-
利用python实现逻辑回归(以鸢尾花数据为例)
从广义线性回归推导出逻辑回归
什么是逻辑回归
逻辑回归不是一个回归的算法,逻辑回归是一个分类的算法,就比如卡巴斯基不是司机。 那为什么逻辑回归不叫逻辑分类?因为逻辑回归算法是基于多元线性回归的算法。而正因为 此,逻辑回归这个分类算法是线性的分类器。未来我们去学的基于决策树的一系列算法,基 于神经网络的算法等那些是非线性的算法。SVM 支持向量机的本质是线性的,但是也可以 通过内部的核函数升维来变成非线性的算法。
Sigmoid 作用
逻辑回归就是在多元线性回归基础上把结果缩放到 0 到 1 之间。 h (x) 越接近+1 越是 正例, h (x) 越接近 0 越是负例,根据中间 0.5 分为二类。
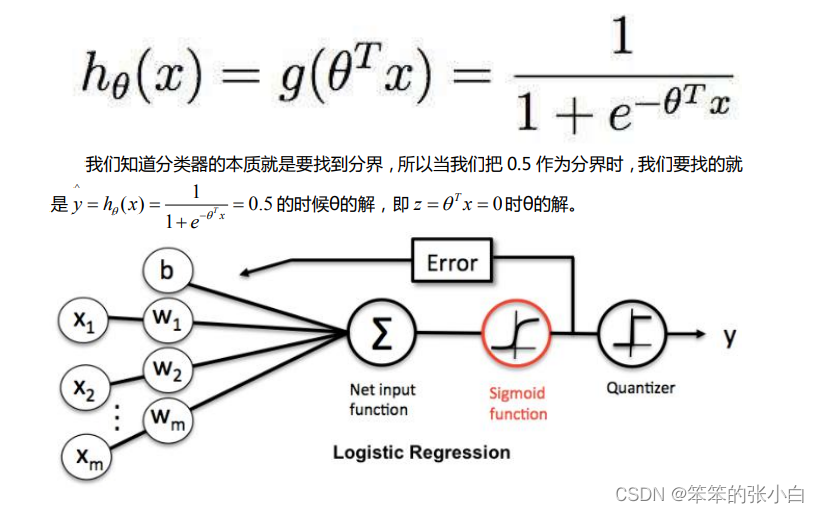
为什么逻辑回归要用 sigmoid 函数
什么事情,都要做到知其然,知其所以然,sigmoid 函数的数学公式推导,我们知道 二分类有个特点就是正例的概率+负例的概率=1。一个非常简单的试验是只有两个可能结 果的试验,比如正面或反面,成功或失败,有缺陷或没有缺陷,病人康复或未康复。为方便起见,记这两个可能的结果为 0 和 1,下面的定义就是建立在这类试验基础之上的。如果随机变量 X 只取 0 和 1 两个值,并且相应的概率为:
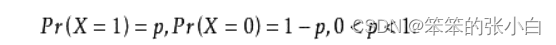
则称随机变量 X 服从参数为 p 的伯努利分布(0-1 分布),若令 q=1-p,则 X 的概率 函数可写:
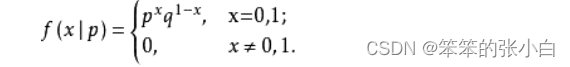
联系上我们的机器学习中的二分类任务,逻辑回归二分类任务中我们会把正例的 label 设置为 1,负例的 label 设置为 0,对于上面公式就是 x=0,1。
逻辑回归的损失函数推导
这里我们依然会用到最大似然估计思想,根据若干已知的 X,y(训练集) 找到一组 W 使得 X 作为已知条件下 y 发生的概率最大。 逻辑回归中既然 g(w,x)的输出含义为 P(y=1|w,x),那么 P(y=0|w,x)=1-g(w,x)
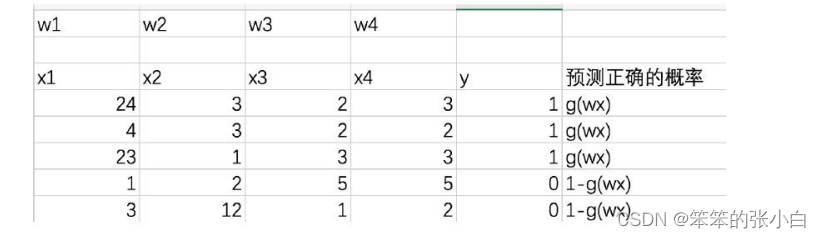
只要让我们的 g(w,x)函数在训练集上预测正确的概率最大,g(w,x)就是最好的解。
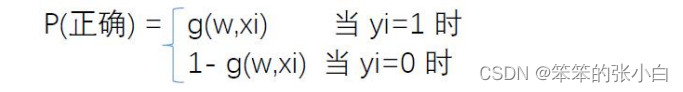
对于每一条数据预测正确的概率,也可以把下面公式看成是上面式子的合并形式
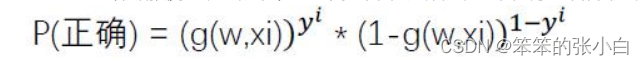
换符号重写一下
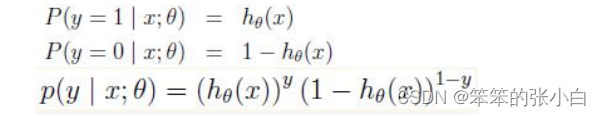
我们假设训练样本相互独立,那么似然函数表达式为:
 同样对似然函数取 log,转换为:
同样对似然函数取 log,转换为:
总结,得到了逻辑回归的表达式,下一步跟线性回归类似,构建似然函数,然后最大似然估 计,最终推导出θ的迭代更新表达式。只不过这里用的不是梯度下降,而是梯度上升,因为 这里是最大化似然函数不是最小化似然函数。通常我们一提到损失函数,往往是求最小,这 样我们就可以用梯度下降来求解。最终损失函数就是上面公式加负号的形式:

绘制损失函数
- from sklearn.datasets import load_breast_cancer
- from sklearn.linear_model import LogisticRegression
- import numpy as np
- import matplotlib.pyplot as plt
- from mpl_toolkits.mplot3d import Axes3D
- from sklearn.preprocessing import scale
- data = load_breast_cancer()
- X, y = scale(data['data'][:, :2]), data['target']
- # 求出两个维度对应的数据在逻辑回归算法下的最优解
- lr = LogisticRegression(fit_intercept=False)
- lr.fit(X, y)
- # 分别把两个维度所对应的参数W1和W2取出来
- theta1 = lr.coef_[0, 0]
- theta2 = lr.coef_[0, 1]
- print(theta1, theta2)
- # 已知W1和W2的情况下,传进来数据的X,返回数据的y_predict
- def p_theta_function(features, w1, w2):
- z = w1*features[0] + w2*features[1]
- return 1 / (1 + np.exp(-z))
- # 传入一份已知数据的X,y,如果已知W1和W2的情况下,计算对应这份数据的Loss损失
- def loss_function(samples_features, samples_labels, w1, w2):
- result = 0
- # 遍历数据集中的每一条样本,并且计算每条样本的损失,加到result身上得到整体的数据集损失
- for features, label in zip(samples_features, samples_labels):
- # 这是计算一条样本的y_predict
- p_result = p_theta_function(features, w1, w2)
- loss_result = -1*label*np.log(p_result)-(1-label)*np.log(1-p_result)
- result += loss_result
- return result
- theta1_space = np.linspace(theta1-0.6, theta1+0.6, 50)
- theta2_space = np.linspace(theta2-0.6, theta2+0.6, 50)
- result1_ = np.array([loss_function(X, y, i, theta2) for i in theta1_space])
- result2_ = np.array([loss_function(X, y, theta1, i) for i in theta2_space])
- fig1 = plt.figure(figsize=(8, 6))
- plt.subplot(2, 2, 1)
- plt.plot(theta1_space, result1_)
- plt.subplot(2, 2, 2)
- plt.plot(theta2_space, result2_)
- plt.subplot(2, 2, 3)
- theta1_grid, theta2_grid = np.meshgrid(theta1_space, theta2_space)
- loss_grid = loss_function(X, y, theta1_grid, theta2_grid)
- plt.contour(theta1_grid, theta2_grid, loss_grid)
- plt.subplot(2, 2, 4)
- plt.contour(theta1_grid, theta2_grid, loss_grid, 30)
- fig2 = plt.figure()
- ax = Axes3D(fig2)
- ax.plot_surface(theta1_grid, theta2_grid, loss_grid)
- plt.show()
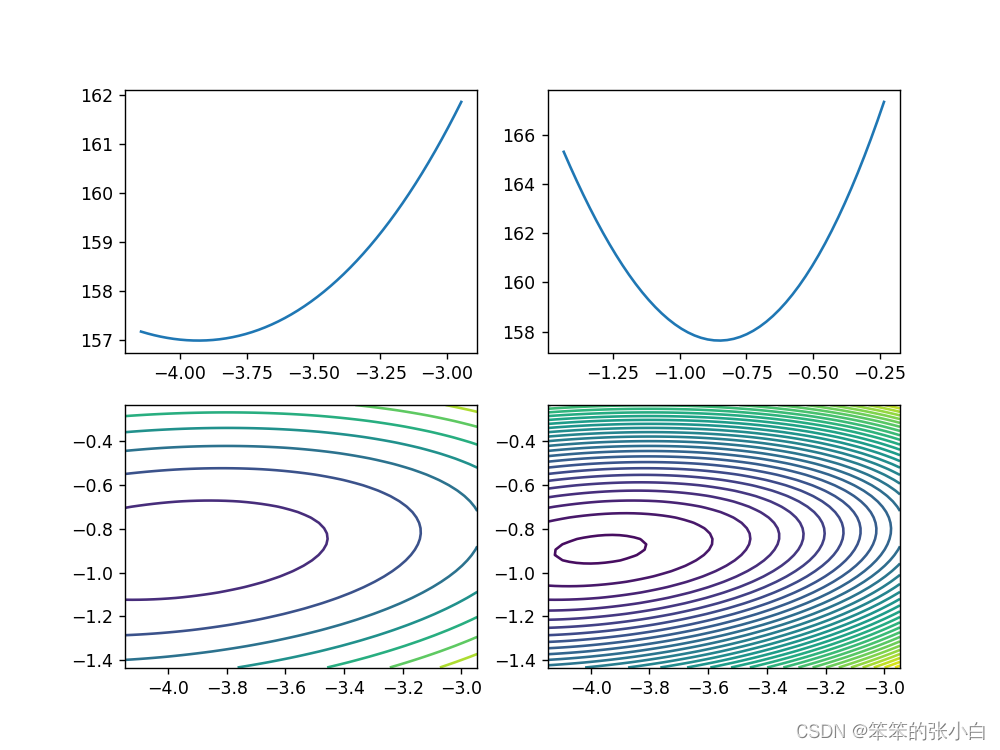
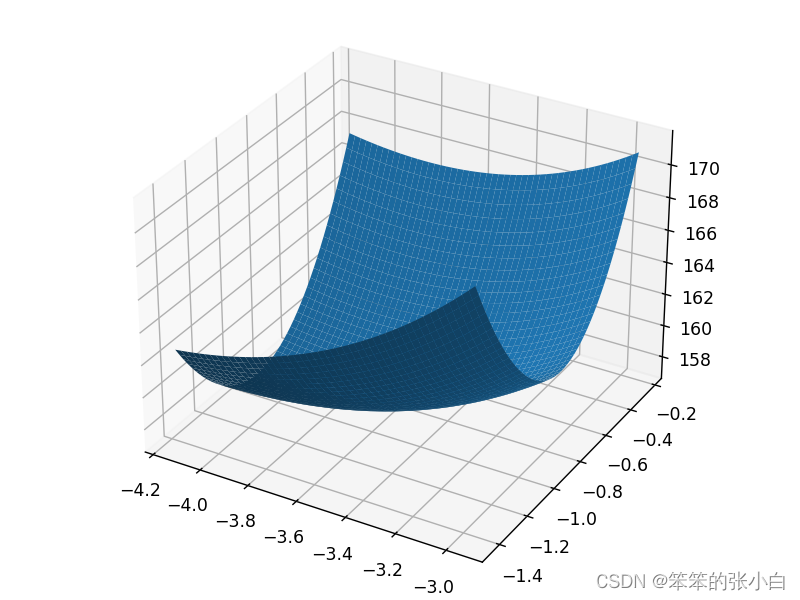
逻辑回归如何求解得到最优解模型
对θ求偏导
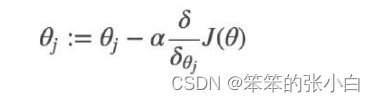
逻辑回归函数求导

回到对逻辑回归损失函数求导
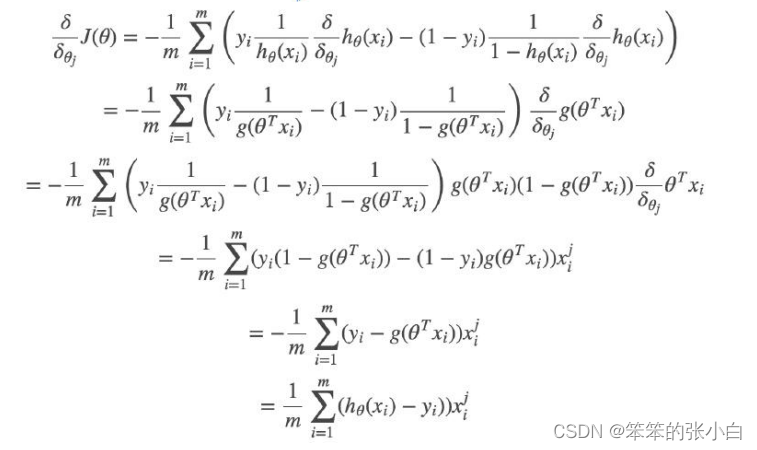
实战鸢尾花分类
先来实现简单的二分类
- import numpy as np
- from sklearn import datasets
- from sklearn.linear_model import LogisticRegression
- # 加载鸢尾花数据集
- iris = datasets.load_iris()
- # 这里我们以鸢尾花数据的最后一个特征拿来进行预测,也可以都进行去训练模型,但是后面预测的时候也要传入相应的所有特征值
- X = iris['data'][:, 3:]
- # 因为要做二分类,原始数据是3个种类,所有这里我们将第一二归为一类,第三类归为一类
- y = (iris['target'] == 2).astype(np.int)
- # 导入逻辑回归模型
- multi_classifier = LogisticRegression(solver='sag',max_iter=1000,multi_class='multinomial')
- # 训练模型
- multi_classifier.fit(X, y)
- # 我们创建1000个样本来进行模型预测
- X_new = np.linspace(0, 3, 1000).reshape(-1, 1)
- # 打印模型预测各个数据的概率
- y_proba = multi_classifier.predict_proba(X_new)
- print(y_proba)
- # 打印模型预测的种类
- y_hat = multi_classifier.predict(X_new)
- print(y_hat)
- [[9.99894620e-01 1.05379741e-04]
- [9.99892853e-01 1.07146756e-04]
- [9.99891057e-01 1.08943398e-04]
- ...
- [5.96947025e-04 9.99403053e-01]
- [5.87107189e-04 9.99412893e-01]
- [5.77429455e-04 9.99422571e-01]]
这是模型预测是哪种类的概率,第一行表示第一条数据,第一列表示预测是第一个种类的概率,第二列表示预测是第二类种类的概率
- [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1
- 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
- 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
- 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
- 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
- 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
- 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
- 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
- 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
- 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
- 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
- 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
- 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
- 1]
这表示的是这1000条数据对应预测出来的种类
逻辑回归如何做多分类
多分类任务
在上面,我们主要使用逻辑回归解决二分类的问题,那对于多分类的问题,也可以用逻 辑回归来解决? 多分类问题 将邮件分为不同类别/标签:工作(y=1),朋友(y=2),家庭(y=3),爱好(y=4) 天气分类:晴天(y=1),多云天(y=2),下雨天(y=3),下雪天(y=4) 医学图示(Medical diagrams):没生病(y=1),感冒(y=2),流感(y=3)
One-vs-all(one-vs-rest),生成三个假的数据集

其思想就是把多分类的任务拆分成多个二分类的任务,进而用逻辑回归进行预测
处理过的数据集就是二分类问题,通过逻辑回归可能得到红线区分不同类别:
同理
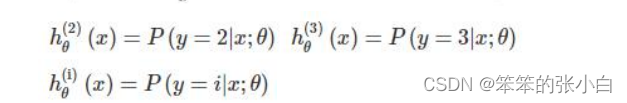
使用不同的函数去预测输入 x,分别计算不同 h(x)的值,然后取其中的最大值。哪个 i 对应 的 h(x)越大,就认为属于哪个类

对鸢尾花数据集做多分类
- import numpy as np
- from sklearn import datasets
- from sklearn.linear_model import LogisticRegression
- # 加载鸢尾花数据集
- iris = datasets.load_iris()
- # 这里我们以鸢尾花数据的最后一个特征拿来进行预测,也可以都进行去训练模型,但是后面预测的时候也要传入相应的所有特征值
- X = iris['data'][:, 3:]
- # 这里我们就直接对原始数据进行多分类预测
- y = y = iris['target']
- # 导入逻辑回归模型
- multi_classifier = LogisticRegression(solver='sag',max_iter=1000,multi_class='multinomial')
- # 训练模型
- multi_classifier.fit(X, y)
- # 我们创建1000个样本来进行模型预测
- X_new = np.linspace(0, 3, 1000).reshape(-1, 1)
- # 打印模型预测各个数据的概率
- y_proba = multi_classifier.predict_proba(X_new)
- print(y_proba)
- # 打印模型预测的种类
- y_hat = multi_classifier.predict(X_new)
- print(y_hat)
- [[9.67659931e-01 3.23060599e-02 3.40089121e-05]
- [9.67246970e-01 3.27181539e-02 3.48757477e-05]
- [9.66828912e-01 3.31353239e-02 3.57644824e-05]
- ...
- [2.34265543e-07 3.68448418e-03 9.96315282e-01]
- [2.28355838e-07 3.63890382e-03 9.96360868e-01]
- [2.22595088e-07 3.59388530e-03 9.96405892e-01]]
这是模型预测是哪种类的概率,第一行表示第一条数据,第一列表示预测是第一个种类的概率,第二列表示预测是第二类种类的概率,第三列表示预测是第三类的概率
- [0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
- 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
- 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
- 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
- 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
- 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
- 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
- 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
- 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2
- 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
- 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
- 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
- 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
- 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
- 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
- 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
- 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
- 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
- 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
- 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
- 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
- 2]
这表示的是这1000条数据对应预测出来的种类
以上就是逻辑回归的使用
-
相关阅读:
python3内置全局函数
6183. 字符串的前缀分数和(每日一难phase2--day18)
2023 AZ900备考
【校招VIP】数据库理论之数据库范式
CF803F
矩阵求导公式的数学推导四部曲
redis数据库简介
Meta Learning
「创作之秋」关于线程池,你需要了解这些
BeautifulSoup4库
- 原文地址:https://blog.csdn.net/m0_64336780/article/details/124872477