-
ChatGPT的一小步,NLP范式转变的一大步

作者:符尧,yao.fu@ed.ac.uk,爱丁堡大学 (University of Edinburgh) 博士生,本科毕业于北京大学;与Tushar Khot,彭昊在艾伦人工智能研究院 (Allen Institute for AI) 共同完成英文原稿;与李如寐(美团NLP中心)共同翻译为中文;感谢 Aristo teammates, Jingfeng Yang, 和 Yi Tay 的讨论与建议。请同时参考CoT[1]团队的博客。
在此前《ChatGPT进化的秘密》一文中,本文作者剖析了ChatGPT的技术路线图。而在ChatGPT发布前,作者详细介绍了大模型的突现能力、以及它在NLP/ML任务中的潜在优势,以此来探讨大模型所带来的“潜在的”范式转变。显然,后来ChatGPT所展现出的强大能力,将这种转变的步伐扎实地推进了一大步。
英文版原文:https://franxyao.github.io/blog.html
最近,人们对大型语言模型所展示的强大能力(例如思维链[2]、便签本[3])产生了极大的兴趣,并开展了许多工作。我们将之统称为大模型的突现能力[4],这些能力可能只存在于大型模型中,而不存在于较小的模型中,因此称为“突现”。其中许多能力都非常令人印象深刻,比如复杂推理、知识推理和分布外鲁棒性。
值得注意的是,这些能力很接近 NLP 社区几十年来一直寻求的能力,因此代表了一种潜在的研究范式转变,即从微调小模型到使用大模型进行上下文学习。对于先行者来说,范式转变可能是很显然的。然而,出于科学的严谨性,我们确实需要非常明确的理由来说明为什么人们应该转向大型语言模型,即使这些模型昂贵、难以使用,并且效果可能一般。
在本文中,我们将仔细研究这些能力是什么,大型语言模型可以提供什么,以及它们在更广泛的 NLP/ML 任务中的潜在优势是什么。前提:我们假设读者具备以下知识:
-
预训练、精调、提示(普通从业者应具备的自然语言处理/深度学习能力)
-
思维链提示、便签本(普通从业者可能不太了解,但不影响阅读)
1
存在于大模型而非小模型的突现能力

图片来自于 Wei. et. al. 2022. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models。X轴为模型尺寸。GSM8K是一个小学水平的数学问题集。
在以上的效果图中,我们可以观察到模型的表现:
-
当尺寸相对小的时候提升并不大
-
当模型变大时有很明显的提升
这从根本上说明,某些能力可能不存在于小模型中,而是在大模型中获得的。
有很多种突现能力,比如 Wei 等人在 2022年[5]所梳理的。有些能力很有意思,但我们在本文不会讨论,比如last latter concatenation,我们认为这是Python而不是语言模型要做的任务;或者3位数加法,我们认为这是计算器而不是语言模型要做的事。
在本文中,我们主要对以下能力感兴趣:
1. NLP 社区近几年都关注但还没实现的能力
2. 之前的 NLP 模型很难达到的能力
3. 源自于人类语言最深层的本质的能力
4. 可能达到人类智力的最高水平的能力
2
突现能力的三个典型例子
很多有意思的能力都可以归到上文提到的类别里,在它们之中,我们主要讨论以下三种典型能力:
-
复杂推理
-
知识推理
-
分布外鲁棒性
接下来让我们一个个详细讨论。
复杂推理
下面是一个GSM8K数据集中,用提示词显著超过精调的例子:
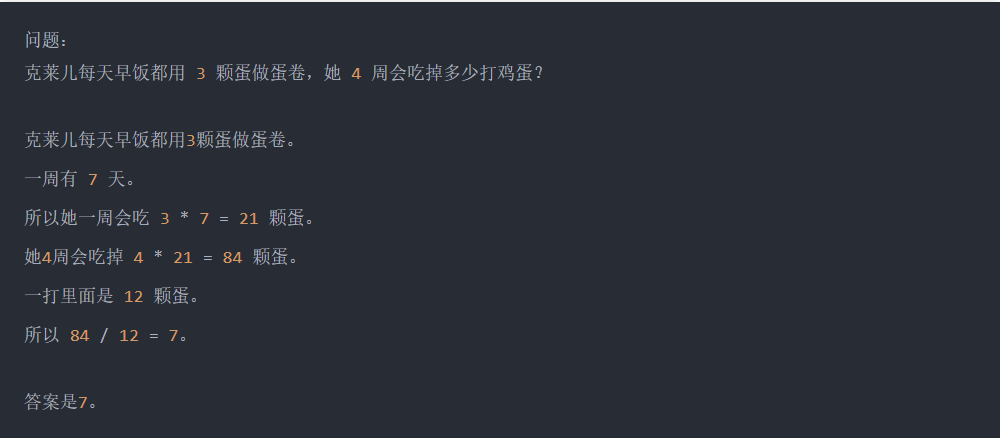
虽然这道题对于10岁的孩子来说很容易,但对语言模型来说却很难,主要是由于数学和语言混合在一起。
GSM8K 最初由 OpenAI 于 2021 年 10 月[6]提出。当时他们用第一版GPT3在全部训练集上进行了精调,准确率约为 35%。这个结果让作者相当悲观,因为他们的结果显示了语言模型的缩放规律:随着模型大小呈指数增长,性能呈线性增长(我之后会讨论)。因此,他们在第 4.1 节中思考:
”175B 模型似乎需要至少额外两个数量级的训练数据才能达到 80% 的求解率。“
三个月后,即 2022 年 1 月,Wei 等人[7]基于 540B PaLM 模型,仅使用了8个思维链提示示例便将准确率提高到56.6%(无需将训练集增加两个数量级)。之后在 2022 年 3 月,Wang 等人[8]基于相同的 540B PaLM 模型,通过多数投票的方法将准确率提高到 74.4% 。当前的 SOTA 来自我自己在 AI2 的工作(Fu et. al. Nov 2022[9]),我们通过使用复杂的思维链在 175B Codex 上实现了 82.9% 的准确率。从以上进展可以看到,技术进步确实呈指数级增长。
思维链提示是一个展示模型随着规模突现出能力的典型例子:
-
从突现能力来看:尽管不需要 17500B,但模型大小确实要大于 100B ,才能使思维链的效果大于的仅有回答提示。所以这种能力只存在于大型模
-
-
相关阅读:
十四天学会C++之第八天:文件操作
ES整合SpringBoot
JVM 直接内存
C# 泛型函数
CDN的优势,为什么各大站点都选择接入CDN
动规(22)-并查集基础题——CD收藏 cd.cpp(并查集)
OpenHarmony创新赛|赋能直播第五期
线性归一化是什么,用python实现数据的线性归一化
《Hello Algo》:动画图解引领的数据结构与算法学习之旅
Mybatis+Mapper完成对数据库的增删改查
- 原文地址:https://blog.csdn.net/OneFlow_Official/article/details/128502464