-
35张图,直观理解Stable Diffusion

作者|Jay Alammar
翻译|杨婷、徐佳渝
最近,AI图像生成引人注目,它能够根据文字描述生成精美图像,这极大地改变了人们的图像创作方式。Stable Diffusion作为一款高性能模型,它生成的图像质量更高、运行速度更快、消耗的资源以及内存占用更小,是AI图像生成领域的里程碑。
在接触了AI图像生成以后,你可能会好奇这些模型背后的工作原理。
下面是对Stable Diffusion工作原理的概述。

Stable Diffusion用途多样,是一款多功能模型。首先它可以根据文本生成图像(text2img)。上图是从文本输入到图像生成的示例。除此之外,我们还可以使用Stable Diffusion来替换、更改图像(这时我们需要同时输入文本和图像)。

下面是Stable Diffusion的内部结构,了解内部结构可以让我们更好地理解Stable Diffusion的组成、各组成部分的交互方式、以及各种图像生成选项/参数的含义。
1
Stable Diffusion的组成Stable Diffusion并不是一个单一模型,而是由多个部分和模型一起构成的系统。
从内部来看,首先我们可以看到一个文本理解组件,这个组件将文本信息转化为数字表示(numeric representation)以捕捉文本意图。

这部分主要对ML进行大概介绍,文章后续还会讲解更多细节。可以说这个文本理解组件(文本编码器)是一个特殊的Transformer语言模型(严格来说它是一个CLIP模型的文本编码器)。将文本输入到 Clip 文本编码器得到特征列表,对于文本中的每一个word/token 都有会得到一个向量特征。
然后将文本特征作为图像生成器的输入,图像生成器又由几部分组成。

图像生成器两步骤:
1-图像信息创建器(Image information creator)
图像信息创建器是Stable Diffusion特有的关键部分,也是其性能远超其他模型的原因。
图像信息创建器运行多个step生成图像信息。Stable Diffusion接口(interfaces)和库(libraries)的step参数一般默认为50或100。
图像信息创建器完全在图像信息空间(亦称潜在空间)上运行,这让Stable Diffusion比以前在像素空间(pixel space)上运行的扩散模型速度更快。从技术上讲,图像信息创建器由UNet神经网络和调度算法组成。
“扩散”一词描述了图像信息创建器中发生的事情。因为图像信息创建器对信息作了逐步处理,所以图像解码器(image decoder)才能随后产出高质量图像。

2-图像解码器(Image Decoder)
图像解码器根据图像信息创建器的信息绘制图像,它只用在过程结束时运行一次,以生成最终的像素图像。
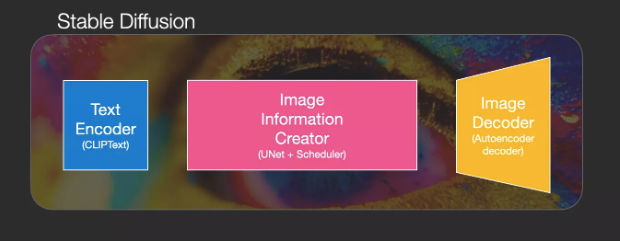
这样就构成了Stable Diffusion的三个主要组成部分,每个部分都有自己的神经网络:
-
ClipText: 用于文本编码。输入: 文本。输出: 77个token embeddings向量,每个向量有768维。
-
UNet+调度程序: 在信息(潜在)空间中逐步处理信息。输入: 文本embeddings和一个初始化的多维数组(结构化的数字列表,也称为
-
-
相关阅读:
已解决ModuleNotFoundError: No module named ‘PIL‘
【PostgreSQL-14版本snapshot的几点优化】
Orchestrator - server_id相同导致graceful-master-takeout-auto失败
Leetcode 75——1768.交替合并字符串 解题思路与具体代码【C++】
华为OD机试真题-分班-2023年OD统一考试(B卷)
精通中间件测试:Asp.Net Core实战指南,提升应用稳定性和可靠性
SSM处理过程
腾讯云4核8G服务器性能如何多少钱一年?
【Python人工智能】Python全栈体系(十九)
学习-Java类和对象之访问限制
- 原文地址:https://blog.csdn.net/OneFlow_Official/article/details/128681586