-
Linux——线程(3)
在上一篇博客中,我介绍了关于Linux系统中pthread库线程的接口使用以 及对于pthread库的理解。但是我们单单会使用多线程的接口还不够,因为 在使用多线程解决问题的时候,由于进程中的数据对于其中的线程来说大 多是共享的,这也势必会导致线程对资源的访问是不安全的,所以我们还 需要能够避免或解决在使用多线程时可能会出现的各种问题。我今天会介 绍其中的第一部分内容,那就是互斥。- 1
- 2
- 3
- 4
- 5
- 6
线程的互斥
一小段代码
我在准备这篇博客之前,还简单的模拟实现出了C++中的线程大致是什么样的,我后面对线程的操作都会使用这个封装好的接口,代码如下:
#include#include #include using namespace std; template <class T> using func_t = function<void(T)>; template <class T> class Thread { public: Thread(string name, func_t<T> func, T arg) : _name(name), _tid(0), _isrunning(false), _func(func), _arg(arg) {} static void *threadroutine(void *arg) { ((Thread *)arg)->_func(((Thread *)arg)->_arg); } bool Start() { int n = pthread_create(&_tid, nullptr, threadroutine, (void *)this); if(n == 0) { _isrunning = true; return true; } } void Join() { pthread_join(_tid, nullptr); } bool IsRunning() { return _isrunning; } private: string _name; pthread_t _tid; bool _isrunning; func_t<T> _func; T _arg; }; - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
这段代码其中需要注意一些小细节,首先就是需要对模板能够有一定的了解,然后就是可能会有人在类中的Start函数中调用pthread_create函数的时候传的参数为什么还要再封装一层threadroutine函数,并且threadroutine函数还是static属性的?
首先,我们使用自己写的Thread的时候,需要线程执行的函数就需要创建对象的时候传过去保存在对象所属的类中的成员变量中,而且pthread_create函数中要求传的函数指针类型是void*(threadroutine)(void)类型的。
但是使用过C++标准库的读者知道,线程对象初始化的时候可没有要求这个函数的参数和返回值都是void的,所以这一点需要我们自己封装一下。
使用者传过来的函数我们并不知道是什么样子的,这由使用者决定,使用者清楚,所以我们需要再封装一层函数那就是threadroutine作为pthread_create函数的参数,然后threadroutine函数中再调用使用者所传入的函数,所以这时候要访问类内成员,这里有两种方式一种就是将threadroutine函数作为Thread类的友元,还有就是作为类内成员函数,这里我选择后者,至于为什么是threadroutine函数是static属性的,那是因为类内的成员函数的参数中第一个参数始终都是this指针,所以实际上成员函数是有着两个参数的,也就是threadroutine函数的类型是void(threadroutine)(Tread, void*)。所以我们需要static修饰这个函数,从而能够符合pthread_ctreate函数的参数要求。1. 问题的提出
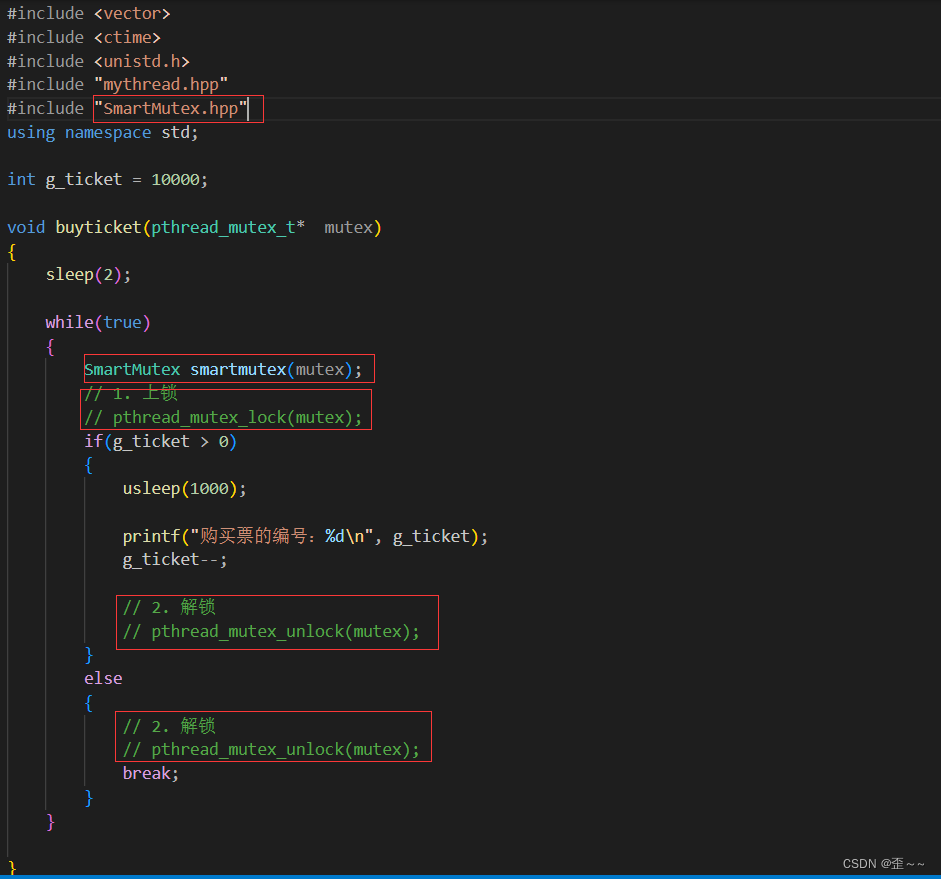
我先来写出一段代码来抛出问题:

其中mythread.hpp就是我封装好的线程库。
这段代码的意思就是创建好五个线程,让这五个线程都去执行byticket,然后这五个线程以并发的方式让全局变量g_ticket进行–,假如该变量小于0的话就跳出循环结束线程,然后线程被回收。现在来运行一下这个代码:
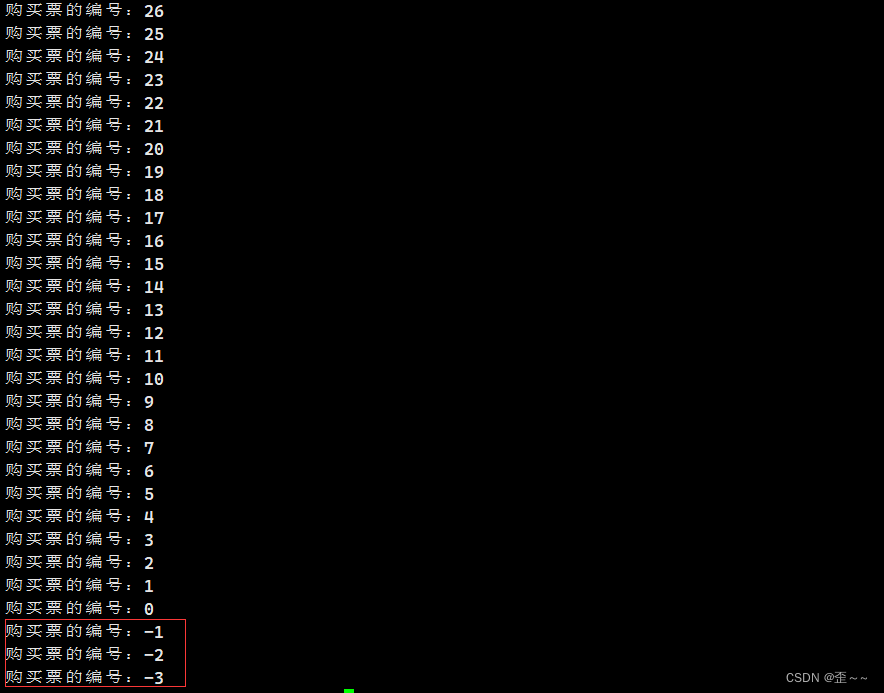
神奇的一幕就出现了,g_ticket这个变量,竟然小于0了,要知道我们的代码在主观认为是不可能出现这个变量小于0的,这显然程序是错误的,而这就是线程不安全了。2. 概念的提出
要真正的理解并解决上面出现的问题需要一些储备知识。
我们看到上面的代码它应该不会出现让g_ticket变量小于零的情况,但是事实就是出现小于零的情况了,这种多线程下的共享资源数据出现错误的现象叫做数据不一致。
而被保护的共享资源叫做临界资源。
我在这篇博客(进程间通信中的简单认识信号量一小节中)中也介绍临界资源的概念,保护临界资源也就是保护访问临界资源的代码,而这段代码也叫做临界区。
而保护共享资源的一个方式就是互斥,互斥的意思就是在同一时刻只能由一个执行流进入临界区访问临界资源。
我也曾经介绍过原子性的概念,原子性的大致意思就是,一个任务如果是原子的,那么它只会有两种状态,完成和没有完成,也就是在进行该任务期间该执行流是不可被切换的。
现在我们来认识一个观点:假如有一个变量a我们让这个a++,其中这个a++这行代码是原子的吗?

这里直接给出结果并做出解释,a++不是原子的,因为我们如果能看到这行代码的汇编代码的话就能得知了:

我们看到a++在汇编代码下,它是由三条指令构成的,下面我来解释一下这三条指令的大致意思:
第一句就是a变量会从内存中转移到寄存器eax中
然后第二句就是执行++
第三局就是再将eax中的内容转移到内存中。
我们可以发现在c++代码中一行就可以完成的任务,对于汇编而言需要三步。我们通常认为一条汇编指令就是原子的。那么a++这行代码明显不是原子的。
既然不是原子的,那么我们可以假设这么一个事件:
我们创建好两个线程(A和B),然后让这两个线程执行同一个函数,在这个函数中对一个全局变量(g_val)做++。
在理论上就可能会出现这样的情况:
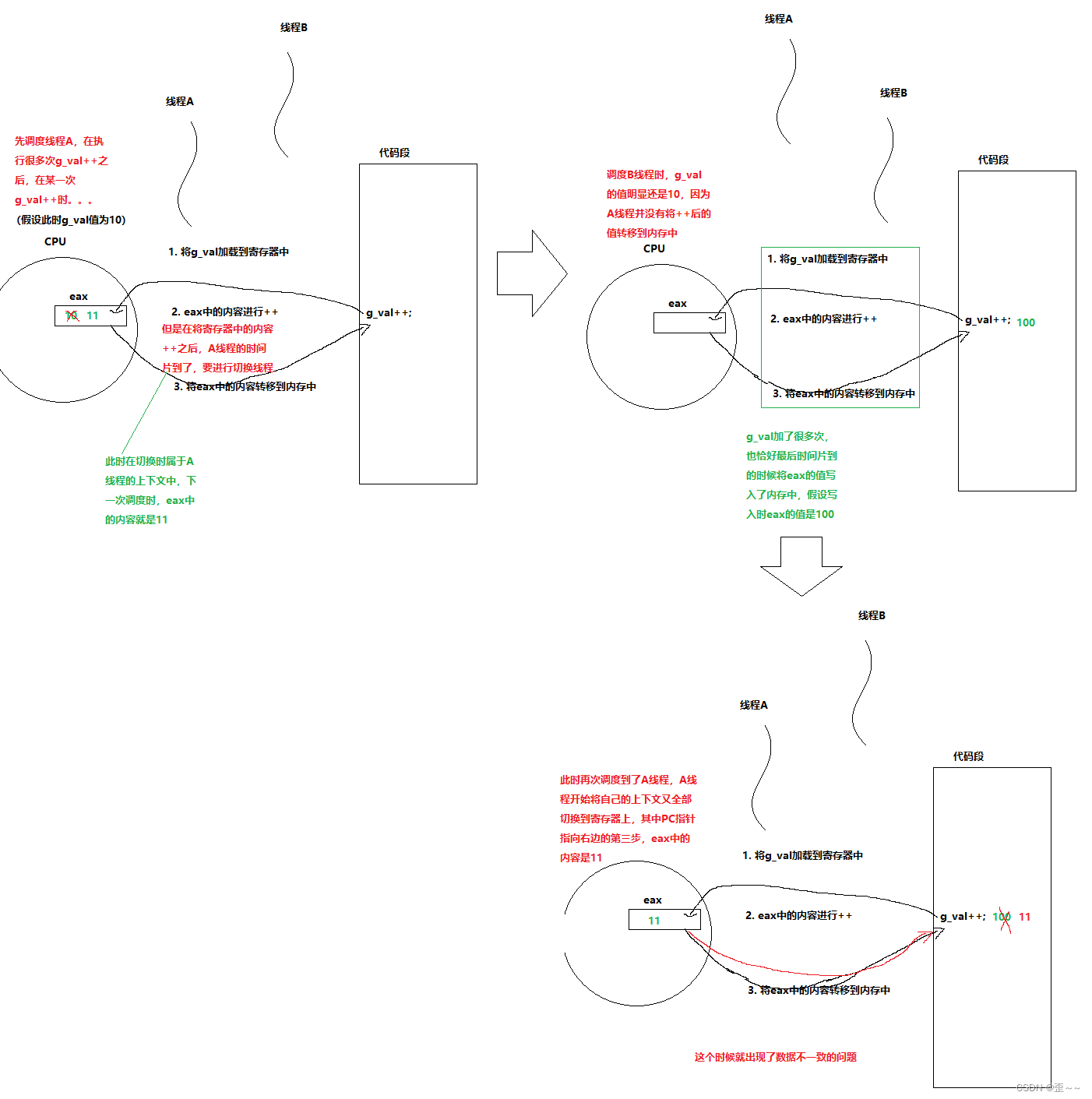
这里我们普及一个小知识点,我们知道CPU中由运算器支持运算,但是它不仅仅支持算术运算(加减乘除),它也支持逻辑运算(比如逻辑或,逻辑与)。3. 解释问题
现在我们来分析最开始的抢票代码为什么会出现负数:
我们创建五个线程,让这五个线程执行一个简单的抢票逻辑,当这个票的数目不大于0的时候,跳出循环。经过上面的理论介绍之后,有些人会以为,这段代码主要的问题出现在g_ticket++了,但是真的是这样吗?
再线程执行的函数中有两个地方是真正对g_ticket进行运算的,一个是g_ticket++,一个就是if语句中的对g_ticket的判断,前面说过逻辑运算也是运算。既然它也是运算的话,g_ticket也肯定需要先被转移到对应的寄存器中,然后再判断g_ticket是否大于0。其实出问题的地方是在这里。当有一个线程A刚要开始准备对g_ticket–时(此时g_ticket值为1),时间片到了,切换到另一个线程B,g_ticket此时值为1,大于零,进入第一个分支中,然后对g_ticket–,这样g_ticket值就为0了,过了一会又调度上了线程A,线程A现在的动作是对g_ticket–啊,此时一旦减了之后,g_ticket就小于零了,又因为我们的代码中有多个线程,所以出现这种现象可能不止在一个线程中,所以会出先我们的代码运行之后出现g_ticket小于零的情况。也就是数据不一致,线程安全出现了问题,针对这种问题,其中的解决方式就是互斥。4. Linux中的互斥
a. 接口介绍
我们知道互斥就是在一个时刻,只允许一个执行流访问临界资源,这样就可以对临界资源做很好的保护。保护临界资源也就是保护临界区,也就是我们对使用临界资源的代码进行保护就可以了,在Linux中互斥的体现就是加锁。这个锁叫做mutex,也叫互斥量。
现在我们就来认识一下Linux中关于锁的接口:
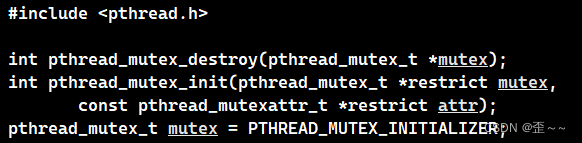
互斥锁其实就是一个类型为pthread_mutex_t的变量,既然是变量就可以分为局部变量和全局变量,在这两个变量中,全局变量可以使用PTHREAD_MUTEX_INITIALIZER来初始化,而局部变量就需要使用上面的pthread_mutex_init来初始化。
而锁的销毁就需要使用pthread_mutex_destroy来销毁。
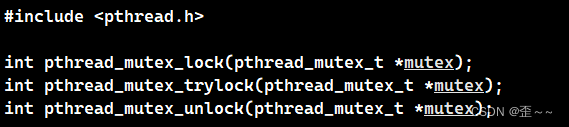
而对临界区的保护,就是给临界区进行上锁。上锁的接口就是pthread_mutex_lock。
但是上锁的前提是执行流能够申请到锁资源(上面的接口也就是申请锁资源的过程),如果申请到了,那么该执行流就会对该临界区上锁,以后就只能由该执行流执行临界区的代码。
而没有申请到锁资源的则会被挂起阻塞,知道锁资源可申请成功。
所以为了申请失败后不让执行流挂起阻塞,pthread_mutex_trylock可以实现这一功能。它会跳过临界区执行之后的代码。
而pthread_mutex_unlock就是解锁,释放锁资源。b. 全局变量的锁
接下来我们来使用一下这些接口,首先先使用全局的锁:
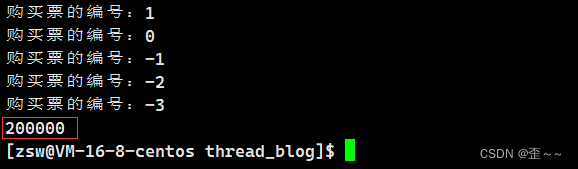
在对临界区上锁之前,我们先要清楚代码中哪一部分是临界区:
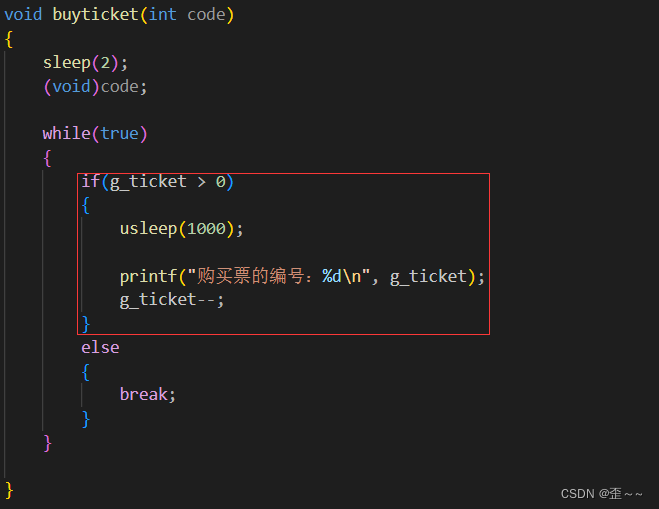
我们可以看到整段代码中,只有这一段代码访问了临界资源,所以我们也是对这段代码上锁:
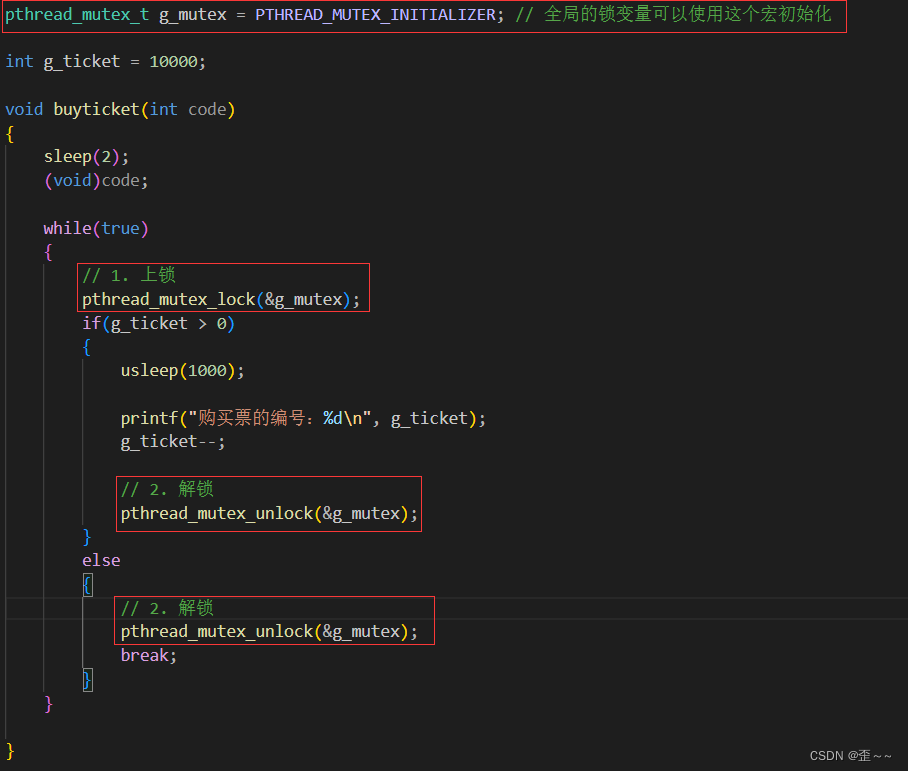
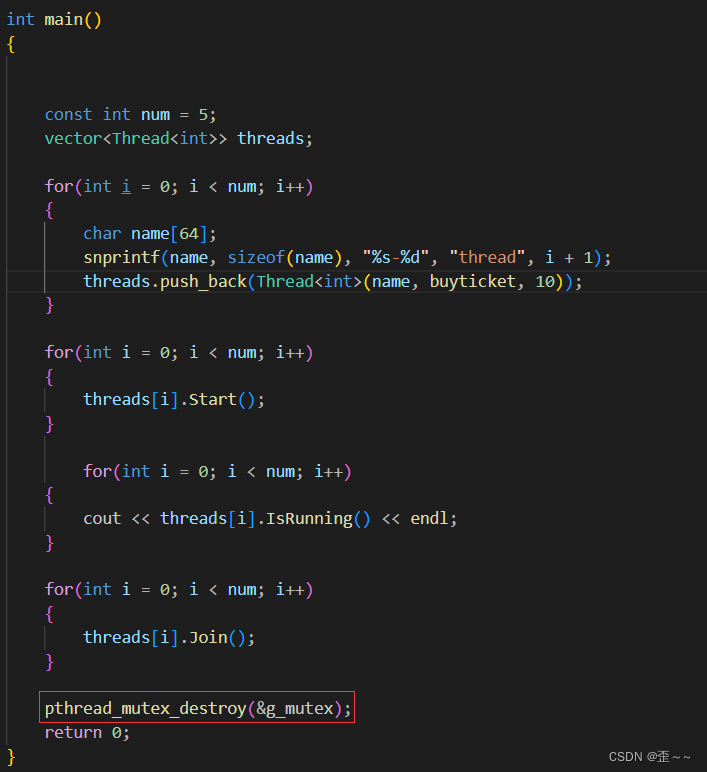
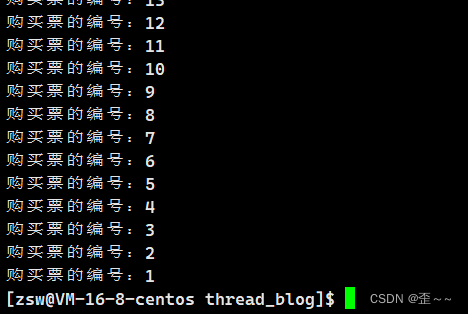
这样的话我们就完成了对临界区的保护,我们再次运行代码:
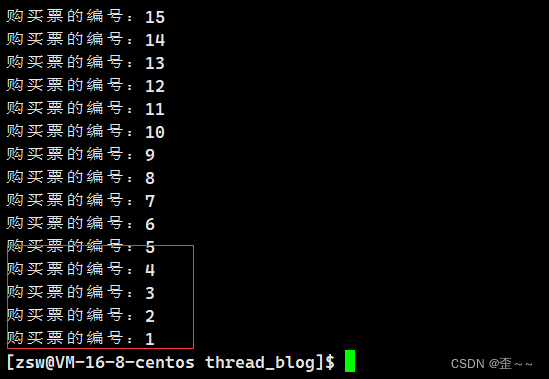
就不会出现负数的情况了。
现在呢,我们做一个小实验,来观察一下,上锁前后代码的运行效率如何:
我这里在代码的前后使用了clock来观察大致的用时是多少:
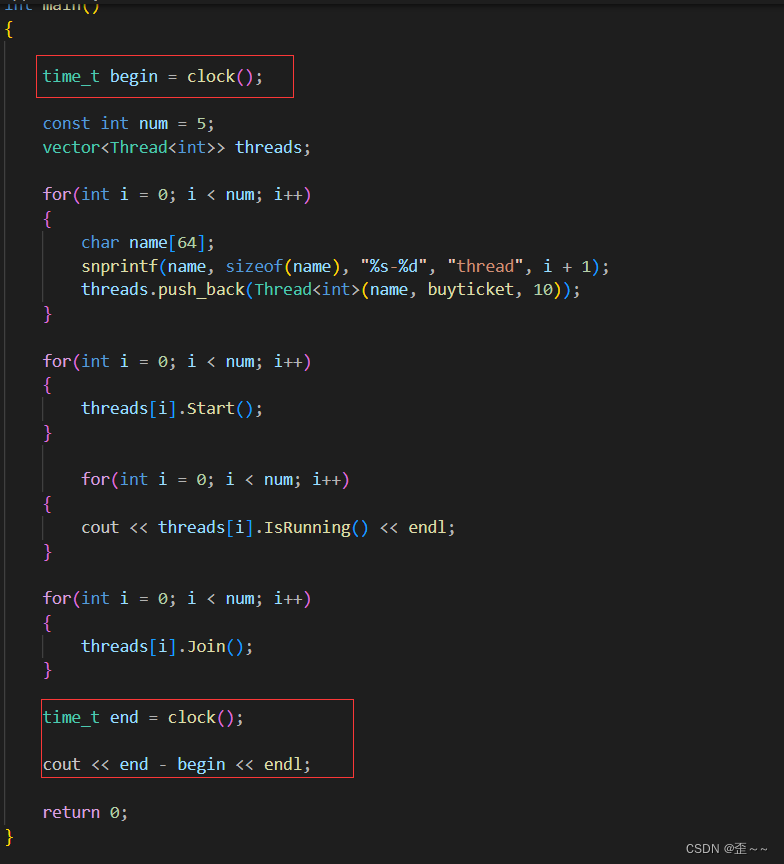
上锁后:

上锁前:
可以看到差距还是很大的,因为上锁之后当有一个执行流执行临界区代码时,就意味着其他执行流,要执行pthread_mutex_lock时会被阻塞。这就会导致线程的效率变低,但是这种情况也是没有办法避免的,除非多执行流不访问共享资源。c. 注意点
通过上面全局的锁的使用之后,我给出关于锁的使用的建议:
1. 尽量对少的代码块加锁 2. 一般加锁,都是给临界区加锁- 1
- 2
这里还有一些问题,在我们使用锁的过程中,g_mutex这个变量是全局的,那就意味着该进程下的所有线程都能访问到这个变量,那么此时这个锁不也是共享资源吗?为什么不需要对这个锁进行保护呢?
这里不难想到,其实关于关于锁资源的申请的过程它是原子的,是安全的。
还有问题,当一个执行流申请到了锁资源开始执行临界区代码的过程中,这个执行流有没有可能被切换呢?
如果脑子能转过弯来的话也不难想到,当然可以了啊。切换并不会出现线程不安全的问题。对于进程的临界区资源本来就是只对进程内部的执行流内部可见的,当切换其他进程中的执行流时,其他进程的执行流对该共享资源不可见,自然就不会访问到该资源了,而对于自己进程下的线程虽然对共享资源是可见的,但是由于锁的存在,它也执行不到临界区中的代码,也就不会发生线程不安全的问题了。所以当一个执行流执行临界区的代码时,该执行流是可以被切换的。
我们发现此时临界区一定意义上好像也具有了“原子性”。d. 局部变量的锁
现在我们来看看局部变量的锁又怎么使用呢?
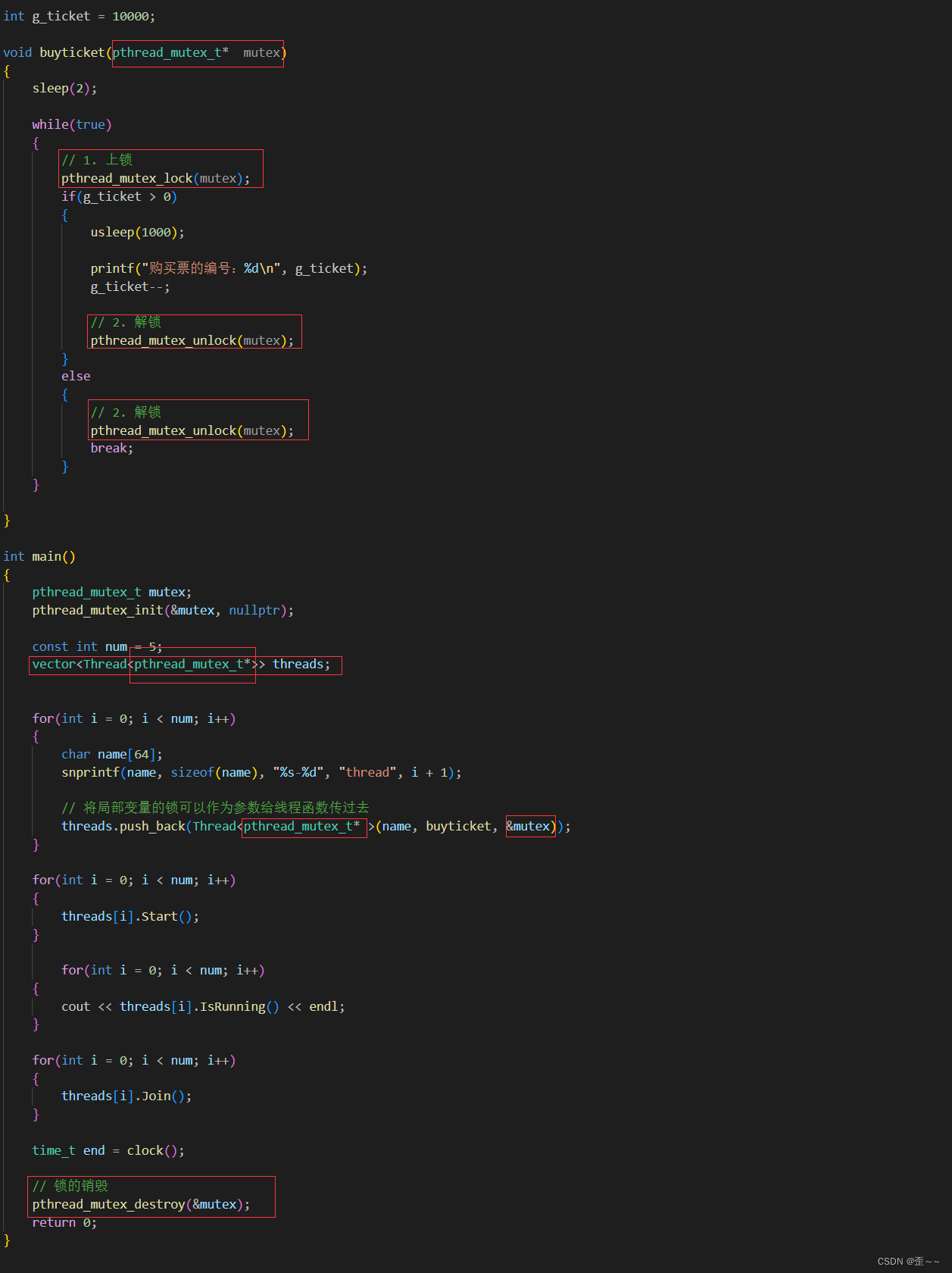
先在我们可以对这个局部变量的锁进行一下简单的封装,让它使用起来更简单一些:
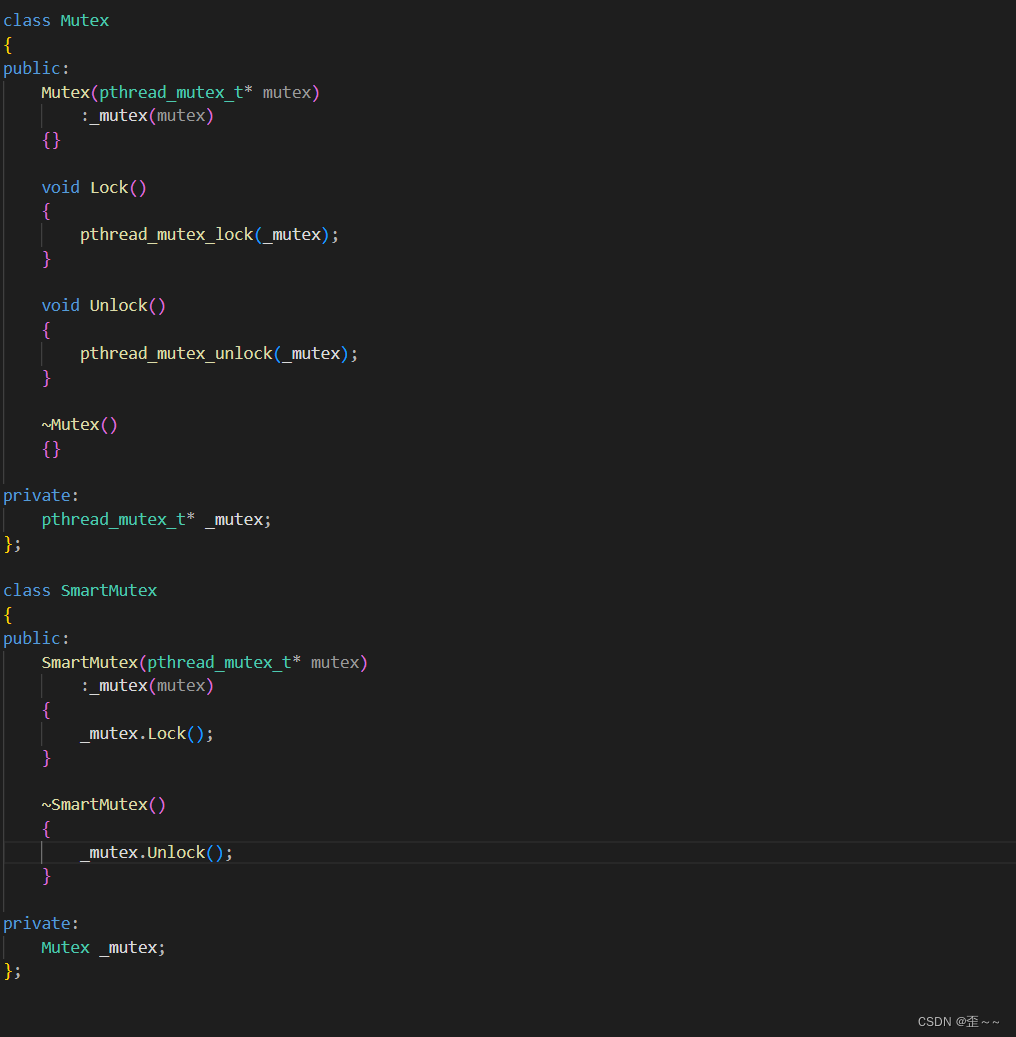

这样当我需要对临界区上锁时我就可以创建这么一个变量,创建好之后锁也就上上了。当该变量生命周期结束的时候则会自动解锁所以我们还应该规范一下该变量的作用域:
花括号的外面就可以是非临界区代码了。e. 理解锁
上面已经介绍了在多执行流执行并发访问共享资源会出现不一致的情况下如何使用加锁来解决问题。但是上面我提出一个疑问,那就是锁也是共享资源,为什么不需要被保护呢?我说加锁的过程是原子的。现在我就来解释一下如何理解加锁的过程是原子的。
我们知道我们使用C/C++写好代码之后,使用编译器编译代码的时候会有将代码转化为汇编代码的过程,我也说过我们可以将汇编代码的一条指令理解为原子的。其实在大多数的体系结构中都提供了诸如swap、exchange这样的指令,它的作用是将内存中的数和寄存器中的数进行交换。
我们假如要进行这样的交换,首先可能会在内存中开辟一个临时空间,然后将内存中的数存入到临时空间,再将寄存器中的内容放入到内存中,再将临时内存中的内容放到寄存器中,完成寄存器内容和内存内容数值的交换,看起来这样的过程有很多步,但其实在汇编层面这确实只是一步。
为了方便下面的理解,我们可以将锁抽象成只是一个整型变量mutex,当这个变量值为1的时候,就代表这个锁可申请,如果是0就代表不可申请。
接下来我给出一段关于加锁的伪代码:

那关于这段代码怎么理解呢?
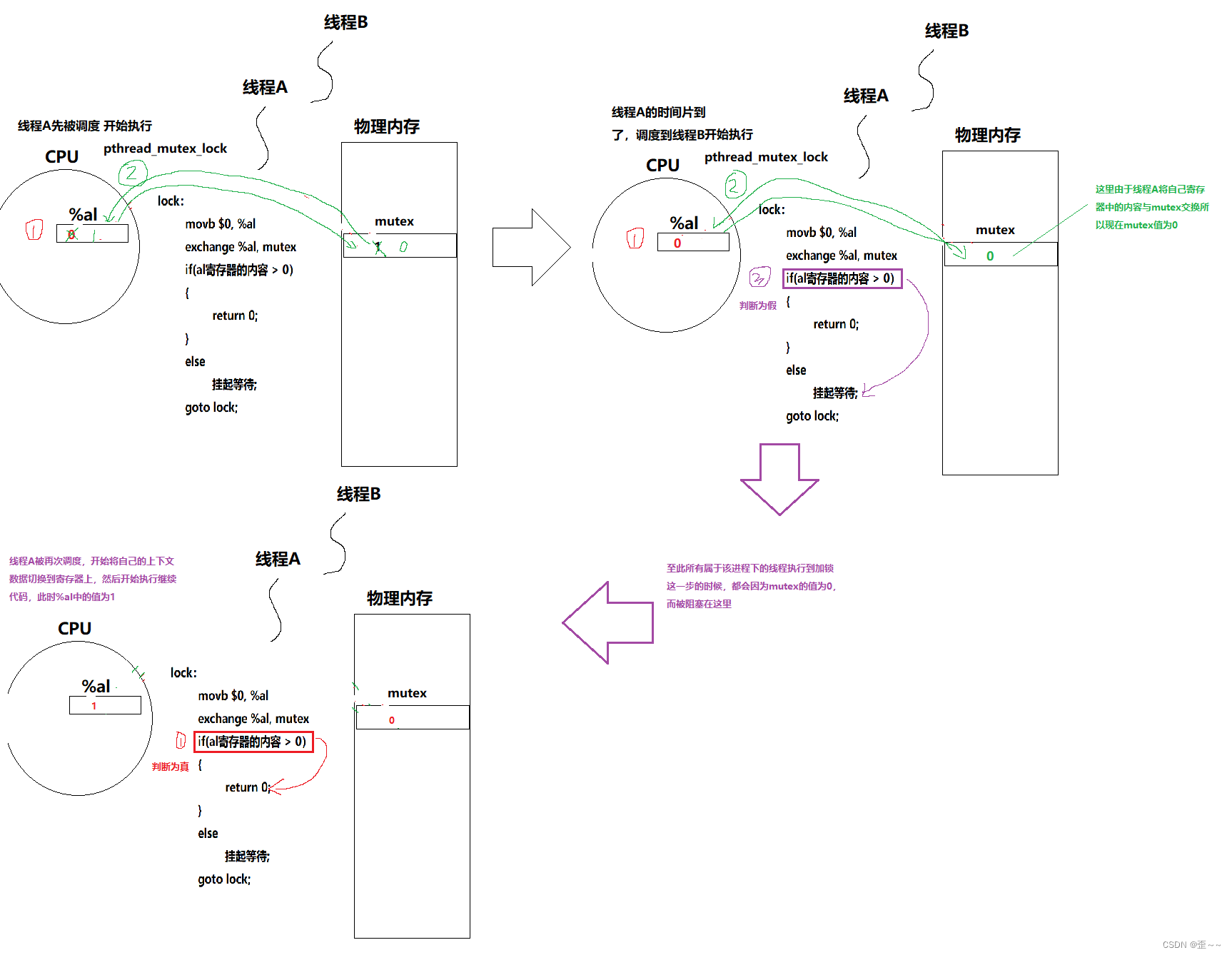
从这其中的过程中,只要在进行exchange交换时mutex的值为1,当执行完成这条指令之后,其实这个线程的锁就已经相当于上好了,所以上锁的过程关键只看这一步之后,属于线程的上下文中%al中的内容是1时,该线程就已将相当于申请到锁资源了。而这句指令又是原子的,所以上锁的过程也就是原子的。
我们现在也可以重新理解一下:上锁的本质其实就是,将共享的mutex资源换入到自己的寄存器中,成为线程独有的资源。
而关于解锁,其实就很简单了,因为解锁的执行首先就意味着该线程有锁,既然有锁,那么解锁是不是原子的也无所谓了,反正任意时刻只能由一个执行流上同一把锁,这里给出解锁的伪代码:

而关于我们加锁的原则就是:谁加的锁,谁来解。5. 互斥导致的问题,同步的提出
经过上面的介绍,我们知道在多执行流并发访问共享资源的情况下可以通过对访问共享资源的代码也就是临界区加锁形成互斥的情况从而防止出现数据不一致的线程不安全问题。但是单单的互斥也会出现问题,在有些操作系统下,执行上述的抢票代码会出现只有一个执行流一直能申请到锁的资源,而其它执行流一直被阻塞,直到进程结束:
这种现象是可能出现的,比如其中的一个执行流的优先级比较高,每次调度时都是优先调度它,那么每次它都能够申请到锁资源,其他线程一直被阻塞,票都让该线程抢走了。
而其他一直被阻塞的线程,我们称这些线程为饥饿线程。这种问题也叫做饥饿问题。
而解决这种问题也很简单(想到很简单,但是理解同步不简单),那就是让线程的执行具有一定的顺序性,而这就是同步,关于同步的话题,我会在之后进行讲述。 -
相关阅读:
vue+mapbox通过地图图层属性进行区划颜色填充(工作笔记,不能直接复制使用,需要自行调整部分代码)
PFC232-SOP8/14/16应广一级可带烧录程序编带
jsp课程设计管理系统Myeclipse开发mysql数据库web结构java编程计算机网页项目
源码部署lamt架构
keil5debug无法进行调试
c++ qt五子棋联网对战游戏
无头单向非循环链表
5V*0.5A低压降二极管芯片 CH213
深入了解 Axios 的 put 请求:使用技巧与最佳实践
【RocketMQ 一】MQ概述
- 原文地址:https://blog.csdn.net/weixin_74074953/article/details/136629770
