-
Mysql(一):深入理解Mysql索引底层数据结构与算法
众所众知,MySql的查询效率以及查询方式,基本上和索引息息相关,所以,我们一定要对MySql的索引有一个具体到数据底层上的认知。
这一次也是借着整理的机会,和大家一起重新复习一下MySql的索引底层。
本节也主要有一下的几个内容:
- 索引数据结构红黑树,Hash,B+树详解
- 千万级数据表如何用B+树索引快速查找
- 聚集索引&非聚集索引到底是什么
- 为什么总推荐使用自增主键做索引
- 联合索引底层数据结构又是怎样的
- Mysql最左前缀优化原则是怎么回事
各位看官可以各取所需,希望能够对大家有所帮助。
一句话总结:索引是帮助MySQL高效获取数据的排好序的数据结构
为什么需要索引
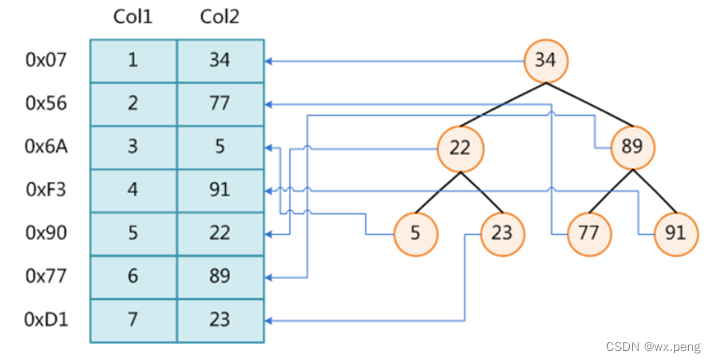
各位都知道,对一个没有索引的表来说,我们只能按行查找。
这似乎看起来也不会慢嘛,一个个往下找嘛。
但是问题在于,对于MySql来讲,数据是存在磁盘的,数据存在磁盘是逻辑上的连续,而不是物理上的连续。
假设我们要执行以下的Sqlselect * from t where t.col2 = 89那我们需要进行多次I/O到磁盘中找我们所需要的数据,那这就会导致我们的查询速度很慢。
注意:和磁盘进行I/O是一件很慢的事情。
索引的数据结构
我们知道,索引的存在,是为了帮助我们能够快速的获取数据的排好序的数据结构
有这种功能的,我们平时学的数据结构中,主要有下面几个:
- 二叉树
- 二叉排序树
- 平衡二叉树
- 红黑树
- Hash表
- B-Tree
- B+ Tree
对于二叉树和红黑树来说,两个的区别在各位学习HashMap的时候,就应该都知道了,这里我们就直接跳过。
但是,对于这两者来说,都有一个很严重的问题
- 随着数据量的增大,树的高度会逐渐增大。
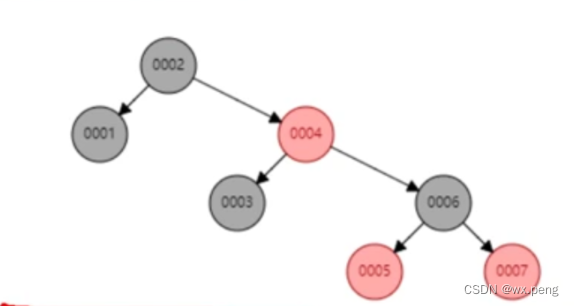
就比如上面这棵红黑树,你要找这个0007,你是不是要进行4次I/O,这肯定是没办法接受的。
所以我们的目标,是能够尽可能的把更多的数据一起放到树的每一层,来减少我I/O的次数
B-Tree
B树是一种多路平衡树,用这种存储结构来存储大量数据,它的整个高度会相比二叉树来说,会矮很多
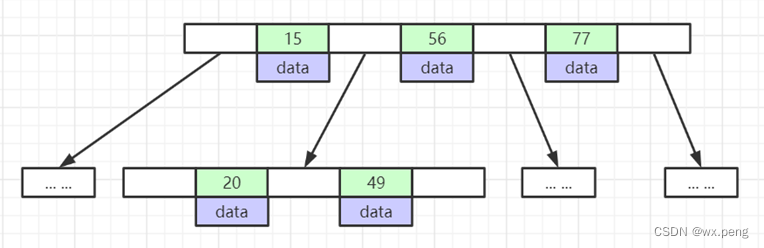
B树的每一个节点,其实可以理解成一个K-V
相比于红黑树,由于每一层能够存储的数据量多了,高度肯定是变低了,磁盘I/O次数少了,性能就提升了。
看似不错,但是几个问题:
-
首先我们要知道,MySql为了能够更快速的查询数据,会将数据通过内存页的方式读入到内存中,一个页是16K。可以通过以下语句查看
SHOW GLOBAL STATUS like 'Innodb_page_size';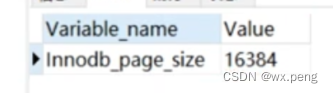
-
我们的每一个节点都存了数据,如果这个数据稍微的打了一点,那我这一页才能存多少数据啊,这种方式就会导致我们的B树的高度会有问题。
-
还有一个问题,如果是进行范围查找呢,B树似乎并不是很方便。
所以,MySql并不是以B树作为我们索引的数据结构
B+ Tree
基于上面的问题,我们引出了B+树
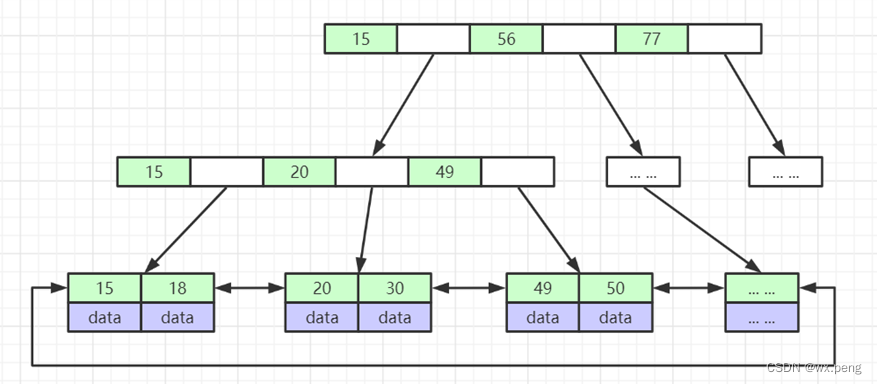
B+树相比于B树,有两个特点:
- B+树的只有叶子节点存储数据,其他节点只存储索引(冗余)
- B+树的叶子节点是一个双向链表。
我们先看看第一个特点,其实B+树的非叶子节点,和我们的跳表差不多, 每个节点都不存储数据,只是为了构建这个B+树。那这样带来了什么好处呢?
前面我们说的,mysql的内存页是16KB,也就是说,每次我们一个节点最多存储16KB的索引,假设我们用bigint作为索引值,也就是8个字节,加上向下的指针,大概是6个字节
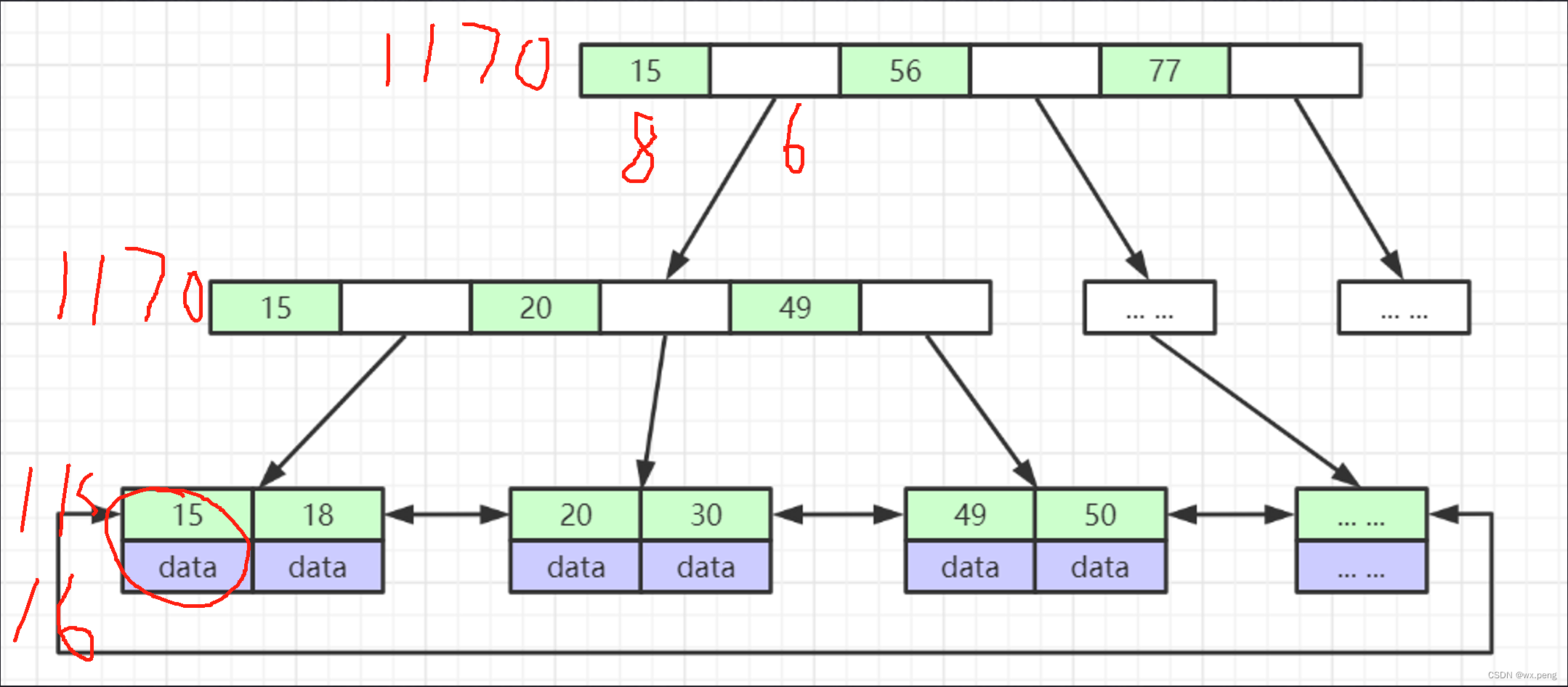
算出来,16KB / 14B = 1170。
下面的带数据的叶子节点,正常也不会太大,我们就算一个1KB,算出来就是16个
1170 * 1170 * 16 = 21,902,400
可以看到,当树的高度为3的时候,就可以通过3次查询覆盖2000万的数据。
所以,对于B+树来说,相比于B树,更加的矮壮。
同时,因为下面是一个双向链表,对于范围查询来说,是不是能够更加快速的查出结果。
Hash

默认来说,mysql都是使用B Tree来存储索引的,但是你仔细看,其实是可以选择Hash的
对于Hash的话,其实大家都不会陌生。
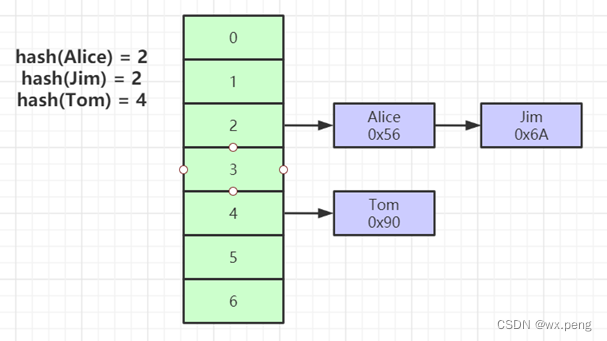
Hash的特点,就是查的够快,只要一次就能查出来
缺点也很明显,Hash冲突啊,不支持范围查找。
索引是怎么存储的
因为现在MyISAM基本上没遇到过,所以这里只对InnoDB进行介绍
注意:存储引擎是基于表的,而不是数据库
我们打开mysql对应的文件位置,进入到里面的data,由于我目前是在test库,所以点进去test文件
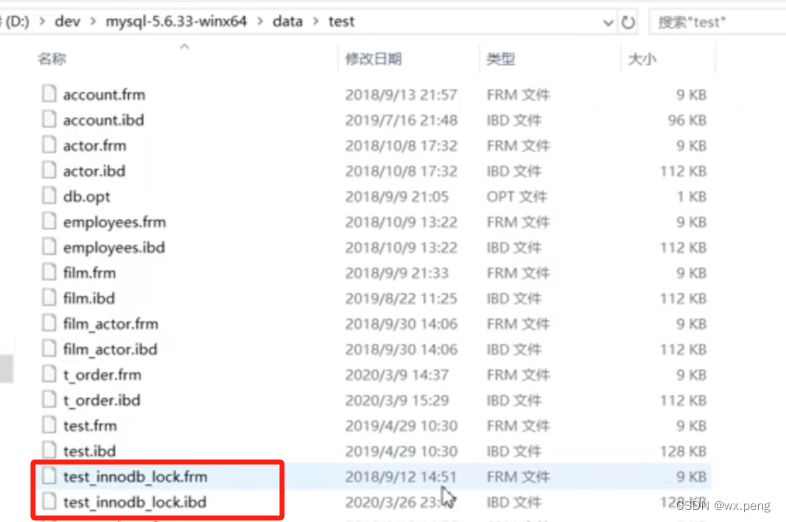
我们可以看到,对应的表有这两个文件
- .frm:表结构信息
- .ibd:数据和索引
.ibd文件其实就是存储我们整张表的所有数据,他会通过B+树的方式进行存储
换句话说,表数据文件本身就是按B+Tree组织的一个索引结构文件,其实也就是我们的聚集索引
这里可以简单的说明这个聚集的概念:
-
聚集索引,其实就是将索引和文件放在同一个文件里,像InnoDB就都放在.ibd文件中
-
而相对应的,叫做非聚集索引,也就是索引和文件不放在同一个文件里,在MyISAM中就是这么设计的,索引在.MYD文件,数据在.MYI文件中。

-
而对于InnoDB的二级索引,其实也是非聚集索引
建议InnoDB表必须建主键
知道了索引是怎么存储的,那我们也就能知道,为什么建议InnoDB表必须建主键
如果有了主键,我们可以直接根据主键生成一个聚集索引,来保存我们的数据。
所以在大多数情况下,聚集索引 = 主键索引
没有主键是怎么存储的
InnoDB表没有主键,也是可以建表的
如果没有主键,它会从第一列开始找,如果第一列所有数据都不相等,他就会直接拿第一列来组织B+树
如果第一列没选到,就继续往后,如果都没选到,它会帮你建一个隐藏列,隐藏列给每一行一个唯一的ID,然后通过这个隐藏列来构建B+树
但是,对于MySql来说,这其实不应该由它来做的。这纯属浪费资源
推荐使用整型的自增主键
整型
首先我们知道,我们通过索引找数据的过程,其实就是一个数据比大小的过程。
所以,相比于整型,其他的肯定没有它快
就那字符串来说,字符串比较是要逐位进行比较的,特别是越长的字符串,比较的次数越多,速度肯定越慢。虽然影响没有那么大,毕竟是在内存中比较的,但是肯定是有影响的。
同时,字符串的空间占用,一般要比整型的大
- 一方面,存储的成本提高了;
- 另一方面,按照我们上面的分析,B+树的矮壮性肯定是会受影响的。
自增
首先,我们要先知道,对于B+树来说,非顺序的插入,会增加B+树的工作,具体的话,大家可以通过数据结构网址来模拟这个过程,在这里我就不再说了。
但是,如果是顺序插入,那B+树就会一直往后去增加,这种效率肯定要比非顺序的效率高。
非主键索引(二级索引)
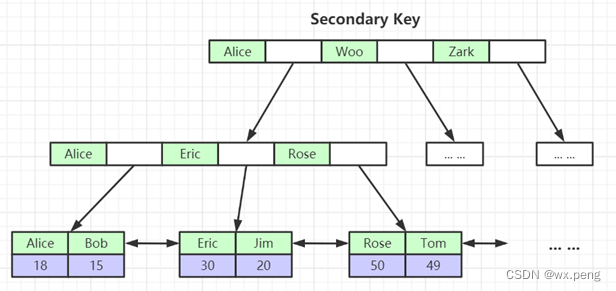
非主键索引,也成为二级索引,非聚集索引,和主键索引一样,也是才用B+树来进行存储。
不一样的是,二级索引下面的值,是存储主键的值。
这样是为了能够节省空间和保持一致性
节省空间很好理解,如果把所有数据都丢进来,占用的空间太大
保持一致性也很好理解,如果把所有数据丢进来,那修改数据的时候,主键索引和非主键索引都要改,这就很麻烦。
当然,这样的索引也有一个问题,就是由于数据和索引不是在一起的,所以往往我们查出来数据之后,就需要进行回表,根据主键索引找到对应的数据。
联合索引
联合索引就是多个字段共同构成的索引
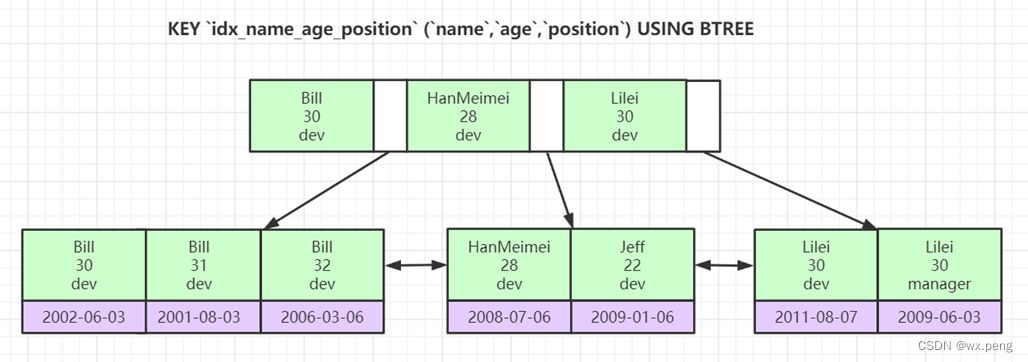
最左匹配原则
各位可以先想一想,如果让你来设计,你要怎么存储,来做到有序呢?
是不是就是一个字段一个字段的排序,先第一个有序,然后在考虑第二个。
那这也就引出了我们的最左匹配原则
就拿我们上面的例子,他会先比较name,然后比较age,最后比较position
SELECT * FROM employees WHERE name='Bill' and age=31; SELECT * FROM employees WHERE age =30 AND position='dev';从上面的图我们可以知道,第一条Sql肯定能走索引,但是第二条呢?
是不是发现了,走不了了,因为出去name了之后,这个索引已经不是有序的了
这就是我们的最左匹配原则。
那我们继续往下走,如果遇到范围查询(>,<,like左匹配)呢?
SELECT * FROM employees WHERE name='Bill' and age > 30 and position='dev';前面两个,走索引大家应该没什么疑问,但是到了第三个呢,从上面的图看,好像没问题,
但如果是这样呢
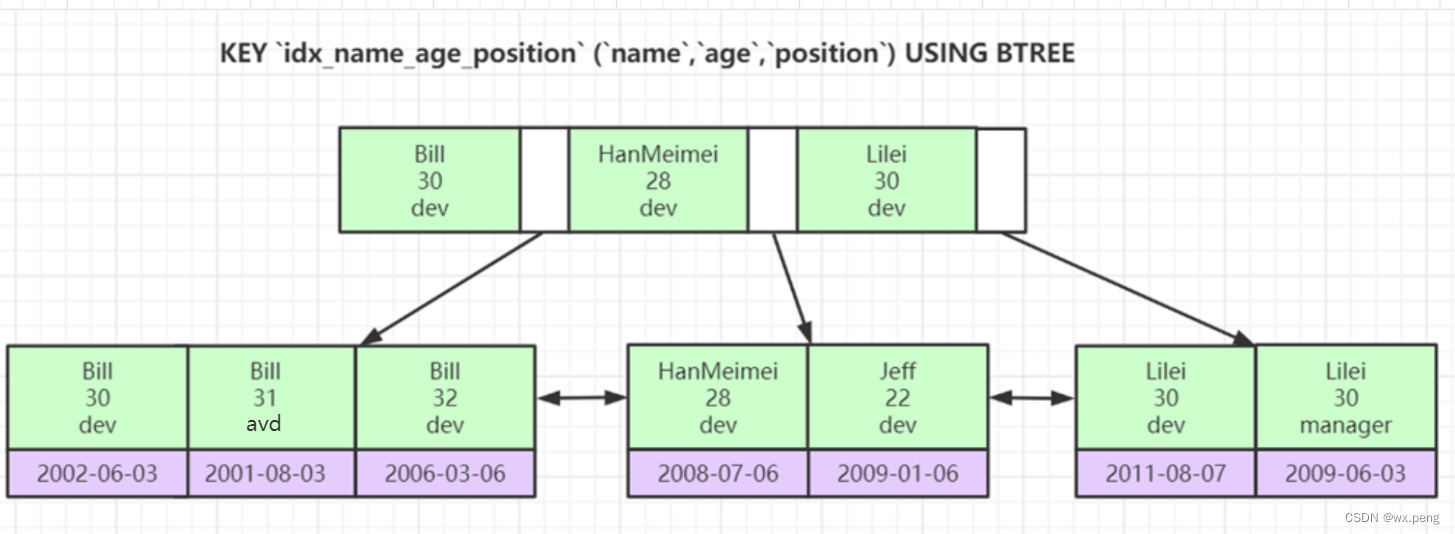
是不是发现,又是无序的了
但是,这里有一个比较有意思的,如果是>=、<=、between等这些带等于的,他其实是走了索引的。
SELECT * FROM employees WHERE name='Bill' and age >= 30 and position='dev';虽然在符合
age>= 30 条件的二级索引记录的范围里,position字段的值是「无序」的,但是对于符合age= 30 的二级索引记录的范围里,position字段的值是「有序」的(因为对于联合索引,是先按照age字段的值排序,然后在age字段的值相同的情况下,再按照position字段的值进行排序)。于是,在确定需要扫描的二级索引的范围时,当二级索引记录的
age字段值为 30 时,可以通过position= ‘dev’ 条件减少需要扫描的二级索引记录范围(position字段可以利用联合索引进行索引查询的意思)。也就是说,从符合age= 30 andposition= ‘dev’ 条件的第一条记录开始扫描,而不需要从第一个age字段值为 30 的记录开始扫描。所以,这条查询语句都用到了联合索引进行索引查询。
这其实也用到了我们另一个知识点:索引下推
索引下推,可以在索引遍历过程中,对索引中包含的字段先做判断,直接过滤掉不满足条件的记录,减少回表次数。
-
相关阅读:
[Python学习笔记]Requests性能优化之Session
【408专项篇】C语言笔记-第四章(选择与循环)
网络安全(黑客)自学
神经系统图 基本结构图,神经系统的组织结构图
监控易:IT基础资源监控的解决方案和价值
前端笔试题总结,带答案和解析(一)
springboot+task整合(定时任务)
Multi-View Learning(多视图学习/多视角学习 )是什么? Co-training(协同训练)和它的关系
基于ssm的果蔬商城管理系统
ERC721标准与加密猫
- 原文地址:https://blog.csdn.net/qq_43602877/article/details/139562565