-
记录些MySQL题集(7)
1. 什么是SQL?
SQL 的全称是
Structured Query Language,即结构化查询语言,它是用来与关系型数据库管理系统(RDBMS)交互的语言,包括从表中获取、更新、插入和删除数据,也就是我们常说的增删改查。2. 什么是 SQL 方言?
SQL 包括多种免费或付费的版本,这些不同的版本都被称为 SQL 方言。各种 SQL 方言的语法非常相似,只是功能有些差别。如 Microsoft SQL Server、PostgreSQL、MySQL、SQLite、T-SQL、Oracle 等。
3. SQL的主要应用有哪些?
使用 SQL,可以实现以下功能。
-
创建、删除和更新数据库中的表。
-
访问、操作和修改表中的数据。
-
从一个或多个表中提取和总结的信息。
-
在表中添加或删除某些行或列。
总之,SQL 允许以多种方式查询数据库,还可以轻松地与 Python 或 R 等编程语言集成。
4. 什么是 SQL 语句?举一些例子。
SQL语句也叫 SQL 命令,由 SQL 引擎解释并执行。SQL 语句包括
SELECT、CREATE、DELETE、DROP和REVOKE等。5. 有哪些类型的 SQL 命令(或 SQL 子集)?
-
数据定义语言 (DDL) – 定义和修改数据库的结构。
-
数据操作语言 (DML) – 访问、操作和修改数据库中的数据。
-
数据控制语言 (DCL) – 控制用户对数据库中数据的访问,并授予或撤销特定用户或一组用户的权限。
-
事务控制语言 (TCL) – 控制数据库中的事务。
-
数据查询语言 (DQL) – 对数据库中的数据执行查询以从中检索必要的信息。
6. 请给出一些常见 SQL 命令。
-
DDL:
CREATE、ALTER、TABLE、DROP、TRUNCATE、ADD COLUMN -
DML:
UPDATE、DELETE、INSERT -
DCL:
GRANT、REVOKE -
TCL:
COMMIT、SET TRANSACTION、ROLLBACK、SAVEPOINT -
DQL:
SELECT
7. 什么是数据库?
数据库是一种结构化的存储空间,数据保存在表中,可供提取、操作和汇总数据信息。
8. 什么是 DBMS?你知道哪些类型的 DBMS?
DBMS 是数据库管理系统,可以对数据执行各种操作,如访问、更新、整理、插入和删除数据。
DBMS 有多种类型,如关系型、层次型、网络型、图型和面向对象型。这些类型的划分基于数据在系统中的组织、结构与存储方式。
9. 什么是关系型数据库管理系统?举一些 RDBMS 的例子。
RDBMS,即关系型数据库管理系统。它是最常见的数据库管理系统,用于处理存储表中的数据。SQL 是专门用于与关系型数据库交互的语言。主流的关系型数据库包括 MySQL、PostgreSQL、Oracle、MariaDB 等。
10. SQL中的表和字段是什么?
表是以表格形式存储的有组织的数据。字段是列的别称。
11. 什么是 SQL 查询,你知道哪些类型的查询?
SQL 查询是用于查询或修改数据库中数据的 SQL 代码。
SQL 查询有两种:选择查询和操作查询。第一种用于检索数据(包括限制、分组、排序数据,以及从多个表中提取数据等)。第二种 SQL 查询用于创建、添加、删除、更新、重命名数据等。
12. 什么是子查询?
子查询也称为内部查询,是在一个查询或外部查询中的查询。子查询可能出现在
SELECT、FROM、WHERE和UPDATE等子句中。子查询中还可以包含子查询。最里面的子查询首先运行,并将结果传递给它的外部查询。
13. 你知道哪些类型的 SQL 子查询?
-
单行子查询 – 最多返回一行。
-
多行子查询 – 返回至少两行。
-
多列子查询 – 返回至少两列。
-
相关子查询 - 与外部查询的信息相关的子查询。
-
嵌套子查询 – 子查询嵌套在另一个子查询中。
14. 什么是约束,为什么使用约束?
定义表中列的数据类型的条件。约束可确保表中数据的完整性,并阻止不需要的操作。
15. 你知道哪些 SQL 约束?
-
DEFAULT– 为列提供默认值。 -
UNIQUE– 只允许唯一值。 -
NOT NULL– 只允许非空值。 -
PRIMARY KEY– 必须是唯一值,且必须是非空值(NOT NULL和UNIQUE)。 -
FOREIGN KEY– 实现两个或多个表之间共享的键。
16. 什么是 join?
用于从多个表中提取数据记录的语句。SQL 表可以根据表之间的关系进行连接。
17. join 的类型都有哪些?
-
(INNER) JOIN– 只返回满足两个(或所有)表中定义的 join 条件的记录。这是默认的 SQL 连接。 -
LEFT (OUTER) JOIN– 返回左表中的所有记录及右表中满足定义的 join 条件的记录。 -
RIGHT (OUTER) JOIN– 返回右表中的所有记录及左表中满足定义的 join 条件的记录。 -
FULL (OUTER) JOIN– 返回两个(或所有)表中的所有记录。它是左连接和右连接的组合。
18. 什么是主键?
把表的一列或多列设置为主键可以约束该列中的值是唯一值,而且必须是非空值。主键是
NOT NULL和UNIQUE约束的组合。主键确保表中的每条记录都是唯一的,每个表都应该包含主键,但不能包含多个主键。19. 什么是唯一键?
把表的一列或多列设置为
UNIQUE可以约束该列中的值是唯一值,即便NULL值也只能是唯一的。20. 什么是外键?
把表的一列或多列设置为
FOREIGN KEY可以将该列与另一个表(或多个表)中的主键相关联。外键用于把数据库的多个表连接起来。21. 什么是索引?
索引用于实现更快的数据检索。索引可以显著提高大型数据库的查询性能。
22. 你知道哪些类型的索引?
-
唯一索引 – 不允许表的列中存在重复项,便于维护数据完整性。
-
聚合索引 – 定义数据库表中记录的物理顺序,并根据键值进行数据搜索。一张表只能有一个聚合索引。
-
非聚合索引 – 表的记录顺序与磁盘数据的物理顺序不匹配。这意味着数据存储在一个位置,非聚合索引存储在另一个位置。一个表可以有多个非聚合索引。
23. 什么是 schema?
schema 是表、存储过程、索引、函数和触发器等数据库结构元素的集合,是数据库的总体架构,指定了数据库中对象之间的关系,并为它们定义不同的访问权限。
24. 什么是 SQL 注释?
SQL 代码注释可以是单行注释(
--),也可以是多行注释(/*comment_text*/)。SQL 引擎运行时会忽略代码注释。注释是为了让人更方便地阅读代码。25. 什么是 SQL 运算符?
用于执行特定操作的保留字符或关键字。SQL 运算符通常与
WHERE子句一起使用,以设置过滤数据的条件。26. 你知道哪些类型的 SQL 运算符?
-
算术运算符:
+、-、*、/ -
比较运算符:
>、<`、`=`、`>= -
复合运算符:
+=、-=、*=、/= -
逻辑运算符:
AND、OR、NOT、BETWEEN -
字符串运算符:
%、_、+、^ -
集合运算符:
UNION、UNION ALL、INTERSECT、MINUS或EXCEPT
27. 什么是别名?
执行 SQL 查询时为表(或表中的列)指定的临时名称。使用别名是为了提高代码的可读性,使代码更加简洁。别名的关键字是
AS:- SELECT col_1 AS column
- FROM table_name;
28. 什么是子句?
SQL 查询的条件,用于过滤数据以获得查询的结果。如,
WHERE、LIMIT、HAVING、LIKE、AND、OR、ORDER BY等。29. SELECT 查询中常用的语句有哪些?
主要有
FROM、GROUP BY、JOIN、WHERE、ORDER BY、LIMIT、HAVING等。30. 如何创建表?
使用
CREATE TABLE。例如,要创建一个包含 3 列预定义数据类型的表。- CREATE TABLE table_name (col_1 datatype,
- col_2 datatype,
- col_3 datatype);
31. 如何更新表?
使用
UPDATE语句。- UPDATE table_name
- SET col_1 = value_1, column_2 = value_2
- WHERE condition;
32. 如何从数据库中删除表?
使用
DROP TABLE声明。语法是:DROP TABLE table_name;。33. 如何获取表中的记录数?
使用聚合函数
COUNT():SELECT COUNT(*) FROM table_name;。34. 如何排序表中的记录?
使用
ORDER BY语句。- SELECT * FROM table_name
- ORDER BY col_1;
默认排序为升序,使用关键字
DESC可以指定降序的列。还可以实现多列排序,分别指定每一列是升序还降序。例如:- SELECT * FROM table_name
- ORDER BY col_1 DESC, col_3, col_6 DESC;
35. 如何选择表中的所有列?
在
SELECT语句中使用星号*。语法是:SELECT * FROM table_name;36. 如何从两个表中选取共同的记录?
使用
INTERSECT语句,示例如下。- 1 SELECT * FROM table_1
- 2 INTERSECT
- 3 SELECT * FROM table_1;
37. 什么是 DISTINCT 语句,如何使用?
DISTINCT可以与SELECT一起使用,以过滤掉重复项,并仅返回表中列的唯一值。示例如下。- 1 SELECT DISTINCT col_1
- 2 FROM table_name;
38. 什么是实体?举一些例子。
实体是可以收集并存储到数据库表中的现实世界中的对象数据。每个实体对应于表中的一行,表的列描述其属性。实体的示例包括银行交易、学校学生、销售的汽车等。
39. 什么是关系?举一些例子。
关系是实体之间的连接,是指数据库中的多个表如何相互关联。例如,可以在销售数据表和客户表中找到同一客户的 ID。
40. 什么是 NULL?它与 0 或空格有什么不同?
NULL表示表格中的某个单元格不存在数据。0 是有效的数值,空字符串是长度为 0 的合法字符串。
41. SQL 中什么是函数,为什么要使用函数?
函数是执行特定任务的一组 SQL 语句。函数接收输入参数,对它们执行计算或其他操作,然后返回结果。函数有助于提高代码可读性,并避免重复相同的代码片段。
42. 你知道哪些类型的 SQL 函数?
-
聚合函数 – 针对处理分组表中列的记录,并返回单个值(通常按组)。
-
标量函数 – 处理每个单独的值,并返回单个值。
另一方面,SQL 函数可以是内置的,或用户定义的(由用户根据其特定需求创建)。
43. 你知道哪些聚合函数?
-
AVG()– 返回平均值。 -
SUM()– 返回值的和。 -
MIN()– 返回最小值。 -
MAX()– 返回最大值。 -
COUNT()– 返回行数,包括具有空值的行数。 -
FIRST()– 返回列中的第一个值。 -
LAST()– 返回列中的最后一个值。
44. 你知道哪些标量函数?
-
LEN()(或LENGTH()) – 返回字符串的长度,包括空格。 -
UCASE()(或UPPER()) – 返回转换为大写的字符串。 -
LCASE()(或LOWER()) – 返回转换为小写的字符串。 -
INITCAP()– 返回转换为首字母大写的字符串。 -
MID()(或SUBSTR()) – 从字符串中提取子字符串。 -
ROUND()– 返回四舍五入到指定小数位数的数值。 -
NOW()– 返回当前日期和时间。
45. 什么是大小写处理函数?举一些例子。
大小写处理函数是文本函数,用于更改文本数据的大小写,可以将数据转换为大写、小写或首字母大写。
-
UCASE()(或UPPER()) – 返回转换为大写的字符串。 -
LCASE()(或LOWER()) – 返回转换为小写的字符串。 -
INITCAP()– 返回转换为首字母大写的字符串。
46. 什么是字符操作函数?举一些例子。
字符操作函数代表字符函数的子集,它们用于修改文本数据。
-
CONCAT()– 连接多个字符串值,将后一个字符串附加到前一个字符串的末尾。 -
SUBSTR()– 返回满足所提供的起点和终点的字符串的一部分。 -
LENGTH()(或LEN()) – 返回字符串的长度,包括空格。 -
REPLACE()– 用一个子字符串替换提供的字符串中所有出现的已定义子字符串。 -
INSTR()– 返回给定字符串中定义的子字符串的数字位置。 -
LPAD()/RPAD()– 返回右对齐/左对齐值的左侧/右侧字符的填充。 -
TRIM()– 从提供的字符串的左侧、右侧或两端删除所有定义的字符及空格。
47. 局部变量和全局变量有什么区别?
局部变量只能在声明该变量的函数内部访问。
在函数外部声明的全局变量存储在内存结构中,可以在整个程序中使用。48. ORDER BY 语句的默认排序是什么??如何更改?
ORDER BY语句的默认排序是升序。要改为降序,需要添加DESC关键字,示例如下。- SELECT * FROM table_name
- ORDER BY col_1 DESC;
49. 你知道哪些集合运算符?
-
UNION– 返回多个查询语句的结果合并后的唯一记录集(不包括重复项)。 -
UNION ALL– 返回多个查询语句的结果合并后的记录集(包括重复项)。 -
INTERSECT– 返回多个查询语句的结果交集的记录集。 -
EXCEPT(MySQL 和 Oracle 中为MINUS) – 仅返回第一个语句查询的结果,不返回第二个查询的结果。
50. 查询中使用什么运算符进行模式匹配?
LIKE运算符与%和_通配符结合使用。通配符%代表任意数量的字符,包括 0 个字符;_严格来说是一个字符。51. 主键和唯一键有什么区别?
两种类型的键都确保列中的值唯一,但主键唯一标识表中的每个记录,唯一键则防止该列中出现重复项。
52. 什么是复合主键?
表的主键,基于多个列。
53. SELECT 查询中常见语句的出现顺序是什么?
SELECT–FROM–JOIN–ON–WHERE–GROUP BY–HAVING–ORDER BY-LIMIT54. 解释器执行 SELECT 查询语句的顺序是什么?
FROM–JOIN–ON–WHERE–GROUP BY–HAVING–SELECT–ORDER BY–LIMIT55. 什么是视图,为什么要使用视图?
视图一种虚拟表,包含从一个或多个数据库表(或其他视图)中提取的数据。
视图占用的空间很少,还可以简化复杂的查询,限制对数据的访问以确保安全,实现数据独立性,并汇总多个表中的数据。
56. 可以基于一个视图再创建一个视图吗?
可以。这也叫嵌套视图。但要避免嵌套多个视图,因为代码会变得难以理解,调试也更加困难。
57. 原表删除后还可以使用视图吗?
不可以。删除基表后,任何基于该表的视图都将失效。使用这样的视图时,将收到错误消息。
58. 你知道哪些类型的 SQL 关系?
-
一对一 — 一个表中的每条记录仅对应于另一个表中的一条记录。
-
一对多 — 一个表中的每条记录对应另一个表中的多条记录。
-
多对多 — 两个表中的每条记录都对应于另一个表中的多条记录。
59. BOOLEAN 数据字段的值有哪些?
在 PostgreSQL 中,BOOLEAN 类型的值包括
TRUE、FALSE和NULL。在其他 SQL 方言中,如 SQL Server,BIT 类型用于将布尔值存储为整数1(true)或0(false)。60. SQL 中的范式(normalization )是什么,为什么要使用范式?
范式是数据库的设计过程,旨在减少数据冗余、提高数据一致性和完整性,让查询效率更高,也更灵活,常用的范式有第一范式(1NF)、第二范式(2NF)和第三范式(3NF)。
61. SQL 中的非范式(denormalization )是什么,为什么要使用非范式?
非范式是与范式相反的过程:它引入数据冗余,并组合来自多个表的数据。在读操作比写操作更重要的情况下,非范式可以优化数据库基础设施的性能,有助于避免复杂的连接,并减少查询运行的时间。
62. 重命名列与列的别名有什么区别?
重命名列意味着永久更改其在原始表中的实际名称。
为列指定别名意味着在执行 SQL 查询时为其指定一个临时名称,使代码更易读,更简洁。63. 嵌套子查询和相关子查询(correlated subquery)有什么区别?
相关子查询是嵌套在外部查询中的内部查询,该查询引用外部查询中的值来执行,这意味着相关子查询依赖于其外部查询。
SELECT employee_id, salary
FROM employees
WHERE salary > (SELECT AVG(salary) FROM employees);相反,非相关子查询不依赖于外部查询的数据,并且可以独立于外部查询运行。
64. 聚合索引和非聚合索引的区别是什么?
聚合索引定义表中记录的物理顺序,并根据键值执行数据搜索,而非聚合索引的记录顺序与磁盘上实际数据的物理顺序不匹配。一张表只能有一个聚合索引,但可以有多个非聚合索引。
65. CASE() 函数是什么?
SQL 中
if-then-else逻辑的实现方式。CASE()函数按顺序检查WHEN子句中的条件,在满足第一个条件时返回THEN子句中的值。如果没有满足任何条件,则该函数将返回ELSE子句中的值(如果已提供),否则返回NULL。- 1 CASE
- 2 WHEN condition_1 THEN value_1
- 3 WHEN condition_2 THEN value_2
- 4 WHEN condition_3 THEN value_3
- 5 ...
- 6 ELSE value
- 7 END;
66. DELETE 和 TRUNCATE 的区别是什么?
DELETE根据WHERE子句中的条件从表中删除一行或多行记录。TRUNCATE是用于删除表中的所有行,但包含外键的表不能使用TRUNCATE语句。DELETE的速度比TRUNCATE慢。67. DROP 和 TRUNCATE 的区别是什么?
DROP从数据库中完全删除表,包括表结构、约束条件、多表关系及访问权限。TRUNCATE删除表中的所有行的数据,但不涉及表的结构和约束条件。DROP的速度比TRUNCATE慢。两者都是不可逆的。
68. HAVING 和 WHERE 语句有什么区别?
HAVING对分组后的数据进行聚合处理。WHERE则核查每一行的数据。如果两个语句都出现在查询中,优先级为
WHERE–GROUP BY–HAVING。SQL 引擎按此顺序进行解析。
69. 如何向表中添加记录?
INSERT INTO与VALUES结合使用。- 1 INSERT INTO table_name
- 2 VALUES (value_1, value_2, ...);
70. 如何删除表中的记录?
使用
DELETE语句删除记录,可以搭配WHERE一起使用。- 1 DELETE FROM table_name
- 2 WHERE condition;
可以删除符合条件的多条记录。
71. 如何向表格添加列?
ALTER TABLE与ADD结合在一起使用。- 1 ALTER TABLE table_name
- 2 ADD column_name datatype;
72. 如何重命名表的列?
ALTER TABLE与RENAME COLUMN ... TO ...一起使用,示例如下。- 1 ALTER TABLE table_name
- 2 RENAME COLUMN old_column_name TO new_column_name;
73. 如何从表中删除列?
ALTER TABLE与DROP COLUMN一起使用,示例如下。- 1 ALTER TABLE table_name
- 2 DROP COLUMN column_name;
74. 如何选择表中的所有偶数或奇数的记录?
通过计算除以 2 的余数,实现这个操作。
在 PostgreSQL 或 My SQL 中,可以使用
MOD函数;在 SQL Server 和 SQLite 中使用%运算符。使用
MOD选择所有偶数记录的示例代码如下。- SELECT * FROM table_name
- WHERE MOD(ID_column, 2) = 0;
使用
%选择所有偶数记录的示例代码如下。- SELECT * FROM table_name
- WHERE ID_column % 2 = 0;
选择所有奇数记录时,其他的内容不变,用
<>运算符替代=即可。75. 查询时如何防止重复记录?
在
SELECT语句中使用DISTINCT,或为该表创建唯一键。76. 如何在表中插入多行数据?
使用
INSERT INTO与VALUES,示例如下。- 1 INSERT INTO table_name
- 2 VALUES (value_1, value_2, ...),
- 3 (value_3, value_4, ...),
- 4 (value_5, value_6, ...),
- 5 ...;
77. 如何找到表中某一列的第 n 个最高值?
使用
OFFSET子句。查找某列中的第 6 个最高值的示例如下。- 1 SELECT * FROM table_name
- 2 ORDER BY column_name DESC
- 3 LIMIT 1
- 4 OFFSET 5;
78. 如何查找表格文本列中以某个字母开头的值?
使用
LIKE运算符和%与_通配符。查找表中所有以A开头的姓的示例如下。- 1 SELECT * FROM table_name
- 2 WHERE surname LIKE 'A_';
假设姓里必须包含至少两个字母。如果没有这个假设则代表姓可以只是 A,示例如下。
- 1 SELECT * FROM table_name
- 2 WHERE surname LIKE 'A%';
79. 如何查找表中最后一个 id?
使用
MAX()函数。在大部分 SQL 方言中的示例如下。- 1 SELECT id
- 2 FROM table_name
- 3 ORDER BY id DESC
- 4 LIMIT 1;
在 SQL Server 中的示例如下。
- 1 SELECT TOP 1 id
- 2 FROM table_name
- 3 ORDER BY id DESC
80. 如何从表中随机选择行?
在
ORDER BY、LIMIT中使用RAND()函数。在 PostgreSQL 中,使用RANDOM()。从 MySQL 的表中返回 5 个随机行的示例如下。
- 1 SELECT * FROM table_name
- 2 ORDER BY RAND()
- 3 LIMIT 5;
undo-log、redo-log、bin-log
一、Undo-log撤销日志
Undo即撤销的意思,但咱们通常也习惯称它为回滚日志,在日常开发过程中,如果代码敲错了,一般会习惯性的按下Ctrl+Z撤销,而Undo-log的作用也是如此,但它是用来给MySQL撤销SQL操作的。当一条写入类型的
SQL执行时,都会记录Undo-log日志,会生成相应的反SQL放入到Undo-log中,例如:-
如果目前是
insert插入操作,则生成一个对应的delete操作。 -
如果目前是
delete删除操作,InnoDB中会修改隐藏字段deleted_bit=1,则生成改为0的语句。 -
如果目前的
update修改操作,比如将姓名从竹子改成了熊猫,那就生成一个从熊猫改回竹子的操作。
当事务中某条
SQL执行失败时,MySQL就需要回滚事务中其他执行成功的SQL,此时就会找到这个事务在Undo-log中生成的反SQL,然后将库中的数据改回事务发生前的样子。实际上并不会生成反
SQL,这样去叙述仅是为了方便理解。那怎么证明不会生成反
SQL呢?如果有研究过MySQL的日志,应该会发现Undo-log并不存在单独的日志文件,也就是磁盘中并不会存在xx-undo.log这类的文件,那Undo-log存在哪儿呢?InnoDB默认是将Undo-log存储在xx.ibdata共享表数据文件当中,默认采用段的形式存储。也就是当一个事务尝试写某行表数据时,首先会将旧数据拷贝到
xx.ibdata文件中,将表中行数据的隐藏字段:roll_ptr回滚指针会指向xx.ibdata文件中的旧数据,然后再写表上的数据。那
Undo-log究竟在xx.ibdata文件中怎么存储呢?在共享表数据文件中,有一块区域名为Rollback Segment回滚段,每个回滚段中有1024个Undo-log Segment,每个Undo段可存储一条旧数据,而执行写SQL时,Undo-log就是写入到这些段中。不过在
MySQL5.5版本前,默认只有一个Rollback Segment,而在MySQL5.5版本后,默认有128个回滚段,即支持128*1024条Undo记录同时存在。1.1、对于事务回滚原理
当一个事务需要回滚时,本质上并不会以执行反
SQL的模式还原数据,而是直接将roll_ptr回滚指针指向的Undo记录,从xx.ibdata共享表数据文件中拷贝到xx.ibd表数据文件,覆盖掉原本改动过的数据。还是上个图简单理解一下吧,如下:
事务回滚原理
一条写SQL执行的流程如上图中的序号所示,当需要回滚事务时,直接用Undo旧记录覆盖表中修改过的新记录即可!如果是
insert操作,由于插入之前这条数据都不存在,那么就不会产生Undo记录,此时回滚时如何删除这条记录呢?因为插入操作不会产生Undo旧记录,因此隐藏字段中的roll_ptr=null,因此直接用null覆盖插入的新记录即可,这样也就实现了删除数据的效果~1.2、基于Undo版本链实现MVCC
Undo-log中记录的旧数据并不仅仅只有一条,一条相同的行数据可能存在多条不同版本的Undo记录,内部会通过roll_ptr回滚指针,组成一个单向链表,而这个链表则被称之为Undo版本链,案例如下:- -- 事务T1:trx_id=1(两次修改同一条数据)
- UPDATE `zz_users` SET user_name = "竹子" WHERE user_id = 1;
- UPDATE `zz_users` SET user_sex = "男" WHERE user_id = 1;
Undo-log中的旧数据版本链示意图大致如下:
Undo版本链
1.3、Undo-log的内存缓冲区
InnoDB在MySQL启动时,会在内存中构建一个BufferPool,而这个缓冲池主要存放两类东西,一类是数据相关的缓冲,如索引、锁、表数据等,另一类则是各种日志的缓冲,如Undo、Bin、Redo....等日志。而当一条写
SQL执行时,不会直接去往磁盘中的xx.ibdata文件写数据,而是会写在undo_log_buffer缓冲区中,因为工作线程直接去写磁盘太影响效率了,写进缓冲区后会由后台线程去刷写磁盘。如果当一个事务提交时,
Undo的旧记录会不会立马被删除呢?因为事务都提交了,不需要再回滚改动过的数据,似乎用不上Undo旧记录了。确实如此,但不会立马删除Undo记录,对于旧记录的删除工作,InnoDB中会有专门的purger线程负责,purger线程内部会维护一个ReadView,它会以此作为判断依据,来决定何时移除Undo记录。为什么不是事务提交后立马删除
Undo记录呢?因为可能会有其他事务在通过快照,读Undo版本链中的旧数据,直接移除可能会导致其他事务读不到数据,因此删除的工作就交给了purger线程。1.4、Undo-log相关的参数
最后再来看看关于
Undo-log的一些参数,其实在MySQL5.5之前没有太多参数,如下:-
innodb_max_undo_log_size:本地磁盘文件中,Undo-log的最大值,默认1GB。 -
innodb_rollback_segments:指定回滚段的数量,默认为1个。
除开上述两个参数外,其他参数基本上是在
MySQL5.6才有的,如下:-
innodb_undo_directory:指定Undo-log的存放目录,默认放在.ibdata文件中。 -
innodb_undo_logs:指定回滚段的数量,默认为128个,也就是之前的innodb_rollback_segments。 -
i
nnodb_undo_tablespaces:指定Undo-log分成几个文件来存储,必须开启innodb_undo_directory参数。 -
innodb_undo_log_truncate:是否开启Undo-log的在线压缩功能,即日志文件超过大小一半时自动压缩,默认OFF关闭。
没错,在
MySQL5.5版本以后,Undo-log日志支持单独存放,并且多出了几个参数可以调整Undo-log的区域。二、Redo-log重做日志
两日志都是
InnoDB引擎独有的,Undo-log主要用于实现事务回滚和MVCC机制,而Redo-log则用来实现数据的恢复。
事务恢复机制
2.1、为何需要Redo-log日志?
MySQL绝大部分引擎都是是基于磁盘存储数据的,但如若每次读写数据都走磁盘,其效率必然十分低下,因此InnoDB引擎在设计时,当MySQL启动后就会在内存中创建一个BufferPool,运行过程中会将大量操作汇集在内存中进行,比如写入数据时,先写到内存中,然后由后台线程再刷写到磁盘。虽然使用
BufferPool提升了MySQL整体的读写性能,但它是基于内存的,也就意味着随着机器的宕机、重启,其中保存的数据会消失,那当一个事务向内存中写入数据后,MySQL突然宕机了,岂不代表这条未刷写到磁盘的数据会丢失吗?答案是Yes,也正由于该原因,Redo-log应运而生!因为数据写到内存后有丢失风险,这明显违背了事务
ACID原则中的持久性,所以Redo-log的出现就是为了解决该问题,Redo-log是一种预写式日志,即在向内存写入数据前,会先写日志,当后续数据未被刷写到磁盘、MySQL崩溃时,就可以通过日志来恢复数据,确保所有提交的事务都会被持久化。但是要注意:工作线程执行
SQL前,写的Redo-log日志,也是写在了内存中的redo_log_buffer缓冲区。既然
Redo-log日志也是先写内存,那Redo-log有没有丢失的风险呢?这跟Redo-log的刷盘策略有关。2.2、Redo-log的刷盘策略
对于内存中的
redo_log_buffer缓冲区,其中写入的数据会何时被刷写到磁盘?
刷盘策略
简单来说就是刷盘的时机由
innodb_flush_log_at_trx_commit参数来控制,默认是处于第二个级别,也就是每次提交事务时都会刷盘,这也就意味着一个事务执行成功后,相应的Redo-log日志绝对会被刷写到磁盘中,因此无需担心会出现丢失风险。但再来思考一个问题:既然
Redo-log要写磁盘,那为何不在写日志的时候,直接把数据写到磁盘里面去呢?2.3、Redo-log中为何“多此一举”?
先刷写一次
Redo-log日志到磁盘,后台线程再根据Redo-log日志把数据落盘,这个动作似乎看起来有些多余对吧?但实际上这样做好处很大:-
①日志比数据先落入磁盘,因此就算
MySQL崩溃也可以通过日志恢复数据。 -
②写日志时是以追加形式写到末尾,而写数据时则是计算数据位置,随机插入。
写日志的时候,只需要将记录追加到日志文件的尾部即可,这是按顺序写入,但写入表数据时,还需要先先计算数据的位置,比如修改一条数据时,需要先判断这条数据在磁盘文件中的那个位置,找到了位置再写入,这是随机写入,顺序写入的速度会比随机写入快很多很多。
因为写日志会比写数据落盘快,因此日志落盘后返回,比数据落盘后返回要快,对于客户端而言,响应时间会更短~
2.4、Redo-log相关的参数
这里也列举出几个
Redo-log日志中,较为重要的系统参数:-
innodb_flush_log_at_trx_commit:设置redo_log_buffer的刷盘策略,默认每次提交事务都刷盘。 -
innodb_log_group_home_dir:指定redo-log日志文件的保存路径,默认为./。 -
innodb_log_buffer_size:指定redo_log_buffer缓冲区的大小,默认为16MB。 -
innodb_log_files_in_group:指定redo日志的磁盘文件个数,默认为2个。 -
innodb_log_file_size:指定redo日志的每个磁盘文件的大小限制,默认为48MB。
其中主要讲一下
Redo-log的本地磁盘文件个数,为啥默认是两个呢?因为MySQL通过来回写这两个文件的形式记录Redo-log日志,用两个日志文件组成一个“环形”,如下:
redo-log本地磁盘文件
先来简单解释一下图中存在的两根指针:
-
write pos:这根指针用来表示当前Redo-log文件写到了哪个位置。 -
check point:这根指针表示目前哪些Redo-log记录已经失效且可以被擦除(覆盖)。
两根指针中间区域,也就是图中的红色区域,代表是可以写入日志记录的可用空间,而蓝色区域则表示日志落盘但数据还未落盘的记录,这句话怎么理解呢?
当一个事务写了
redo-log日志、并将数据写入缓冲区后,但数据还未写到本地的表数据文件中,此时这个事务对应的redo-log记录就为上图中的蓝色,而当一个事务所写的数据也落盘后,对应的redo-log记录就会变为红色。当
write pos指针追上check point指针时,红色区域就会消失,也就代表Redo-log文件满了,再当MySQL执行写操作时就会被阻塞,因为无法再写入redo-log日志了,所以会触发checkpoint刷盘机制,将redo-log记录对应的事务数据,全部刷写到磁盘中的表数据文件后,阻塞的写事务才能继续执行。触发
checkpoint刷盘机制后,随着数据的落盘,check point指针也会不断的向后移动,红色区域也会不断增长,因此阻塞的写事务才能继续执行。再补齐一些关于
checkpoint机制的系统参数:-
innodb_log_write_ahead_size:设置checkpoint刷盘机制每次落盘动作的大小,默认为8K,如果你要设置,必须要为4k的整数倍,这跟read-on-write问题有关。 -
innodb_log_compressed_pages:是否对Redo日志开启页压缩机制,默认ON,这跟InnoDB的页压缩技术有关。 -
innodb_log_checksums:Redo日志完整性效验机制,默认开启,必须要开启,否则有可能刷写数据时,只刷一半,出现类似于“网络粘包”的问题。
三、Bin-log变更日志
Bin-log日志也被称之为二进制日志,作用与Redo-log类似,主要是记录所有对数据库表结构变更和表数据修改的操作,对于select、show这类读操作并不会记录。bin-log是MySQL-Server级别的日志,也就是所有引擎都能用的日志,而redo-log、undo-log都是InnoDB引擎专享的,无法跨引擎生效。
写SQL执行流程
看到这张写
SQL的执行流程图,重点观察里面的第⑨步,无论当前表使用的是什么引擎,实际上都需要完成记录bin-log日志这步操作,和之前分析的两种日志相同,bin-log也由内存日志缓冲区+本地磁盘文件两部分组成,这也就意味着:写bin-log日志时,也会先写缓冲区,然后由后台线程去刷盘。3.1、bin-log的缓冲区
bin-log的缓冲区跟redo-log、undo-log的缓冲区并不同,前面分析的两种日志缓冲区,都位于InnoDB创建的共享BufferPool中,而bin_log_buffer是位于每条线程中的,关系图如下: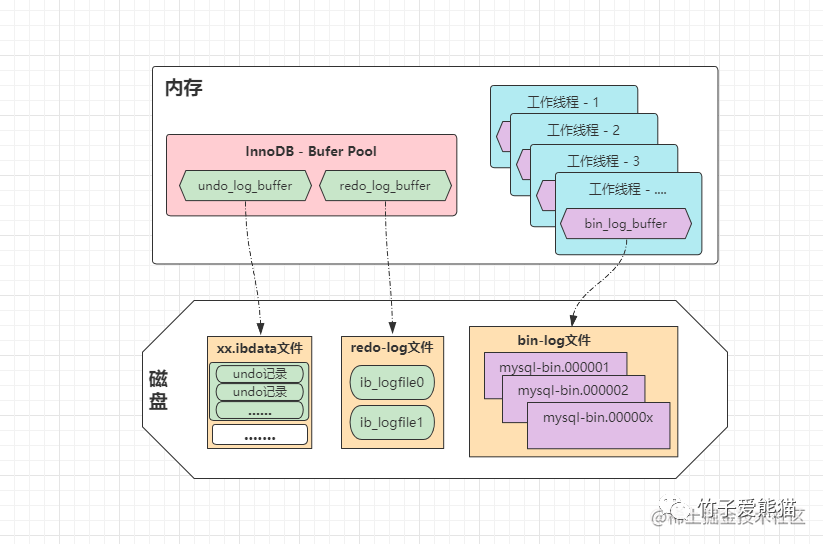
日志缓冲区与本地文件
也就是说,
MySQL-Server会给每一条工作线程,都分配一个bin_log_buffer,而并不是放在共享缓冲区中,这是为啥呢?因为MySQL设计时要兼容所有引擎,直接将bin-log的缓冲区,设计在线程的工作内存中,这样就能够让所有引擎通用,并且不同线程/事务之间,由于写的都是自己工作内存中的bin-log缓冲,因此并发执行时也不会冲突!简单理解
bin-log缓冲区的设计后,对于bin-log的刷盘策略就不反复赘述了,就是通过sync_binlog参数控制,与之前redo-log类似。3.2、Bin-log本地日志文件的格式
bin-log的本地日志文件,采用的是追加写的模式,也就是一直向文件末尾写入新的日志记录,当一个日志文件写满后,会创建一个新的bin-log日志文件,每个日志文件的命名为mysql-bin.000001、mysql-bin.000002、mysql-bin.00000x....,可以通过show binary logs;命令查看已有的bin-log日志文件。在
bin-log的本地文件中,其中存储的日志记录共有Statment、Row、Mixed三种格式。Statment:每一条会对数据库产生变更的SQL语句都会记录到bin-log中。- -- 查询一次用户表数据,如下:
- SELECT * FROM `zz_users`;
- +---------+-----------+----------+----------+---------------------+
- | user_id | user_name | user_sex | password | register_time |
- +---------+-----------+----------+----------+---------------------+
- | 1 | 熊猫 | 女 | 6666 | 2022-08-14 15:22:01 |
- | 2 | 竹子 | 男 | 1234 | 2022-09-14 16:17:44 |
- | 3 | 子竹 | 男 | 4321 | 2022-09-16 07:42:21 |
- | 4 | 猫熊 | 女 | 8888 | 2022-09-27 17:22:59 |
- | 9 | 黑竹 | 男 | 9999 | 2022-09-28 22:31:44 |
- +---------+-----------+----------+----------+---------------------+
- -- 将用户表中所有 ID>3的密码重置
- update `zz_users` set `password` = "1111" where user_id > 3;
比如上述这个事务执行时,
MySQL会将第二条update语句记录在bin-log日志中,但对于select语句则不会记录(在记录SQL时,还会记录一下SQL的上下文信息,如执行时间、事务ID、日志量......)。这种方式的优势很明显,由于只记录对数据库产生变更操作的
SQL,所以不会产生太大的日志量,节约空间,恢复数据时因为数据量小,所以磁盘IO次数少,因此性能会比较不错。同时做主备等高可用架构时,数据同步也会较小,因此比较节省带宽。但虽然优势不小,但缺点也很明显,即恢复数据、主从同步数据时,有时会出现数据不一致的情况,如
SQL中使用了sysdate()、now()这类函数,比如举个简单的例子:insert into `zz_users` values(11,"棕熊","男","3333",sysdate());比如这条插入语句,由于对用户表产生了变更操作,所以会被记录到
bin-log中,但当主从架构之间做数据同步时,假设将这条SQL同步到从机上执行,此时问题就来了,sysdate()函数会获取机器的当前时间,但主机和从机执行这条SQL显然不是同一时间,因此就会导致ID=11的这条数据,在主机和从机的用户表中,注册时间会出现不一致。Row:这种模式就是为了解决Statment模式的缺陷,Row模式中不再记录每条造成变更的SQL语句,而是记录具体哪一个分区中的、哪一个页中的、哪一行数据被修改了。这又怎么理解呢?还是以前面的重置密码的例子来说:
- -- 将用户表中所有 ID>3的密码重置(ID=4、9的两条数据会被重置)
- update `zz_users` set `password` = "1111" where user_id > 3;
在这种模式下,就不会记录这条
update语句,而是记录发生改变的行数据,即ID=4、9的两条用户数据,会将其更改后的值记录到bin-log日志中。这种方式因为不记录
SQL,而是记录修改后的值,因此有个很大的好处是:当主从同步数据时,复制的是主机上的数据,因此不会出现主从数据不一致的情况。但缺陷同样很明显,比如表中有800W数据,现在我对ID<600W的所有数据进行了修改操作,哪也就意味着会有600W条记录写入bin-log日志,这个数据量可想而知,其磁盘IO、网络带宽开销会很高。Mixed:这种被称为混合模式,即Statment、Row的结合版,因为Statment模式会导致数据出现不一致,而Row模式数据量又会很大,因此Mixed模式结合了两者的优劣势,对于可以复制的SQL采用Statment模式记录,对于无法复制的SQL采用Row记录。这样即保留了
Statment模式的数据量小,又具备Row模式的数据精准性。3.2、为什么有了Redo-log还需要Bin-log?
Redo-log、Bin-log都是记录更新数据库的操作,但为什么会同时设计两个呢?这其实跟InnoDB有关,MySQL自己的官方引擎实际上最初是MyISAM,InnoDB是Innobase-Oy公司开发的一款可拔插式引擎,由于InnoDB被MySQL支持后使用频率越来越高,后面MySQL官方才用InnoDB替换了MyISAM作为默认引擎。MySQL-Server、MyISAM是出自于官方的产品,因此MyISAM中并未设计记录变更操作的日志,记录变更操作由MySQL-Server来通过Bin-log完成。但因为
MyISAM不支持事务,所以MySQL-Server设计的Bin-log无法用于灾难恢复,因此InnoDB在设计时,又重新设计出Redo-log日志,可以利用该日志实现crash-safe灾难恢复能力,确保任何事务提交后数据都不会丢失。3.3、Redo-log、Bin-log两者的区别
对于
Redo-log、Bin-log两者的区别,主要可以从四个维度上来说:-
①生效范围不同,
Redo-log是InnoDB专享的,Bin-log是所有引擎通用的。 -
②写入方式不同,
Redo-log是用两个文件循环写,而Bin-log是不断创建新文件追加写。 -
③文件格式不同,
Redo-log中记录的都是变更后的数据,而Bin-log会记录变更SQL语句。 -
④使用场景不同,
Redo-log主要实现故障情况下的数据恢复,Bin-log则用于数据灾备、同步。
3.4、不小心删库后应该跑路吗?
这里有两个问题:①删库后跑路会不会被人发现?②
MySQL能不能和Oracle一样具备闪回功能?bin-log日志中会记录执行SQL的连接会话信息,同时一般规模较大的企业,都会搭建完善的监控系统,会监控服务的网络连接,因此当你删库后,可以顺着bin-log → session → network-connection这条线确定执行删库SQL的IP!如果你还未断开连接,直接通过MySQL的命令就能定位到删库的IP,因此基本上删库了,是可以定位到责任人。当然,如果项目配备的监控系统不够完善,同时你的连接已经断开,并且电脑换了一个局域网,同时时间来到了三天以后,如果还没人发现你,哪基本上跑路也不会有人发现。
通过日志恢复,但
Redo-log、Bin-log都会记录数据库的变更操作,因此用谁比较合适呢?答案是
Bin-log,因为Redo-log采用循环写的方式,一边写会一边擦,里面无法得到完整的数据,而Bin-log是追加写的模式,你不去主动删除磁盘的日志文件,并且磁盘的空间还足够,一般Bin-log日志文件都会在本地,因此当你删库后,可以直接去本地找Bin-log的日志文件,然后拷贝出来一份,再打开最后一个文件,把里面删库的记录手动移除,再利用mysqlbinlog工具导出xx.SQL文件,最后执行该SQL文件即可恢复删库前的数据。3.5、bin-log相关的参数
-
log_bin:是否开启bin-log日志,默认ON开启,表示会记录变更DB的操作。 -
log_bin_basename:设置bin-log日志的存储目录和文件名前缀,默认为./bin.0000x。 -
log_bin_index:设置bin-log索引文件的存储位置,因为本地有多个日志文件,需要用索引来确定目前该操作的日志文件。 -
binlog_format:指定bin-log日志记录的存储方式,可选Statment、Row、Mixed。 -
max_binlog_size:设置bin-log本地单个文件的最大限制,最多只能调整到1GB。 -
binlog_cache_size:设置为每条线程的工作内存,分配多大的bin-log缓冲区。 -
sync_binlog:控制bin-log日志的刷盘频率。 -
binlog_do_db:设置后,只会收集指定库的bin-log日志,默认所有库都会记录。
3.6、Redo-log的两阶段提交
MySQL事务两阶段提交方案,实则是指Redo-log分两次写入,如下:
两阶段提交
注意看之前给出的写
SQL执行流程图,其中第⑤、⑩步,分别会写两次Redo-log日志,这个日志的作用前面讲的很明白了,主要用来做崩溃恢复,但为什么要分两次写呢?如果只写一次的话,那到底先写
bin-log还是redo-log呢?先写
bin-log,再写redo-log:当事务提交后,先写bin-log成功,结果在写redo-log时断电宕机了,再重启后由于redo-log中没有该事务的日志记录,因此不会恢复该事务提交的数据。但要注意,主从架构中同步数据是使用bin-log来实现的,而宕机前bin-log写入成功了,就代表这个事务提交的数据会被同步到从机,也就意味着从机会比主机多出一条数据。先写
redo-log,再写bin-log:当事务提交后,先写redo-log成功,但在写bin-log时宕机了,主节点重启后,会根据redo-log恢复数据,但从机依旧是依赖bin-log来同步数据的,因此从机无法将这个事务提交的数据同步过去,毕竟bin-log中没有撒,最终从机会比主机少一条数据。经过上述分析后可得知:如果
redo-log只写一次,那不管谁先写,都有可能造成主从同步数据时的不一致问题出现,为了解决该问题,redo-log就被设计成了两阶段提交模式,设置成两阶段提交后,整个执行过程有三处崩溃点:-
redo-log(prepare):在写入准备状态的redo记录时宕机,事务还未提交,不会影响一致性。 -
bin-log:在写bin记录时崩溃,重启后会根据redo记录中的事务ID,回滚前面已写入的数据。 -
redo-log(commit):在bin-log写入成功后,写redo(commit)记录时崩溃,因为bin-log中已经写入成功了,所以从机也可以同步数据,因此重启时直接再次提交事务,写入一条redo(commit)记录即可。
通过这种两阶段提交的方案,就能够确保
redo-log、bin-log两者的日志数据是相同的,bin-log中有的主机再恢复,如果bin-log没有则直接回滚主机上写入的数据,确保整个数据库系统的数据一致性。为什么
bin-log又被叫做二进制日志呢?因为记录日志时,MySQL写入的是二进制数据,而并非字符数据,也就意味着直接用cat/vim这类工具是无法打开的,必须要通过MySQL提供的mysqlbinlog工具解析查看。四、Error-log错误日志
undo-log、redo-log、bin-log这三个日志都是用来辅助MySQL、InnoDB在线上正常运行的,但凡其中一个出现问题,都有可能导致MySQL无法正常工作。几个辅助性的日志,即
error-log、slow-log、relay-log。-
error-log:MySQL线上MySQL由于非外在因素(断电、硬件损坏...)导致崩溃时,辅助线上排错的日志。 -
slow-log:系统响应缓慢时,用于定位问题SQL的日志,其中记录了查询时间较长的SQL。 -
relay-log:搭建MySQL高可用热备架构时,用于同步数据的辅助日志。
接下来先看
error-log,这个日志的作用很明显,从名字都能得知它是用于记录MySQL报错信息的,其中涵盖了MySQL-Server的启动、停止运行的时间,以及报错的诊断信息,也包括了错误、警告和提示等多个级别的日志详情。通过错误日志,一方面可以用来监控
MySQL的运行状态,便于预防故障、发现故障,同时也可以在出现问题时,用来辅助排查问题、修复故障,因为MySQL-Server的错误日志是默认开启的,并且无法手动关闭!一般来说,
error-log日志文件默认是在MySQL安装目录下的data文件夹中,但如果你想要改变位置,哪也可以通过log-error这个参数,来手动指定保存的位置与文件名。如果你不清楚错误日志的位置,也可以通过
SHOW VARIABLES LIKE 'log_error';命令来查看。如何根据错误日志来排错问题呢?实际上非常简单,在
MySQL故障的情况下,打开error-log文件,然后搜索Error、Waiting级别的日志记录,然后参考诊断信息即可。五、Slow-log慢查询日志
对于线上响应缓慢的问题,一步步的排查过程之后还未找到问题,最终就会来到数据库,尝试对
SQL或索引调优,但一个项目中,存在成千上万条SQL,到底是由于哪条SQL造成的响应缓慢,如果一条条去分析,其工作量定然非常吃力,为了排查问题时足够轻松,MySQL官方支持开启慢查询日志。慢查询日志是什么呢?也就是当一条
SQL执行的时间超过规定的阈值后,那么这些耗时的SQL就会被记录在慢查询日志中,当线下出现响应缓慢的问题时,可以直接通过查看慢查询日志定位问题,定位到产生问题的SQL后,再用explain这类工具去生成SQL的执行计划,然后根据生成的执行计划来判断为什么耗时长,是由于没走索引,还是索引失效等情况导致的。不过对于慢查询
SQL的监控,MySQL默认是关闭的,也就是说MySQL默认不会记录慢查询日志,因为为了后续线上问题好排查,项目上线前一定要记得开启!-
slow_query_log:设置是否开启慢查询日志,默认OFF关闭。 -
slow_query_log_file:指定慢查询日志的存储目录及文件名。
可以通过这两个参数来开启慢查询日志,如果不设置存储目录,默认放在
MySQL的具体库的目录下。当开启慢查询日志的监控后,可以通过设置long_query_time参数,来指定查询SQL的阈值:set global long_query_time = 1;其默认单位是秒,因此如果要指定更细粒度的时间,可以通过
0.01这种形式设置,0.01表示10ms。当然,该参数也可不设置,不指定阈值的情况下,默认为10s,即执行时间超过10s的查询SQL才会记录到慢查询日志中。对于阈值的设置,并不是随咱们率性而为,这个参数一定要设置合理!因为该参数的大小会直接影响
MySQL的性能,比如设置一个0.2s,但如果大量业务SQL执行时都会超出该时长,那最终会导致MySQL十分频繁的往慢查询日志中写数据。要记住:慢查询日志在内存中是没有缓冲区的,也就意味着每次记录慢查询
SQL,都必须触发磁盘IO来完成,因此阈值设的太小,容易使得MySQL性能下降;如果设的太大,又会导致无法检测到问题SQL,因此该值一定要设置一个合理值。这个值设成多大合理呢?可以先开启
general log,观察后实际的业务情况后再决定。General-log查询日志
general log即查询日志,MySQL会向其中写入所有收到的查询命令,如select、show等,同时要注意:无论SQL的语法正确还是错误、也无论SQL执行成功还是失败,MySQL都会将其记录下来。对于该日志可以通过下述参数开启:-
general_log:是否开启查询日志,默认OFF关闭。 -
general_log_file:指定查询日志的存储路径和文件名(默认在库的目录下,主机名+.log)。
项目测试阶段,可以先开启查询日志,然后压测所有业务,紧接着再分析日志中
SQL的平均耗时,再根据正常的SQL执行时间,设置一个偏大的慢查询阈值即可(这是个笨办法,如果项目规模较大,直接设置一个大概值,然后上灰度发布,走正式的运营场景效果会更佳)。当然,压测阶段结束后,项目正式上线前,一定要记得关闭普通查询日志!!
六、Relay-log中继日志
relay log在单库中是见不到的,该类型的日志仅存在主从架构中的从机上,主从架构中的从机,其数据基本上都是复制主机bin-log日志同步过来的,而从主机复制过来的bin-log数据放在哪儿呢?也就是放在relay-log日志中,中继日志的作用就跟它的名字一样,仅仅只是作为主从同步数据的“中转站”。当主机的增量数据被复制到中继日志后,从机的线程会不断从
relay-log日志中读取数据并更新自身的数据,relay-log的结构和bin-log一模一样,同样存在一个xx-relaybin.index索引文件,以及多个xx-relaybin.00001、xx-relaybin.00002....数据文件。七、日志篇总结
-
undo-log:主要用于实现事务ACID原则中的原子性和MVCC机制。 -
redo-log:主要用于实现事务原则中的持久性,确保事务提交后就不会丢失。 -
bin-log:主要结合redo-log实现事务原则中的一致性,确保事务提交前后,数据的一致。
InnoDB为什么使用B+树实现索引?
InnoDB 中的索引类型
InnoDB 存储引擎支持两种常见的索引数据结构:B+树索引和哈希索引,其中 B+树索引是目前关系型数据库系统中最为常见、最为高效的索引之一。
数据库中的 B+树索引可分为聚簇索引和非聚簇索引。聚簇索引按照每张表的主键构建一个 B+树,其叶子节点记录着表中每行记录的所有值。只需访问叶子节点即可获取整行记录的信息。非聚簇索引的叶子节点中并不包含完整的行记录信息,而仅包含索引值和对应的主键值。
根据索引的唯一性,索引可分为唯一索引和普通索引。唯一索引要求索引列的值必须唯一,不可重复。
此外,在 MySQL 5.6 版本中引入了全文索引,在 5.7 版本及以后,通过使用 ngram 插件开始支持中文全文搜索。
B+树的特点
-
B+树是一棵平衡树,每个叶子节点到根节点的路径长度相同,从而提高了查找效率;
-
所有关键字都存储在 B+树的叶子节点上,因此进行范围查询时只需遍历一次叶子节点即可;
-
叶子节点按照关键字大小顺序存放,因此能够快速支持按关键字大小进行排序;
-
非叶子节点不存储实际数据,这使得可以存储更多的索引数据;
-
非叶子节点使用指针连接子节点,从而能够迅速支持范围查询和倒序查询;
-
叶子节点之间通过双向链表连接,便于进行范围查询。

使用 B+树实现索引具有以下几个优点:
-
支持范围查询:B+树在执行范围查找时,只需从根节点遍历至叶子节点,因为数据存储在叶子节点上,并且叶子节点之间有指针连接,便于进行范围查找。
-
支持排序:B+树的叶子节点按关键字顺序存储,能够快速支持排序操作,提升排序效率。
-
存储更多的索引数据:由于非叶子节点仅存储索引关键字而不存储实际数据,可容纳更多索引数据。
-
减少 IO 操作:B+树的叶子节点大小固定,一般设置为一页大小,使得节点分裂和合并时的 IO 操作较少,只需读取和写入一页。
-
利用磁盘预读:节点大小固定有利于利用磁盘预读特性,一次性读取多个节点到内存中,减少 IO 操作次数,提高查询效率。
-
优化缓存利用:B+树的非叶子节点仅存储指向子节点的指针,不存储数据,可使缓存容纳更多索引数据,提高缓存命中率,加速查询速度。
为什么不用红黑树或者 B 树?
因为 B+树的特点是只有叶子节点存储数据,而非叶子节点不存储数据,并且节点大小固定,叶子节点之间通过双向链表链接,所以,使用 B+树实现索引具有诸多优势,比如支持范围查询、有利于磁盘预读、优化排序等等。而这些是红黑树和 B 树无法实现的。
B+树索引和 Hash 索引有什么区别?
B+树索引和哈希索引是常见的数据库索引结构,它们之间存在以下几个主要区别:
B+树索引将索引列的值按大小排序后存储,因此适合范围查找和排序操作;而哈希索引则通过哈希函数计算索引列的值,得到一个桶的编号,然后将桶内记录保存在链表或树结构中。因此,哈希索引适合等值查询,但不适合范围查询和排序操作。
在插入和删除数据时,B+树索引需要调整索引结构,可能涉及页分裂和页合并等操作,因此维护成本较高;而哈希索引只需计算哈希值并操作链表中的记录,维护成本相对较低。
B+树索引在磁盘上有序存储,可利用磁盘预读提高区间查询效率;而哈希索引在磁盘上无序存储,可能需要随机访问磁盘,导致查询效率下降。
由于 B+树索引在节点中存储多个键值对,能充分利用磁盘块空间,提高空间利用率;而哈希索引需要额外存储哈希值和指针,空间利用率相对较低。
-
-
相关阅读:
39页零碳数字能源综合解决方案
节点加密技术:保障数据传输安全的新利器
2023软件测试面试避坑指南
变量使用volatile和不使用volatile的区别
深入理解 python 虚拟机:字节码教程(2)——控制流是如何实现的?
2022Java面试题大全,附答案,最新整理
【MySQL】基础实战篇(3)—九大储存引擎详解
基于OpenDaylight和OVSDB搭建VxLAN网络
Codeforces Round 901 (Div. 2)
学习笔记17--国内网联车上路的测试政策
- 原文地址:https://blog.csdn.net/lichunericli/article/details/140416943