-
正则表达式
正则表达式(Regular Expression,简称regex或regexp)是一种用于匹配字符串中字符组合的模式。在编写复杂的字符串处理逻辑时,正则表达式提供了强大的工具,使得文本搜索、文本替换、数据验证等操作变得更加简便和高效。以下是正则表达式的详细讲解,包括基本概念、常用符号和一些高级用法。
基本概念
- 字符:正则表达式中的字符可以是字母、数字、标点符号以及特殊字符。
- 元字符:在正则表达式中有特殊含义的字符,如
.、*、+、?、^、`$
(续)和
\等。- 模式:由字符和元字符组成的字符串,用于定义搜索模式。
常用符号和语法
字符匹配
- 普通字符:如
a、b、1、A等,直接匹配对应的字符。 - 点号
.:匹配除换行符\n以外的任何单个字符。 - 字符类
[]:匹配方括号内的任意一个字符。例如,[abc]匹配a、b或c。- 字符范围:如
[a-z]匹配任何小写字母,[0-9] 匹配任何数字。 - 排除字符类
[^]:如[^a-z]匹配任何不是小写字母的字符。
- 字符范围:如
预定义字符类
\d:匹配任何数字,相当于[0-9]。\D:匹配任何非数字字符,相当于[^0-9]。\w:匹配任何单词字符(字母、数字、下划线),相当于[A-Za-z0-9_]。\W:匹配任何非单词字符,相当于[^A-Za-z0-9_]。\s:匹配任何空白字符,包括空格、制表符、换页符等。\S:匹配任何非空白字符。
量词
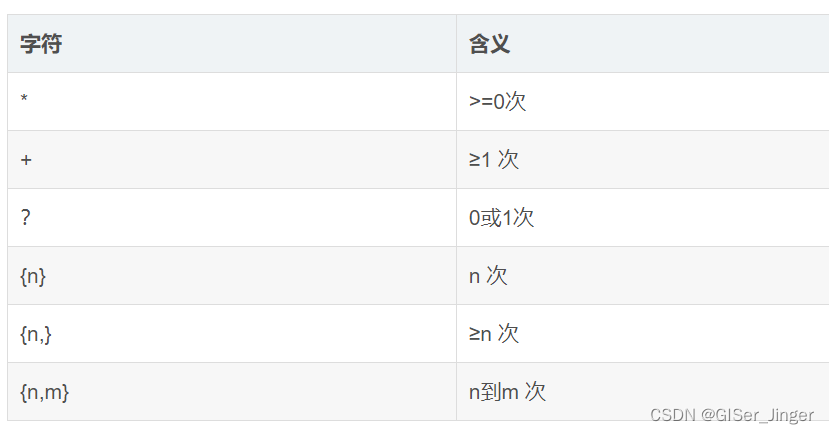
*:匹配前面的字符零次或多次。+:匹配前面的字符一次或多次。?:匹配前面的字符零次或一次。{n}:匹配前面的字符恰好n次。{n,}:匹配前面的字符至少n次。{n,m}:匹配前面的字符至少n次,至多m次。
边界匹配
^:匹配字符串的开头。$:匹配字符串的结尾。\b:匹配单词边界。\B:匹配非单词边界。
分组和捕获
- 圆括号
():用于分组,将括号内的内容视为一个整体。也用于捕获匹配的内容。- 例如,
(abc)+匹配abc、abcabc等。
- 例如,
- 反向引用:使用
\1,\2等来引用分组捕获的内容。- 例如,
(\d)\1匹配两个连续相同的数字,如11、22。
- 例如,
或操作符
|a|b:匹配a或b。- 例如,
cat|dog匹配cat或dog。
- 例如,
高级用法
零宽断言
- 正向先行断言
(?=...):匹配某个位置后面是指定的内容,但不包含在匹配结果中。- 例如,
\d(?=px)匹配3px中的3。
- 例如,
- 负向先行断言
(?!...):匹配某个位置后面不是指定的内容。- 例如,
\d(?!px)匹配3em中的3。
- 例如,
- 正向后行断言
(?<=...):匹配某个位置前面是指定的内容,但不包含在匹配结果中。- 例如,
(?<=\$)\d+匹配$100中的100。
- 例如,
- 负向后行断言
(?:匹配某个位置前面不是指定的内容。- 例如,
(? 匹配100而不匹配$100中的100。
- 例如,
常见示例
- 匹配电子邮件地址:
/^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$/ - 匹配电话号码:
/^(\+\d{1,3}[- ]?)?\d{10}$/ - 匹配网址:
/^(https?:\/\/)?(www\.)?[a-zA-Z0-9-]+\.[a-zA-Z]{2,6}\/?$/
在Javascript中的使用
- // 创建正则表达式
- let regex = /hello/;
- let regex2 = new RegExp('hello');
- // 测试字符串是否匹配正则表达式
- console.log(regex.test('hello world')); // true
- // 匹配字符串
- let str = 'hello world';
- let result = str.match(regex);
- console.log(result); // ['hello']
- // 替换字符串中的匹配部分
- let newStr = str.replace(regex, 'hi');
- console.log(newStr); // 'hi world'
⭐⭐附加⭐⭐

var reg = /正则表达式/修饰符;
修饰符:
- i: ignoreCase, 匹配忽视大小写
- m: multiline , 多行匹配
- g: global , 全局匹配
限定符
或运算符
- (ab|cd) ab或cd
- a (dog|cat) a dog 或a cat
字符类
- [a-c] [a-c] a或b或c
- [a-zA-Z0-9]匹配大小写字母以及数字
- [^0-9]非数字 此处^表示非
元字符
[] var reg = /[abc]/;//匹配abc任意一个字符
var reg1 = /abc/;//匹配abc^ var reg1 = /[^abc]/;//匹配abc之外的字符 var reg = /^abc/;//匹配以abc开头的字符 $ var reg = /abc$/;//匹配以abc结尾的字符
. 匹配除换行符以外的任意字符 \w 匹配字母或数字或下划线或汉字 \s 匹配任意的空白符 \d 匹配数字 \b 匹配单词的开始或结束 -
相关阅读:
uniapp 在uni.scss 根据@mixin定义方法 、通过@include全局使用
持续测试破解自动化测试的行业谜题
RocketMQ安装和使用
数字化安全生产平台 DPS 重磅发布
echarts+vue实现柱状图分页显示
Python编程基础:实验6——函数的递归
Android Framework 常见解决方案(21)默认开启adb
【机器学习基础】无监督学习(3)——AutoEncoder
计算机视觉与深度学习实战,Python工具,多尺度形态学提取眼前节
紫光同创FPGA实现UDP协议栈精简版,基于YT8511和RTL8211,提供2套PDS工程源码和技术支持
- 原文地址:https://blog.csdn.net/m0_55049655/article/details/139582869