-
Scrapy与Selenium强强联合-共创爬虫大业
🐸文章适合于所有的相关人士进行学习🐸
🐶各位看官看完了之后不要立刻转身呀🐶
🐼期待三连关注小小博主加收藏🐼
🐤小小博主回关快 会给你意想不到的惊喜呀🐤
🚩效果展示
selenium+scrapy
🚩问题提出
在问题提出之前,我先把爬虫需要学习的框架发上来让大家看一下,需要了解学习什么之后才是一个合格的爬虫工程师。

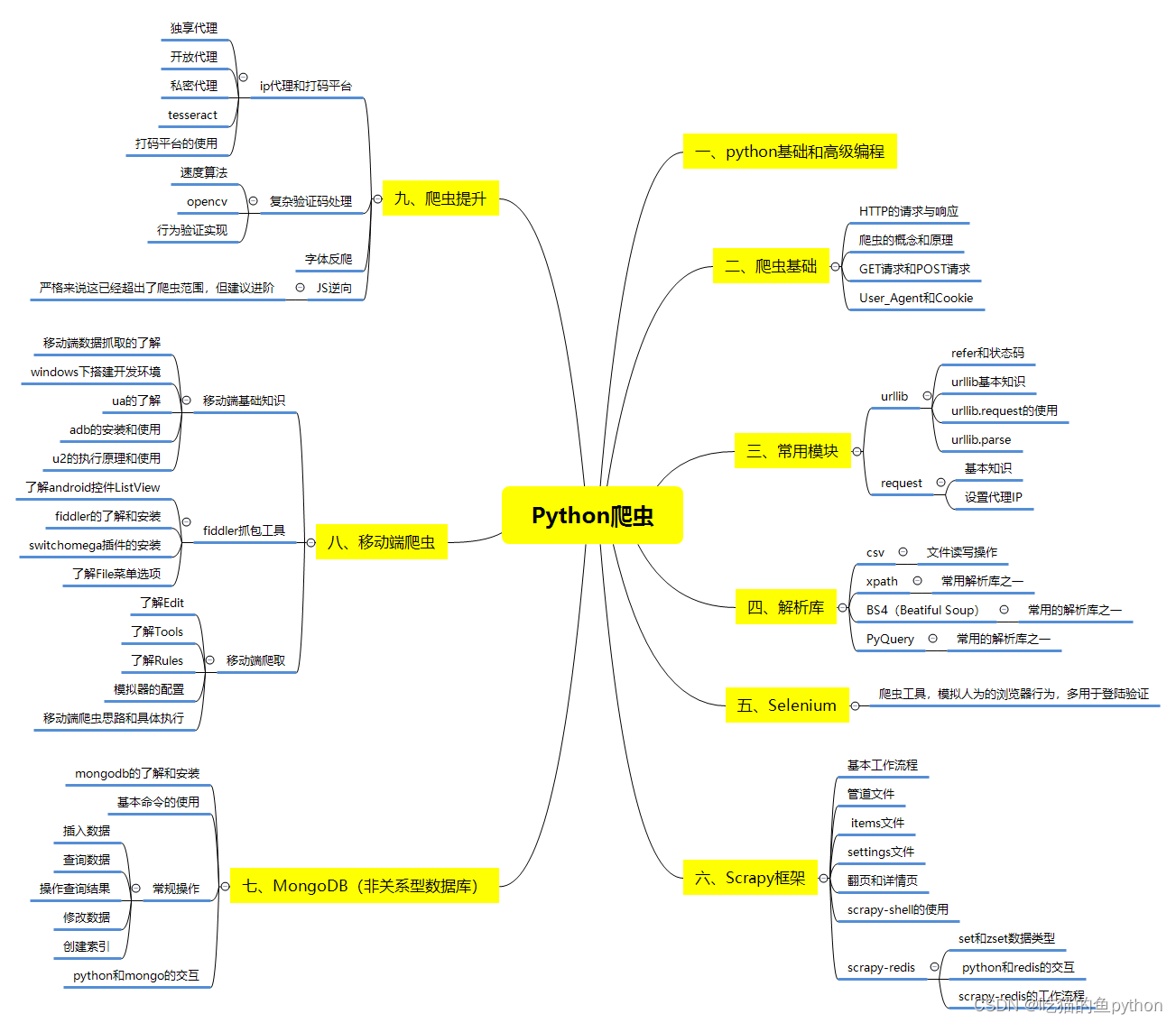
☁️我们可能会遭遇的情况
当我们爬取网站的时候,可能会出现需要我们使用鼠标点击的操作,比如说当一个专栏出现了过多,网站为了防止占用太多的网页空间,然后直接把他多余部分进行隐藏,然后弄成查看更多的链接,这里如果我们想要爬取这部分内容就需要我们去点击这个查看更多,如果单纯的使用爬虫去做这部分工作的话就会直接报错。或者无法全部爬取。
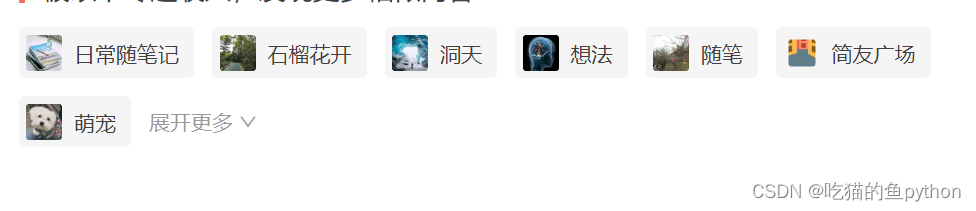
比如这一部分我们就需要去点击展开更多,然后继续获取多余的数据信息。那么我们如何解决这个问题呢?🚩解决问题方案
☁️解决方案
如果我们使用selenium去做这件事情,很容易就可以实现,详情请参考12306selenium爬取过程。那么为了使scrapy+selenium这两个大佬一起做事,我们做出了以下分析。
☁️创建scrapy中的crawspider
这里我们重新介绍一个CrawlSpider爬虫。我们一般情况下在解析完整的页面之后获得下一页的url,然后我们重新发送一个request请求。但是如果我们想要做只要满足某个条件的url,就进行爬取,这个时候我们就可以通过crawspider来完成,crawspider继承自spider,只不过在之前的基础之上呢又添加了新的功能,可以定义url的规则,以后遇到满足条件的都进行爬取。
创建就是在cmd中找到想要创建的文件夹,然后scrapy startproject +你想爬取的文件名
然后cd 你想爬取的文件名
然后scrapy genspider -t crawl 爬虫demo名字 加网站域名☁️单纯使用selenium进行爬取
🌊网页分析及代码
我们对简书进行爬取,首先导入库
from selenium import webdriver#selenium需要的库 from selenium.webdriver.support.ui import WebDriverWait#等待 from selenium.webdriver.common.by import By#By库 from selenium.webdriver.support import expected_conditions as EC#等待- 1
- 2
- 3
- 4
然后我们让driver运行
driver = webdriver.Chrome()- 1
因为这里我们会发现很多问题,反爬虫设计的十分恶心,他的class是动态变化的,且源码的结构也是会发生改变的,所以我们下面的定位各位大佬一定要好好的去看。
url = "简书url/p/004ae79ab62b"#jianshu的url driver.get(url) WebDriverWait(driver,5).until( EC.element_to_be_clickable((By.XPATH,"//section[last()]/div/div")) )#等待可以xpath定位部分可以点击了 执行下方操作 while True: try: next_btn = driver.find_element(By.XPATH,"//section[last()]/div/div") driver.execute_script("arguments[0].click();",next_btn)#重点,此时我们要重复进行点击 所以加入到while true 如果报错则我们跳出循环就是说没有这个按钮就会报错的 except Exception as e: break subjects = driver.find_elements(By.XPATH,"//section[last()]/div[position()=1]/a")#点击完成之后我们找到相对应到的元素,然后直接找到所有元素 for subject in subjects: print(subject.text)#遍历爬取- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
这里我们解把selenium爬取的过程讲解完了 那么我们如何把selenium和scrapy进行结合呢???
☁️强强联合爬取
🌊网页分析及代码
首先我们进行分析页面,我们要找到所有的详情页面的url,所以我们以rule规则为标准,最后发现规则是:
.*/p/0-9a-z]{12}- 1
这里解释一下就是说我们前面是若干个字符然后/p/由12个0到9或者a到z的组合构成。回馈给parse_detail函数,follow进行跟进。
class JsSpider(CrawlSpider): name = 'js' allowed_domains = ['jianshu.com'] start_urls = ['简书url/p/004ae79ab62b'] rules = [ Rule(link_extractor=LinkExtractor(allow=r'.*/p/[0-9a-z]{12}'),callback="parse_detail",follow=True) ] def parse_detail(self, response): print(response.text)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这里我们就定义完成了
然后我们在中间件中思想就是在进行request时候,把request请求进行拦截,然后这个时候使用selenium进行请求页面,最后把selenium请求到的页面进行返回给response对象返回给spider。
class JianshuDownloaderMiddleware: def __init__(self): self.driver = webdriver.Chrome() def process_request(self, request, spider): # 然后用selenium去请求 self.driver.get(request.url) next_btn_xpath = "//div[@role='main']/div[position()=1]/section[last()]/div[position()=1]/div" WebDriverWait(self.driver, 5).until( EC.element_to_be_clickable((By.XPATH, next_btn_xpath)) ) while True: try: next_btn = self.driver.find_element(By.XPATH,next_btn_xpath) self.driver.execute_script("arguments[0].click();", next_btn) except Exception as e: break # 把selenium获得的网页数据,创建一个Response对象返回给spider response = HtmlResponse(request.url,body=self.driver.page_source,request=request,encoding='utf-8') return response- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
这里完成之后,我们进入到settings中,把相关设置打开,管道打开,中间件打开,然后协议False,还有就是下载延迟打开延迟2s。这里我就们就可以进行爬取了,最后我们可以在JsSpider中继续xpath爬取内容,然后通过items进行获取,最后通过pipelines进行保存至文件当中这些操作就都可以完成了。谢谢各位小伙伴的观看。

🐸文章适合于所有的相关人士进行学习🐸
🐶各位看官看完了之后不要立刻转身呀🐶
🐼期待三连关注小小博主加收藏🐼
🐤小小博主回关快 会给你意想不到的惊喜呀🐤 -
相关阅读:
coq程序编写好用的IDE推荐
Redis学习3——列表数据类型的操作
「网页开发|后端开发|Flask」08 python接口开发快速入门:技术选型&写一个HelloWorld接口
卓越领先!安全狗入选2023年福建省互联网综合实力50强
RxJava的前世【RxJava系列之设计模式】
游戏制作资源推荐
Linux 查看进程启动时间、运行时间
嵌入式开发:ST-LINK V2.1仿真器,Type-C接口
数商云B2B电商系统商品管理功能剖析,助力家用电器企业业务提效
Python:每日一题之最少砝码
- 原文地址:https://blog.csdn.net/m0_37623374/article/details/124863279