-
混淆矩阵(Confusion Matrix)
一,混淆矩阵简介
随着机器学习和人工智能的迅速发展,分类模型成为了解决各种问题的重要工具。然而,仅仅知道模型预测对了多少样本是不够的。我们需要一种更详细、更系统的方法来理解模型的分类能力,以及它在不同类别上的表现。
混淆矩阵是在机器学习和统计学中用于评估分类模型性能的一种表格。它对模型的分类结果进行了详细的总结,特别是针对二元分类问题,另外混淆矩阵是用于评估分类模型性能的一种表格,特别适用于监督学习中的分类问题。它以矩阵形式展示了模型对样本进行分类的情况,将模型的预测结果与实际标签进行对比。
二,混淆矩阵概述
混淆矩阵是一种用于评估分类模型性能的重要工具。它通过矩阵形式清晰地展示了模型对样本进行分类的结果,帮助我们理解模型在不同类别上的表现。
1.基本结构
混淆矩阵的基本结构如下:
预测为正类别 预测为负类别 实际为正类别 True Positive (TP) False Negative (FN) 实际为负类别 False Positive (FP) True Negative (TN) - True Positive (TP): 模型将实际为正类别的样本正确预测为正类别。
- False Negative (FN): 模型将实际为正类别的样本错误预测为负类别。
- False Positive (FP): 模型将实际为负类别的样本错误预测为正类别。
- True Negative (TN): 模型将实际为负类别的样本正确预测为负类别。
这些元素帮助我们理解模型在分类任务中所做的预测,并将这些预测与实际情况进行对比。
2.作用
混淆矩阵的目的是帮助我们理解分类模型在不同类别上的表现。通过将模型的分类结果分成真正类别(True)和错误类别(False),我们可以计算出一系列性能指标,例如准确率、精确率、召回率和F1分数。这些指标帮助我们量化模型的分类准确性、可靠性和全面性。
3. 用途
混淆矩阵广泛应用于各种领域,包括医学诊断、自然语言处理、图像处理等。在医学领域,混淆矩阵可以用于评估疾病诊断模型,判断病人是否患有特定疾病。在自然语言处理中,它可用于评估文本分类模型,判断一段文本属于哪个类别。混淆矩阵为我们提供了详细的信息,可以用于模型性能的改进和优化。
混淆矩阵是理解分类模型性能的关键,它提供了对模型预测的深入洞察,使我们能够更好地理解模型的分类能力,以便采取适当的措施来改进模型。
三,混淆矩阵示例
为了更好地理解混淆矩阵,让我们考虑一个简单的二元分类问题。假设我们正在开发一个垃圾邮件检测器,目标是将电子邮件分为两类:垃圾邮件(正类别)和非垃圾邮件(负类别)。
假设我们已经训练好了一个分类模型,并用测试数据集进行了测试。测试集共有100个样本,结果如下:
- 模型将60封实际是垃圾邮件的邮件预测为垃圾邮件(True Positive, TP = 60)。
- 模型将10封实际是垃圾邮件的邮件错误地预测为非垃圾邮件(False Negative, FN = 10)。
- 模型将5封实际上不是垃圾邮件的邮件错误地预测为垃圾邮件(False Positive, FP = 5)。
- 模型将25封实际上不是垃圾邮件的邮件正确预测为非垃圾邮件(True Negative, TN = 25)。
基于这些结果,我们可以构建混淆矩阵:
预测为垃圾邮件 预测为非垃圾邮件 实际是垃圾邮件 60 (TP) 10 (FN) 实际非垃圾邮件 5 (FP) 25 (TN) 分析:
- True Positive (TP): 模型正确地将实际为垃圾邮件的60封邮件预测为垃圾邮件。
- False Negative (FN): 模型将实际为垃圾邮件的10封邮件错误地预测为非垃圾邮件。
- False Positive (FP): 模型将实际非垃圾邮件的5封邮件错误地预测为垃圾邮件。
- True Negative (TN): 模型正确地将实际非垃圾邮件的25封邮件预测为非垃圾邮件。
混淆矩阵为我们提供了对分类模型性能的详细视图,有助于我们理解模型在不同类别上的表现。
四,混淆矩阵解释
混淆矩阵是评估分类模型性能的基础,它可以帮助我们计算多种重要的性能指标,以量化模型在不同类别上的表现。
1. 准确率(Accuracy)
准确率表示模型正确分类的样本占总样本数的比例,计算方式为:
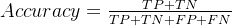
2. 精确率(Precision)
精确率表示模型预测为正类别的样本中有多少是真正的正类别,计算方式为:
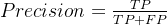
3. True Positive Rate (TPR) - 召回率/灵敏度
召回率,也称为 True Positive Rate (TPR) 或灵敏度,是指在所有实际为正类别的样本中,模型能够正确预测为正类别的比例。其计算方式为::
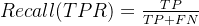
高召回率意味着模型能够有效地捕捉到实际为正类别的样本,是在医疗诊断等领域非常重要的指标。
4.True Negative Rate (TNR) - 特异度
特异度,也称为 True Negative Rate (TNR),是指在所有实际为负类别的样本中,模型能够正确预测为负类别的比例。其计算方式为:
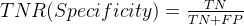
高特异度意味着模型能够有效地将实际为负类别的样本正确分类。
5. False Positive Rate (FPR)
False Positive Rate (FPR) 是指在所有实际为负类别的样本中,模型错误预测为正类别的比例。其计算方式为:
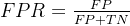
FPR 与特异度有关,是衡量模型在负类别样本中的误判程度。
6. False Negative Rate (FNR)
False Negative Rate (FNR) 是指在所有实际为正类别的样本中,模型错误预测为负类别的比例。其计算方式为:
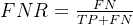
FNR 表示模型在正类别样本中的遗漏程度,即未能正确识别的正类别样本比例。
7. F1 分数(F1-score)
F1 分数是精确率和召回率的调和平均数,它综合了两者的性能,计算方式为:
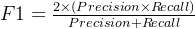
F1 分数的取值范围是 [0, 1],越接近 1 表示模型的性能越好,同时考虑到了模型在查准率和查全率之间的平衡。F1 分数对于二元分类问题非常有用,特别是当我们希望在精确率和召回率之间取得平衡时。高 F1 分数意味着模型在查准率和查全率之间取得了良好的平衡。
这些指标提供了多方面的信息,帮助我们全面了解模型的性能。准确率衡量了模型在所有样本上的整体表现,精确率关注模型在预测为正类别的样本上的准确性,召回率关注模型在实际为正类别的样本上的覆盖程度,而 F1 分数平衡了精确率和召回率。
混淆矩阵和这些性能指标共同提供了对分类模型性能全面的理解,并帮助我们评估模型的优缺点,进而进行必要的改进。
五,混淆矩阵在实践中的应用
混淆矩阵是一个强大的工具,可以帮助我们深入了解分类模型的性能,特别是在不同应用场景中,它发挥了重要作用。
1. 医疗诊断
在医疗领域,混淆矩阵被广泛应用于评估医学诊断模型的性能。例如,针对某种疾病的诊断模型,我们可以将患者分为“患病”和“未患病”两类。通过混淆矩阵,我们可以计算出模型的准确率、召回率、精确率等性能指标,以及了解模型在不同疾病阶段的表现。
2. 自然语言处理
在自然语言处理领域,混淆矩阵常用于文本分类问题。例如,针对垃圾邮件过滤模型,我们可以将邮件分为“垃圾邮件”和“正常邮件”两类。通过混淆矩阵,我们可以评估模型对垃圾邮件的识别能力,并根据误判情况调整模型参数,提高模型性能。
3. 图像识别
在图像识别领域,混淆矩阵可以用于评估模型对不同物体的识别性能。例如,在车辆识别模型中,我们可以将图像分为“汽车”和“非汽车”两类。混淆矩阵可以帮助我们了解模型在不同车型上的识别情况,进而改进模型的分类能力。
4. 改进模型
利用混淆矩阵,我们可以分析模型的误判情况,进而有针对性地调整模型参数或进行数据增强。比如,如果模型在正类别上有较高的误判率,我们可以通过增加正类别样本或调整模型阈值来改善模型的性能。
混淆矩阵不仅提供了模型性能评估的可视化结果,也为我们改进模型、优化模型参数提供了有力的依据。在实践中,混淆矩阵是一个非常实用的工具,有助于我们不断优化模型,提高模型的分类能力。
六,总结
-
混淆矩阵概述:
- 混淆矩阵是一个二维矩阵,用于总结分类模型在不同类别上的预测结果,包括 True Positive (TP)、False Negative (FN)、False Positive (FP)、True Negative (TN)。
-
性能指标:
- 准确率(Accuracy):模型正确分类的样本占总样本数的比例。
- 精确率(Precision):模型预测为正类别的样本中有多少是真正的正类别。
- 召回率(Recall):实际为正类别的样本中,有多少被模型正确预测为正类别。
- F1 分数:精确率和召回率的调和平均数,综合考虑了查准率和查全率。
-
其他性能指标:
- True Positive Rate (TPR) - 召回率/灵敏度:实际为正类别的样本中,模型能够正确预测为正类别的比例。
- True Negative Rate (TNR) - 特异度:实际为负类别的样本中,模型能够正确预测为负类别的比例。
- False Positive Rate (FPR):实际为负类别的样本中,模型错误预测为正类别的比例。
- False Negative Rate (FNR):实际为正类别的样本中,模型错误预测为负类别的比例。
-
混淆矩阵在实践中的应用:
- 在医疗诊断、自然语言处理、图像识别等领域,混淆矩阵被广泛应用于模型性能评估和优化。
- 通过分析混淆矩阵,可以改进模型、优化模型参数,以提高模型的分类能力。
混淆矩阵是一个重要且多用途的工具,为我们提供了深入了解分类模型性能的手段,有助于不断改进和优化我们的机器学习应用。深刻理解和熟练应用混淆矩阵和相关性能指标将有助于我们在实践中构建更可靠和高效的分类模型。
-
相关阅读:
算法——滑动窗口
故障电弧探测器的必要性及组网方案 安科瑞 时丽花
使用Element进行前端开发
【洛谷题解/SDOI2008】P2158 仪仗队
【Try Hack Me】Buffer Overflow-2
CPP emplace_bake 和 push_back 的相同和区别
Leetcode 435. 无重叠区间
阿里云服务器企业级和入门级实例规格有何区别?如何选择?
ctfshow-web2(SQL注入)
单链表排序
- 原文地址:https://blog.csdn.net/fhy567888/article/details/133642746