-
人工智能(pytorch)搭建模型28-基于Transformer的端到端目标检测DETR模型的实际应用,DETR的原理与结构
大家好,我是微学AI,今天给大家介绍一下人工智能(pytorch)搭建模型28-基于Transformer的端到端目标检测DETR模型的实际应用,DETR的原理与结构。DETR(Detected Transformers)是一种基于Transformer的端到端目标检测模型,由Facebook AI Research团队提出。该模型彻底革新了传统的目标检测方法,不再依赖于复杂的区域提议或锚点生成,而是直接从输入图像中预测出所有物体的位置和类别。DETR的核心思想是将目标检测任务转化为一个集束搜索问题,通过自注意力机制在编码器和解码器之间传递信息,实现对图像内容的理解和定位。
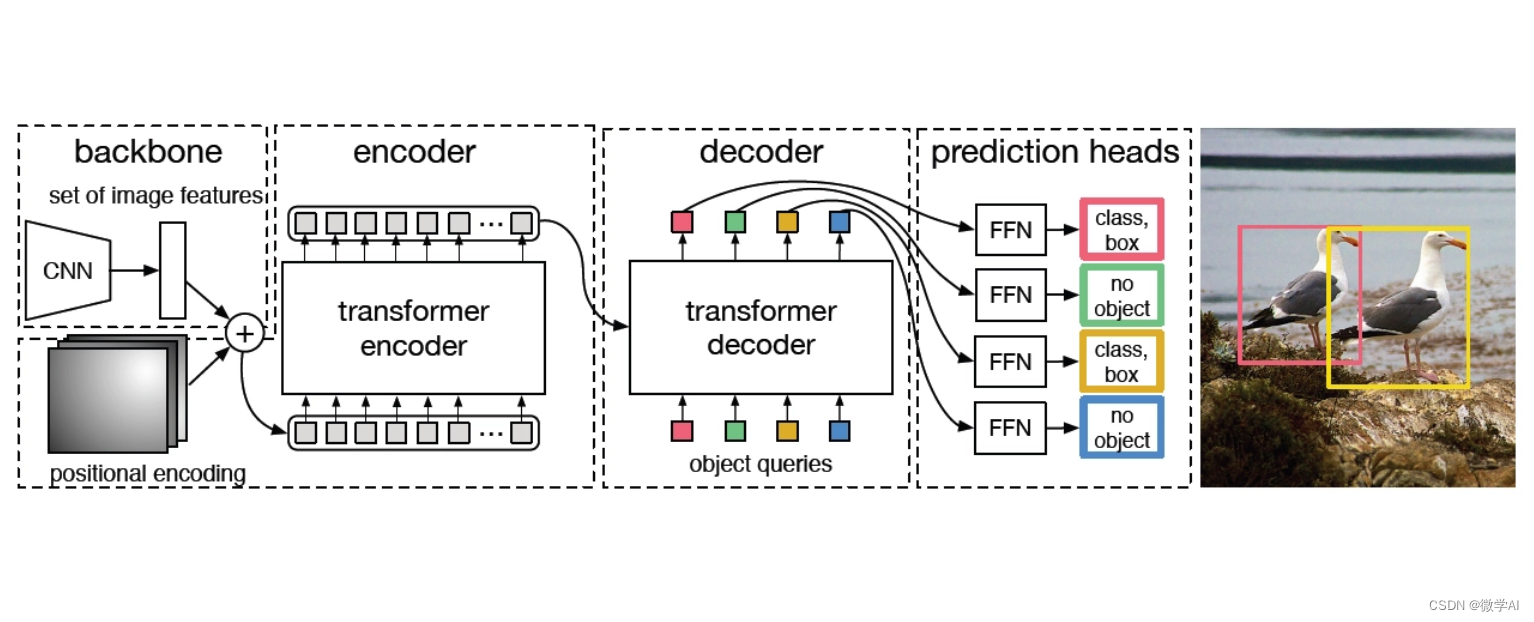
一、DETR模型原理
1. 自注意力机制
DETR(Detected Transformers)是一种用于目标检测的全新架构,它彻底抛弃了传统的滑动窗口和区域提议策略,而是直接预测每个物体的位置和类别。其核心原理是自注意力机制。
自注意力机制,源自Transformer模型,允许模型在输入序列的每个位置上,同时考虑所有其他位置的信息。在DETR中,每个位置的特征向量不仅与自身相关,还与其他所有位置的特征进行交互,通过计算它们之间的相似度权重,形成一个全局的上下文表示。这使得模型能够捕捉到物体之间的复杂关系,如遮挡或重叠。
DETR首先将图像通过卷积神经网络转化为一系列特征图,然后通过多层自注意力层,每个位置都能“理解”全局图像内容,寻找可能的目标候选。最后,一个全连接层输出每个位置的类别的概率和边界框坐标,无需复杂的后处理步骤,如非极大值抑制,就能得到准确的检测结果。这种设计大大简化了目标检测任务,提高了效率和准确性。
2. 位置编码和查询编码
DETR(Detected Transformers)是一种基于Transformer架构的端到端目标检测模型。它抛弃了传统的区域提议生成和分类两步法,直接从输入图像中预测出所有物体的位置和类别。其核心原理是将每个物体视为一个query,通过自注意力机制与输入图像的所有像素进行交互,从而获取物体的精确位置信息。
位置编码在DETR中起着关键作用。它为每个query和图像的每个像素添加了一个位置信息向量,使得Transformer能够理解物体的相对位置关系,而不仅仅是像素值。查询编码则是将输入的类别标签转化为向量形式,与位置编码一起作为query输入到Transformer中。
DETR可以应用于车辆、行人等目标的识别和定位。输入摄像头捕获的图像,经过位置编码后,每个像素都包含了其在图像中的位置信息。同时,每个目标类别(如车、人)都会被转换为查询编码。Transformer会根据这些编码,找出图像中的目标并预测其精确位置,无需额外的区域提议步骤,大大提高了检测效率。这在实时的自动驾驶决策中,对于快速准确地识别周围环境具有重要意义。
二、DETR模型结构详解
1. 编码器-解码器架构
DETR(Detected Transformers)是一种基于Transformer的端到端目标检测模型,其核心架构是编码器-解码器设计。编码器部分,它采用了ViT(Vision Transformer)的基础结构,将输入图像划分为多个固定大小的patches,并通过多层自注意力和前馈神经网络进行特征提取,生成全局上下文丰富的特征表示。解码器部分则是Transformer的变种,引入了自注意力机制和多头注意力机制,用于预测目标的位置和类别。每个解码器头预测一个类别的置信度和一组相对位置偏移,这些信息被用于生成最终的目标框。
比如自动驾驶或者智能监控中,DETR可以接收摄像头捕捉的实时图像,通过编码器理解图像内容,解码器则预测出图像中的行人、车辆等物体的位置和类别,无需人为设定复杂的区域提议或锚点,极大地简化了目标检测的过程。其强大的性能使得它在多项目标检测任务上取得了显著的成果,展示了Transformer在计算机视觉领域的巨大潜力。
2. 多头注意力与动态解码
DETR(Detected Transformers)是一种用于对象检测的新型Transformer架构,它彻底抛弃了传统的区域提议生成和分类两步法,改用单一的Transformer网络进行端到端的处理。其中,关键的组成部分是多头注意力机制和动态解码。
多头注意力,即Multi-Head Attention,是Transformer的核心模块。它将输入特征映射分解成多个子空间,每个子空间执行独立的注意力计算,最后将结果合并。这样可以同时捕捉不同尺度和方向的信息,提高了模型对全局上下文的理解能力。在DETR中,多头注意力被用于对图像中的每个位置进行编码,以便捕捉物体的位置信息和关系。
动态解码则是DETR的独特之处。传统的对象检测模型需要预先定义可能的物体数量,而DETR则通过自回归的方式,逐个预测目标的类别和边界框,直到输出序列结束。这个过程是动态的,无需人为设定候选框的数量,能适应各种复杂场景。在项目中,比如在自动驾驶或智能监控中,DETR能够实时准确地识别并定位车辆、行人等目标,大大提高了系统的智能化水平。
举个例子,在一个图像中,DETR首先通过多头注意力机制理解每个像素点的上下文信息,然后在解码阶段,它会预测出“存在一个行人,坐标在(50, 100),类别为行人”,然后再继续预测下一个目标,直到没有更多的目标为止。这种方式不仅简化了模型结构,也提升了检测的灵活性和准确性。
三、实际应用案例与讨论
1. 行为识别与视频分析
行为识别与视频分析是一种先进的计算机视觉技术,它通过深度学习算法对视频中的动态行为进行实时监控和解析。例如,在零售业中,超市可以利用这项技术来识别顾客的行为模式,如滞留时间长的货架、频繁拿起又放下的商品,甚至预测潜在的购买行为。在安全领域,行为分析系统能检测出异常行为,如无人区域的陌生人长时间逗留,或者在禁止区域的活动,及时发出警报。
以某大型购物中心为例,安装了行为识别摄像头后,系统可以精确追踪每个顾客的行走路径,分析他们在各个店铺的停留时间,帮助商家调整布局和促销策略。同时,系统还能识别出可能的盗窃行为,一旦检测到异常,安保人员就能迅速响应,提高安全防范效率。此外,学校也运用此技术监控学生出勤和行为规范,如自动统计迟到早退的学生,或者识别出在课堂上分心的行为,有助于提升教育管理效能。
总的来说,行为识别与视频分析在各个行业都有广泛的应用,通过智能化的数据处理,不仅提高了工作效率,也提升了安全性,是现代数字化管理的重要组成部分。
2. 自动驾驶中的对象检测
自动驾驶中的对象检测是关键技术之一,它主要负责在行驶环境中识别和定位各种障碍物、行人、车辆等目标。通过深度学习的卷积神经网络(CNN)模型,如YOLO(You Only Look Once)、Faster R-CNN或SSD(Single Shot MultiBox Detector),自动驾驶系统能实时处理来自摄像头、雷达和激光雷达的数据,生成高精度的物体位置和类别信息。
以特斯拉Autopilot为例,其使用了先进的物体检测算法。当车辆行驶时,摄像头捕捉到的图像首先被输入到对象检测模块,这个模块会快速扫描并标记出道路上的所有可能障碍,包括其他车辆、行人、交通标志等。如果检测到前方有障碍物,系统会计算出安全距离并做出相应的驾驶决策,如减速、变道或停车。这种实时、准确的对象检测能力,极大地提高了自动驾驶的安全性。
在实际项目中,工程师们会对大量的标注数据进行训练,不断优化模型的性能,使其在复杂光照、天气和道路条件下都能稳定工作。例如,当雨天或夜晚光线不足时,系统需要能够识别出清晰的轮廓和颜色信息,这就对算法的鲁棒性提出了更高要求。因此,对象检测在自动驾驶领域的应用,既是一个技术挑战,也是一个推动技术创新的重要驱动力。
3. 图像检索与智能推荐
图像检索与智能推荐是现代信息技术的重要应用,它结合了计算机视觉和机器学习技术,为用户提供个性化和高效的信息服务。在实际项目中,例如电子商务平台,我们可以看到其广泛应用。
首先,图像检索技术使得用户可以通过上传一张商品图片,快速找到与其相似或完全匹配的商品。比如,当用户在亚马逊搜索一款特定的鞋子,系统会通过分析鞋子的颜色、纹理、款式等特征,从庞大的商品库中找出最接近的选项。这大大提高了用户的购物体验,节省了他们筛选的时间。
其次,智能推荐则是基于用户的行为历史和偏好,通过深度学习算法对用户可能感兴趣的内容进行预测。例如,Netflix的电影推荐系统,会根据用户的观看历史、评分以及浏览行为,推荐他们可能会喜欢的新电影或电视剧。这种个性化的推荐不仅增加了用户的活跃度,也提升了商家的转化率。
在实际项目开发中,我们首先需要收集并标注大量的图像数据,作为训练模型的基础。然后,利用深度学习模型如卷积神经网络(CNN)进行图像特征提取,再通过相似度计算或者推荐算法进行匹配或推荐。最后,通过实时更新用户行为数据,持续优化推荐结果,实现精准推送。
总的来说,图像检索与智能推荐技术在提升用户体验、驱动商业增长等方面发挥着关键作用,是现代数字化世界中的核心技术之一。
四、DETR模型的数学原理
DETR (Detected Transformers) 是一种基于Transformer的端到端目标检测模型,它在目标检测任务中引入了自注意力机制,使得模型可以直接从输入图像中学习到目标的位置和类别信息,而无需复杂的区域提议生成步骤。下面是DETR的一些关键数学原理的公式表示:
-
自注意力机制:
Transformer中的自注意力模块通过计算query、key和value之间的相似度来获取每个位置的上下文信息。这可以通过softmax函数和点积运算实现,公式如下:A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q, K, V) = softmax\left(\frac{QK^T}{\sqrt{d_k}}\right)V Attention(Q,K,V)=softmax(dkQKT)V
其中, Q Q Q, K K K, 和 V V V 分别是查询、键和值矩阵, d k d_k dk 是键的维度,softmax用于归一化。 -
多头自注意力:
DETR使用多头自注意力,将输入分解为多个并行的注意力头,每个头关注输入的不同方面,公式为:M u l t i H e a d ( Q , K , V ) = C o n c a t ( h e a d 1 , . . . , h e a d h ) W O MultiHead(Q, K, V) = Concat(head_1, ..., head_h)W^O MultiHead(Q,K,V)=Concat(head1,...,headh)WO
其中, h h h 是头的数量, W O W^O WO 是输出权重矩阵。 -
位置编码:
DETR在输入特征上添加了位置编码,以便模型能够区分不同位置的信息。常用的有Sinusoidal位置编码,其公式为:P E ( p o s , 2 i ) = s i n ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos, 2i)} = sin(pos/10000^{2i/d_{model}}) PE(pos,2i)=sin(pos/100002i/dmodel)
P E ( p o s , 2 i + 1 ) = c o s ( p o s / 1000 0 2 i / d m o d e l ) PE_{(pos, 2i+1)} = cos(pos/10000^{2i/d_{model}}) PE(pos,2i+1)=cos(pos/100002i/dmodel) -
Transformer Encoder:
DETR的编码器由多个Transformer编码层组成,每个层包括自注意力层和前馈神经网络(FFN):SelfAttention ( X ) = A t t e n t i o n ( X W Q , X W K , X W V ) FFN ( X ) = ReLU ( X W 1 + b 1 ) W 2 + b 2 X ′ = LayerNorm ( X + SelfAttention ( X ) ) X ′ ′ = LayerNorm ( X ′ + FFN ( X ′ ) ) SelfAttention(X)=Attention(XWQ,XWK,XWV)FFN(X)=ReLU(XW1+b1)W2+b2X′=LayerNorm(X+SelfAttention(X))X″=LayerNorm(X′+FFN(X′))
SelfAttention(X)FFN(X)X′X′′=Attention(XWQ,XWK,XWV)=ReLU(XW1+b1)W2+b2=LayerNorm(X+SelfAttention(X))=LayerNorm(X′+FFN(X′)) -
解码器和预测头:
DETR的解码器是一个标准的Transformer decoder,它接收编码器的输出并预测目标的位置和类别。预测头将解码器的输出映射到目标类别和位置偏移量:p ^ i = softmax ( L i n e a r ( [ cls ] i , X ′ ′ ) ) t ^ i = L i n e a r ( [ reg ] i , X ′ ′ ) ˆpi=softmax(Linear([cls]i,X″))ˆti=Linear([reg]i,X″)
p^it^i=softmax(Linear([cls]i,X′′))=Linear([reg]i,X′′)
其中, p ^ i \hat{p}_i p^i 是第 i i i个目标的概率分布, t ^ i \hat{t}_i t^i 是第 i i i个目标的位置偏移量。
这些公式展示了DETR模型的基本结构和核心数学原理,但实际的模型实现可能还会包含一些其他细节,如损失函数、训练策略等。
五、DETR模型的代码实现
DETR(Detr: End-to-End Object Detection with Transformers)是一个基于Transformer的端到端目标检测模型,它使用自注意力机制来学习特征和预测目标。以下是一个简单的DETR模型的PyTorch实现示例,注意这只是一个基础版本,实际应用中可能需要更复杂的网络结构和数据预处理步骤:
import torch from torch import nn from torch.nn import TransformerEncoder, TransformerEncoderLayer # 定义Transformer Encoder class TransformerEncoderLayer(nn.Module): def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1): super().__init__() self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout) self.linear1 = nn.Linear(d_model, dim_feedforward) self.dropout = nn.Dropout(dropout) self.linear2 = nn.Linear(dim_feedforward, d_model) def forward(self, src, mask=None): src2 = self.self_attn(src, src, src, key_padding_mask=mask)[0] src = src + self.dropout(src2) src2 = self.linear2(self.dropout(F.relu(self.linear1(src)))) src = src + self.dropout(src2) return src class TransformerEncoderNet(nn.Module): def __init__(self, num_layers=6, num_heads=8, d_model=512, dropout=0.1): super().__init__() self.encoder = TransformerEncoder(TransformerEncoderLayer(d_model, num_heads, dropout=dropout), num_layers) def forward(self, x): src_key_padding_mask = ~x.any(dim=1) # True for padding, False for non-padding return self.encoder(x, src_key_padding_mask) # 假设我们有一个简单的输入数据(这里只是一个例子,实际应用中需要更复杂的数据预处理) input_data = torch.randn(1, 10, 256) # (batch_size, num_queries, feature_dim) # 创建Transformer Encoder网络 model = TransformerEncoderNet() # 前向传播 output = model(input_data) print("Output shape:", output.shape) # 这里输出应该是 (1, 10, d_model)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
这个代码示例创建了一个基本的Transformer Encoder,用于处理特征向量。在DETR中,还需要一个解码器来预测目标的位置和类别,以及一个分类头。这些部分的实现会更复杂,并且通常在训练过程中还需要额外的损失函数和优化器。完整的DETR模型实现应该包含这些部分。
此外,DETR通常使用预训练的Transformer作为特征提取器(如ViT或DeiT),并将目标检测任务转换为点预测问题,这超出了这个简单示例的范围。如果你需要完整的DETR模型实现,建议查阅相关论文或官方代码库(如Hugging Face的Transformers库)。
六、总结
DETR是一款基于Transformer的端到端目标检测模型,由Facebook AI研发,革新了传统检测方法。它摒弃了区域提议和锚点生成,直接从图像中预测位置和类别,通过全局特征捕获和解码器的自注意力机制进行目标生成与定位。其核心是将检测视为集束搜索问题,简化了流程并提升效率。虽然计算成本较高,适用于大规模数据和高分辨率场景有限,但DETR展示了深度学习在目标检测领域的创新潜力,预示着未来技术的突破。
-
-
相关阅读:
Matlab使用cftool进行曲线拟合
2023NOIP A层联测9 长春花
入门力扣自学笔记75 C++ (题目编号522)
linux U盘无法使用,提示“Partition table entries are not in disk order“
Android 获取短信验证
CentOS 7 编译安装Boost
SpringBoot整合JPA+SQLite
喜讯 | 同立海源CGT核心原料CD28单抗完成FDA DMF备案
[Qt] Qt Creator中配置 Vs-Code 编码风格
使用.NET简单实现一个Redis的高性能克隆版(一)
- 原文地址:https://blog.csdn.net/weixin_42878111/article/details/138195606
