总结一下python里面常见安全问题,文章大部分内容来自MisakiKata师傅的python_code_audit项目,对原文进行了一些修改,后续会使用编写了规则对代码里面是否用到这些危险函数进行相应检测
SQL注入
SQL注入漏洞的原因是用户输入直接拼接到了SQL查询语句里面,在python Web应用中一般都是用orm库来进行数据库相关操作,比如Flask和Tornado经常使用Sqlalchemy,而Django有自己自带的orm引擎。
但是如果没有使用orm,而直接拼接sql语句的话就会存在SQL注入的风险
在Django中的示例代码,此处就存在SQL注入
Flask中使用SQLAlchemy进行数据库操作
对应的原始SQL语句如下
一般来说这种情况下就不会出现SQL注入了,但在某些我们没有正确使用API操作的时候还是会存在SQL注入漏洞,例如phithon的Pwnhub Web题Classroom题解与分析
其中最关键的部分view.py的代码如下
可以看到这一行代码stu = models.Student.objects.filter(**data).first()
我们传入的data数据直接被带入了filter语句,在前面的介绍中,filter的操作是这样的.filter(User.id == id),这两者的不同之处在于前者的参数名被我们所控制,进而可以查询我们想要的数据
另外虽然ORM框架能防御SQL注入,但使用不当的情况下还会造成二次注入,例如
当我们保存字段filename的时候,如果filename的值是' or '1'='1,则会被转义为\' or \'1\'=\'1,但是其中的单引号并不会被去除,而是被当作字符串被保存到数据库中,在后续的过程中被触发SQL注入漏洞
cur.execute("""select * from code_audit_file where filename='%s'""" %(filename))
因为正则匹配规则的死板,二次注入或者Django的历史漏洞想要在正则匹配中写出通用的规则是非常困难的,也需要有庞大的规则库才能实现
借鉴``代码中select查询正则如下,删改查操作的正则匹配也类似
"select\s{1,4}.{1,60}from.{1,50}where\s{1,3}.{1,50}=["\s\.]{0,10}\$\w{1,20}((\[["']|\[)\${0,1}[\w\[\]"']{0,30}){0,1}"
RCE
常见的执行命令模块和函数有
- os
- subprocess
- pty
- codecs
- popen
- eval
- exec
- ...
包括我自己在最开始写爬虫的时候也会有这种不规范:
如果反制爬虫的URL为"http://evil.com|rm -rf / &,进一步也可以控制服务器权限
CTF题目里面常见的命令执行操作ping
动态调用实现
又比如使用eval将字符串转字典
如果json1可控也会造成RCE
subprocess.run的案例
subprocess是一个为了代替os其中的命令执行库而出现的,python3.5以后的版本,建议是使用subprocess.run来操作,3.5之前的可以使用库中你认为合适的函数。不过实际上都是基于subprocess.Popen的封装实现的,也可以执行使用subprocess.Popen来执行较复杂的操作,在shell=False的时候,第一个字符是列表,或者传入字符串。当使用shell=True的时候,python会调用/bin/sh来执行命令,届时会造成命令执行。
XSS
XSS和SQL注入相同点都是对用户的输入参数没有过滤和正确引用,导致输出的时候造成代码注入到页面上
示例如下
Django上的XSS示例
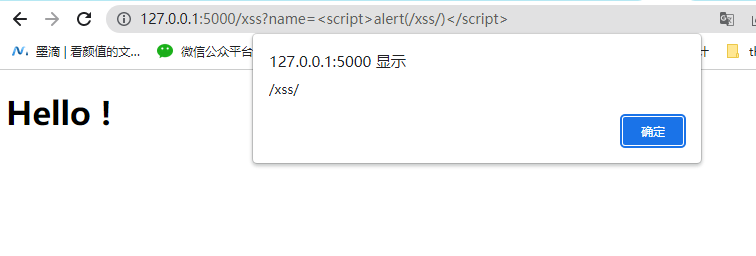
Flask上的XSS示例
在flask中使用render_template能够防御XSS漏洞,但在使用safe过滤器的情况下还是会导致XSS
前端代码为
XXE
XML外部实体注入。当允许引用外部实体时,通过构造恶意内容,就可能导致任意文件读取、系统命令执行、内网端口探测、攻击内网网站等危害
在python中有三种方法解析XML:
- SAX
xml.sax.parse()
- DOM
xml.dom.minidom.parse()xml.dom.pulldom.parse()
- ElementTree
xml.etree.ElementTree()
另外python中第三方xml解析库也很多,libxml2是使用C语言开发的xml解析器,而lxml是python基于libxml2开发的,该库存在XXE漏洞
存在漏洞的示例代码
此处利用file协议读取服务器上的敏感文件,漏洞存在的原因是XMLparse方法中resolve_entities默认设置为True,导致可以解析外部实体
下表概述了标准库XML已知的攻击以及各种模块是否容易受到攻击。
| 种类 | sax | etree | minidom | pulldom | xmlrpc |
|---|---|---|---|---|---|
| billion laughs | 易受攻击 | 易受攻击 | 易受攻击 | 易受攻击 | 易受攻击 |
| quadratic blowup | 易受攻击 | 易受攻击 | 易受攻击 | 易受攻击 | 易受攻击 |
| external entity expansion | 安全 (4) | 安全 (1) | 安全 (2) | 安全 (4) | 安全 (3) |
| DTD retrieval | 安全 (4) | 安全 | 安全 | 安全 (4) | 安全 |
| decompression bomb | 安全 | 安全 | 安全 | 安全 | 易受攻击 |
一些版本比较低的第三方解析excel库内部是使用lxml模块实现的,采用的也是默认配置,导致存在XXE漏洞,例如openpyxl<=2.3.5
CSRF
因为flask的设计哲学,所以在flask中默认没有csrf的防护
但是用户可以自行选择使用扩展插件flask_wtf.csrf实现让所有模块接受csrf防护
如果想要取消某个路由的csrf防护,则使用装饰器
Django中默认存在csrf中间件django.middleware.csrf.CsrfViewMiddleware,但是也可以通过@csrf_exempt进行某个视图的取消保护
如果设置中取消了默认的中间件,也可以通过@csrf_protect对路由进行token防护
SSRF
代码中存在网络请求的时候就可能有SSRF漏洞
python的可以造成这种问题的常用请求库:
- pycurl
- urllib
- urllib3
- requests
因为我个人用requests比较多,这里就以requests为案例
不过requests有一个Adapter的字典,请求类型为http://或者https://,在某种程度上也算有限制
要是需要利用来读取文件,可以配合requests_file来增加对file协议的支持。
python中另外两个URL请求的库相比就没有这么多限制,能够构造的SSRF payload就更多
关于python SSRF的防御,P师傅早年写过一篇文章谈一谈如何在Python开发中拒绝SSRF漏洞,虽然有的方法现在已经不适用了,但可以进行思路上的启发
SSTI
不同语言在使用模板渲染的时候都有可能存在模板注入漏洞,python中以flask为例:
其中大概有两个点是值得在意的,一个是格式化字符串,另一个是函数render_template_string。其是这两个更像是配合利用,像这么使用就不会有这个问题
这么看的话,问题出在格式化字符串上面,而非某个函数render_template_string上,当前者传入{{config}}时,会被模板当作合法语句来执行,而后者会把参数当作字符串处理而不进行相关解析。
为了安全模板引擎基本上都拥有沙盒环境,模板注入并不会直接解析python代码造成任意代码执行,所以想要利用SSTI一般还需要配合沙箱逃逸,例如
沙箱逃逸不是我们这里的重点,就不进一步阐述了。
在django中,使用一些IDE创建项目的时候可以很明显看到,使用的模板是Django模板,当然我们也可以使用jinja2模板,不过django自己的模板并是很少见过ssti这种问题,倒是由于格式化字符串导致信息泄露,如下使用两种格式化字符串才造成问题的情况。
其中,当name传入{user.password}会读取到登陆用户的密码,此处使用管理员账号。那么为什么会传入的参数是name,而下面解析的时候被按照变量来读取了。
使用format来格式化字符串的时候,我们设定的user是等于request.user,而传入的是{user.password},相当于template是<p>user:{user}, name:{user.password}<p1>,这样再去格式化字符串就变成了,name:request.user.password,导致被读取到信息。
在format格式符的情况下,出现ssti的情况也极少,比如使用如下代码,只能获得一个eval函数调用,format只能使用点和中括号,导致执行受到了限制。
p牛给过两个代码用来利用django读取信息
http://localhost:8000/?email={user.groups.model._meta.app_config.module.admin.settings.SECRET_KEY}http://localhost:8000/?email={user.user_permissions.model._meta.app_config.module.admin.settings.SECRET_KEY}
再找几个也可以使用的,上面都是直接使用auth模块来执行,因此可以先使用{user.groups.model._meta.apps.app_configs}找到包含的APP。
{user.groups.model._meta.apps.app_configs[auth].module.middleware.settings.SECRET_KEY}{user.groups.model._meta.apps.app_configs[sessions].module.middleware.settings.SECRET_KEY}{user.groups.model._meta.apps.app_configs[staticfiles].module.utils.settings.SECRET_KEY}
文件操作
文件操作即文件的增删查改
增和改都可以利用write方法
当使用write的时候就容易出现任意文件上传漏洞
django中的一个文件上传样例:
在这些样例代码中都存在未限制文件大小,未限制文件后缀等问题,但上传上去的python文件会像例如php一句话木马一样被解析吗
我们知道flask,Django都是通过路由来进行请求,如果我们单纯上传一个python文件,并不会造成常规的文件上传利用,除非后续处理用使用了eval
但如果使用Apache和python的环境开发,那就跟常规的网站类似了,例如在httpd.conf中配置了对python的解析存在一段AddHandler mod_python .py。那么通过链接请求的时候,比如http://www.xxx.com/test.py,python文件就会被正常解析。
还有一种是文件名的文件覆盖,例如功能需要批量上传,允许压缩包形式上传文件,然后解压到用户资源目录,如果此处存在问题,可能会覆盖关键文件来造成代码执行。比如__init__.py文件。
以上就是一个上传压缩包并且解压到目录的代码,他会按照解压出来的文件夹和文件进行写入目录。构造一个存在问题的压缩包,上传后可以看到文件并不在uploadfile目录,而在根目录下
项目如果被重新启动,就会看到界面输出了test字段。
python中也提供了一种安全的方法来解压,``zipfile.extract替换zipfile.ZipFile,但是并不代表extractall`也是安全的。
使用os.remove对文件进行删除
任意文件删除的案例如下,这个方法是用来删除七天后的文件,通过django的文件系统来获取目录下的文件,然后根据时间来删除。唯一的问题是dir_path,但是原系统中不存在问题,只是因为使用的时候这个目录是硬编码进去的。
当传入参数为file协议的形式就可以读取系统上任意文件
当然也可以用刚才的文件读取模块来读取
flask中还有一个文件读取下载的方法send_from_directory,操作不当的时候也能够进行敏感文件读取
反序列化
Python 的序列化的目的也是为了保存、传递和恢复对象的方便性,在众多传递对象的方式中,序列化和反序列化可以说是最简单和最容易实现的方式
Python 为我们提供了两个比较重要的库 pickle 和 cPickle以及几个比较重要的函数来实现序列化和反序列化,这里以pickle为例
- 序列化
- pickle.dump(文件)
- pickle.dumps(字符串)
- 反序列化
- pickle.load(文件)
- pickle.loads(字符串)
其中可造成威胁的一般是pickle.load和pickle.loads,或者面向对象的反序列化类pickle.Unpickler。
python官方认为并不没有义务保证你传入反序列化函数的内容是安全的,官方只负责反序列化,如果你传入不安全的内容那么自然就是不安全的
这里不得不提一下__reduce__ 魔术方法:
当序列化以及反序列化的过程中中碰到一无所知的扩展类型(这里指的就是新式类)的时候,可以通过类中定义的
__reduce__方法来告知如何进行序列化或者反序列化
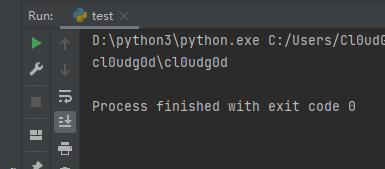
我们只要在新式类中定义一个 __reduce__ 方法,就能在序列化的使用让这个类根据我们在__reduce__ 中指定的方式进行序列化,当__reduce__返回值是一个元祖的时候,可以提供2到5个参数,我们重点利用的是前两个,第一个参数是一个callable object(可调用的对象),第二个参数可以是一个元祖为这个可调用对象提供必要的参数,示例代码如下
成功执行命令
Marshal库序列化code对象,使用的load和loads方法会导致问题
PyYAML库是yaml标记语言的python实现库,支持yaml格式的语言,有自己的实现来进行yaml格式的解析。yaml有一套对象转化规则,pyyaml在解析数据的时候遇到特定格式数据会自动转换。
比如,使用如下转换,实际是使用python模块执行了命令
可以构造命令的python语法,有!!python/object/apply和!!python/object/new两种。!!python/object接收的是一个dict类型的对象属性。并不接收args的列表参数。
jsonpickle用于将任意对象序列化为JSON的Python库。该对象必须可以通过模块进行全局访问,并且必须继承自对象(又称新类)。
创建一个对象:
使用Jsonpickle将对象转换为JSON字符串:
使用Jsonpickle从JSON字符串重新创建Python对象:
thawed = jsonpickle.decode(frozen)
可以使用类似的利用方式:
Shelve是对象持久化保存方法,将对象保存到文件里面,缺省(即默认)的数据存储文件是二进制的。
由于shelve是使用pickle来序列化数据,所以可以使用pickle的方式来执行命令
任意URL跳转
任意URL的跳转案例
总结
python里面的安全问题还有很多,这里也只是列举了一些常见并且危害较大的漏洞,还需要在后续不断总结。如何在自动化白盒审计中检测到这些漏洞?使用传统的正则表达式匹配危险函数局限性非常大,误报导致代码审计人员花费大量时间回溯危险函数的调用;利用AST语法树的方式辅助代码审计现在逐步成为主流,以CodeQL为例,需要自己先学习QL语言,然后编写匹配规则,不同语言的规则库不同这些问题无形之中拉高了学习门槛,其本身也有标准库覆盖不完全等问题
所以编写一个python的白盒代码审计系统就是后续的工作啦:-)
参考链接
- https://github.com/bit4woo/python_sec
- http://xxlegend.com/2015/07/30/Python安全编码和代码审计/
- Python_Hack_知道创宇_北北(孙博)
- http://blog.neargle.com/2016/07/22/pythonweb-framework-dev-vulnerable/
- http://xxlegend.com/2015/07/31/Python eval的常见错误封装及利用原理/
- https://www.k0rz3n.com/2018/11/12/一篇文章带你理解漏洞之Python 反序列化漏洞/
END
建了一个微信的安全交流群,欢迎添加我微信备注进群,一起来聊天吹水哇,以及一个会发布安全相关内容的公众号,欢迎关注 😃


__EOF__

本文链接:https://www.cnblogs.com/Cl0ud/p/16213353.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!