-
Linux高级IO
🌟🌟hello,各位读者大大们你们好呀🌟🌟
🚀🚀系列专栏:【Linux的学习】
📝📝本篇内容:五种IO模型;高级IO重要概念;非阻塞IO;I/O多路转接之select;I/O多路转接之poll;I/O多路转接之epoll
⬆⬆⬆⬆上一篇:网络基础(三)
💖💖作者简介:轩情吖,请多多指教(>> •̀֊•́ ) ̖́-1.五种IO模型
其实我们之前的使用的IO就是调用系统调用,但是讲的更加详细一点就是IO=等待+数据拷贝,我们进行IO是有条件的,比如write的时候要有空间,read的时候要有数据,达成这种条件就叫做IO事件就绪
高效的IO就是单位时间,等待的比重越低,效率越高1.1 阻塞IO
阻塞IO: 在内核将数据准备好之前, 系统调用会一直等待. 所有的套接字, 默认都是阻塞方式
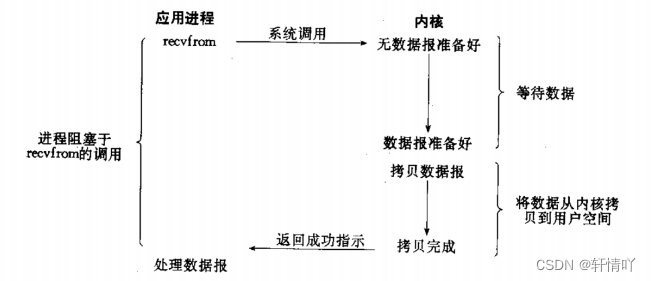
1.2 非阻塞IO
非阻塞IO: 如果内核还未将数据准备好, 系统调用仍然会直接返回, 并且返回EWOULDBLOCK错误码.
非阻塞IO往往需要程序员循环的方式反复尝试读写文件描述符, 这个过程称为轮询. 这对CPU来说是较大的浪费, 一般只有特定场景下才使用
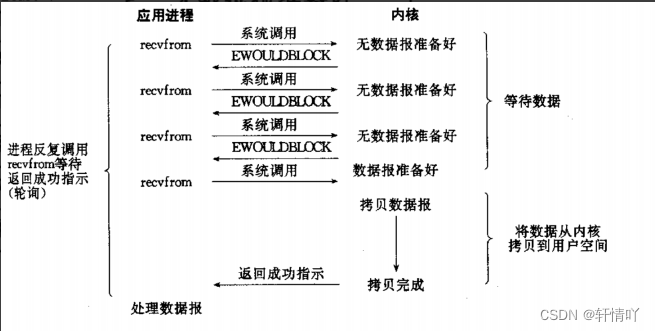
对比阻塞IO就是等的方式不同1.3 信号驱动IO
信号驱动IO: 内核将数据准备好的时候, 使用SIGIO信号通知应用程序进行IO操作.
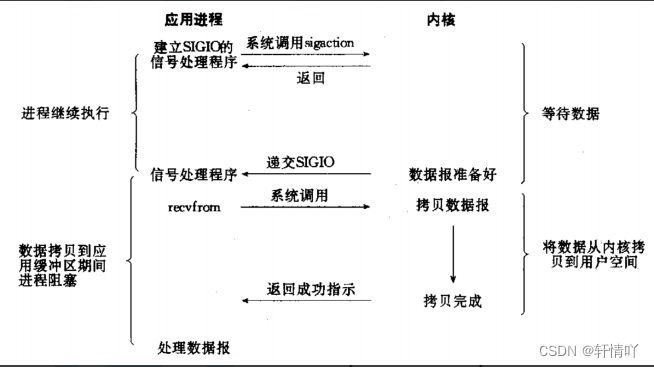
对于这种IO,就是需要进行信号捕捉1.4 多路复用/多路转接IO
IO多路转接: 虽然从流程图上看起来和阻塞IO类似. 实际上最核心在于IO多路转接能够同时等待多个文件描述符的就绪状态.

它的效率是最高的,因为它能同时等待多个IO1.5 异步IO
异步IO: 由内核在数据拷贝完成时, 通知应用程序(而信号驱动是告诉应用程序何时可以开始拷贝数据).
它并没有参与等或者拷贝的过程,它是由系统完成的,它只需要完成处理数据

1.6 小结
任何IO过程中, 都包含两个步骤. 第一是等待, 第二是拷贝. 而且在实际的应用场景中, 等待消耗的时间往往都远远高于拷贝的时间. 让IO更高效, 最核心的办法就是让等待的时间尽量少.
2.高级IO重要概念
同步通信 vs 异步通信(synchronous communication/ asynchronous communication)
同步和异步关注的是消息通信机制.
所谓同步,就是在发出一个调用时,在没有得到结果之前,该调用就不返回. 但是一旦调用返回,就得到返回值了; 换句话说,就是由调用者主动等待这个调用的结果;
异步则是相反,调用在发出之后,这个调用就直接返回了,所以没有返回结果; 换句话说,当一个异步过程调用发出后,调用者不会立刻得到结果; 而是在调用发出后,被调用者通过状态、通知来通知调用者,或通过回调函数处理这个调用.
另外, 在多进程多线程的时候, 也提到同步和互斥. 这里的同步通信和进程之间的同步是完全不想干的概念.
进程/线程同步也是进程/线程之间直接的制约关系
是为完成某种任务而建立的两个或多个线程,这个线程需要在某些位置上协调他们的工作次序而等待、传递信息所产生的制约关系. 尤其是在访问临界资源的时候.
看到 “同步” 这个词, 一定要先搞清楚大背景是什么. 这个同步, 是同步通信异步通信的同步, 还是同步与互斥的同步.阻塞 vs 非阻塞
阻塞和非阻塞关注的是程序在等待调用结果(消息,返回值)时的状态.
阻塞调用是指调用结果返回之前,当前线程会被挂起. 调用线程只有在得到结果之后才会返回.
非阻塞调用指在不能立刻得到结果之前,该调用不会阻塞当前线程3.非阻塞IO
一个文件描述符,默认都是阻塞IO的
函数fcntl

传入的cmd的值不同, 后面追加的参数也不相同.
fcntl函数有5种功能:
复制一个现有的描述符(cmd=F_DUPFD).
获得/设置文件描述符标记(cmd=F_GETFD或F_SETFD).
获得/设置文件状态标记(cmd=F_GETFL或F_SETFL).
获得/设置异步I/O所有权(cmd=F_GETOWN或F_SETOWN).
获得/设置记录锁(cmd=F_GETLK,F_SETLK或F_SETLKW).
我们此处只是用第三种功能, 获取/设置文件状态标记, 就可以将一个文件描述符设置为非阻塞3.1 实现函数NoBlock
void SetNoBlock(int fd) { int fl = fcntl(fd, F_GETFL); if (fl < 0) { cerr << "error string:" << strerror(errno) << endl; } fcntl(fd, F_SETFL, fl | O_NONBLOCK); }使用F_GETFL将当前的文件描述符的属性取出来(这是一个位图).
然后再使用F_SETFL将文件描述符设置回去. 设置回去的同时, 加上一个O_NONBLOCK参数3.2 轮询方式读取标准输入
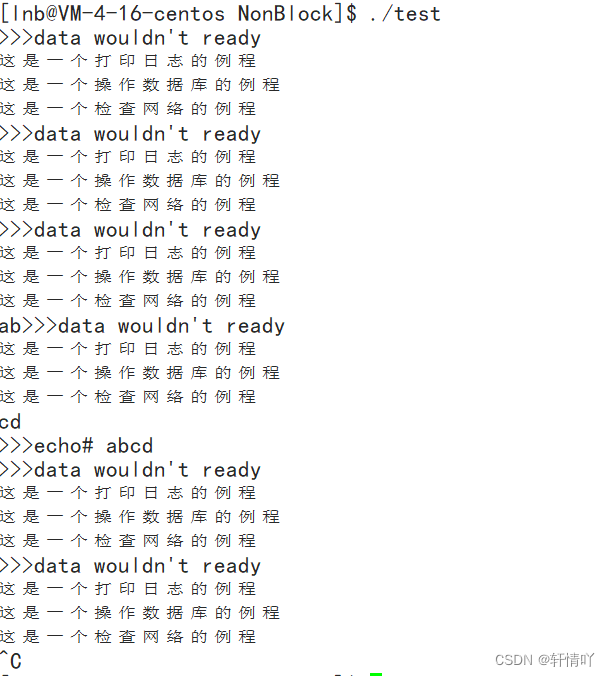
#include#include #include #include #include #include #include using namespace std; using func_t=function<void(void)>; vector<func_t> task; void PrintLog(void) { cout<<"这是一个打印日志的例程"<<endl; } void OperateMySQL(void) { cout<<"这是一个操作数据库的例程"<<endl; } void CheckNet(void) { cout<<"这是一个检查网络的例程"<<endl; } void LoadTask(void) { task.push_back(PrintLog); task.push_back(OperateMySQL); task.push_back(CheckNet); } void HandleTask() { for(const auto& e:task) { e(); } } void SetNoBlock(int fd) { int fl = fcntl(fd, F_GETFL); if (fl < 0) { cerr << "error string:" << strerror(errno) << endl; } fcntl(fd, F_SETFL, fl | O_NONBLOCK); } int main() { SetNoBlock(0); char buff[1024]; LoadTask(); while (1) { cout << ">>>"; fflush(stdout); //read三种状态:1.成功 2.结束 3.出错(一旦底层没有数据就绪,以出错的形式返回,但是不算真正的出错) ssize_t n = read(0, buff, sizeof(buff) - 1); if (n > 0) { buff[n - 1] = '\0'; cout << "echo# " << buff << endl; } else if (n == 0) { cout << "end file" << endl; break; } else { if (errno == EAGAIN || errno == EWOULDBLOCK) { // 底层数据没有准备好,希望你下次继续检测 cout << "data wouldn't ready" << endl; HandleTask();//轮询的方式读取,先去完成别的任务,待会再回来检测 sleep(1); continue; } else if (errno == EINTR) { // 这次IO被信号中断,也需要被重新获取 continue; } else { cerr << "read error,error string" << strerror(errno) << endl; break; } } } return 0; } 
其中当read读取时因为fd是设置为非阻塞的,所以说read所返回的errno是EWOULDBLOCK,表明读取时数据还没准备好,还处于阻塞状态
4.I/O多路转接之select
系统提供select函数来实现多路复用输入/输出模型.
select系统调用是用来让我们的程序监视多个文件描述符的状态变化的;
程序会停在select这里等待,直到被监视的文件描述符有一个或多个发生了状态改变;
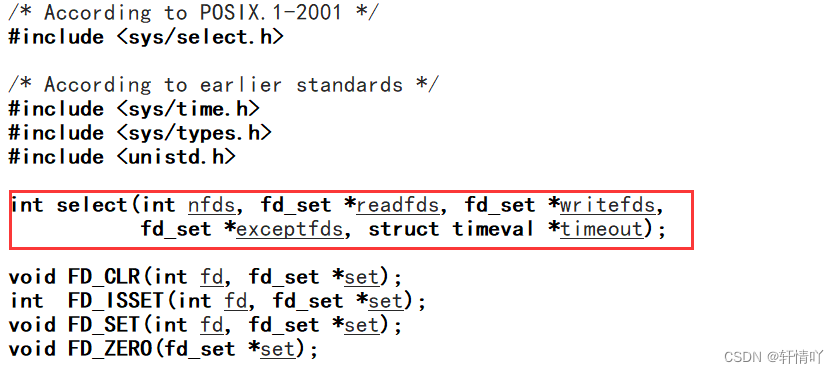
参数解释:
参数nfds是需要监视的最大的文件描述符值+1;
rdset,wrset,exset分别对应于需要检测的可读文件描述符的集合,可写文件描述符的集合及异常文件描述符的集合;
参数timeout为结构timeval,用来设置select()的等待时间;
后四个是输入输出型参数
我们以readfds来举例:当它是输入参数时,表示用户告诉内核哪些fd读事件需要内核关心;当它是输出参数时,表示内核要告诉用户,哪些fd读事件已经就绪.他们都是fd_set类型,有固定大小,所以说比特位数一定有上限。select所能管理的fd一定有上限.用位图结构表示多个fd,来进行用户和内核之间信息的互相传递

其实这个结构就是一个整数数组, 更严格的说, 是一个 “位图”. 使用位图中对应的位来表示要监视的文件描述符.
提供了一组操作fd_set的接口, 来比较方便的操作位图.void FD_CLR(int fd, fd_set *set); // 用来清除描述词组set中相关fd 的位 int FD_ISSET(int fd, fd_set *set); // 用来测试描述词组set中相关fd 的位是否为真 void FD_SET(int fd, fd_set *set); // 用来设置描述词组set中相关fd的位 void FD_ZERO(fd_set *set); // 用来清除描述词组set的全部位参数timeout取值:

①NULL:阻塞等待
②{0,0}:非阻塞等待
③{n,m}:例{5,0},5秒以内阻塞等待,否则timeout一次,返回的时候表示剩余时间
函数返回值:
执行成功则返回文件描述词状态已改变的个数
如果返回0代表在描述词状态改变前已超过timeout时间,没有返回
当有错误发生时则返回-1,错误原因存于errno,此时参数readfds,writefds, exceptfds和timeout的
值变成不可预测。4.1 理解select执行过程
理解select模型的关键在于理解fd_set,为说明方便,取fd_set长度为1字节,fd_set中的每一bit可以对应一个文件描述符fd。则1字节长的fd_set最大可以对应8个fd.
(1)执行fd_set set; FD_ZERO(&set);则set用位表示是0000,0000。
(2)若fd=5,执行FD_SET(fd,&set)后set变为0001,0000(第5位置为1)
(3)若再加入fd=2,fd=1,则set变为0001,0011
(4)执行select(6,&set,0,0,0)阻塞等待
(5)若fd=1,fd=2上都发生可读事件,则select返回,此时set变为0000,0011。注意:没有事件发生的fd=5被清空4.2 select的特点
可监控的文件描述符个数取决与sizeof(fd_set)的值. 我这边服务器上sizeof(fd_set)=128,每bit表示一个文件描述符,则我服务器上支持的最大文件描述符是128*8=1024.
将fd加入select监控集的同时,还要再使用一个数据结构array保存放到select监控集中的fd.
一是用于再select返回后,array作为源数据和fd_set进行FD_ISSET判断.
二是select返回后会把以前加入的但并无事件发生的fd清空,则每次开始select前都要重新从array取得
fd逐一加入(FD_ZERO最先),扫描array的同时取得fd最大值maxfd,用于select的第一个参数。
备注: fd_set的大小可以调整,可能涉及到重新编译内核.4.3 select缺点
每次调用select, 都需要手动设置fd集合, 从接口使用角度来说也非常不便.
每次调用select,都需要把fd集合从用户态拷贝到内核态,这个开销在fd很多时会很大
同时每次调用select都需要在内核遍历传递进来的所有fd,这个开销在fd很多时也很大
select支持的文件描述符数量太小对于进程而言可以打开100001个文件,因此对于进程来说select支持的文件描述符过于小
4.4 实现
Select实现标准输出
Select实现标准输入输出的大致轮廓5.I/O多路转接之poll
5.1 poll函数


参数说明:
fds是一个poll函数监听的结构列表. 每一个元素中, 包含了三部分内容: 文件描述符, 监听的事件集合, 返回的事件集合.可以当做一个“数组”来看
nfds表示fds数组的长度.
timeout表示poll函数的超时时间, 单位是毫秒(ms),<0是阻塞,==0是非阻塞,>0是等待多少毫秒后返回
events和revents的取值:
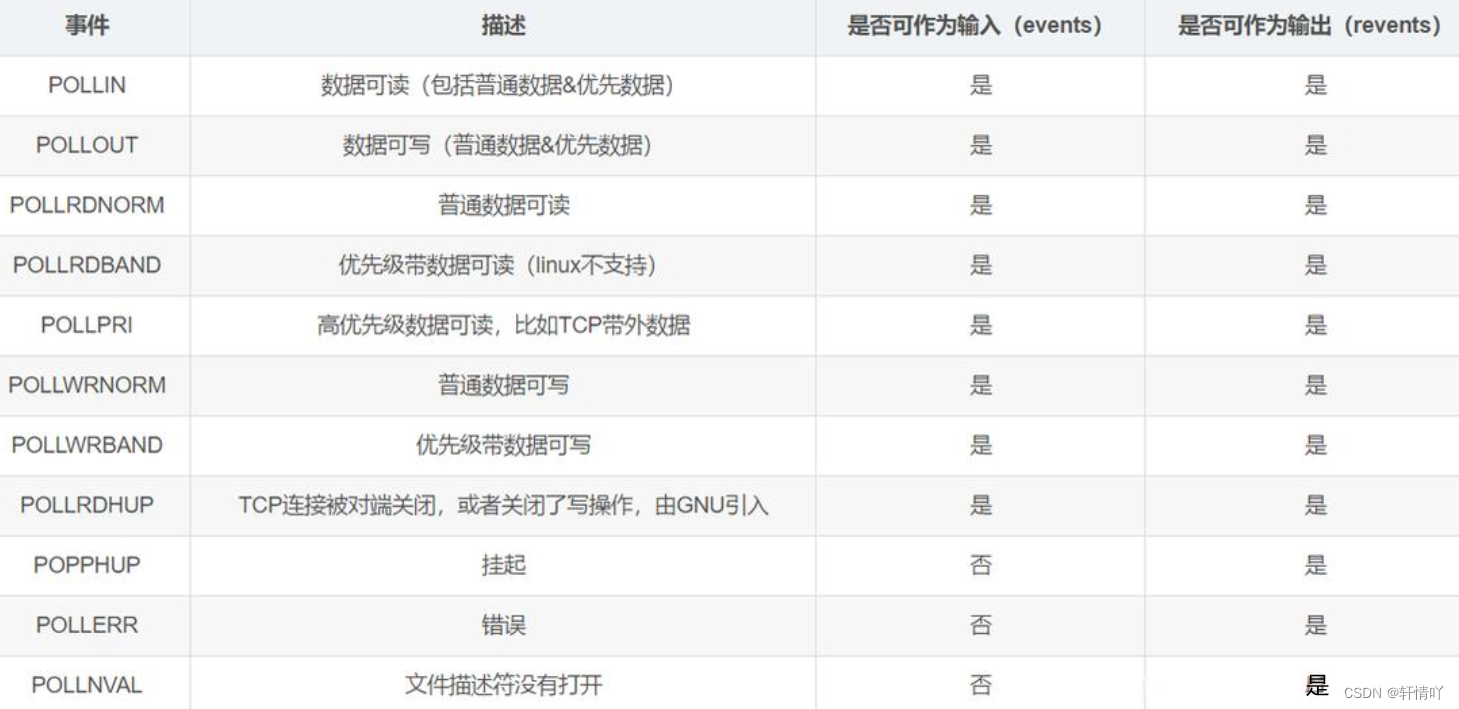
返回结果:
返回值小于0, 表示出错;
返回值等于0, 表示poll函数等待超时;
返回值大于0, 表示poll由于监听的(个数)文件描述符就绪而返回.5.2 poll的优点
不同与select使用三个位图来表示三个fdset的方式,poll使用一个pollfd的指针实现.
pollfd结构包含了要监视的event和发生的event,不再使用select“参数-值”传递的方式. 接口使用比
select更方便.
poll将输入参数和输出参数进行了分离,不用调用poll重新设置了
poll并没有最大数量限制 (但是数量过大后性能也是会下降).5.3 poll的缺点
poll中监听的文件描述符数目增多时
和select函数一样,poll返回后,需要轮询pollfd来获取就绪的描述符.
每次调用poll都需要把大量的pollfd结构从用户态拷贝到内核中.
同时连接的大量客户端在一时刻可能只有很少的处于就绪状态, 因此随着监视的描述符数量的增长, 其效率也会线性下降.5.4 实现
6.I/O多路转接之epoll
6.1 epoll的相关系统调用
epoll 有3个相关的系统调用

创建一个epoll的句柄.
自从linux2.6.8之后,size参数是被忽略的(>0).
用完之后, 必须调用close()关闭.
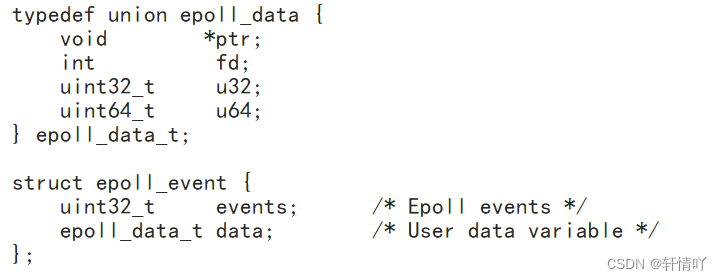
epoll的事件注册函数.
它不同于select()是在监听事件时告诉内核要监听什么类型的事件, 而是在这里先注册要监听的事件类型.
第一个参数是epoll_create()的返回值(epoll的句柄).
第二个参数表示动作,用三个宏来表示.
第三个参数是需要监听的fd.
第四个参数是告诉内核需要监听什么事.
第二个参数的取值:
EPOLL_CTL_ADD :注册新的fd到epfd中;
EPOLL_CTL_MOD :修改已经注册的fd的监听事件;
EPOLL_CTL_DEL :从epfd中删除一个fd;
events可以是以下几个宏的集合:
EPOLLIN : 表示对应的文件描述符可以读 (包括对端SOCKET正常关闭);
EPOLLOUT : 表示对应的文件描述符可以写;
EPOLLPRI : 表示对应的文件描述符有紧急的数据可读 (这里应该表示有带外数据到来);
EPOLLERR : 表示对应的文件描述符发生错误;
EPOLLHUP : 表示对应的文件描述符被挂断;
EPOLLET : 将EPOLL设为边缘触发(Edge Triggered)模式, 这是相对于水平触发(Level Triggered)来说的.
EPOLLONESHOT:只监听一次事件, 当监听完这次事件之后, 如果还需要继续监听这个socket的话,需要再次把这个socket加入到EPOLL队列里
收集在epoll监控的事件中已经发生的事件.
参数events是分配好的epoll_event结构体数组.
epoll将会把发生的事件赋值到events数组中 (events不可以是空指针,内核只负责把数据复制到这个events数组中,不会去帮助我们在用户态中分配内存).
maxevents告之内核这个events有多大,这个 maxevents的值不能大于创建epoll_create()时的size. 参数timeout是超时时间 (毫秒,0会立即返回,-1是永久阻塞).
如果函数调用成功,返回对应I/O上已准备好的文件描述符数目,如返回0表示已超时, 返回小于0表示函数失败总的来说epoll_ctl是为了达成用户告诉内核所需要关心的哪个文件描述符上的哪个事件。而epoll_wait是内核要告诉用户关心的哪些文件描述符的哪些事件已经就绪了
6.2 epoll工作原理
首先我们要先知道一下操作系统是怎么知道网卡上面有数据了?这其实和之前信号部分的键盘输入的问题类似,当网卡拿到数据后,会触发对应CPU的引脚的中断号,CPU把它交给CPU中的寄存器,就是对其进行充放电(二进制),而对应的中断号是中断向量表的下标,中断向量表是一个函数指针数组,所以说软件层能够读到寄存器的内容,可以调用对应的函数来把数据从外设拷贝到内存
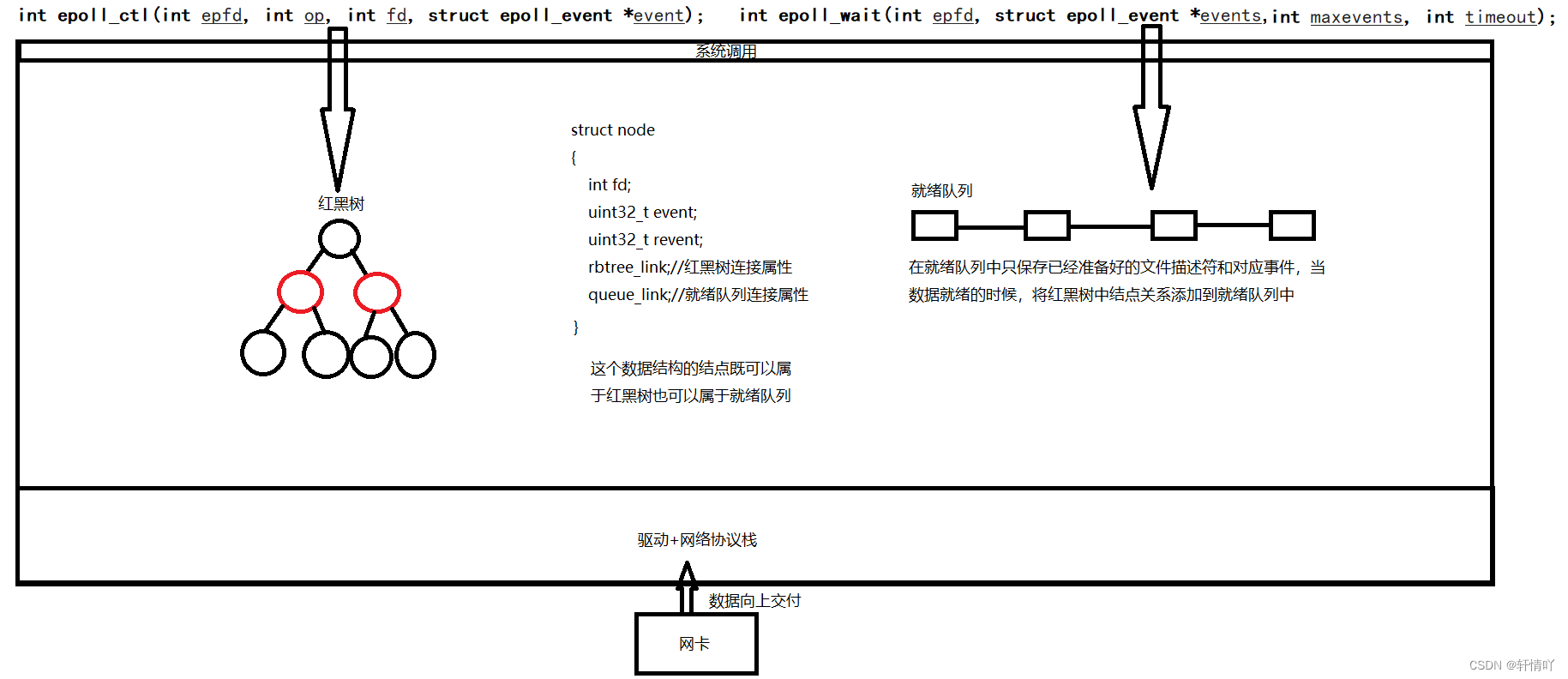
对于我们的epoll_create的返回值是一个文件描述符是为了当调用epoll_ctl和epoll_wait时能够找到并构建对应的红黑树和在就绪队列里取数据。
我们的红黑树和就绪队列是我们的OS维护的,整体一个大的模型称之为epoll模型。因此对于epoll_wait来说检查数据有没有就绪(检查就绪队列是否为空)的时间复杂度就是O(1)。
我们的strcut file中会有对应的回调机制,通过对应的回调函数将红黑树中的结点添加到就绪队列中国。当我们的操作系统处理完所有的数据后,会先检查对应的struct file中对应的函数指针是否为NULL,然后调用其函数。只有当我们使用epoll时这个函数指针会有对应的地址。6.3 epoll的优点(和 select 的缺点对应)
接口使用方便: 虽然拆分成了三个函数, 但是反而使用起来更方便高效. 不需要每次循环都设置关注的文件描述符, 也做到了输入输出参数分离开
数据拷贝轻量: 只在合适的时候调用 EPOLL_CTL_ADD 将文件描述符结构拷贝到内核中, 这个操作并不频繁(而select/poll都是每次循环都要进行拷贝)
内核中的红黑树也能提高查找的效率和去重
事件回调机制: 避免使用遍历, 而是使用回调函数的方式, 将就绪的文件描述符结构加入到就绪队列中, epoll_wait 返回直接访问就绪队列就知道哪些文件描述符就绪. 这个操作时间复杂度O(1). 即使文件描述符数目很多, 效率也不会受到影响.
没有数量限制: 文件描述符数目无上限6.4 epoll工作方式
epoll有2种工作方式:水平触发(LT)和边缘触发(ET)
假如有这样一个例子:
我们已经把一个tcp socket添加到epoll描述符
这个时候socket的另一端被写入了2KB的数据
调用epoll_wait,并且它会返回. 说明它已经准备好读取操作
然后调用read, 只读取了1KB的数据
继续调用epoll_wait…水平触发Level Triggered 工作模式
epoll默认状态下就是LT工作模式.
当epoll检测到socket上事件就绪的时候, 可以不立刻进行处理. 或者只处理一部分.
如上面的例子, 由于只读了1K数据, 缓冲区中还剩1K数据, 在第二次调用 epoll_wait 时, epoll_wait仍然会立刻返回并通知socket读事件就绪.
直到缓冲区上所有的数据都被处理完, epoll_wait 才不会立刻返回.
支持阻塞读写和非阻塞读写边缘触发Edge Triggered工作模式
如果我们在第1步将socket添加到epoll描述符的时候使用了EPOLLET标志, epoll进入ET工作模式.
当epoll检测到socket上事件就绪时, 必须立刻处理.
如上面的例子, 虽然只读了1K的数据, 缓冲区还剩1K的数据, 在第二次调用 epoll_wait 的时候, epoll_wait 不会再返回了.
也就是说, ET模式下, 文件描述符上的事件就绪后, 只有一次处理机会. 数据从有无到有会有通知,从有到多,产生变化,会有第二次通知
ET的性能比LT性能更高( epoll_wait 返回的次数少了很多). Nginx默认采用ET模式使用epoll.
只支持非阻塞的读写
select和poll其实也是工作在LT模式下. epoll既可以支持LT, 也可以支持ET.6.5 对比LT和ET
LT是 epoll 的默认行为. 使用 ET 能够减少 epoll 触发的次数,相等于减少系统调用. 但是代价就是强逼着程序猿一次响应就绪过程中就把所有的数据都处理完.相当于一个文件描述符就绪之后, 不会反复被提示就绪, 看起来就比 LT 更高效一些. 但是在 LT 情况下如果也能做到每次就绪的文件描述符都立刻处理, 不让这个就绪被重复提示的话, 其实性能也是一样的.另一方面, ET 的代码复杂程度更高了。他们二者的通知效率其实是ET>=LT的,因为LT也可能会遇到上层立马把数据读取的情况,并且ET可以做到百分之百的减少epoll的触发,而LT万一代码出现问题,效率就不一定有ET高了,其实高效的本质也是让TCP的底层更新出更大的接收窗口,从而在较大概率上能让对方的滑动窗口更大,提高发送效率。
LT更适合用于需要边接收边处理的场景,而ET是高效的IO6.6 实现
EpollServerV1
EpollServerV2
EpollServerV3
上面的就是Reactor模式,基于多路转接的包含事件派发器,连接管理器等半同步半异步的IO服务器,Reactor翻译过来是反应堆的意思,可以理解为有一个connection就绪了,就会去处理,调用回调,底层读写。🌸🌸高级IO的知识大概就讲到这里啦,博主后续会继续更新更多Linux的相关知识,干货满满,如果觉得博主写的还不错的话,希望各位小伙伴不要吝啬手中的三连哦!你们的支持是博主坚持创作的动力!💪💪
-
相关阅读:
如何将 PDF 转换为 Word:前 5 个应用程序
等额本金和等额本息的区别
C++【STL】【模板进阶】
RabbitMQ:消息队列的卓越之选
【计算机毕业设计】图像识别水电表读取
Codeforces Round #815 (Div. 2)(A~D1)
CSS实现文本左右对齐
网上智慧教育云vr实验室管理系统促进教学公平和普及
【DETR源码解析】三、Transformer模块
RecyclerView的item布局预览显示是一行两块 运行后显示了一行一块,怎么回事
- 原文地址:https://blog.csdn.net/m0_73372323/article/details/136093241