-
Scala基础
目录
1.安装与运行Scala
任务描述
Scala是Spark编程常用的语言之一,本书进行Spark编程时使用的语言也是Scala。因此,在学习Spark之前,需要先了解Scala语言、Scala安装过程和基础编程操作。
本节的任务如下。
了解Scala语言及其特性并安装Scala,为后续Scala程序提供运行环境。
了解Scala语言
1.Scala是Scalable Language的缩写,是一种多范式的编程语言,由洛桑联邦理工学院的马丁·奥德斯在2001年基于Funnel的工作开始设计,设计初衷是想集成面向对象编程和函数式编程的各种特性
2.Scala 是一种纯粹的面向对象的语言,每个值都是对象。Scala也是一种函数式语言,因此函数可以当成值使用。由于Scala整合了面向对象编程和函数式编程的特性,因此Scala相对于Java、C#、C++等其他语言更加简洁。
3.Scala源代码会被编译成Java字节码,因此Scala可以运行于Java虚拟机(Java Virtual Machine,JVM)之上,并可以调用现有的Java类库。
了解Scala特性
面向对象,函数式编程,静态类型,可扩展
安装Scala
1. 在网页上运行Scala
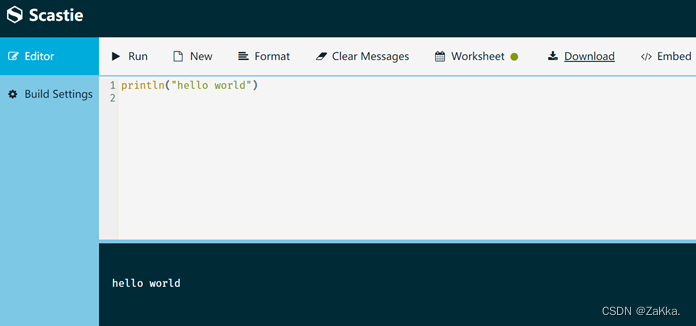
(1)通过浏览器查找Scastie并进入,即可进入Scala在线运行环境。
(2)进入Scastie界面后,在上窗格中输入“println("hello world")”。
(3)单击“Run”按钮,输出信息将显示在下窗格中,如下图。
2.Scala环境设置
(1)Scala运行环境众多,可以运行在Windows、Linux、macOS等系统上。Scala是运行在JVM上的语言,因此必须确保系统环境中安装了JDK,即Java开发工具包,而且必须确保JDK版本与本书安装的Spark的JDK编译版本一致,本书中使用的JDK是JDK 8(Java 1.8)。
(2)查看Java版本

3.Scala安装
(1)在Linux和macOS系统上安装Scala
从Scala官网下载Scala安装包,安装包名称为“scala-2.12.15.tgz”
将其上传至/opt目录
解压安装包至/usr/local目录下
配置Scala环境变量
(2)在Windows系统上安装Scala
从Scala官网下载Scala安装包,安装包名称为“scala.msi”。
双击scala.msi安装包,开始安装软件。
进入欢迎界面,单击右下角的“Next”按钮后出现许可协议选择提示框,选择接受许可协议中的条款并单击右下角的“Next”按钮。
选择安装路径,本文Scala的安装路径选择在非系统盘的“D:\Program Files (x86)\spark\scala\” ,单击“OK”按钮进入安装界面。
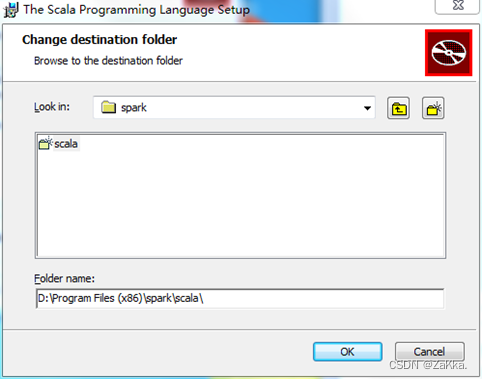
在安装界面中单击右下角的“Install”按钮进行安装,安装完成时单击“Finish”按钮完成安装。
右键单击“此电脑”图标,选择“属性”选项,在弹出的窗口中选择“高级系统设置”选项。在弹出的对话框中选择“高级”选项卡,并单击“环境变量”按钮,在环境变量对话框中,选择“Path”变量并单击“编辑”按钮,在Path变量中添加Scala安装目录的bin文件夹所在路径,如“D:\Program Files (x86)\spark\scala\bin”。
运行Scala
Scala解释器也称为REPL(Read-Evaluate-Print-Loop,读取-执行-输出-循环)。
在命令行中输入“scala”,即可进入REPL,如下图。
 REPL是一个交互式界面,用户输入命令时,可立即产生交互反馈。
REPL是一个交互式界面,用户输入命令时,可立即产生交互反馈。输入“:quit”命令即可退出REPL,如下图。

图2是一个Scala类,该类实现了两个数相加的方法。。
如果要使用该方法,那么需要通过import加载该方法,如图1,其中,add是类名,addInt是方法名。
图1:
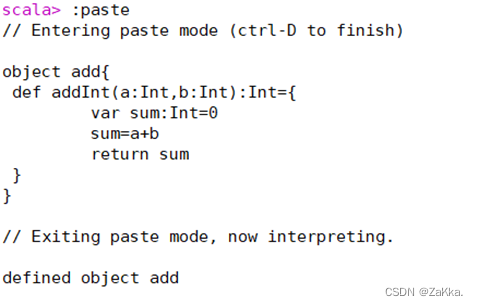
图2:
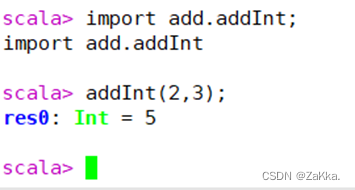
2.定义函数识别号码类型
任务描述
中国移动、中国联通和中国电信这3种类型的手机号码都有特定的手机号码段。
•中国移动的手机号码段有1340~1348、135~139、150~152、157~159、182~184、187、188、178、147、1705等;
•中国联通的手机号码段有130~132、155、156、185、186、176、145、1709等;
•中国电信的手机号码段有133、1349、153、180、181、189、1700、177等。
本节的任务如下。
•使用数组分别存储不同类型的手机号码段,并编写函数用于识别某个手机号码段的类型。
了解数据类型
了解Scala常用数据类型
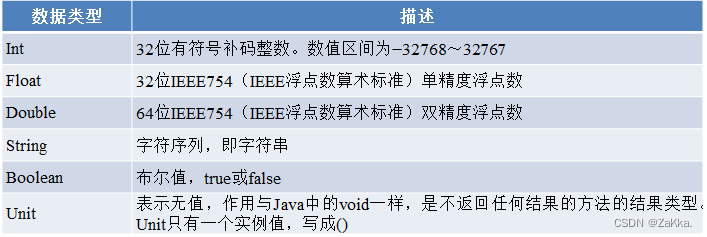 Scala会区分不同类型的值,并且会基于使用值的方式确定最终结果的数据类型,这称为类型推断。
Scala会区分不同类型的值,并且会基于使用值的方式确定最终结果的数据类型,这称为类型推断。Scala使用类型推断可以确定混合使用数据类型时最终结果的数据类型。
如在加法中混用Int和Double类型时,Scala将确定最终结果为Double类型,如下图。

定义与使用常量、变量
常量
在程序运行过程中值不会发生变化的量为常量或值,常量通过val关键字定义,常量一旦定义就不可更改,即不能对常量进行重新计算或重新赋值。定义一个常量的语法格式如下。
val name: type = initialization
变量
变量是在程序运行过程中值可能发生改变的量。变量使用关键字var定义。与常量不同的是,变量定义之后可以重新被赋值。定义一个变量的语法格式如下。
var name: type = initialization
使用运算符
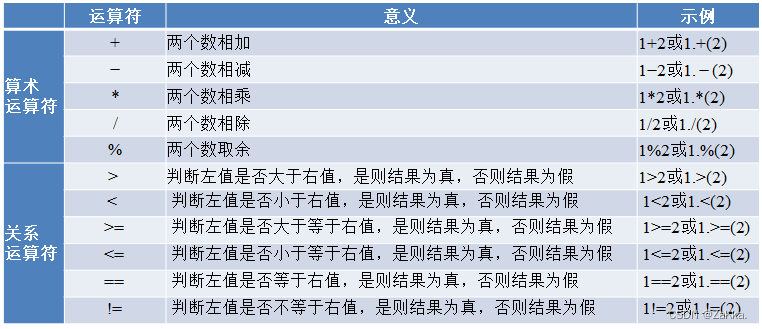
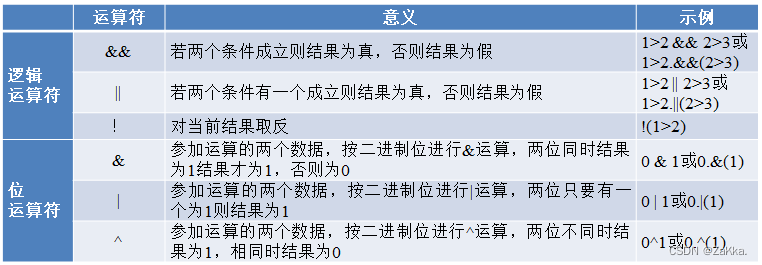
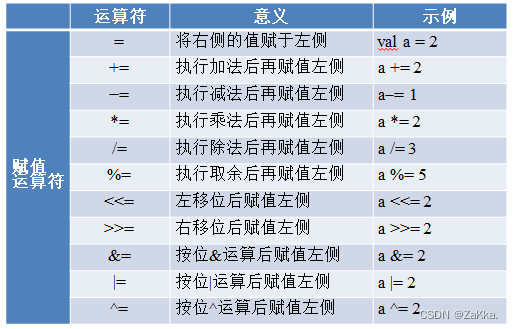
定义与使用数组
数组是Scala中常用的一种数据结构,数组是一种存储了相同类型元素的固定大小的顺序集合。
Scala定义一个数组的语法格式如下。
# 第1种方式
var arr: Array[String] = new Array[String](num)
# 第2种方式
var arr:Array[String] = Array(元素1,元素2,…)
数组常用的方法
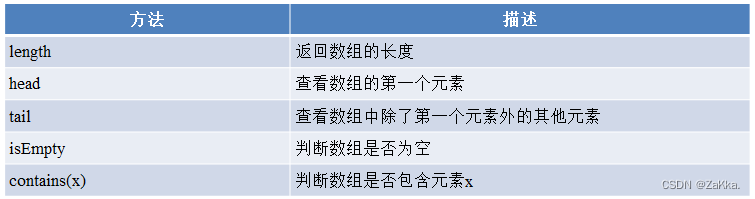 数组的使用
数组的使用 Scala可以使用range()方法创建区间数组。
Scala可以使用range()方法创建区间数组。使用range()方法前同样需要先通过命令“import Array._”导入包。
函数是Scala的重要组成部分,Scala作为支持函数式编程的语言,可以将函数作为对象.
定义函数的语法格式如下。
def functionName(参数列表): [return type] = {}
Scala提供了多种不同的函数调用方式,以下是调用函数的标准格式。
functionName(参数列表)
如果函数定义在一个类中,那么可以通过“类名.方法名(参数列表)”的方式调用。
1.匿名函数
匿名函数即在定义函数时不给出函数名的函数。
Scala中匿名函数是使用箭头“=>”定义的,箭头的左边是参数列表,箭头的右边是表达式,表达式将产生函数的结果。
通常可以将匿名函数赋值给一个常量或变量,再通过常量名或变量名调用该函数。
若函数中的每个参数在函数中最多只出现一次,则可以使用占位符“_”代替参数。
2.高阶函数—函数作为参数
高阶函数指的是操作其他函数的函数。
高阶函数可以将函数作为参数,也可以将函数作为返回值。
高阶函数经常将只需要执行一次的函数定义为匿名函数并作为参数。一般情况下,匿名函数的定义是“参数列表=>表达式”。
由于匿名参数具有参数推断的特性,即推断参数的数据类型,或根据表达式的计算结果推断返回结果的数据类型,因此定义高阶函数并使用匿名函数作为参数时,可以简化匿名函数的写法。
3.高阶函数—函数作为返回值
高阶函数可以产生新的函数,并将新的函数作为返回值。
定义高阶函数计算矩形的周长,该函数传入一个Double类型的值作为参数,返回以一个Double类型的值作为参数的函数,如下图。

4.函数柯里化
函数柯里化是指将接收多个参数的函数变换成接收单一参数(最初函数的第一个参数)的函数,新的函数返回一个以原函数余下的参数为参数的函数。
定义两个整数相加的函数,一般函数的写法及其调用方式如下图。

使用函数柯里化

任务实现
实现手机号码类型识别,首先用数组存储各种类型的手机号码段,并编写一个函数识别手机号码类型。
•用数组分别存储各种类型的手机号码段。
•定义一个函数identify识别手机号码段,并使用该函数查询手机号码段为133的手机号码类型。

3.基本语法
1 变量
在scala中,可以使用
val或者var来定义变量,语法格式如下:- /** val定义:不可重新赋值的变量;var定义:可重新赋值的变量 */
- val/var 变量标识:变量类型 = 初始值
[!NOTE]:变量类型写在变量名后面,不需要添加分号,优先使用
val定义变量,如果变量需要被重新赋值,才使用var使用类型推断来定义变量
scala可以自动根据变量的值来自动推断变量的类型
- scala> val name = "tom"
- name: String = tom
惰性赋值
在大数据开发中,有时会编写非常复杂的SQL语句,如果直接加载到JVM中,会有很大的内存开销。如何解决?当有一些变量保存的数据较大时,但是不需要马上加载到JVM内存。可以使用惰性赋值来提高效率。语法格式:
lazy val/var 变量名 = 表达式2 字符串
scala提供多种定义字符串的方式,将来我们可以根据需要来选择最方便的定义方式。
使用双引号
val/var 变量名 = “字符串”使用插值表达式
scala中,可以使用插值表达式来定义字符串,有效避免大量字符串的拼接。
val/var 变量名 = s"${变量/表达式}字符串"注意:定义字符串之前添加
s;在字符串中,可以使用${}来引用变量或者编写表达式- scala> val name = "zhangsan"
- scala> val age = 30
- scala> val sex = "male"
- scala> val info = s"name=${name}, age=${age}, sex=${sex}"
- info: String = name=zhangsan, age=30, sex=male
使用三引号
如果有大段的文本需要保存,就可以使用三引号来定义字符串。例如:保存一大段的SQL语句。三个引号中间的所有字符串都将作为字符串的值。
- val/var 变量名 = """字符串1
- 字符串2"""
3 数据类型&操作符
scala中的类型以及操作符绝大多数和Java一样,以下总结与java不一样的用法:
数据类型
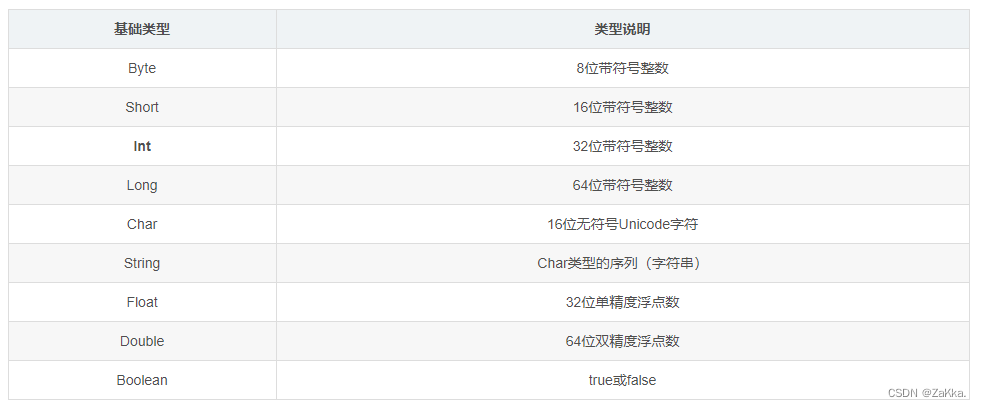
scala类型与Java的区别:
- scala中所有的类型都使用大写字母;
- 开头整形使用
Int而不是Integer; - scala中定义变量可以不写类型,让scala编译器自动推断;
运算符
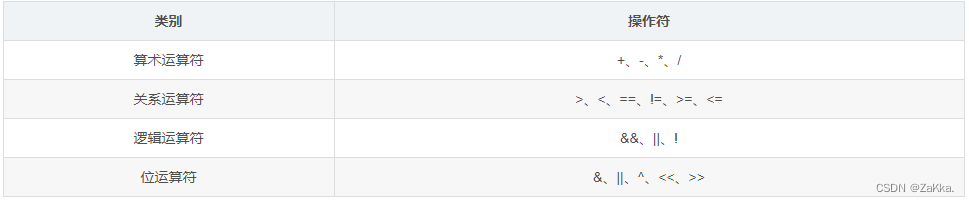
-
scala中没有,++、--运算符
-
与Java不一样,在scala中,可以直接使用
==、!=进行比较,它们与equals方法表示一致。而比较两个对象的引用值,使用eq
- val str1 = "abc"
- val str2 = str1 + ""
- str1 == str2
- str1.eq(str2)
4 条件表达式
条件表达式就是if表达式,if表达式可以根据给定的条件是否满足,根据条件的结果(真或假)决定执行对应的操作。scala条件表达式的语法和Java一样。
有返回值的if
与Java不一样的是:1、条件表达式也是有返回值的;2、没有三元表达式,可以使用if表达式替代三元表达式
- scala> val sex = "male"
- sex: String = male
- scala> val result = if(sex == "male") 1 else 0
- result: Int = 1
块表达式
scala中,使用
{}表示一个块表达式,和if表达式一样,块表达式也是有值的,值就是最后一个表达式的值。- scala> val a = {
- | println("1 + 1")
- | 1 + 1
- }
5 循环
在scala中,可以使用for和while,但一般推荐使用for表达式,因为for表达式语法更简洁
- for(i <- 表达式/数组/集合) {
- // 表达式
- }
- scala> val nums = 1.to(10)
- nums: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
- scala> for(i <- nums) println(i)
- //简写方式:
- scala> for(i <- 1 to 10) println(i)
嵌套循环
for(i <- 1 to 3; j <- 1 to 5) {print("*");if(j == 5) println("")}for推导式
将来可以使用for推导式生成一个新的集合(一组数据),在for循环体中,可以使用
yield表达式构建出一个集合,把使用yield的for表达式称之为推导式.示例:生成一个10、20、30…100的集合
- // for推导式:for表达式中以yield开始,该for表达式会构建出一个集合
- val v = for(i <- 1 to 10) yield i * 10
5.2 while循环
scala中while循环和Java中是一致的
- scala> var i = 1
- scala> while(i <= 10) {
- | println(i)
- | i = i+1
- | }
6 break和continue
在scala中,类似Java和C++的break/continue关键字被移除了;如果一定要使用break/continue,就需要使用scala.util.control包的Break类的breable和break方法。
break用法
导入Breaks包import scala.util.control.Breaks._;使用breakable将for表达式包起来;for表达式中需要退出循环的地方,添加break()方法调用。示例如下:
- // 导入scala.util.control包下的Break
- import scala.util.control.Breaks._
- breakable{
- for(i <- 1 to 100) {
- if(i >= 50) break()
- else println(i)
- }
- }
continue用法
continue的实现与break类似,但有一点不同:
实现break是用breakable{}将整个for表达式包起来,而实现continue是用breakable{}将for表达式的循环体包含起来就可以了。示例如下:- // 导入scala.util.control包下的Break
- import scala.util.control.Breaks._
- for(i <- 1 to 100 ) {
- breakable{
- if(i % 10 == 0) break()
- else println(i)
- }
- }
7 方法
- def methodName (参数名:参数类型, 参数名:参数类型) : [return type] = {
- // 方法体:一系列的代码
- }
注意:参数列表的参数类型不能省略;返回值类型可以省略,由scala编译器自动推断;返回值可以不写return,默认就是
{}块表达式的值。- scala> def add(a:Int, b:Int) = a + b
- m1: (x: Int, y: Int)Int
- scala> add(1,2)
- res10: Int = 3
返回值类型推断
scala定义方法可以省略返回值,由scala自动推断返回值类型。这样方法定义后更加简洁。但是要注意:定义递归方法,不能省略返回值类型。示例如下:
- scala> def m2(x:Int) = {
- | if(x<=1) 1
- | else m2(x-1) * x
- | }
:13: error: recursive method m2 needs result type - else m2(x-1) * x
1.1 方法参数
scala中的方法参数,使用比较灵活。它支持以下几种类型的参数:
默认参数:在定义方法时可以给参数定义一个默认值。
- // x,y带有默认值为0
- def add(x:Int = 0, y:Int = 0) = x + y
- add()
带名参数:在调用方法时,可以指定参数的名称来进行调用。
- def add(x:Int = 0, y:Int = 0) = x + y
- add(x=1)
变长参数:如果方法的参数是不固定的,在参数类型后面加一个
*号,表示参数可以是0个或者多个。- def 方法名(参数名:参数类型*):返回值类型 = {
- 方法体
- }
- scala> def add(num:Int*) = num.sum
- add: (num: Int*)Int
- scala> add(1,2,3,4,5)
- res1: Int = 15
8 函数
scala支持函数式编程,函数定义不需要使用,无需指定返回值类型;
def定义语法如下:val 函数变量名 = (参数名:参数类型, 参数名:参数类型....) => 函数体- scala> val add = (x:Int, y:Int) => x + y
- add: (Int, Int) => Int =
- scala> add(1,2)
- res3: Int = 3
方法和函数的区别:
1.方法是隶属于类或者对象的,在运行时,它是加载到JVM的方法区中
2.可以将函数对象赋值给一个变量,在运行时,它是加载到JVM的堆内存中
3.函数是一个对象,继承自FunctionN,函数对象有apply,curried,toString,tupled这些方法。方法则没有9 数组
scala中数组的概念是和Java类似,可以用数组来存放一组数据。scala中,有两种数组,一种是定长数组,另一种是变长数组。
1.1 定长数组
定长数组指的是数组的长度是不允许改变的,数组的元素是可以改变的。语法如下:
- // 通过指定长度定义数组
- val/var 变量名 = new Array[元素类型](数组长度)
- // 用元素直接初始化数组
- val/var 变量名 = Array(元素1, 元素2, 元素3...)
注意:在scala中,数组的泛型使用
[]来指定,使用()来获取元素- scala> val a = new Array[Int](100)
- a: Array[Int] = Array(0, 0, 0, 0, 0, 0, 0, 0, 0, 0,...)
- scala> a(0) = 110
- scala> a(0)
- 110
1.2 变长数组
变长数组指的是数组的长度是可变的,可以往数组中添加、删除元素。
定义变长数组
创建变长数组,需要提前导入ArrayBuffer类import scala.collection.mutable.ArrayBuffer,语法:
创建空的ArrayBuffer变长数组:
val/var a = ArrayBuffer[元素类型]()val a = ArrayBuffer[Int]()创建带有初始元素的ArrayBuffer
val/var a = ArrayBuffer(元素1,元素2,元素3....)- scala> val a = ArrayBuffer("hadoop", "storm", "spark")
- a: scala.collection.mutable.ArrayBuffer[String] = ArrayBuffer(hadoop, storm, spark)
添加/修改/删除元素
- 使用
+=添加元素 - 使用
-=删除元素 - 使用
++=追加一个数组到变长数组
- // 定义变长数组
- scala> val a = ArrayBuffer("hadoop", "spark", "flink")
- a: scala.collection.mutable.ArrayBuffer[String] = ArrayBuffer(hadoop, spark, flink)
- // 追加一个元素
- scala> a += "flume"
- res10: a.type = ArrayBuffer(hadoop, spark, flink, flume)
- // 删除一个元素
- scala> a -= "hadoop"
- res11: a.type = ArrayBuffer(spark, flink, flume)
- // 追加一个数组
- scala> a ++= Array("hive", "sqoop")
- res12: a.type = ArrayBuffer(spark, flink, flume, hive, sqoop)
1.3 遍历数组
可以使用以下两种方式来遍历数组:
使用
for表达式直接遍历数组中的元素- scala> val a = Array(1,2,3,4,5)
- scala> for(i<-a) println(i)
使用
索引遍历数组中的元素- scala> val a = Array(1,2,3,4,5)
- scala> for(i <- 0 to a.length - 1) println(a(i))
- scala> for(i <- 0 until a.length) println(a(i))
1.4 数组常用操作
scala中的数组封装了一些常用的计算操作,在对数据处理的时候不需要再重新实现;以下为常用的几个算法:
求和:数组中的
sum方法可以将所有的元素进行累加,然后得到结果- scala> val a = Array(1,2,3,4)
- scala> a.sum
最大值:数组中的
max方法,可以获取到数组中的最大的那个元素值- scala> val a = Array(4,1,2,4,10)
- scala> a.max
最小值:数组的
min方法,可以获取到数组中最小的那个元素值- scala> val a = Array(4,1,2,4,10)
- scala> a.min
排序:
sorted方法,将数组进行升序排序;reverse方法,将数组进行反转,实现降序排序- scala> val a = Array(4,1,2,4,10)
- scala> a.sorted
- scala> a.sorted.reverse
10 元组
元组可以用来包含一组不同类型的值。例如:姓名,年龄,性别,出生年月。元组的元素是不可变的。语法定义:
使用括号来定义元组
val/var 元组 = (元素1, 元素2, 元素3....)使用箭头来定义元组(元组只有两个元素)
val/var 元组 = 元素1->元素2- scala> val a = ("zhangsan", 20)
- scala> val a = "zhangsan" -> 20
访问元组
使用_1、_2、_3…来访问元组中的元素,_1表示访问第一个元素,依次类推.
- scala> val a = "zhangsan" -> "male"
- scala> a._1
- scala> a._2
11List
列表是scala中最重要的、也是最常用的数据结构。List具备以下性质:可以保存重复的值,有先后顺序。在scala中,也有两种列表,一种是不可变列表、另一种是可变列表。
使用
ListBuffer[元素类型]()创建空的可变列表,语法结构:val/var 变量名 = ListBuffer[Int]()使用
ListBuffer(元素1, 元素2, 元素3...)创建可变列表,语法结构:val/var 变量名 = ListBuffer(元素1,元素2,元素3...)- /* 示例一:创建空的整形可变列表 */
- scala> val a = ListBuffer[Int]()
- /* 示例二:创建一个可变列表,包含以下元素:1,2,3,4 */
- scala> val a = ListBuffer(1,2,3,4)
判断列表是否为空
- scala> val a = List(1,2,3,4)
- scala> a.isEmpty
12 Set
Set(集)是代表没有重复元素的集合。Set具备两个性质:1. 元素不重复;2. 不保证插入顺序。scala中的集也分为两种,一种是不可变集,另一种是可变集。
创建一个空的不可变集,语法格式:
val/var 变量名 = Set[类型]()给定元素来创建一个不可变集,语法格式:
val/var 变量名 = Set(元素1, 元素2, 元素3...)- /* 示例一:定义一个空的不可变集 */
- scala> val a = Set[Int]()
- /* 示例二:定义一个不可变集,保存以下元素:1,1,3,2,4,8 */
- scala> val a = Set(1,1,3,2,4,8)
基本操作
- // 创建集
- scala> val a = Set(1,1,2,3,4,5)
- // 获取集的大小
- scala> a.size
- // 遍历集
- scala> for(i <- a) println(i)
- // 删除一个元素
- scala> a - 1
- // 拼接两个集
- scala> a ++ Set(6,7,8)
- // 拼接集和列表
- scala> a ++ List(6,7,8,9)
13 Map
Map可以称之为映射。它是由键值对组成的集合。在scala中,Map也分为不可变Map和可变Map。
- val/var map = Map(键->值, 键->值, 键->值...) // 推荐,可读性更好
- val/var map = Map((键, 值), (键, 值), (键, 值), (键, 值)...)
- scala> val map = Map("zhangsan"->30, "lisi"->40)
- scala> val map = Map(("zhangsan", 30), ("lisi", 30))
- /* 根据key获取value */
- scala> map("zhangsan")
1.2 可变Map
定义语法与不可变Map一致。但定义可变Map需要手动导入
import scala.collection.mutable.Map- scala> val map = Map("zhangsan"->30, "lisi"->40)
- /* 修改value */
- scala> map("zhangsan") = 20
14 iterator
scala针对每一类集合都提供了一个迭代器(iterator)用来迭代访问集合。
使用迭代器遍历集合
使用iterator方法可以从集合获取一个迭代器,迭代器的两个基本操作:
hasNext——查询容器中是否有下一个元素
next——返回迭代器的下一个元素,如果没有,抛出NoSuchElementException
每一个迭代器都是有状态的;迭代完后保留在最后一个元素的位置,再次使用则抛出NoSuchElementException;可以使用while或者for来逐个返回元素。- scala> val a = List(1,2,3,4,5)
- scala> val ite = a.iterator
- scala> while(ite.hasNext) {
- | println(ite.next)
- | }
- scala> for(i <- a) println(i)
15 函数式编程
使用
foreach方法来进行遍历、迭代,它可以让代码更加简洁。foreach(f: (A) ⇒ Unit): Unit 示例:有一个列表,包含以下元素1,2,3,4,使用foreach方法遍历打印每个元素
示例:有一个列表,包含以下元素1,2,3,4,使用foreach方法遍历打印每个元素- scala> val a = List(1,2,3,4)
- scala> a.foreach((x:Int)=>println(x))
上述案例函数定义有点啰嗦,因为使用foreach去迭代列表,而列表中的每个元素类型是确定的:scala可以自动来推断出来集合中每个元素参数的类型,创建函数时,可以省略其参数列表的类型。如下:
scala> a.foreach(x=>println(x))当函数参数,只在函数体中出现一次,而且函数体没有嵌套调用时,可以使用下划线来简化函数定义
scala> a.foreach(println(_))如果方法参数是函数,如果出现了下划线,scala编译器会自动将代码封装到一个函数中,参数列表也是由scala编译器自动处理。
map方法接收一个函数,将这个函数应用到每一个元素,返回一个新的列表
def map[B](f: (A) ⇒ B): TraversableOnce[B] map方法解析
map方法解析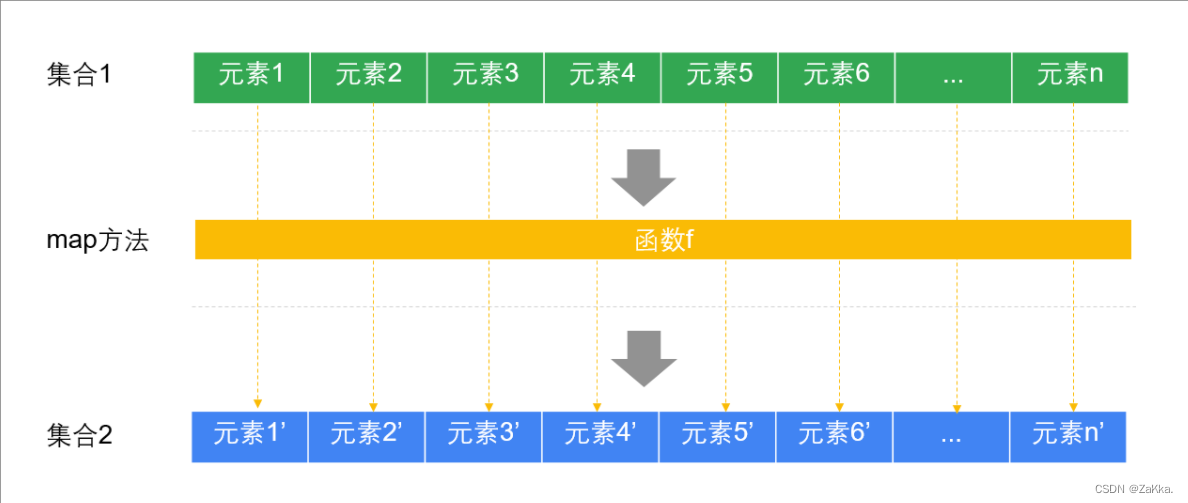
- scala> val a = List(1,2,3,4)
- scala> a.map(x=>x+1)
- /* 或者 */
- scala> a.map(_ + 1)
1.3 flatMap
扁平化映射可以把flatMap,理解为先map,然后再flatten。

- map是将列表中的元素转换为一个List
- flatten再将整个列表进行扁平化
def flatMap[B](f: (A) ⇒ GenTraversableOnce[B]): TraversableOnce[B]1.4 filter
过滤符合一定条件的元素
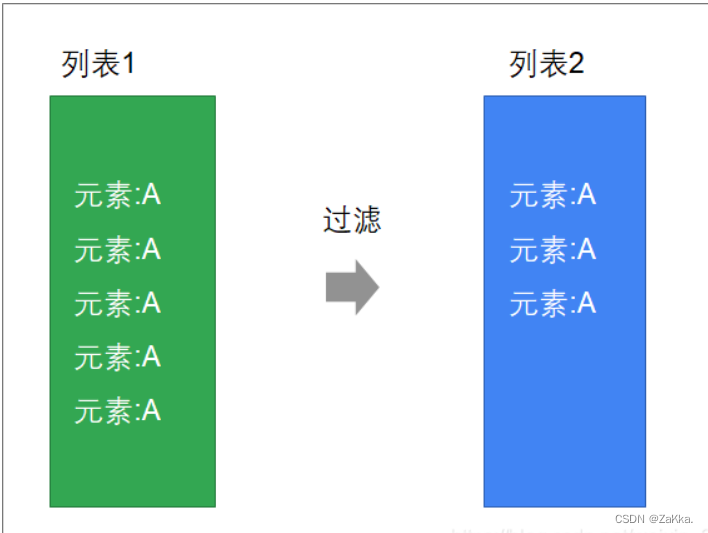
def filter(p: (A) ⇒ Boolean): TraversableOnce[A]
scala> List(1,2,3,4,5,6,7,8,9).filter(_ % 2 == 0)1.5 分组
如果要将数据按照分组来进行统计分析,就需要使用到分组方法。groupBy表示按照函数将列表分成不同的组。
def groupBy[K](f: (A) ⇒ K): Map[K, List[A]]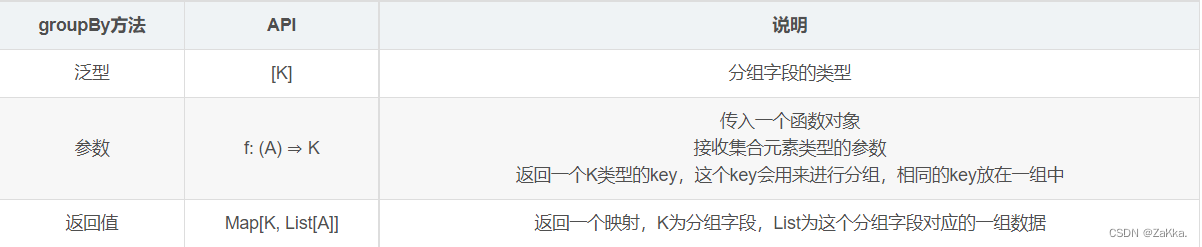
groupBy执行过程
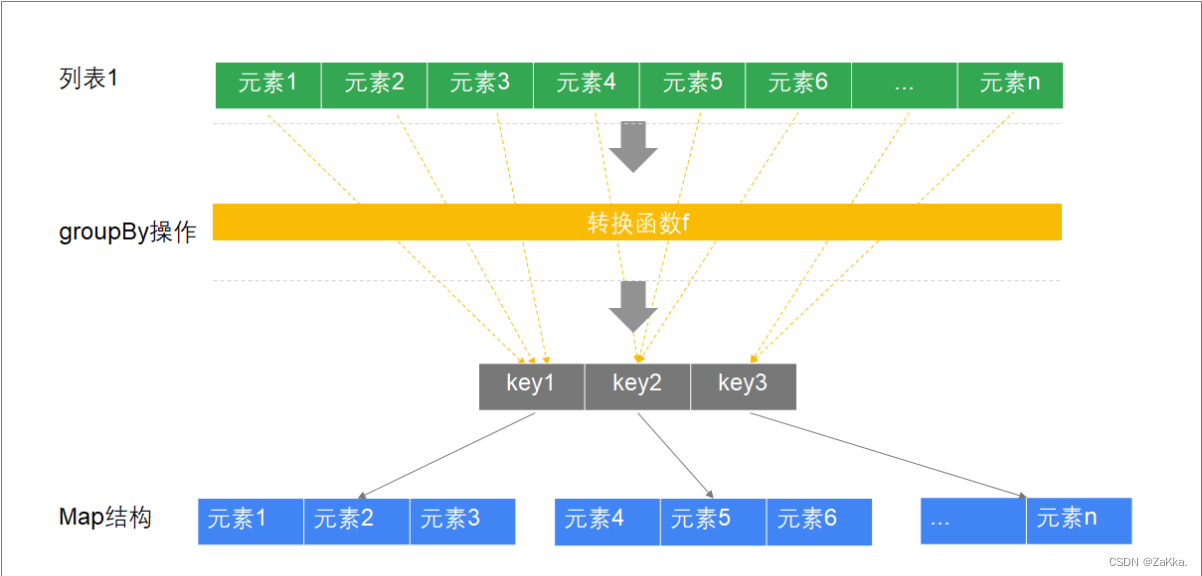
- scala> val a = List("张三"->"男", "李四"->"女", "王五"->"男")
- // 按照性别分组
- scala> a.groupBy(_._2)
- // 将分组后的映射转换为性别/人数元组列表
- scala> res0.map(x => x._1 -> x._2.size)
- res3: scala.collection.immutable.Map[String,Int] = Map(男 -> 2, 女 -> 1)
4.面向对象
scala是支持面向对象的,也有类和对象的概念;依然可以基于scala语言来开发面向对象的应用程序。
1.1 创建类和对象
- object ClassDemo {
- // 创建类
- class Person{}
- def main(args: Array[String]): Unit = {
- // 创建对象
- val p = new Person()
- println(p)
- }
- }
1.2 定义和访问成员变量
一个类会有自己的属性,例如:人这样一个类,有自己的姓名和年龄。具体用法如下:
- 在类中使用
var/val来定义成员变量 - 对象直接使用成员变量名称来访问成员变量
- object ClassDemo {
- class Person {
- // 定义成员变量
- var name = ""
- var age = 0
- }
- def main(args: Array[String]): Unit = {
- // 创建Person对象
- val person = new Person
- person.name = "zhangsan"
- person.age = 20
- // 获取变量值
- println(person.name)
- println(person.age)
- }
- }
1.3 使用下划线初始化成员变量
scala中有一个更简洁的初始化成员变量的方式,可以让代码看起来更加简洁,用法如下:
- 在定义
var类型的成员变量时,可以使用_来初始化成员变量; val类型的成员变量,必须要自己手动初始化;
- object ClassDemo {
- class Person{
- // 使用下划线进行初始化
- var name:String = _
- var age:Int = _
- val sign:Boolean = true
- }
- def main(args: Array[String]): Unit = {
- val person = new Person
- println(person.name)
- println(person.age)
- println(person.sign)
- }
- }
1.4 定义成员方法
类可以有自己的行为,scala中也可以通过定义成员方法来定义类的行为。在scala的类中,也是使用
def来定义成员方法。- object ClassDemo {
- class Customer {
- var name:String = _
- var sex:String = _
- // 定义成员方法
- def sayHi(msg:String) = {
- println(msg)
- }
- }
- def main(args: Array[String]): Unit = {
- val customer = new Customer
- customer.name = "张三"
- customer.sex = "男"
- customer.sayHi("你好")
- }
- }
1.5 成员访问修饰符
和Java一样,scala也可以通过访问修饰符,来控制成员变量和成员方法是否可以被访问。Java中的访问控制,同样适用于scala,可以在成员前面添加private/protected关键字来控制成员的可见性。但在scala中没有public关键字,任何没有被标为private或protected的成员都是公共的。- object AccessDemo {
- class Person {
- // 定义私有成员变量
- private var name:String = _
- private var age:Int = _
- def getName() = name
- def setName(name:String) = this.name = name
- def getAge() = age
- def setAge(age:Int) = this.age = age
- // 定义私有成员方法
- private def getNameAndAge = {
- name -> age
- }
- }
- def main(args: Array[String]): Unit = {
- val person = new Person
- person.setName("张三")
- person.setAge(10)
- println(person.getName())
- println(person.getAge())
- }
- }
5模式匹配
scala中有一个非常强大的模式匹配机制,可以应用在很多场景:switch语句,类型查询,使用模式匹配快速获取数据。
在Java中,有switch关键字,可以简化if条件判断语句。在scala中,可以使用match表达式替代。
- 变量 match {
- case "常量1" => 表达式1
- case "常量2" => 表达式2
- case "常量3" => 表达式3
- case _ => 表达式4 // 默认匹配
- }
- println("请输出一个词:")
- // StdIn.readLine表示从控制台读取一行文本
- val name = StdIn.readLine()
- val result = name match {
- case "hadoop" => "大数据分布式存储和计算框架"
- case "zookeeper" => "大数据分布式协调服务框架"
- case "spark" => "大数据分布式内存计算框架"
- case _ => "未匹配"
- }
- println(result)
2 匹配类型
除了像Java中的switch匹配数据之外,match表达式还可以进行类型匹配。如果要根据不同的数据类型,来执行不同的逻辑,也可以使用match表达式来实现。
- 变量 match {
- case 类型1变量名: 类型1 => 表达式1
- case 类型2变量名: 类型2 => 表达式2
- case 类型3变量名: 类型3 => 表达式3
- ...
- case _ => 表达式4
- }
- val a:Any = "hadoop"
- val result = a match {
- case _:String => "String"
- case _:Int => "Int"
- case _:Double => "Double"
- }
- println(result)
3.样例类
样例类是一种特殊类,它可以用来快速定义一个用于保存数据的类(类似于Java POJO类)。语法格式:
case class 样例类名([var/val] 成员变量名1:类型1, 成员变量名2:类型2, 成员变量名3:类型3)如果要实现某个成员变量可以被修改,可以添加var;默认为val,可以省略。
- object CaseClassDemo {
- case class Person(name:String, age:Int)
- def main(args: Array[String]): Unit = {
- val zhangsan = Person("张三", 20)
- println(zhangsan)
- }
- }
1 样例类方法
当我们定义一个样例类,编译器自动帮助我们实现了以下几个有用的方法:
apply方法可以让我们快速地使用类名来创建对象(省略了new关键字)。参考以下代码:
- case class CasePerson(name:String, age:Int)
- object CaseClassDemo {
- def main(args: Array[String]): Unit = {
- val lisi = CasePerson("李四", 21)
- println(lisi.toString)
- }
- }
1.2 toString
toString返回样例类名称(成员变量1, 成员变量2, 成员变量3…),我们可以更方面查看样例类的成员。
- case class CasePerson(name:String, age:Int)
- object CaseClassDemo {
- def main(args: Array[String]): Unit = {
- val lisi = CasePerson("李四", 21)
- println(lisi.toString)
- // 输出:CasePerson(李四,21)
- }
- }
1.3 equals
样例类自动实现了equals方法,可以直接使用
==比较两个样例类是否相等,即所有的成员变量是否相等- val lisi1 = CasePerson("李四", 21)
- val lisi2 = CasePerson("李四", 21)
- println(lisi1.eq(lisi2)) //false
- println(lisi1 == lisi2) //true
1.4copy
样例类实现了copy方法,可以快速创建一个相同的实例对象,可以使用带名参数指定给成员进行重新赋值
- val lisi1 = CasePerson("李四", 21)
- val wangwu = lisi1.copy(name="王五")
- println(wangwu)
-
相关阅读:
Vuex 组件间通讯
代码随想录算法训练营第二十四天丨 回溯算法part02
【小5聊】sql server 分页和分组-row_number()和over()、rank()和over()的小区别
在进行自动化测试,遇到验证码的问题,怎么办?
不指定时区会踩坑:MySQL Java 驱动升级遇到的 Bug 分析
ASP.Net Core设置接口根路径的方法
Java岗大厂面试百日冲刺 - 日积月累,每日三题【Day5】 —— 基础篇2
Windows连接SFTP服务
h264编码算法流程
POI 中 Excel设置列的格式
- 原文地址:https://blog.csdn.net/2301_77281478/article/details/138782681