-
C++ XML文件和解析
XML(可扩展标记语言)是一种用于存储和传输数据的标记语言。它具有自描述性和平台无关性的特点。XML 文档的格式主要由一组嵌套的元素和属性构成,结构清晰,易于理解和解析。
XML 文档的基本格式
一个 XML 文档通常包括以下部分:
- XML 声明:标识文档和版本信息。
- 根元素:整个 XML 文档只能有一个根元素,所有其他元素必须嵌套在根元素内。
- 元素:具有开始标签和结束标签,可以嵌套其他元素。
- 属性:为元素提供额外的信息。
- 文本内容:元素可以包含文本内容。
- 注释:用于注释文档内容。
具体示例
以下是一个简单的 XML 文档示例,展示了上述基本部分:
- "1.0" encoding="UTF-8"?>
- <bookstore>
- <book category="cooking">
- <title lang="en">Everyday Italiantitle>
- <author>Giada De Laurentiisauthor>
- <year>2005year>
- <price>30.00price>
- book>
- <book category="children">
- <title lang="en">Harry Pottertitle>
- <author>J K. Rowlingauthor>
- <year>2005year>
- <price>29.99price>
- book>
- <book category="web">
- <title lang="en">Learning XMLtitle>
- <author>Erik T. Rayauthor>
- <year>2003year>
- <price>39.95price>
- book>
- bookstore>
XML 文档的详细部分
XML 声明:
"1.0" encoding="UTF-8"?>这是文档的声明部分,指定了 XML 版本和编码方式。
注释:
注释可以放在 XML 文档中的任何位置,不会被解析器处理。
根元素:
- <bookstore>
- bookstore>
bookstore 是根元素,所有其他元素都嵌套在其中。
元素:
- <book category="cooking">
- <title lang="en">Everyday Italiantitle>
- <author>Giada De Laurentiisauthor>
- <year>2005year>
- <price>30.00price>
- book>
book 是一个元素,其中包含了多个子元素和一个属性 category。
属性:
- <book category="cooking">
- <title lang="en">Everyday Italiantitle>
- book>
category 和 lang 是属性,为元素提供额外的信息。
文本内容:
<title lang="en">Everyday Italiantitle>title 元素包含了文本内容 Everyday Italian。
常见的 XML 结构
嵌套元素:
- <family>
- <parent name="John">
- <child name="Doe" age="10"/>
- <child name="Jane" age="8"/>
- parent>
- family>
元素可以嵌套其他元素,形成层级结构。
属性和子元素结合:
- <employee id="1001">
- <name>John Doename>
- <department>HRdepartment>
- <salary>5000salary>
- employee>
元素可以同时包含属性和子元素。
自闭合元素:
<img src="image.jpg" alt="Sample Image"/>自闭合元素是一种简洁的表示方式,不包含子元素。
XML 文档的规则
- 良好格式:XML 文档必须是良好格式的,即每个元素都必须正确关闭,元素必须正确嵌套,属性值必须用引号括起来。
- 区分大小写:XML 标签是区分大小写的。
- 根元素:每个 XML 文档必须有且只有一个根元素。
- 特殊字符:某些字符(如 <, >, & 等)在 XML 中有特殊含义,需要使用转义序列(如 <, >, &)表示。
XML文档解析
XML 文件解析通常有两种主要方式:DOM(Document Object Model)解析和 SAX(Simple API for XML)解析。这两种方法各有优缺点,适用于不同的应用场景。
DOM 解析
DOM 解析将整个 XML 文档读入内存中,并将其表示为一个树结构。每个节点在树中对应 XML 文档中的一个元素。用户可以通过 DOM API 访问和操作树中的节点。
优点
- 易于使用:通过树结构可以方便地访问和操作 XML 文档中的任意节点。
- 丰富的功能:支持随机访问和复杂的查询操作。
- 标准化:DOM 是 W3C 标准,广泛支持和文档丰富。
缺点
- 内存消耗大:需要将整个 XML 文档加载到内存中,对于大文件可能会导致高内存占用。
- 性能较低:解析和构建整个文档树的开销较大,处理大文件时性能可能会成为瓶颈。
适用场景
- 适用于需要频繁访问和操作 XML 文档的应用场景。
- 适用于中小规模的 XML 文档。
示例(使用 TinyXML)
- #include
- using namespace tinyxml2;
- int main() {
- XMLDocument doc;
- doc.LoadFile("example.xml");
- XMLElement* root = doc.RootElement();
- if (root != nullptr) {
- XMLElement* element = root->FirstChildElement("ElementName");
- if (element != nullptr) {
- const char* text = element->GetText();
- printf("Element text: %s\n", text);
- }
- }
- return 0;
- }
SAX 解析
SAX 解析是一种事件驱动的解析方法,逐行读取 XML 文档,并在遇到不同的结构(如开始标签、结束标签、文本节点等)时触发相应的事件处理函数。SAX 解析不会将整个文档加载到内存中,而是按需处理文档内容。
优点
- 内存消耗低:不需要将整个文档加载到内存中,适合处理大文件。
- 性能高:按顺序处理文档内容,解析速度快。
缺点
- 使用复杂:事件驱动的编程模型较为复杂,需要编写事件处理函数。
- 不支持随机访问:只能按顺序读取文档内容,无法直接访问任意节点。
适用场景
- 适用于处理大型 XML 文档或内存有限的环境。
- 适用于一次性读取和处理文档内容的场景。
示例(使用 Expat)
- #include
- #include
- #include
- void startElement(void *userData, const char *name, const char **atts) {
- printf("Start element: %s\n", name);
- }
- void endElement(void *userData, const char *name) {
- printf("End element: %s\n", name);
- }
- void characterData(void *userData, const char *s, int len) {
- printf("Character data: %.*s\n", len, s);
- }
- int main() {
- FILE *file = fopen("example.xml", "r");
- if (!file) return 1;
- XML_Parser parser = XML_ParserCreate(NULL);
- XML_SetElementHandler(parser, startElement, endElement);
- XML_SetCharacterDataHandler(parser, characterData);
- char buffer[1024];
- size_t len;
- while ((len = fread(buffer, 1, sizeof(buffer), file)) != 0) {
- if (XML_Parse(parser, buffer, len, feof(file)) == XML_STATUS_ERROR) {
- fprintf(stderr, "Parse error at line %lu:\n%s\n",
- XML_GetCurrentLineNumber(parser),
- XML_ErrorString(XML_GetErrorCode(parser)));
- return 1;
- }
- }
- XML_ParserFree(parser);
- fclose(file);
- return 0;
- }
总结
- DOM 解析:适合需要随机访问和操作 XML 内容的场景,使用简单但内存和性能消耗较大。
- SAX 解析:适合处理大文件或内存有限的场景,性能高但使用复杂。
tinyxml2 库
tinyxml2 是一款简单、小巧、高效的开源C++ xml解析库,在 tinyxml2 库中,XMLNode 是一个基类,它有几个派生类型。这些派生类型用于表示不同类型的 XML 节点。以下是 XMLNode 的主要派生类型:
XMLDocument:
- 表示整个 XML 文档。
- XMLDocument 是 XMLNode 的根,可以包含其他节点。
- 提供了加载、保存和解析 XML 文档的功能。
XMLElement:
- 表示 XML 文档中的一个元素(节点)。
- 可以包含其他元素、属性和文本。
- 是最常用的节点类型,用于表示 XML 标签。
XMLText:
- 表示 XML 元素中的文本内容。
- 用于包含实际的文本数据。
XMLComment:
- 表示 XML 文档中的注释节点。
- 注释节点内容不参与 XML 文档的逻辑处理,只用于提供额外的信息。
XMLDeclaration:
- 表示 XML 文档的声明部分(如 )。
- 通常在文档的最开始。
XMLUnknown:
- 表示未知的 XML 节点类型。
- 用于处理不符合其他已知节点类型的节点。
XMLAttribute:
- 严格来说,XMLAttribute 不是从 XMLNode 派生的,但它用于描述 XML 元素的属性。
- 属性节点包含名称和值,不直接参与 XML 文档的树结构。
tinyxml2解析有限元求解文件
一些有限元求解器的求解文件就是xml格式的,以开源FEM软件FEBio的求解文件为例,我们使用tinyxml2来提取里面的一些关键信息。

对于一个包含2万节点,12万单元的模型文件,我们通过tinyxml2解节点和单元信息花了0.3s,这个效率还是不错的。
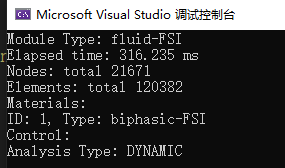
如下为tinyxml2解析FEBio求解文件源码:
- #include "tinyxml2.h"
- #include
- #include
- #include
- #include
- #include
- #include
- using namespace std;
- using namespace tinyxml2;
- class FemXmlParser
- {
- public:
- FemXmlParser(const char* xmlFile)
- :xml_file(xmlFile) {
- }
- void parse() {
- XMLDocument doc;
- if (doc.LoadFile(xml_file) != XML_SUCCESS) {
- std::cerr << "Failed to load file: " << xml_file << std::endl;
- return;
- }
- XMLElement* febio = doc.FirstChildElement("febio_spec");
- if (!febio) {
- std::cerr << "No
element in XML file." << std::endl; - return;
- }
- XMLElement* module = febio->FirstChildElement("Module");
- if (module) {
- const char* type = module->Attribute("type");
- std::cout << "Module Type: " << (type ? type : "Unknown") << std::endl;
- }
- XMLElement* geometry = febio->FirstChildElement("Mesh");
- if (geometry) {
- XMLElement* nodesElement = geometry->FirstChildElement("Nodes");
- if (nodesElement) ParseNodes(nodesElement);
- XMLElement* elementsElement = geometry->FirstChildElement("Elements");
- if (elementsElement) ParseElements(elementsElement);
- }
- XMLElement* materialsElement = febio->FirstChildElement("Material");
- if (materialsElement) ParseMaterials(materialsElement);
- XMLElement* controlElement = febio->FirstChildElement("Control");
- if (controlElement) ParseControl(controlElement);
- }
- void printSumaryInfo()
- {
- std::cout << "Nodes: total " <
- std::cout << "Elements: total " << elements.size()<< std::endl;
- std::cout << "Materials:" << std::endl;
- for (const Material& material : materials) {
- std::cout << "ID: " << material.id << ", Type: " << material.type << std::endl;
- }
- std::cout << "Control:" << std::endl;
- std::cout << "Analysis Type: " << control.analysis << std::endl;
- }
- void printDetailInfo()
- {
- // 测试输出,确保数据正确存储在容器中
- std::cout << "Nodes:" << std::endl;
- for (const Node& node : nodes) {
- std::cout << "ID: " << node.id << ", Position: (" << node.x << ", " << node.y << ", " << node.z << ")" << std::endl;
- }
- std::cout << "Elements:" << std::endl;
- for (const Element& element : elements) {
- std::cout << "ID: " << element.id << ", Node IDs: ";
- for (int nodeId : element.nodeIds) {
- std::cout << nodeId << " ";
- }
- std::cout << std::endl;
- }
- std::cout << "Materials:" << std::endl;
- for (const Material& material : materials) {
- std::cout << "ID: " << material.id << ", Type: " << material.type << std::endl;
- }
- std::cout << "Control:" << std::endl;
- std::cout << "Analysis Type: " << control.analysis << std::endl;
- }
- private:
- struct Node {
- int id;
- double x, y, z;
- };
- struct Element {
- int id;
- std::vector<int> nodeIds;
- };
- struct Material {
- int id;
- std::string type;
- };
- struct Control {
- std::string analysis;
- };
- vector<int> splitStringToInts(const string& str, char delimiter) {
- vector<int> result;
- size_t start = 0;
- size_t end = str.find(delimiter);
- while (end != string::npos) {
- result.push_back(stoi(str.substr(start, end - start)));
- start = end + 1;
- end = str.find(delimiter, start);
- }
- result.push_back(stoi(str.substr(start, end - start)));
- return result;
- }
- vector<double> splitStringToDoubles(const string& str, char delimiter) {
- vector<double> result;
- stringstream ss(str);
- string item;
- while (getline(ss, item, delimiter)) {
- result.push_back(stod(item));
- }
- return result;
- }
- void ParseNodes(XMLElement* nodesElement) {
- for (XMLElement* node = nodesElement->FirstChildElement("node"); node != nullptr; node = node->NextSiblingElement("node")) {
- Node n;
- node->QueryIntAttribute("id", &n.id);
- const char* nodeText = node->GetText();
- if (nodeText) {
- vector<double> ns = splitStringToDoubles(nodeText, ',');
- n.x = ns[0];
- n.y = ns[1];
- n.z = ns[2];
- }
- nodes.push_back(n);
- }
- }
- void ParseElements(XMLElement* elementsElement) {
- for (XMLElement* element = elementsElement->FirstChildElement("elem"); element != nullptr; element = element->NextSiblingElement("elem")) {
- Element e;
- element->QueryIntAttribute("id", &e.id);
- const char* elemText = element->GetText();
- if (elemText) {
- e.nodeIds = splitStringToInts(elemText, ',');
- }
- elements.push_back(e);
- }
- }
- void ParseMaterials(XMLElement* materialsElement) {
- for (XMLElement* material = materialsElement->FirstChildElement("material"); material != nullptr; material = material->NextSiblingElement("material")) {
- Material m;
- material->QueryIntAttribute("id", &m.id);
- m.type = material->Attribute("type");
- materials.push_back(m);
- }
- }
- void ParseControl(XMLElement* controlElement) {
- XMLElement* ctrl = controlElement->FirstChildElement("analysis");
- control.analysis = ctrl->GetText();
- }
- private:
- const char* xml_file;
- std::vector
nodes; - std::vector
elements; - std::vector
materials; - Control control;
- };
- class Timer {
- public:
- Timer() : start_time_point(std::chrono::high_resolution_clock::now()) {}
- void reset() {
- start_time_point = std::chrono::high_resolution_clock::now();
- }
- double elapsed() const {
- return std::chrono::duration_cast
- std::chrono::high_resolution_clock::now() - start_time_point
- ).count() / 1000.0; // 返回毫秒
- }
- void report()
- {
- double elapsed_time = elapsed();
- std::cout << "Elapsed time: " << elapsed_time << " ms" << std::endl;
- }
- private:
- std::chrono::high_resolution_clock::time_point start_time_point;
- };
- int main()
- {
- Timer time;
- FemXmlParser parser("../big_file.xml");
- parser.parse();
- time.report();
- parser.printSumaryInfo();
- return 1;
- }
-
相关阅读:
【JAVA】Servlet
RCE极限挑战
JAVA-分页查询
不了解无线调制方式?这几个“老古董”大家现在还在用!
QtCreator配置代码字体和颜色
【iptables 实战】05 iptables设置网络转发实验
P08 DQL
76. 最小覆盖子串
水果库存系统(SSM+Thymeleaf版)
VulnHub Earth
- 原文地址:https://blog.csdn.net/leizhengshenglzs/article/details/139455605