-
160. 相交链表
问题描述
给定两个单链表的头节点
headA和headB,找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,则返回null。注意:
- 返回结果后,链表必须保持其原始结构。
提示
listA中节点数目为mlistB中节点数目为n- 1 <= m, n <= 30,000
- 1 <= Node.val <= 100,000
- 0 <= skipA <= m
- 0 <= skipB <= n
- 如果
listA和listB没有交点,intersectVal为 0 - 如果
listA和listB有交点,intersectVal == listA[skipA] == listB[skipB]
进阶
设计一个时间复杂度为
O(m + n)且仅用O(1)内存的解决方案。代码
/** * Definition for singly-linked list. * struct ListNode { * int val; * struct ListNode *next; * }; */ #includestruct ListNode { int val; struct ListNode *next; }; struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) { struct ListNode* dummyA = headA; struct ListNode* dummyB = headB; while (dummyA != NULL) { while (dummyB != NULL) { if(dummyA == dummyB) { return dummyB; } if(dummyB->next != NULL) { dummyB = dummyB->next; } else { dummyB = headB; break; } } if(dummyA->next != NULL) { dummyA = dummyA->next; } else { dummyA = NULL; } } return NULL; } 代码思路分析
该代码试图通过嵌套循环遍历两个链表,找到它们的相交节点。如果找到了相交节点,则返回该节点;如果没有找到,则返回
NULL。分块拆解分析
定义结构和初始化
#includestruct ListNode { int val; struct ListNode *next; }; - 定义了一个单链表节点的结构体
ListNode,包含一个整数值val和一个指向下一个节点的指针next。
核心函数
getIntersectionNodestruct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) { struct ListNode* dummyA = headA; struct ListNode* dummyB = headB;- 初始化两个指针
dummyA和dummyB,分别指向链表headA和headB的头节点。
外层循环遍历
dummyAwhile (dummyA != NULL) {- 遍历链表
headA,直到dummyA变为NULL。
内层循环遍历
dummyBwhile (dummyB != NULL) {- 遍历链表
headB,直到dummyB变为NULL。
检查相交节点
if(dummyA == dummyB) { return dummyB; }- 如果
dummyA和dummyB指向同一个节点,则返回该节点,即找到了相交点。
移动
dummyB指针if(dummyB->next != NULL) { dummyB = dummyB->next; } else { dummyB = headB; break; }- 如果
dummyB的下一个节点不为NULL,则移动到下一个节点。 - 如果
dummyB的下一个节点为NULL,则重置dummyB指针为headB,并跳出内层循环。
移动
dummyA指针if(dummyA->next != NULL) { dummyA = dummyA->next; } else { dummyA = NULL; } } return NULL; }- 如果
dummyA的下一个节点不为NULL,则移动到下一个节点。 - 如果
dummyA的下一个节点为NULL,则将dummyA置为NULL,结束外层循环。 - 如果两个链表没有相交节点,则返回
NULL。
复杂度分析
时间复杂度
- 最坏情况下,外层循环遍历
headA的每个节点,内层循环遍历headB的每个节点。因此时间复杂度为O(m * n),其中m和n分别是链表headA和headB的长度。
空间复杂度
- 该算法只使用了常数级的额外空间,因此空间复杂度为
O(1)。
改进
上述代码的时间复杂度较高,可以通过双指针法优化,将时间复杂度降低到
O(m + n)。具体思路是:- 初始化两个指针
pA和pB,分别指向headA和headB。 - 遍历两个链表,当
pA到达末尾时,重置为headB;当pB到达末尾时,重置为headA。 - 两个指针最终会相遇于相交节点,或同时到达链表末尾(无相交节点)。
优化后的代码实现
struct ListNode *getIntersectionNode(struct ListNode *headA, struct ListNode *headB) { if (headA == NULL || headB == NULL) { return NULL; } struct ListNode *pA = headA; struct ListNode *pB = headB; while (pA != pB) { pA = (pA == NULL) ? headB : pA->next; pB = (pB == NULL) ? headA : pB->next; } return pA; }会相交的原因
双指针法能够找到链表相交的节点,尽管两个链表的前置节点步长不一样,这是由于指针在遍历完一个链表后切换到另一个链表,从而消除了长度差异,使两个指针最终同步到达相交节点。以下是详细解释:
详细解释
假设链表
headA的长度为m,链表headB的长度为n。为了简化说明,假设headA和headB在节点C相交。- 链表
headA:A1 -> A2 -> ... -> Am -> C -> ... - 链表
headB:B1 -> B2 -> ... -> Bn -> C -> ...
如果
m和n不相等,那么指针pA和pB在初始遍历时到达末尾的时间不同。但通过交替切换遍历,两个指针在相同的时间步到达相交节点。下面是具体过程:- 初始化两个指针
pA和pB,分别指向headA和headB。 - 让两个指针分别遍历各自的链表。
- 当指针到达链表末尾时,切换到另一个链表的头部继续遍历。
- 最终,两个指针会在相交节点相遇,或者同时到达链表末尾(无相交节点)。
双指针遍历过程
pA的轨迹
pA从headA开始,走m + 1 + c_to_end步到达末尾,然后切换到headB。pA继续遍历headB,走n步到达C。
pB的轨迹
pB从headB开始,走n + 1 + c_to_end步到达末尾,然后切换到headA。pB继续遍历headA,走m步到达C。
由于
pA和pB走的总步数相等(都是m + n + 1 + c_to_end步),如果m == n,则在第一次遍历的时候就会相遇在C的位置,否则在遍历完两个链表的节点后,两个指针会相遇于相交节点C,或者同时到达链表末尾(无相交节点)。时间复杂度和空间复杂度
- 时间复杂度:
O(m + n),因为每个指针最多遍历两个链表的总长度。 - 空间复杂度:
O(1),只使用了常数级的额外空间。
这种方法通过交替遍历链表,实现了在相同的时间步内找到两个链表的相交节点或确认无相交节点,避免了嵌套循环的高时间复杂度。
结果
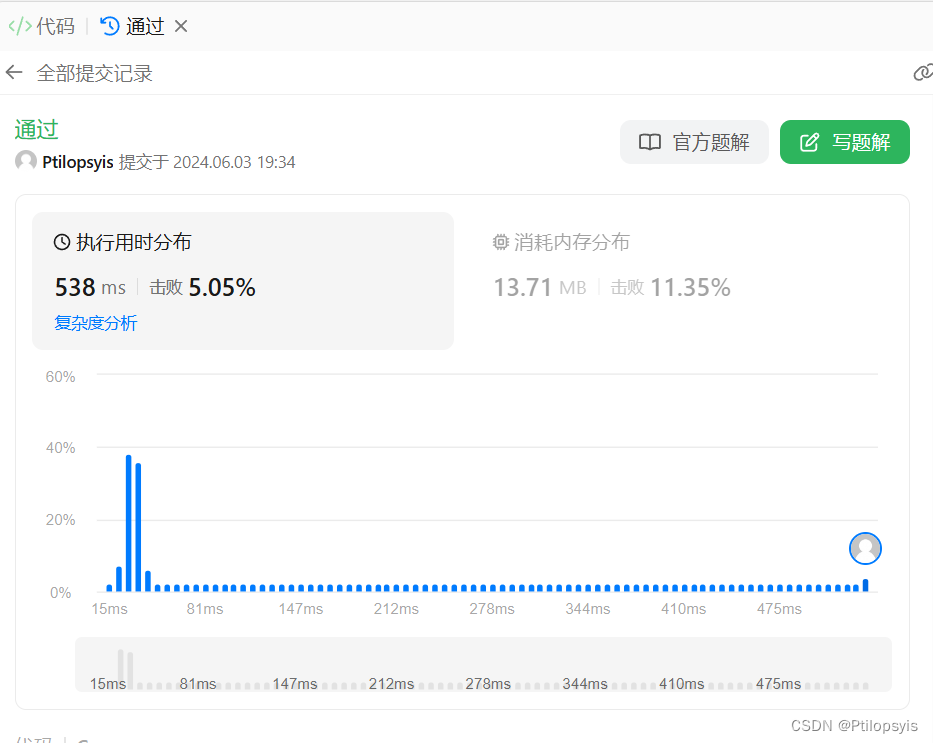
源代码结果如下:
优化后结果如下: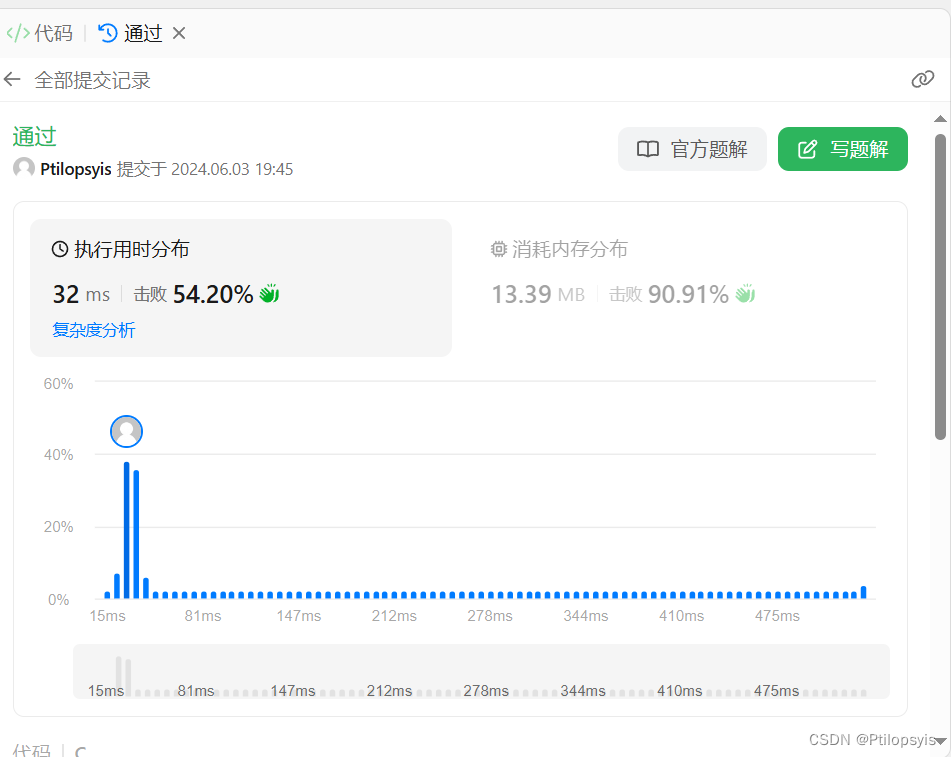
-
相关阅读:
使用ChatGLMTokenizer处理json格式数据
雨云 宿迁 14900KF 高防云服务器性能测评
软件版本号详解
[从零开始学习FPGA编程-47]:视野篇 - 第三代半导体技术现状与发展趋势
文件(夹)批量重命名数字、字母、日期、中文数字大写小写
《HelloGitHub》第 77 期
VSCode-常用快捷键
GBase 8s RTSync服务端口介绍(一)
信息学奥赛一本通(c++):1407:笨小猴
导数求函数的单调性与极值
- 原文地址:https://blog.csdn.net/qq_35085273/article/details/139422963