-
Java——正则表达式
一.正则表达式
1.概述
正则表达式可以校验字符串是否满足一定的规则,并用来校验数据格式的合法性
我们可以把正则表达式理解为是一种规则,这种规则就是可以用来校验字符串
2.Pattern与Matcher
⑴概述
①Pattern类为正则表达式的编译表现形式
②Matcher类为Pattern对Character sequence(文本)执行匹配操作的引擎(文本匹配器)
⑵常见方法摘要
①Pattern类

②Matcher类

3.正则表达式的常用构造摘要
正则表达式其实就是字符拼凑出来的规则
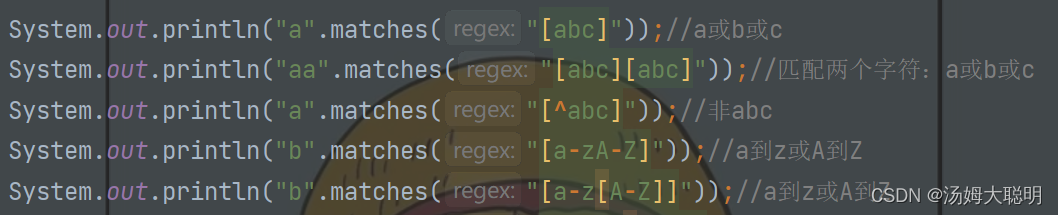
⑴字符类
其中表示对一个字符的匹配

⑵预定义字符
其中表示对一个字符的匹配

反斜线字符 ('\') 用于引用转义构造,同时还用于引用其他将被解释为非转义构造的字符。因此,表达式 \\ 与单个反斜线匹配,而 \{ 与左括号匹配
如图:若我要使用预定义字符,其中\\才表示上表的\

⑶数量词

4.正则表达式的作用
⑴校验字符串是否满足规则
字符串中定义了一个Matchers方法用来校验字符串是否满足给定的规则
boolean matches(String regex)
方法的底层就是调用的Pattern类中的marches方法
⑵在一段文本中查找满足要求的内容(爬取数据)
如何在一段文本中查找满足要求的内容?
第一步:写好规则(正则表达式)
第二步:获取文本匹配器
第三步:利用文本匹配器从头开始读取,将符合要求的内容截取
第四步:获取截取的内容
利用这四步思路,我们看一下如何利用代码实现
①本地爬取

如图:我想要获取下面文本的关键词"路飞",我们定义规则然后调用方法
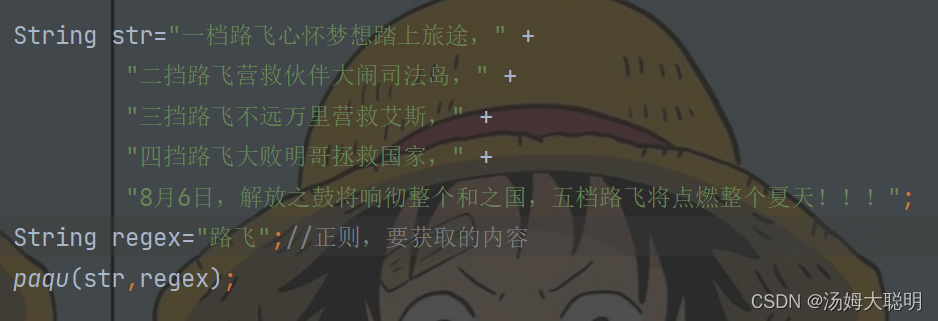
②网络爬取
网络爬取就是在本地爬取的基础上多了个读取网络内容的要求

5.正则表达式在字符串中的使用

replaceAll其中的regex是正则表达式,newStr是要替换的内容

6.爬虫
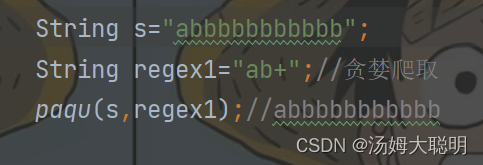
⑴贪婪爬取
在爬取的时候尽可能的多获取数据
Java中默认的是贪婪爬取,数量词+或*就表示贪婪爬取
如图:我想要尽可能的多获取b
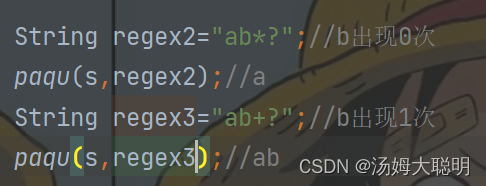
⑵非贪婪爬取
在爬取的时候尽可能的少获取数据
在Java中默认的是贪婪爬取,如果我们在数量词+或*的后面加上问号,就表示非贪婪爬取
⑶带条件的爬取
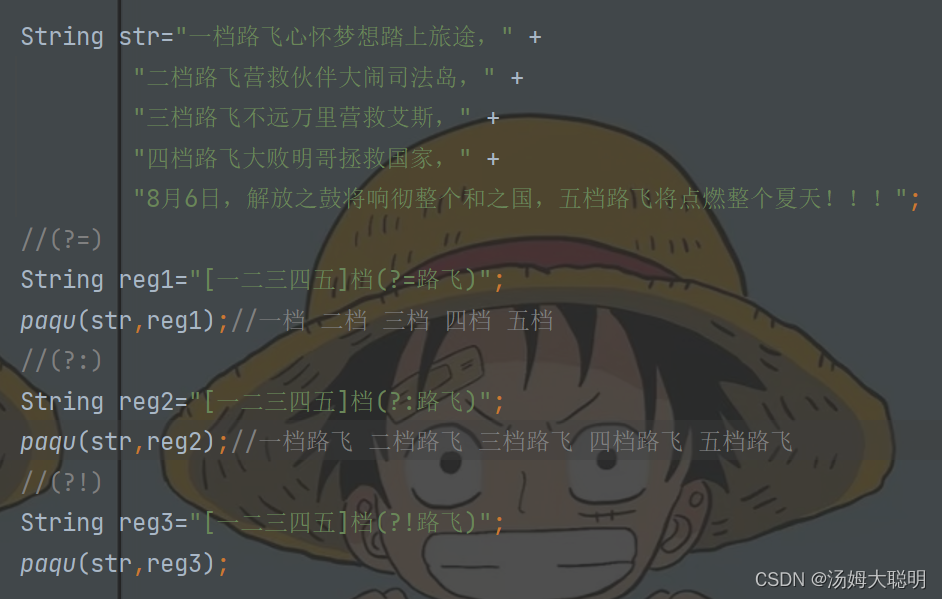
带条件的爬取就是我们可以一次性爬取到不同的内容
如:一段文本中包含"a1","a2","a3"等等关键词,我想要统计其中aX出现的个数,就可以定义正则
a(?:1|2|3)

7.组和捕获
⑴捕获分组
捕获分组就是把这一组的数据捕获出来,再用一次
Ⅰ.规则
捕获组可以通过从左到右计算其开括号来编号
规则1:从1开始连续不间断
规则2:以左括号为基准,最左边的是第一组,其次是第二组,以此类推
Ⅱ.组的使用
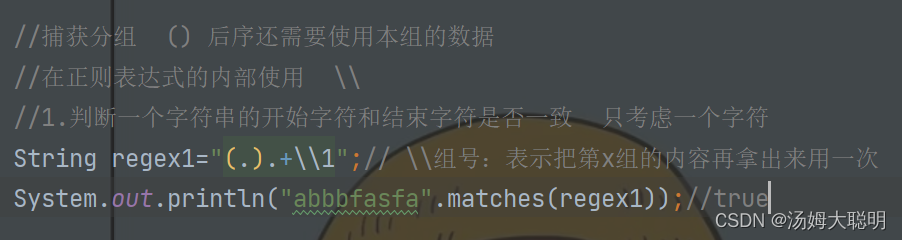
正则内部使用:\\组号
如图:我要判断一个字符串的开始字符与结束字符是否一致
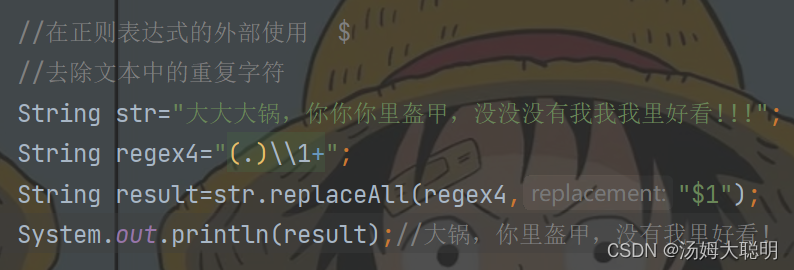
正则外部使用:$组号
如图:我要去除文本中的重复字符
⑵非捕获分组
分组之后不需要再使用本组数据,仅仅是把数据括起来
以(?)开头的组是纯的非捕获分组,也就是我们不能再去调用该正则表达式
上面的(?:) ,(?!)以及(?=)均是非捕获分组
-
相关阅读:
Tmux 简单使用
【微信小程序】携带参数跳转,参数中 = 部分参数丢失?数据传输过程中丢失/不全,遇 ‘=‘ 和 ‘?‘ 被截取
信息系统项目管理师---第十一章项目风险管理
PE文件(十一)移动导出表和重定位表
一、了解[mysql]索引底层结构和算法
足球大数据预测胜平负、走地之人工智能算法现状与改进措施
【数据结构与算法】之深入解析“恢复数组”的求解思路与算法示例
php怎么检测字符串是否只含数字
会员中心通过AJAX、JSON、PHP、MySql等技术实现注册和登录功能(1+X Web前端开发中级 例题)——初稿
C++基础从0到1入门编程(三)
- 原文地址:https://blog.csdn.net/m0_74808313/article/details/132168949