前言:说到爬虫,基本上清一色的都知道用Python,但是对于一些没玩过或者不想玩Python的来说,却比较头大一点。所以以下我站在C# 的角度,来写一个简单的Demo,用来演示C# 实现的简单小爬虫。大家感兴趣可以自己拓展出更加丰富的爬虫功能。
前提:引用包HtmlAgilityPack
先来个爬取文本。
新建一个文本处理的方法,用于处理爬取的文本数据,并写入到指定文件夹内的text.txt文件内
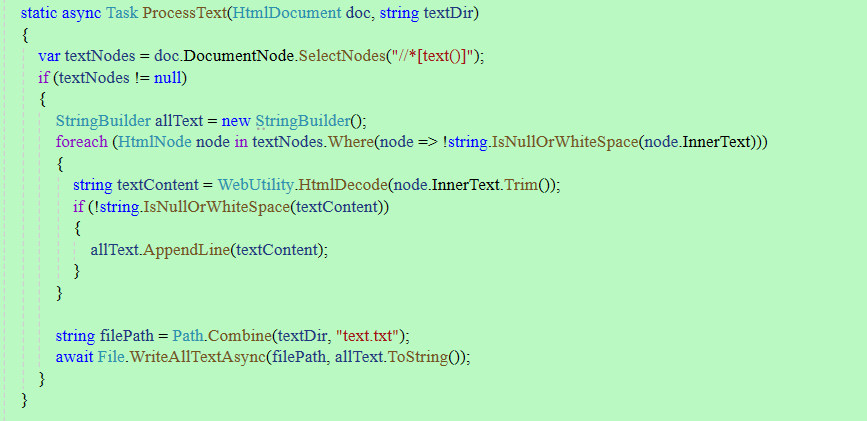

static async Task ProcessText(HtmlDocument doc, string textDir)
{
var textNodes = doc.DocumentNode.SelectNodes("//*[text()]");
if (textNodes != null)
{
StringBuilder allText = new StringBuilder();
foreach (HtmlNode node in textNodes.Where(node => !string.IsNullOrWhiteSpace(node.InnerText)))
{
string textContent = WebUtility.HtmlDecode(node.InnerText.Trim());
if (!string.IsNullOrWhiteSpace(textContent))
{
allText.AppendLine(textContent);
}
}
string filePath = Path.Combine(textDir, "text.txt");
await File.WriteAllTextAsync(filePath, allText.ToString());
}
}
新增一个网页处理方法,用于传入网址进行抓取网页数据,并传给以上的文本处理方法进行解析文本数据,保存到当前根目录下的Texts文件夹内

以我两天前写的博客内容为例,进行抓取。博客地址为:https://www.cnblogs.com/weskynet/p/18213135
Main里面调用有关方法,进行爬取。
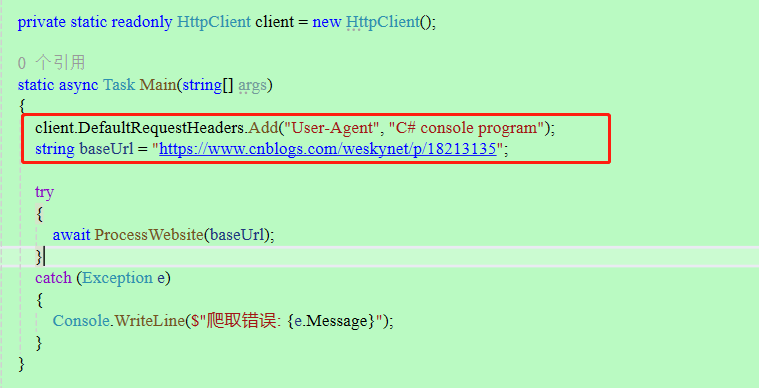
说明:添加 User-Agent 头部信息可以帮助模拟常规的浏览器请求,避免被目标服务器拒绝。
看下我当前的根目录:
运行完毕,多出Texts文件夹
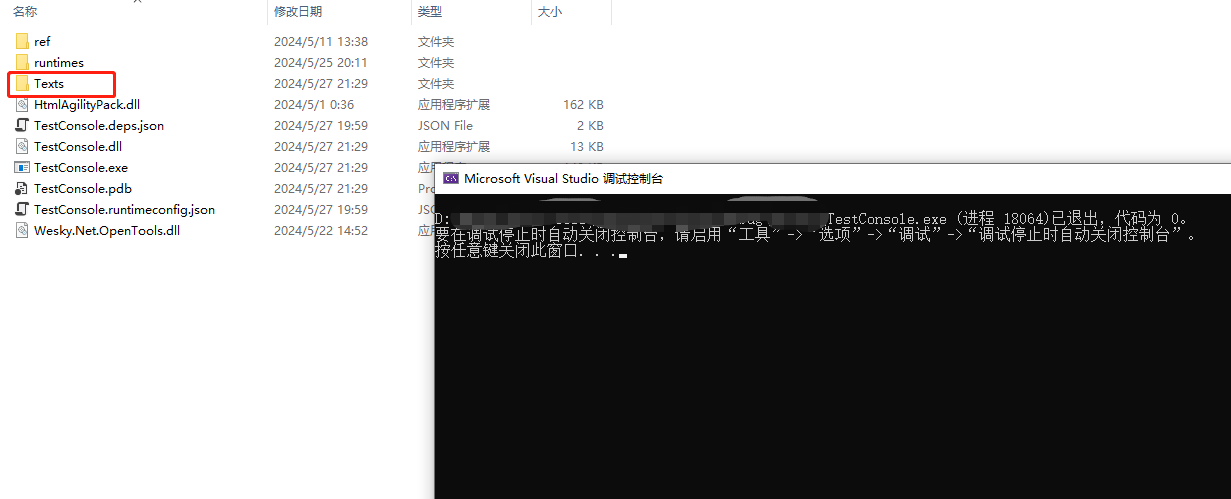
文件夹内多出程序里面写定的text.txt文件
打开文本文件,可以看到文章全部内容,以及所有文本都被抓取下来了。

同文本处理,新增一个图片处理方法:
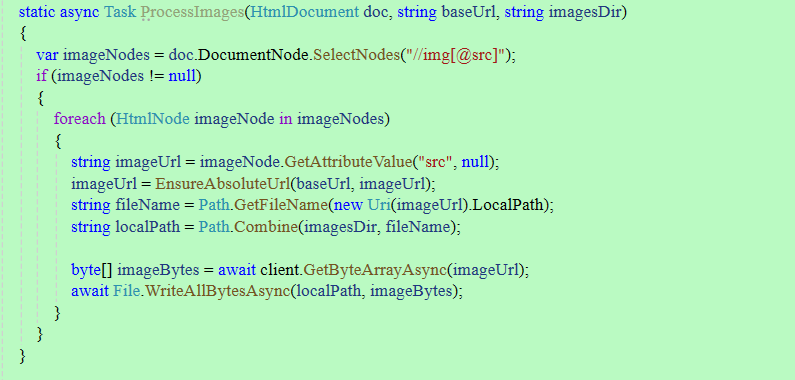
static async Task ProcessImages(HtmlDocument doc, string baseUrl, string imagesDir)
{
var imageNodes = doc.DocumentNode.SelectNodes("//img[@src]");
if (imageNodes != null)
{
foreach (HtmlNode imageNode in imageNodes)
{
string imageUrl = imageNode.GetAttributeValue("src", null);
imageUrl = EnsureAbsoluteUrl(baseUrl, imageUrl);
string fileName = Path.GetFileName(new Uri(imageUrl).LocalPath);
string localPath = Path.Combine(imagesDir, fileName);
byte[] imageBytes = await client.GetByteArrayAsync(imageUrl);
await File.WriteAllBytesAsync(localPath, imageBytes);
}
}
}
网页爬取方法里面把文本有关改成图片
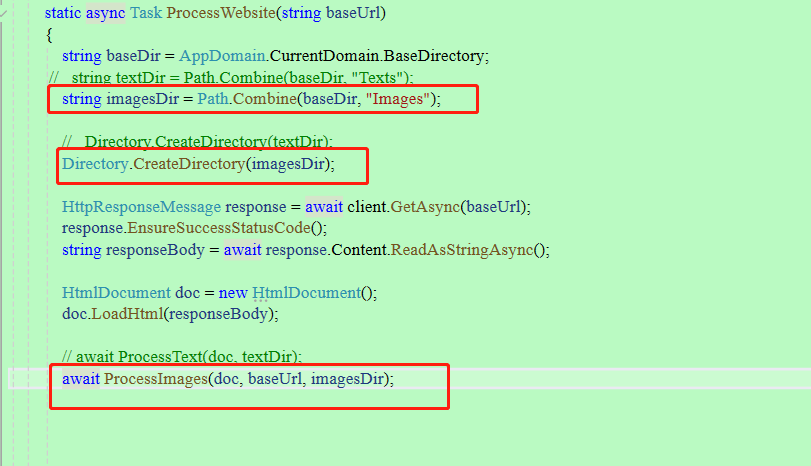
以下是一个辅助方法,辅助方法用于处理相对URL,确保所有请求的URL是绝对的,防止资源加载失败。
static string EnsureAbsoluteUrl(string baseUrl, string url) { return Uri.IsWellFormedUriString(url, UriKind.Absolute) ? url : new Uri(new Uri(baseUrl), url).AbsoluteUri; }
执行程序,执行完毕,根目录下新增Images文件夹
文件夹内会看到该网址的所有图片文件。
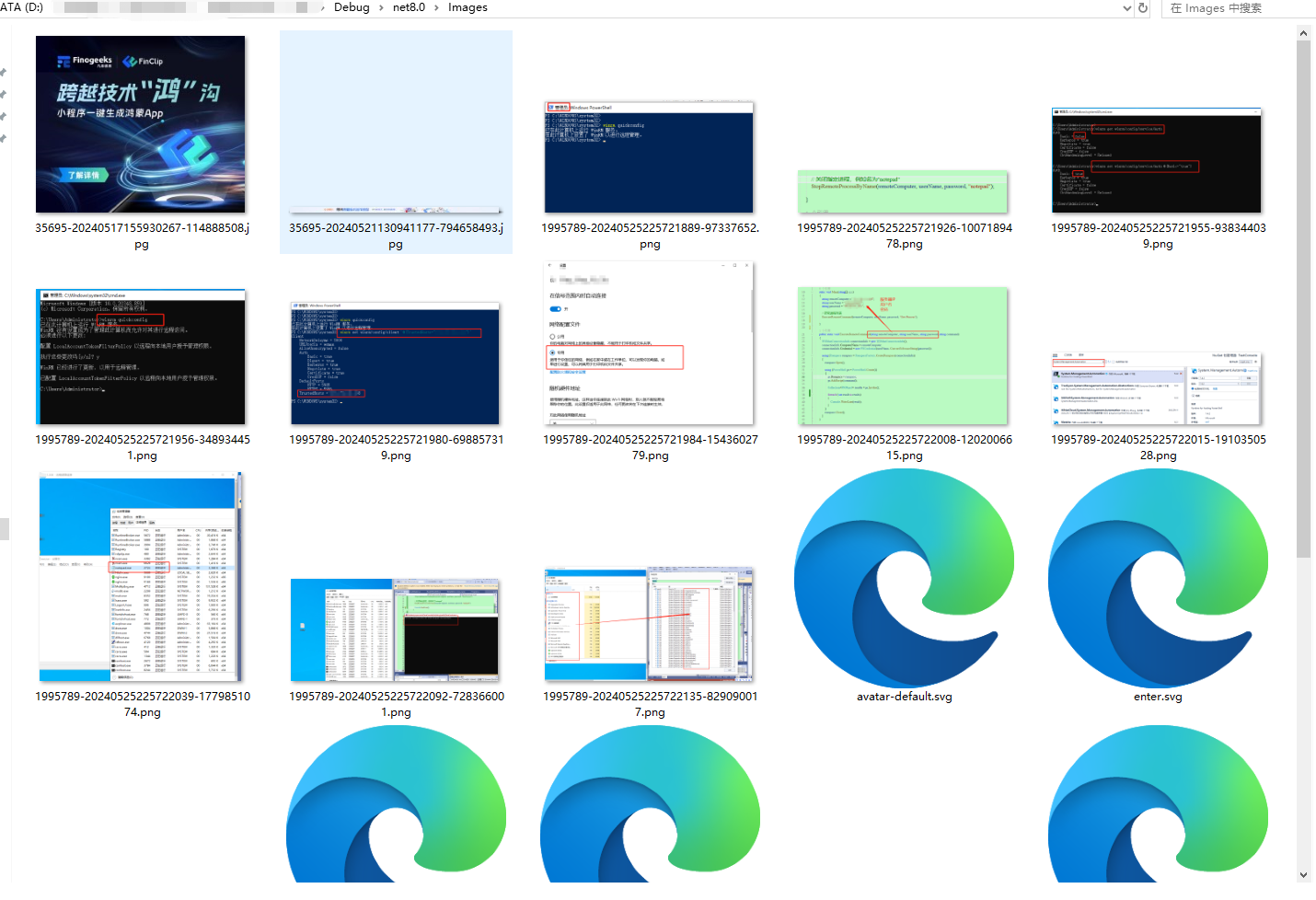
图片文件格式都会被抓取,可以根据自己需要进行过滤。如果是整个站点,可以根据循环进行获取每个页面的数据。
最后再提供一个视频爬取的代码,由于没找到可以爬取的站点,此处演示就不演示了,仅供代码出来给大家学习和技术分享使用。感兴趣的大佬可以自行尝试。
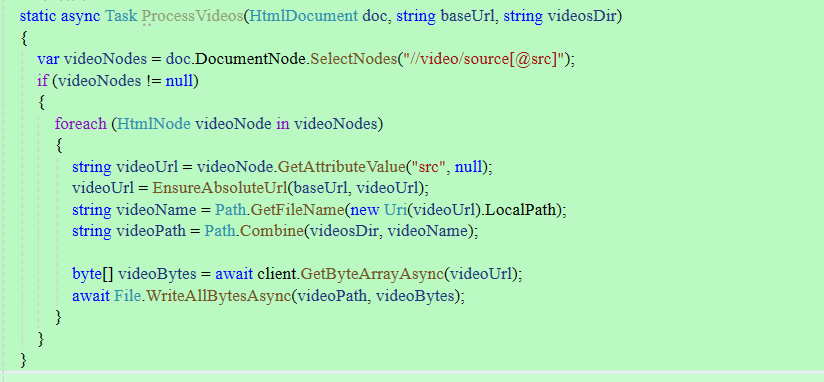
static async Task ProcessVideos(HtmlDocument doc, string baseUrl, string videosDir)
{
var videoNodes = doc.DocumentNode.SelectNodes("//video/source[@src]");
if (videoNodes != null)
{
foreach (HtmlNode videoNode in videoNodes)
{
string videoUrl = videoNode.GetAttributeValue("src", null);
videoUrl = EnsureAbsoluteUrl(baseUrl, videoUrl);
string videoName = Path.GetFileName(new Uri(videoUrl).LocalPath);
string videoPath = Path.Combine(videosDir, videoName);
byte[] videoBytes = await client.GetByteArrayAsync(videoUrl);
await File.WriteAllBytesAsync(videoPath, videoBytes);
}
}
}
如果大佬们想要直接获取我本地测试的源码demo,可以在我的公众号【Dotnet Dancer】后台回复:【爬虫】 即可获取我的本地demo源码自行调试和把玩。
最近园子时不时会图片全挂掉,如果图片没掉了,可以移步另一个地方围观:
https://mp.weixin.qq.com/s/NB2UWsfUdgNU82UVRbWe3Q
如果以上内容对你有帮助,欢迎关注我的公众号【Dotnet Dancer】,或点赞、推荐和分享。我会时不时更新一些其他C#或者其他技术文章。