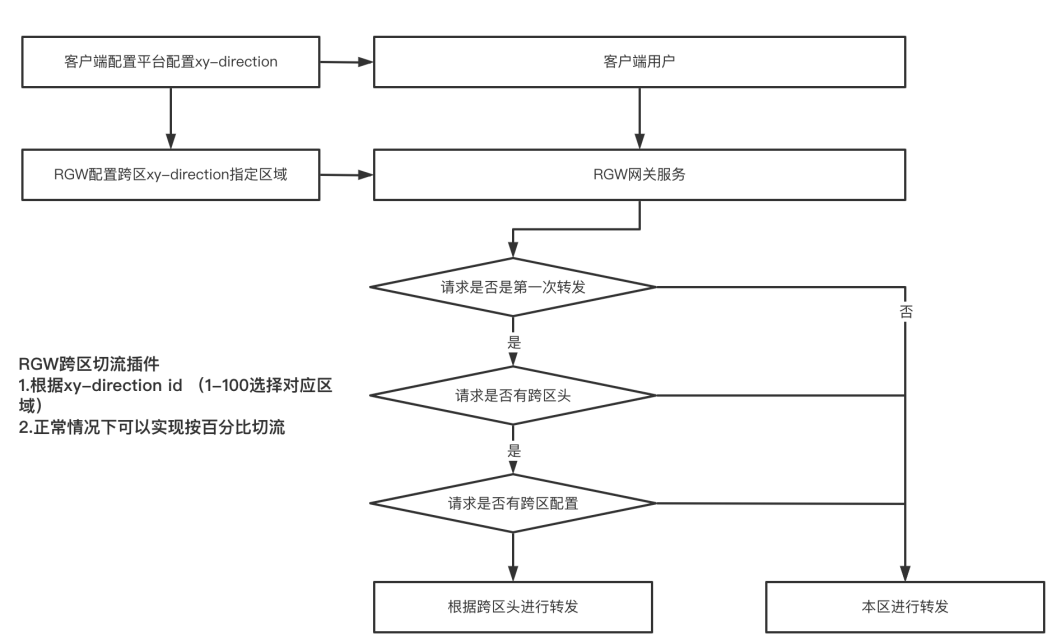
例如,某个机房承载了30%的流量,而某一天,我们希望该机房可以提升到40%,就需要从固定用户的角度,把别的机房的固定用户等比例地切过来。在切流过程中,要坚守的原则就是确保用户流量趋向一个稳定的状态。
业务改造多活建设需要进行业务改造。比如模型索引数据下载采用P2P模式,而之前的业务可能是直接访问对象存储,现在则可以通过业务接入P2P的SDK,通过机器上的agent转发数据下载请求实现下载数据。
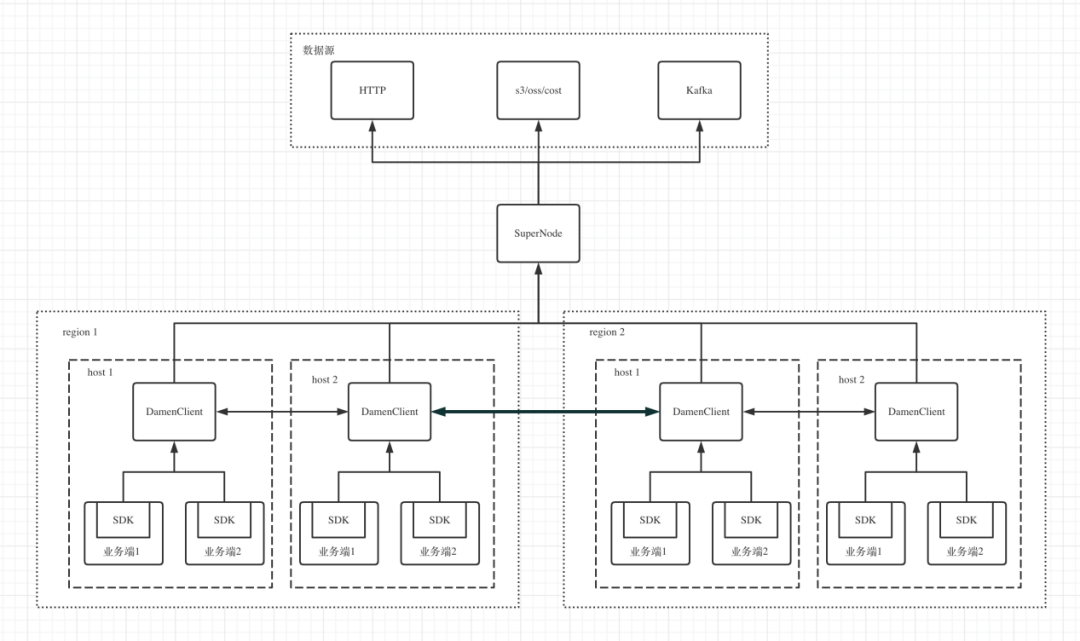
无独有偶,业务改造还需要做东西向流量调度改造的适配,以实现根据服务层级控制其访问本机房、本地域、本云亦或是Global,从而优化东西流量控制。得益于可观测性的增强,在服务调用的打点中,我们就可以知道这个服务访问的是下游的哪个机房中的哪个服务。
在做完上述东西向流量调度改造、南北向流量调度改造和业务改造之后,跨云多活的服务已经可以启用,可以正常接入流量。
阶段三:多活治理
小红书在接入流量的过程中发现了一些新的问题。其中相对典型的是,虽然专线在不断扩容,但还是难以满足流量的涨幅。因此,小红书专门做了专线流量问题的优化。优化的核心点就是要建设专线的流量分析工具,有了这样的工具,我们就可以把出现的尖刺或者是日常产生的比较大的带宽的Top的IP和端口抽取出来,进而分析是哪个服务导致的。
首先,对于之前做的P2P模式里面的agent,其也会对对象存储进行访问,在发现该问题后,小红书做了一些更深层次的优化,把agent从对象存储下载数据的逻辑全部清理干净。其次,一些新迭代的近线服务跨Region调用,当其服务层级是Global时,在拿到不同机房的实例后,就直接负载均衡地去访问所有的机房,而由此产生流量是不具备必要性的。因此,需要在服务发现的控制面将服务层级变更为机房级别的。如此,它就只能在本机房访问服务了。最后,还有一些问题是由于在业务层面有些业务写特征数据未压缩导致的。在治理完这些问题之后,尖刺消失了的同时也节省了流量,其收益较为明显。

预案建设
在做以上治理的过程中,我们会发现切流能力是必不可少的,比如客户端的网关切流、服务层级的东西向切流等。
小红书客户端访问网关是通过预埋IP的方式实现的,比如新增了一个地域,需要把那个地域的LB和域名的映射、IP和域名的映射直接预埋在客户端。在新增一个地域之后会做客户端的发版,不走DNS,这样的好处是可以避免因为DNS服务出现问题而引起的其他问题。在客户端发版之后,将在2-3周内推送给80%以上的用户。基于此,我们可以根据客户端的配置平台控制用户访问的机房,而对于一些未升级的老版本客户端,则用网关内层的纠偏能力确保其可以固定到某个机房。
RGW切流是小红书自己的网关,属于机房级别的。例如有四个提供不同比例的机房,按照Hash值等指标,在每个机房分配一部分用户,根据事先预定的比例控制不同的用户访问某个固定的机房。而对于一些老版本的客户端,则会直接选择让其固定到某个机房。在执行该预案时,需要做一个灰度机房以保证没有问题后再全量,整个切流过程在两分钟内就可以完全生效。

东西向切流一般仅在新服务上线的时候用到。当一个新服务上线时,在启用控制后,会打入100%的流量,如果希望其更平滑,就可以做东西向切流。
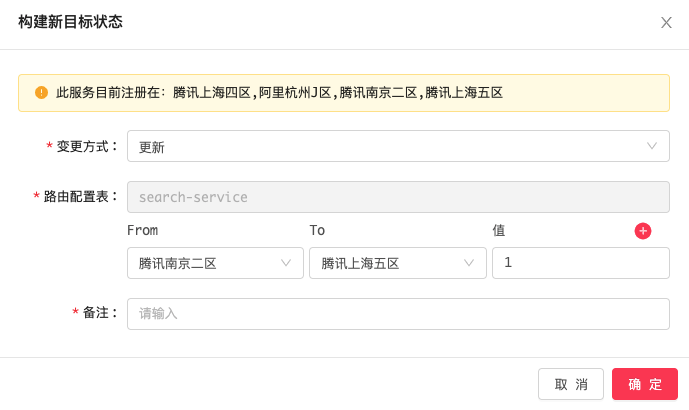
另外,还有一个服务层级的预案建设,比如推荐服务是需要降低能力的,即在做排序或者召回时,由于其耗费算力而去控制其计算比例。

对于一次召回或者排序,它返回的笔记池子是不会每次都被用户直接消费完的,因此不需要每次去做这样的排序。基于这样的逻辑,我们会按照等比例去做降级。
-
手动档的降级可以通过实验平台实现控制,直接规定50%的请求不需要做一次打分。
-
自动档的降级即基于下游服务的错误率控制降级比例。
由于自动档控制的比例存在抖动,所以在演练过程中,一般会采用手动档降级。而自动档是通过滑动窗口逐步降级,一般做应急之用。
容量管理在有这样一个多活之后,容量管理成为很重要的话题,即每个机房到底能够扛起多大的流量,而这需要经过日常的训练去摸底。每个机房会预定一个目标,如扛起30%的流量,当遇到问题需要切流时,我们需要明确其实际能够扛起多少流量以避免切流之后的崩溃。因此,在日常中需要保证区域的流量比例可以灵活调配。

另一方面,需要通过区域切流验证单区域容量是否达到冗余要求。我们要知道每个服务现在的容量是多了还是少了,多则做一定的缩容,少则及时扩容。在这个过程中,根据指标和生成的趋势图去判断其最佳容量到底是多少单实例,然后乘以其副本数量,就是服务整体的容量。
在日常中,还要做单元化的治理。
-
其一是做机房的隔离,例如可以把A机房访问B机房的网络屏蔽,然后观察其单元化的业务是否可以正常工作。
-
其二是我们有很多的兜底逻辑,例如在进行推荐业务时,我们有降级的能力以保证用户享受持续的个性化推荐,做验证时可以把某个机房切空,然后开一点点流量,保证它在触发阈值条件下,通过客户端观察其降级预案是否工作。

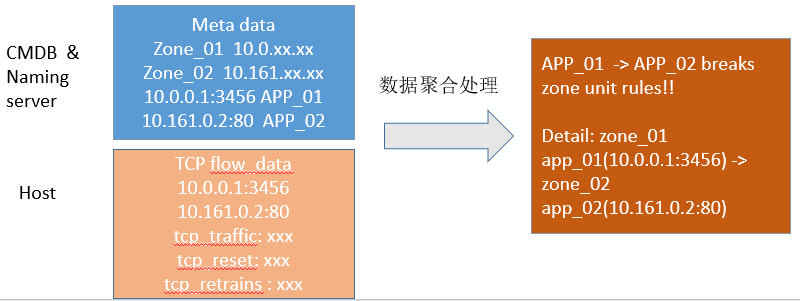
而对于东西向流量是否会按照预设范围的问题,可以通过内核级别的一些参数,基于BPF的检测能力去看到其IP端口、原IP端口和目的IP端口的访问路径,以及通过明确访问服务A、访问服务B的层级这样一个输入条件去聚合,从而判断这个访问是否破坏了单元化的规则。基于这样的过程,把对应的不正确的配置纠正过来。
巡检能力
最后需要加强巡检能力。巡检的目标就是在有多单元之后要保证不同单元的能力是对齐的,例如各种操作系统、镜像版本、磁盘状况和内核参数等环境,要保证其是对齐、可以落地的。同样的,还有规格和实例数等资源对齐、服务发现和路由等流量对齐,以及监控对齐。
做完这些治理之后,我们会发现服务已经可以稳定地跑在这样一个跨云多活的环境里了。

结束语
其实我们还有很多事情要做,比如专线的流量治理。小红书在分片级别正在做一个分布式存储的治理,这样就可以极大地优化专线的流量问题。另外,小红书会继续做好搜索社区以及广告等核心场景的跨云多活的落地。在做这些事情的过程中,我们发现不同公司或者不同业务,其玩法或者特点各不相同。小红书要基于特点做分析,找到更适合的玩法——只有适合的才是最好的。
聚焦云原生新技术、新实践,帮助开发者群体赢在开发范式转移的新时代。欢迎关注 CSDN云原生 微信公众号~
-
-
相关阅读:
呜呜呜呜呜呜呜呜呜
tkinter滚动事件详解
Android 滑动事件消费监控,Debug 环境下通用思路
UE4 利用WEBUI插件完成UE与JS的交互 (UE4嵌入WEB)
强化科技创新“辐射力”,中国移动的数智化大棋局
yum安装mysql8
开发环境搭建---Ubuntu18.04开发环境搭建
png图片自动转ttf字体(使用python实现)
VSCode 好用的插件分享
linux 下 java环境安装
- 原文地址:https://blog.csdn.net/m0_46700908/article/details/124179620