EMIFF
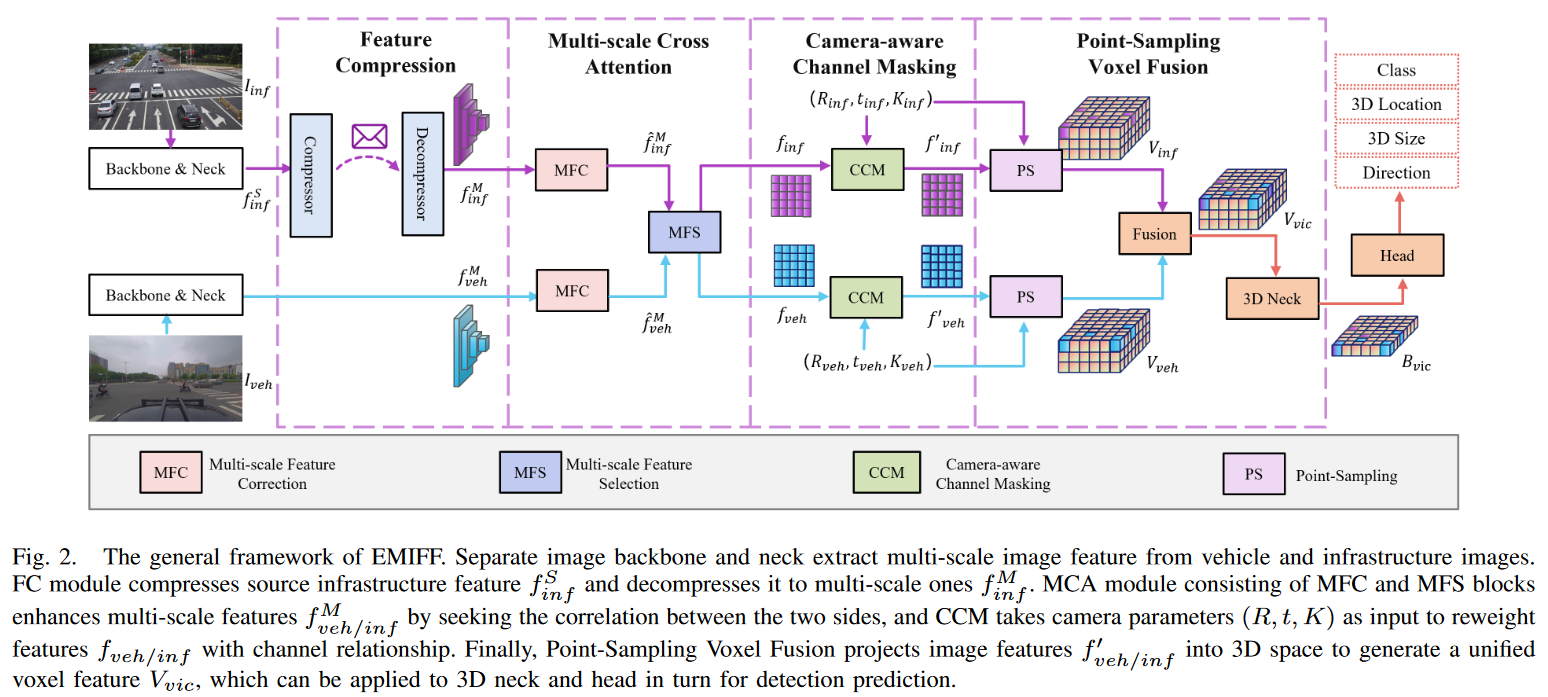
本文提出了一种新的基于摄像机的三维检测框架,增强型多尺度图像特征融合(EMIFF)。虽然EMIFF的输入是2D图像,但是它的neck层的结构设计应该普适于点云的3D目标检测,同时其中的MFC等模块可以简单地被替换成更先进的其他组件。
为了充分利用车辆和基础设施的整体视角,本文提出了多尺度交叉注意MCA(包含了MFC和MFS)和相机感知通道掩蔽CCM模块,以在尺度、空间和通道(MFC尺度级增强、MFS空间级增强、CCM通道级增强)级别增强基础设施和车辆特征,从而纠正相机异步引入的姿态误差。我们还引入了一个特征压缩FC模块,该模块具有信道和空间压缩块,以提高传输效率。
MFC
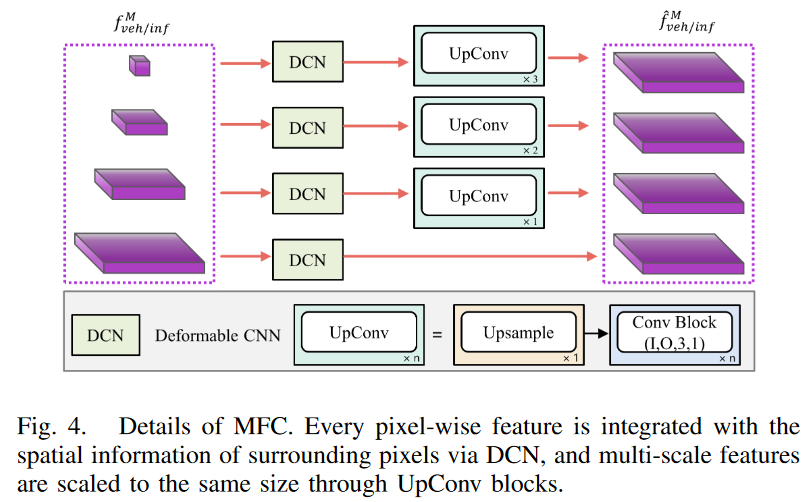
MFC模块首先应用于多尺度特征。由于姿态误差会导致2D平面上投影位置和地面真实位置之间的位移,我们对每个比例特征应用DCN,以允许每个像素获得其周围的空间信息。然后,通过UpConv块将不同尺度的特征上采样到相同的尺寸。
class double_conv(nn.Module):
def __init__(self, in_ch, out_ch):
super(double_conv, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_ch, out_ch, 3, stride=1, padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU(),
nn.Conv2d(out_ch, out_ch, 3, stride=1, padding=1),
nn.BatchNorm2d(out_ch),
nn.ReLU()
)
def forward(self, x):
x = self.conv(x)
return x
class DCN_Up_Conv_List(nn.Module):
def __init__(self, neck_dcn, channels):
super(DCN_Up_Conv_List, self).__init__()
self.upconv0 = nn.Sequential(
double_conv(channels,channels),
)
self.upconv1 = nn.Sequential(
nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True),
double_conv(channels,channels),
)
self.upconv2 = nn.Sequential(
nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True),
double_conv(channels,channels),
nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True),
double_conv(channels,channels),
)
self.upconv3 = nn.Sequential(
nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True),
double_conv(channels,channels),
nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True),
double_conv(channels,channels),
nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True),
double_conv(channels,channels),
)
self.dcn0 = build_neck(neck_dcn)
self.dcn1 = build_neck(neck_dcn)
self.dcn2 = build_neck(neck_dcn)
self.dcn3 = build_neck(neck_dcn)
def forward(self, x):
assert x.__len__() == 4
x0 = self.dcn0(x[0])
x0 = self.upconv0(x0)
x1 = self.dcn1(x[1])
x1 = self.upconv1(x1)
x2 = self.dcn2(x[2])
x2 = self.upconv2(x2)
x3 = self.dcn3(x[3])
x3 = self.upconv3(x3)
return [x0,x1,x2,x3]
MFS
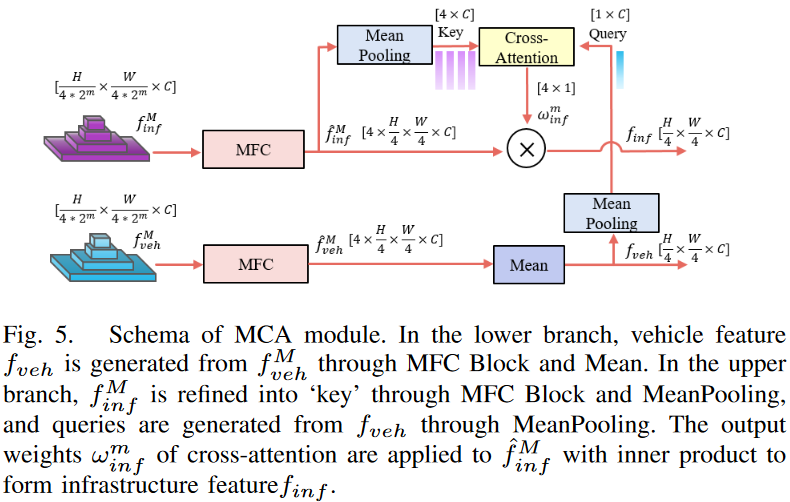
MFS应用MeanPooling操作获得不同尺度的基础设施特征的表示,而不同尺度的车辆特征首先通过mean操作融合,然后通过MeanPooling进行细化。为了寻找不同尺度下车辆特征和基础设施特征之间的相关性,交叉注意应用于基础设施表示作为关键,车辆表示作为查询,生成每个尺度m的注意权重ω m inf。我们计算特征^fM inf和权重ω m inf之间的乘积。MCA的最终输出是增强的基础设施图像特征finf和车辆图像特征fveh。
def attention(query, key, mask=None, dropout=None):
# from IPython import embed
# embed()
"Compute 'Scaled Dot Product Attention'"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) \
/ math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return p_attn
def extract_img_feat(self, img, img_metas):
"""Extract features from images."""
bs = img.shape[0]
img_v = img[:,0,...]
img_i = img[:,1,...]
x_v = self.backbone_v(img_v)
x_v = self.neck_v(x_v)
x_v = self.dcn_up_conv_v(list(x_v))
x_v_tensor = torch.stack(x_v).permute(1,0,2,3,4)
x_v_out = torch.mean(x_v_tensor,dim=1)
x_i = self.backbone_i(img_i)
x_i = self.neck_i(x_i)
# from IPython import embed
# embed(header='compress')
# Add compression encoder-decoder
x_i = self.inf_compressor(x_i)
x_i = self.dcn_up_conv_i(list(x_i))
x_i_tensor = torch.stack(x_i).permute(1,0,2,3,4)
# query.shape[B,C]
# key.shape[B,N_levels,C]
query = torch.mean(x_v_out,dim=(-2,-1))[:,None,:]
key = torch.mean(x_i_tensor,dim=(-2,-1))
weights_i = attention(query,key).squeeze(1)
# print('attention_weights',weights_i)
x_i_out = (weights_i[:,:,None,None,None] * x_i_tensor).sum(dim=1)
return tuple((x_v_out, x_i_out))
CCM
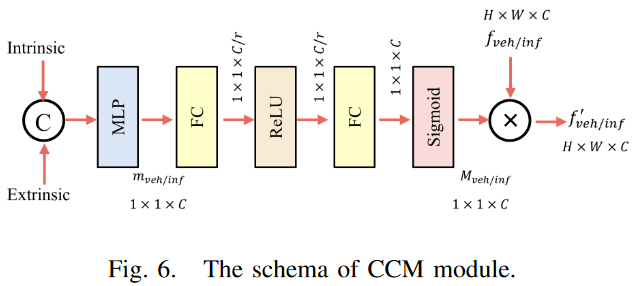
CCM将学习一个通道掩码来衡量通道之间的重要性。由于不同的通道表示不同距离的目标信息,这些信息与相机参数密切相关,因此将相机参数作为先验来增强图像特征是直观的。首先,将摄像机的内、外特性拉伸成一维并进行连接。然后,使用MLP将它们放大到特征的维数C,以生成通道掩模Mveh/inf。最后,Mveh/inf用于在通道方向上重新加权图像特征fveh/inf,并获得结果f’veh/inf。
class CCMNet(nn.Module):
def __init__(self, in_channels, mid_channels, context_channels, reduction_ratio=1):
super(CCMNet, self).__init__()
self.reduce_conv = nn.Sequential(
nn.Conv2d(in_channels,
mid_channels,
kernel_size=3,
stride=1,
padding=1),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
)
self.context_conv = nn.Conv2d(mid_channels,
context_channels,
kernel_size=1,
stride=1,
padding=0)
self.bn = nn.BatchNorm1d(16)
self.context_mlp = Mlp(16, mid_channels, mid_channels)
self.context_se = SE_Inception_Layer(mid_channels,reduction_ratio=reduction_ratio) # NOTE: add camera-aware
# self.context_se = CASELayer(mid_channels,reduction_ratio=8) # NOTE: add camera-aware
def ida_mat_cal(self,img_meta):
img_scale_factor = (img_meta['scale_factor'][:2]
if 'scale_factor' in img_meta.keys() else 1)
img_shape = img_meta['img_shape'][:2]
orig_h, orig_w = img_shape
ida_rot = torch.eye(2)
ida_tran = torch.zeros(2)
ida_rot *= img_scale_factor
# ida_tran -= torch.Tensor(crop[:2])
if 'flip' in img_meta.keys() and img_meta['flip']:
A = torch.Tensor([[-1, 0], [0, 1]])
b = torch.Tensor([orig_w, 0])
ida_rot = A.matmul(ida_rot)
ida_tran = A.matmul(ida_tran) + b
ida_mat = ida_rot.new_zeros(4, 4)
ida_mat[3, 3] = 1
ida_mat[2, 2] = 1
ida_mat[:2, :2] = ida_rot
ida_mat[:2, 3] = ida_tran
return ida_mat
def forward(self, x_v, x_i, img_metas):
# x [bs,num_cams,C,H,W]
bs, C, H, W = x_v.shape
num_cams = 2
x = torch.stack((x_v,x_i),dim=1).reshape(-1, C, H, W)
extrinsic_v_list = list()
extrinsic_i_list = list()
intrinsic_v_list = list()
intrinsic_i_list = list()
for img_meta in img_metas:
extrinsic_v = torch.Tensor(img_meta['lidar2img']['extrinsic'][0])
extrinsic_i = torch.Tensor(img_meta['lidar2img']['extrinsic'][1])
intrinsic_v = torch.Tensor(img_meta['lidar2img']['intrinsic'][0])
intrinsic_i = torch.Tensor(img_meta['lidar2img']['intrinsic'][1])
# from IPython import embed
# embed(header='ida')
ida_mat = self.ida_mat_cal(img_meta)
intrinsic_v = ida_mat @ intrinsic_v
intrinsic_i = ida_mat @ intrinsic_i
extrinsic_v_list.append(extrinsic_v)
extrinsic_i_list.append(extrinsic_i)
intrinsic_v_list.append(intrinsic_v)
intrinsic_i_list.append(intrinsic_i)
extrinsic_v = torch.stack(extrinsic_v_list)
extrinsic_i = torch.stack(extrinsic_i_list)
intrinsic_v = torch.stack(intrinsic_v_list)
intrinsic_i = torch.stack(intrinsic_i_list)
extrinsic = torch.stack((extrinsic_v,extrinsic_i),dim=1)
intrinsic = torch.stack((intrinsic_v,intrinsic_i),dim=1)
in_mlp = torch.stack(
(
intrinsic[..., 0, 0],
intrinsic[..., 1, 1],
intrinsic[..., 0, 2],
intrinsic[ ..., 1, 2],
),
dim=-1
)
# from IPython import embed
# embed(header='DCMNet')
ex_mlp = extrinsic[...,:3,:].view(bs,num_cams,-1)
mlp_input = torch.cat((in_mlp,ex_mlp),dim=-1)
mlp_input = mlp_input.reshape(-1,mlp_input.shape[-1]).to(x.device)
mlp_input = self.bn(mlp_input)
x = self.reduce_conv(x)
# context_se = self.context_mlp(mlp_input)[..., None, None]
context_se = self.context_mlp(mlp_input)
context = self.context_se(x, context_se)
context = self.context_conv(context)
context = context.reshape(bs,num_cams,C,H,W)
x_v_out = context[:,0,...]
x_i_out = context[:,1,...]
# from IPython import embed
# embed(header='DCMNet end')
return tuple((x_v_out, x_i_out))