前几天Meta开源发布了新的Llama大语言模型:Llama-3系列,本次一共发布了两个版本:Llama-3-8B和Llama-3-70B,根据Meta发布的测评报告,Llama-3-8B的性能吊打之前的Llama-2-70B,也就是说80亿参数的模型干掉了700亿参数的模型,这个还真挺让人震惊的。

Llama-3-8B真的有这么强吗?
鉴于8B的模型可以在24G显存下流畅运行,成本不高,我就在AutoDL上实际测试了一下。
测试方案
使用的是我之前在AutoDL上发布的一个大语言模型WebUI镜像:yinghuoai-text-generation-webui (这个WebUI可以对大语言模型进行推理和微调),显卡选择的是 4090D 24G显存版本,使用三个问题分别测试了 Llama-3-8B-Instruct(英文问答)、Llama-3-8B-Instruct(中文问答)、llama3-chinese-chat、Qwen1.5-7B-Chat。其中llama3-chinese-chat是网友基于Llama-3-8B-Instruct训练的中文对话模型,项目地址:https://github.com/CrazyBoyM/llama3-Chinese-chat
三个问题分别是:
- 小明的妻子生了一对双胞胎。以下哪个推论是正确的?
- A.小明家里一共有三个孩子
- B.小明家里一共有两个孩子。
- C.小明家里既有男孩子也有女孩子
- D.无法确定小明家里孩子的具体情况
- 有若干只鸡兔同在一个笼子里,从上面数,有35个头,从下面数,有94只脚。问笼中各有多少只鸡和兔?
- 请使用C#帮我写一个猜数字的游戏。
这三个问题分别考察大语言模型的逻辑推理、数学计算和编码能力。当然这个考察方案不怎么严谨,但是也能发现一些问题。
因为Llama-3的中文训练语料很少,所有非英语的训练数据才占到5%,所以我这里对Llama-3-8B分别使用了中英文问答,避免因中文训练不足导致测试结果偏差。
测试结果
鸡兔同笼问题
Llama-3-8B-Instruct(中文问答)
首先模型没有搞清楚鸡和兔的脚的数量是不同的,其次模型解方程的能力也不怎么行,总是算不对。
另外还是不是飙几句英语,看来中文训练的确实不太行。

Llama-3-8B-Instruct(英文问答)
搞清楚了不同动物脚的数量问题,但是还是不会计算,有时候方程能列正确,但是测试多次还是不会解方程组。

llama3-chinese-chat
中文无障碍,数学公式也列对了,但是答案是错的,没有给出解答过程。实测结果稳定性也比较差,每次总会给出不一样的解答方式。

Qwen1.5-7B-Chat
中文无障碍,答案正确,解答过程也基本完整。

小明家孩子的情况
Llama-3-8B-Instruct(中文问答)
答案不正确,解释的也不全面,没有说明其它答案为什么不正确。

Llama-3-8B-Instruct(英文问答)
答案正确,但是分析的逻辑有缺陷,没有完全说明白,只谈到性别问题,数字逻辑好像有点绕不清。

llama3-chinese-chat
答案错误,逻辑是混乱的,前言不搭后语,没有逻辑性。

Qwen1.5-7B-Chat
答案是正确的,但是逻辑不太通顺,说着性别,就跳到数量上去了。

猜数字游戏编程
Llama-3-8B-Instruct(中文问答)
代码完整,没有明显问题,但是还是会冒英文。

Llama-3-8B-Instruct(英文问答)
代码完整,没有明显问题。

llama3-chinese-chat
代码正确,但是不够完整,还需要更多提示。

Qwen1.5-7B-Chat
代码完整,没有明显问题。

测试结论
根据上边的测试结果,有一些结论是比较明确的。
Llama-3-8B的中文能力确实不太行,最明显的是时不时会冒一些英文,更重要的是使用中文时输出的内容偏简单化,逻辑上不那么严谨。
网友训练的 llama3-chinese-chat 问题比较多,可能是训练数据不足,或者训练参数上不够优秀,回答问题过于简略,逻辑性不够,稳定性也不太行,经常输出各种不一样的答案。建议只是玩玩,可以学习下它的训练方法。
Llama-3-8B的逻辑分析和数学能力不太行?至少在回答上边的鸡兔同笼问题和小明家孩子的情况上表现不佳,这是什么原因呢?训练语料的问题?但是我使用Llama-3-70B时,它可以正确且圆满的回答这两个问题,这就是权重参数不够的问题了,8B参数的能力还是差点。
Llama-3-8B的英文能力总体感觉还可以,但实测也没有那么惊艳,总有一种缺少临门一脚的感觉,有点瑕疵。说它媲美或者超越百亿参数的模型,这个是存在一些疑虑的。
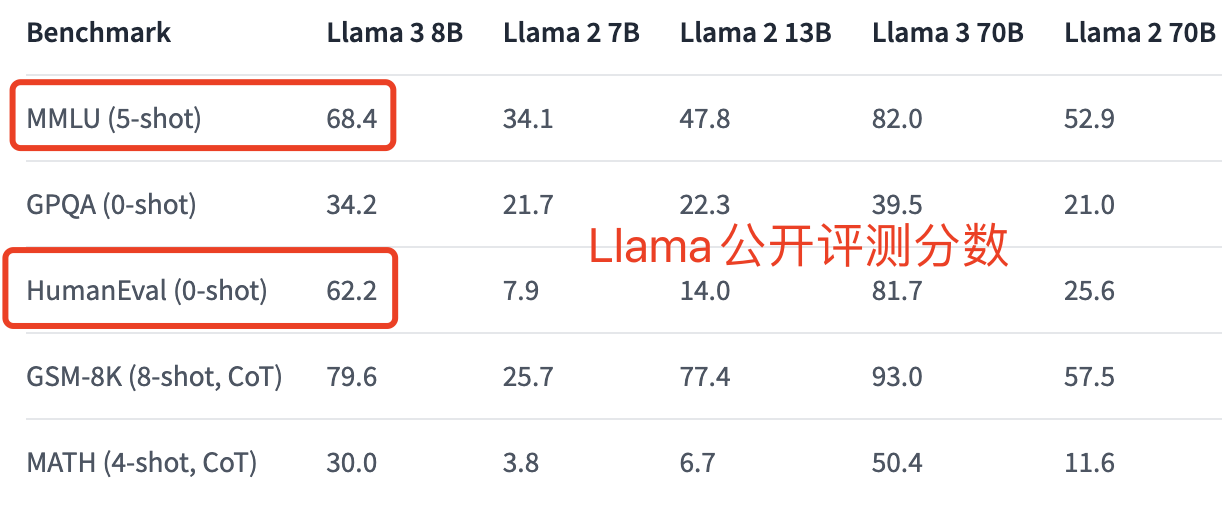
Qwen1.5-7B-Chat在这几个问题的表现上还不错,不过很可能是这几个问题都学的很熟练了,特别是鸡兔同笼问题,大语言模型刚刚火爆的时候在国内常常被拿来做比较使用。目前还没有完整的Llama-3和Qwen1.5的评测对比数据,Llama-3公开的基准测试很多使用了few-shot,也就是评估时先给出几个问答示例,然后再看模型在类似问题上的表现,关注的是学习能力。根据HuggingFace上公开的数据,仅可以对比模型在MMLU(英文综合能力)和HumanEval(编程)上的的表现,比较突出的是编程能力,如下面两张图所示:

企业或者个人要在业务中真正使用,感觉还得是百亿模型,准确性和稳定性都会更好,百亿之下目前还不太行,经常理解或者输出不到位,目前感觉70B参数的最好。
对于Llama-3-8B,如果你使用英文开展业务,又不想太高的成本,不妨试试,但是需要做更多增强确定性的工作,比如优化提示词、做些微调之类的,至于中文能力还得等国内的厂商们再努力一把,目前还不太行。
Llama-3的在线体验地址请移步这里:性能直逼GPT4,Llama3的三种在线体验方式。