-
Kafka详解
一、Kafka介绍
Kafka包括producer、consumer、broker、topic、Partition、Group
1、Producer
生产者即数据的发布者,该角色将消息发布到Kafka的topic中。broker接收到生产者发送的消息后, broker将该消息追加到当前用于追加数据的segment文件中。生产者发送的消息,存储到一个partition 中,生产者也可以指定数据存储的partition。
2、Consumer
消费者可以从broker中读取数据。消费者可以消费多个topic中的数据。
3、Topic
在Kafka中,使用一个类别属性来划分数据的所属类,划分数据的这个类称为topic。如果把Kafka看做 为一个数据库,topic可以理解为数据库中的一张表,topic的名字即为表名。
4、Partition
一个Topic下面会有多个Partition(分区),每个Partition都是一个有序队列,Partition中的每条消息都会被分配一个有序的id。每个topic至少有一个partition。partition中的数据是有序的,partition间的数据丢失了数据的顺序。如果 topic有多个partition,消费数据时就不能保证数据的顺序。在需要严格保证消息的消费顺序的场景下, 需要将partition数目设为1。
5、Partition offset
每条消息都有一个当前Partition下唯一的64字节的offset,它指明了这条消息的起始位置。
6、Replicas of partition
副本是一个分区的备份。副本不会被消费者消费,副本只用于防止数据丢失,即消费者不从为follower 的partition中消费数据,而是从为leader的partition中读取数据。副本之间是一主多从的关系。
7、Broker
Kafka 集群包含一个或多个服务器,服务器节点称为broker。broker存储topic的数据。如果某topic有 N个partition,集群有N个broker,那么每个broker存储该topic的一个partition。如果某topic有N个 partition,集群有(N+M)个broker,那么其中有N个broker存储该topic的一个partition,剩下的M个 broker不存储该topic的partition数据。如果某topic有N个partition,集群中broker数目少于N个,那么 一个broker存储该topic的一个或多个partition。在实际生产环境中,尽量避免这种情况的发生,这种 情况容易导致Kafka集群数据不均衡。
8、Leader
每个partition有多个副本,其中有且仅有一个作为Leader,Leader是当前负责数据的读写的 partition。
二、Kafka架构组件
1)topic:消息存放的目录即主题
2)Producer:生产消息到topic的一方
3)Consumer:订阅topic消费消息的一方
4)Broker:Kafka的服务实例就是一个broker

三、Kafka特点
- Kafka:内存、磁盘、数据库、支持大量堆积
- Kafka:支持负载均衡
- 集群方式,天然的‘Leader-Slave’无状态集群,每台服务器既是Master也是Slave。
四、Kafka配置
在kafka解压目录下下有一个config的文件夹,里面放置的是我们的配置文件
1、consumer.properites 消费者配置
2、producer.properties 生产者配置

3、server.properties kafka服务器的配置
1)broker.id 申明当前kafka服务器在集群中的唯一ID,需配置为integer,并且集群中的每一个kafka服务器的id都应是唯一的,我们这里采用默认配置即可
2)listeners 申明此kafka服务器需要监听的端口号,如果是在本机上跑虚拟机运行可以不用配置本项,默认会使用localhost的地址,如果是在远程服务器上运行则必须配置。
例如:listeners=PLAINTEXT:// 192.168.180.128:9092。并确保服务器的9092端口能够访问
3)zookeeper.connect 申明kafka所连接的zookeeper的地址 ,需配置为zookeeper的地址,由于本次使用的是kafka高版本中自带zookeeper,使用默认配置即可zookeeper.connect=localhost:2181



五、常用配置项
1、broker配置
配置项
作用
broker.id
broker的唯一标识
auto.create.topics.auto
设置成true,就是遇到没有的topic自动创建topic。
log.dirs
log的目录数,目录里面放partition,当生成新的partition时,会挑目录里partition数最少的目录放。
2、topic配置
配置项
作用
num.partitions
新建一个topic,会有几个partition。
log.retention.ms
对应的还有minutes,hours的单位。日志保留时间,因为删除是文件维度而不是消息维度,看的是日志文件的mtime。
log.retention.bytes
partion最大的容量,超过就清理老的。注意这个是partion维度,就是说如果你的topic有8个partition,配置1G,那么平均分配下,topic理论最大值8G。
log.segment.bytes
一个segment的大小。超过了就滚动。
log.segment.ms
一个segment的打开时间,超过了就滚动。
message.max.bytes
message最大多大
六、启动
1、启动ZooKeeper
.\zookeeper-server-start.bat ..\..\config\zookeeper.properties
2、启动Kafka
.\kafka-server-start.bat ..\..\config\server.properties
七、linux环境下创建topic
- [root@iZ2zegzlkedbo3e64vkbefZ ~]# cd /usr/local/kafka-cluster/kafka1/bin/
- [root@iZ2zegzlkedbo3e64vkbefZ bin]# ./kafka-topics.sh --create --zookeeper 172.17.80.219:2181 --replication-factor 2 --partitions 2 --topic topic1
- Created topic topic1.
- [root@iZ2zegzlkedbo3e64vkbefZ bin]# ./kafka-topics.sh --create --zookeeper 172.17.80.219:2181 --replication-factor 2 --partitions 2 --topic topic2
- Created topic topic2.
当然我们也可以不手动创建topic,在执行代码kafkaTemplate.send("topic1", normalMessage)发送消息时,kafka会帮我们自动完成topic的创建工作,但这种情况下创建的topic默认只有一个分区,分区也没有副本。
所以,我们可以在项目中新建一个配置类专门用来初始化topic,如下,
- @Configuration
- public class KafkaInitialConfiguration {
- // 创建一个名为testtopic的Topic并设置分区数为8,分区副本数为2
- @Bean
- public NewTopic initialTopic() {
- return new NewTopic("testtopic",8, (short) 1 );
- }
-
- // 如果要修改分区数,只需修改配置值重启项目即可
- // 修改分区数并不会导致数据的丢失,但是分区数只能增大不能减小
- @Bean
- public NewTopic updateTopic() {
- return new NewTopic("testtopic",10, (short) 2 );
- }
- }
八、Kafka API AdminClient的使用
1、创建kafka队列

2、修改kafka分区数

3、查询所有的topic

4、查询topic是否存在

5、查询Topic的配置信息

6、获取指定topic的分区数
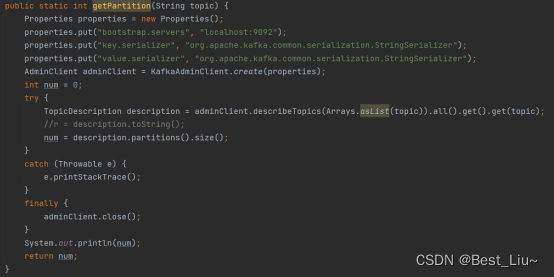
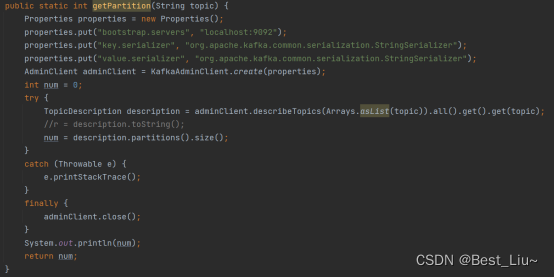
九、Springboot集成kafka
1、springboot引入kafka依赖
org.springframework.kafka spring-kafka
2、application.propertise配置
- ###########【Kafka集群】###########
- spring.kafka.bootstrap-servers=112.126.74.249:9092,112.126.74.249:9093
- ###########【初始化生产者配置】###########
- # 重试次数
- spring.kafka.producer.retries=0
- # 应答级别:多少个分区副本备份完成时向生产者发送ack确认(可选0、1、all/-1)
- spring.kafka.producer.acks=1
- # 批量大小
- spring.kafka.producer.batch-size=16384
- # 提交延时
- spring.kafka.producer.properties.linger.ms=0
- # 当生产端积累的消息达到batch-size或接收到消息linger.ms后,生产者就会将消息提交给kafka
- # linger.ms为0表示每接收到一条消息就提交给kafka,这时候batch-size其实就没用了
-
- # 生产端缓冲区大小
- spring.kafka.producer.buffer-memory = 33554432
- # Kafka提供的序列化和反序列化类
- spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
- spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
- # 自定义分区器
- # spring.kafka.producer.properties.partitioner.class=com.felix.kafka.producer.CustomizePartitioner
-
- ###########【初始化消费者配置】###########
- # 默认的消费组ID
- spring.kafka.consumer.properties.group.id=defaultConsumerGroup
- # 是否自动提交offset
- spring.kafka.consumer.enable-auto-commit=true
- # 提交offset延时(接收到消息后多久提交offset)
- spring.kafka.consumer.auto.commit.interval.ms=1000
- # 当kafka中没有初始offset或offset超出范围时将自动重置offset
- # earliest:重置为分区中最小的offset;
- # latest:重置为分区中最新的offset(消费分区中新产生的数据);
- # none:只要有一个分区不存在已提交的offset,就抛出异常;
- spring.kafka.consumer.auto-offset-reset=latest
- # 消费会话超时时间(超过这个时间consumer没有发送心跳,就会触发rebalance操作)
- spring.kafka.consumer.properties.session.timeout.ms=120000
- # 消费请求超时时间
- spring.kafka.consumer.properties.request.timeout.ms=180000
- # Kafka提供的序列化和反序列化类
- spring.kafka.consumer.key-deserializer=org.apache.kafka.common.serialization.StringDeserializer
- spring.kafka.consumer.value-deserializer=org.apache.kafka.common.serialization.StringDeserializer
- # 消费端监听的topic不存在时,项目启动会报错(关掉)
- spring.kafka.listener.missing-topics-fatal=false
- # 设置批量消费
- # spring.kafka.listener.type=batch
- # 批量消费每次最多消费多少条消息
- # spring.kafka.consumer.max-poll-records=50
3、Kafka简单操作
1)生产者
- @RestController
- @RequestMapping("/kafka")
- public class KafkaProducer {
- @Autowired
- private KafkaTemplate
-
- // 发送消息
- @GetMapping("/normal")
- public void sendMessage1() {
- kafkaTemplate.send("topic1", normalMessage);
- }
- }
2)消费者
- @Component
- public class KafkaConsumer {
- // 消费监听
- @KafkaListener(topics = {"topic1"})
- public void onMessage1(ConsumerRecord record){
- // 消费的哪个topic、partition的消息,打印出消息内容
- System.out.println("简单消费:"+record.topic()+"-"+record.partition()+"-"+record.value());
- }
- }
消息确认机制:
为确保消息被成功处理,可以使用消息确认机制。例如,在消费者中手动确认消息:- @Service
- public class KafkaConsumer {
- @KafkaListener(topics = "my-topic", groupName = "my-group")
- public void consume(String message) {
- System.out.println("Consumed: " + message);
- // 手动确认消息已处理完成。
- kafkaTemplate.acknowledge(Collections.singletonList(message)); // 如果是手动确认模式。
- }
- }
3)带回调的生产者
- @GetMapping("/kafka/callbackOne/{message}")
- public void sendMessage2(@PathVariable("message") String callbackMessage) {
- kafkaTemplate.send("topic1", callbackMessage).addCallback(success -> {
- // 消息发送到的topic
- String topic = success.getRecordMetadata().topic();
- // 消息发送到的分区
- int partition = success.getRecordMetadata().partition();
- // 消息在分区内的offset
- long offset = success.getRecordMetadata().offset();
- System.out.println("发送消息成功:" + topic + "-" + partition + "-" + offset);
- }, failure -> {
- System.out.println("发送消息失败:" + failure.getMessage());
- });
- }
4)指定topic、partition、offset消费
- /**
- * @Title 指定topic、partition、offset消费
- * @Description 同时监听topic1和topic2,监听topic1的0号分区、topic2的 "0号和1号" 分区,指向1号分区的offset初始值为8
- * @Author long.yuan
- * @Date 2020/3/22 13:38
- * @Param [record]
- * @return void
- **/
- @KafkaListener(id = "consumer1",groupId = "felix-group",topicPartitions = {
- @TopicPartition(topic = "topic1", partitions = { "1" }),
- @TopicPartition(topic = "topic2", partitions = "0", partitionOffsets = @PartitionOffset(partition = "1", initialOffset = "8"))
- })
- public void onMessage1(ConsumerRecord record){
- // 消费的哪个topic、partition的消息,打印出消息内容
- System.out.println("简单消费:"+record.topic()+"-"+record.partition()+"-"+record.value()+"-"+record.offset());
- }
5)消息过滤器
- @Component
- public class KafkaConsumer {
- @Autowired
- ConsumerFactory consumerFactory;
-
- // 消息过滤器
- @Bean
- public ConcurrentKafkaListenerContainerFactory filterContainerFactory() {
- ConcurrentKafkaListenerContainerFactory factory = new ConcurrentKafkaListenerContainerFactory();
- factory.setConsumerFactory(consumerFactory);
- // 被过滤的消息将被丢弃
- factory.setAckDiscarded(true);
- // 消息过滤策略
- factory.setRecordFilterStrategy(consumerRecord -> {
- if (Integer.parseInt(consumerRecord.value().toString()) % 2 == 0) {
- return false;
- }
- //返回true消息则被过滤
- return true;
- });
- return factory;
- }
-
- // 消息过滤监听
- @KafkaListener(topics = {"topic1"},containerFactory = "filterContainerFactory")
- public void onMessage6(ConsumerRecord record) {
- System.out.println(record.value());
- }
- }
6)消息转发
从topic1接收到的消息经过处理后转发到topic2
- @KafkaListener(topics = {"topic1"})
- @SendTo("topic2")
- public String onMessage7(ConsumerRecord record) {
- return record.value()+"-forward message";
- }
十、Kafka保证消息不丢失
Kafka 要保证消息不会丢失,需要在producer、broker、consumer共同保证消息不丢失
1、producer生产者配置
1)producer端使用producer.send(msg,callback) 带有回调 send 的方法,而不是producer.send(msg)方法,根据callback 回调,一旦消息提交失败,就可以针对性的补偿处理。
2)设置ack=all,表面所有的broker上的副本都已经落盘成功了,才算是“已提交”
3)retries >1自动重试的次数,当出现网络问题时,消息可能会发送失败,配置了retries 能够自动重试,尽量避免消息丢失。最严谨的方式是失败的消失日志记录或者入库,然后定时重发。2、Broker配置
1)unclean.leader.election.enable =false,禁止ISR之外的副本参与选举,否则就有可能丢丢失消息
2)replication-factor >=3,需要三个以上的副本
3)min.insync.replicas>1,broker端的参数,至少写入多少个ISR中副本才算是“已提交”,大于1 可以提升消息的持久性,推荐设置replication-factor=min.insync.replicas+13、consumer消费者配置
1)确保消息已经消费完成在提交
2)enable.auto.commit 设置成false,并自己来处理offset的提交更新
- //文件KafkaReceiver中的消息接收,新增Acknowledgment 接收字段
- @KafkaListener(id = "rollback_default_test", topics = {"topic.quick.default"})
- public void receiveSk(ConsumerRecord
- System.out.println(record);
- System.out.println("我收到了普通消息");
- // 手动确认消息被 消费
- ack.acknowledge();
- // ack.nack(1000); 拒收当前消息,并睡眠10秒钟后再重新接收消息
- // ack.nack(100,1000); 拒收当前消息,并睡眠10秒钟后接收第100条之后的消息
- }
十一、常见消息中间件的介绍和对比
Kafka、RabbitMQ、RocketMQ常见消息中间件的介绍和对比
1、Kafka

Kafka是LinkedIn开源的分布式发布-订阅消息系统,目前归属于Apache顶级项目。Kafka主要为高吞吐量的订阅发布系统而设计,追求速度与持久化。kafka中的消息由键、值、时间戳组成,kafka不记录每个消息被谁使用,只通过偏移量记录哪些消息是未读的,kafka中可以指定消费组来实现订阅发布的功能。
2、RabbitMQ

RabbitMQ是使用Erlang语言开发的开源消息队列系统,基于AMQP协议来实现。AMQP的主要特征是面向消息、队列、路由(包括点对点和发布/订阅)、可靠性、安全。AMQP协议更多用在企业系统内,对数据一致性、稳定性和可靠性要求很高的场景,对性能和吞吐量的要求还在其次。
3、RocketMQ
RocketMQ是阿里开源的消息中间件,它是纯Java开发,具有高吞吐量、高可用性、适合大规模分布式系统应用的特点。RocketMQ思路起源于Kafka,但并不是Kafka的一个Copy,它对消息的可靠传输及事务性做了优化,目前在阿里集团被广泛应用于交易、充值、流计算、消息推送、日志流式处理、binglog分发等场景。支持的客户端语言不多,目前是Java及C++,其中C++还不成熟;
4、对比概览

1、Rabbitmq比kafka可靠,kafka更适合IO高吞吐的处理,比如ELK日志收集。
2、kafka具有高的吞吐量,内部采用消息的批量处理,zero-copy机制,数据的存储和获取是本地磁盘顺序批量操作,具有O(1)的复杂度,消息处理的效率很高。rabbitMQ在吞吐量方面稍逊于kafka,他们的出发点不一样,rabbitMQ支持对消息的可靠的传递,支持事务,不支持批量的操作;基于存储的可靠性的要求存储可以采用内存或者硬盘。
十二、docker启动kafka
1、拉取zookeeper镜像
docker pull bitnami/zookeeper
2、拉取kafka镜像
docker pull bitnami/kafka
3、docker-compose.yml
- version: "3"
- services:
- zookeeper:
- image: bitnami/zookeeper:latest
- container_name: zookeeper
- # user: root
- restart: always
- ports:
- - 2181:2181
- environment:
- # 匿名登录--必须开启
- - ALLOW_ANONYMOUS_LOGIN=yes
- volumes:
- - ./zookeeper:/bitnami/zookeeper
- # 该镜像具体配置参考 https://github.com/bitnami/bitnami-docker-kafka/blob/master/README.md
- kafka:
- image: bitnami/kafka:latest
- container_name: kafka
- restart: always
- hostname: kafka
- # user: root
- ports:
- - 9092:9092
- environment:
- - KAFKA_BROKER_ID=1
- - KAFKA_CFG_LISTENERS=PLAINTEXT://0.0.0.0:9092
- # 客户端访问地址,更换成自己的
- - KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://192.168.4.252:9092
- - KAFKA_CFG_ZOOKEEPER_CONNECT=zookeeper:2181
- - KAFKA_ADVERTISED_HOST_NAME=kafka
- - KAFKA_ADVERTISED_PORT=9092
- - KAFKA_ZOOKEEPER_CONNECT=zookeeper:2181
- # 允许使用PLAINTEXT协议(镜像中默认为关闭,需要手动开启)
- - ALLOW_PLAINTEXT_LISTENER=yes
- # 关闭自动创建 topic 功能
- - KAFKA_CFG_AUTO_CREATE_TOPICS_ENABLE=false
- # 全局消息过期时间 6 小时(测试时可以设置短一点)
- - KAFKA_CFG_LOG_RETENTION_HOURS=6
- # 开启JMX监控
- # - JMX_PORT=9999
- volumes:
- - ./kafka:/bitnami/kafka
- depends_on:
- - zookeeper
- # Web 管理界面 另外也可以用exporter+prometheus+grafana的方式来监控 https://github.com/danielqsj/kafka_exporter
- # kafdrop:
- # image: obsidiandynamics/kafdrop:latest
- # ports:
- # - 9000:9000
- # restart: always
- # extra_hosts:
- # - kafka1:192.168.4.252
- # environment:
- # KAFKA_BROKERCONNECT: "kafka:9092"
- # depends_on:
- # - zookeeper
- # - kafka
- # container_name: kafdrop
- # cpus: '1'
- # mem_limit: 1024m
-
相关阅读:
Python吴恩达深度学习作业24 -- 语音识别关键字
[附源码]JAVA毕业设计简易在线教学系统(系统+LW)
第十一章《Java实战常用类》第4节:Random类
最新一站式AI创作中文系统网站源码+系统部署+支持GPT对话、Midjourney绘画、Suno音乐、GPT-4o文档分析等大模型
Java容器之Map
git学习笔记
D. Make Them Equal(dp + 范围优化 )
开了挂似的,直接涨薪25K,跪谢这份Java性能调优实战宝典
1796_通过vmware打开VirtualBox虚拟机文件
windows搭建elasticsearch和elasticsearch-head/kibana
- 原文地址:https://blog.csdn.net/askuld/article/details/139629441