-
PaddlePaddle----基于paddlehub的OCR识别
Paddlehub介绍
PaddleHub是一个基于PaddlePaddle深度学习框架开发的预训练模型库和工具集,提供了丰富的功能和模型,包括但不限于以下几种:
1.文本相关功能:包括文本分类、情感分析、文本生成、文本相似度计算等预训练模型和工具。
2.图像相关功能:包括图像分类、目标检测、人脸识别、图像生成等任务的预训练模型和工具。
3.视频相关功能:包括视频分类、视频目标检测、视频行为识别等任务的预训练模型和工具。
4.语音相关功能:包括语音识别、语音合成、语音情感分析等任务的预训练模型和工具。
5.推荐系统相关功能:包括推荐模型、召回模型等预训练模型和工具。
6.自然语言处理相关功能:包括词向量、句向量、文本匹配、关键词提取等预训练模型和工具。
7.多模态相关功能:包括图文匹配、文图生成等多模态任务的预训练模型和工具。
除了以上列举的功能外,PaddleHub还提供了模型管理、模型训练、模型部署等功能,方便用户快速部署和使用深度学习模型。用户可以通过PaddleHub轻松实现各种深度学习任务,加速模型开发和部署过程。
Paddlehub的OCR环境搭建
搭建环境的时候有两点需要注意:
- paddlepaddle和paddlehub的版本要匹配起来
- 需要安装隐形的依赖库(如下)
- #需要将PaddleHub和PaddlePaddle统一升级到2.0版本
- !pip install paddlehub==2.0.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
- !pip install paddlepaddle==2.0.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
- #该Module依赖于第三方库shapely、pyclipper,使用该Module之前,请先安装shapely、pyclipper
- !pip install shapely -i https://pypi.tuna.tsinghua.edu.cn/simple
- !pip install pyclipper -i https://pypi.tuna.tsinghua.edu.cn/simple
这里我介绍一下我本机电脑的相关环境:
系统:windows10 企业版(无独立显卡)
编译器:python 3.6.8(X64)
依赖包:
numpy 1.16.4
pandas 0.21.1
scipy 1.2.2
opencv-python 3.4.2.16
paddlepaddle 1.8.4
paddlehub 1.8.2
Shapely 1.7.1
pyclipper 1.2.0
OCR介绍
光学字符识别(Optical Character Recognition, OCR)是指对文本材料的图像文件进行分析识别处理,以获取文字和版本信息的过程。也就是说将图象中的文字进行识别,并返回文本形式的内容。例如(该预测效果基于PaddleHub一键OCR中文识别效果展示):


识别网络图如下:
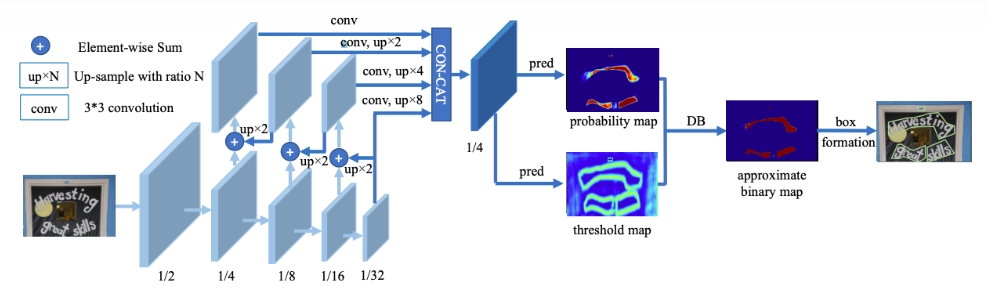 典型的OCR技术路线如下图所示:
典型的OCR技术路线如下图所示: 其中OCR识别的关键路径在于文字检测和文本识别部分,这也是深度学习技术可以充分发挥功效的地方。PaddleHub为大家开源的预训练模型的网络结构是Differentiable Binarization+ CRNN,基于icdar2015数据集下进行的训练。
其中OCR识别的关键路径在于文字检测和文本识别部分,这也是深度学习技术可以充分发挥功效的地方。PaddleHub为大家开源的预训练模型的网络结构是Differentiable Binarization+ CRNN,基于icdar2015数据集下进行的训练。环境测试
下面用一段简单的代码来测试一下环境是否安装成功,该代码段功能主要是来检测图像中的文字区域,需要注意的是,你应该提前准备好一张图片“fp.png”和代码在同一个目录中。
- import paddlehub as hub
- import cv2
- text_detector = hub.Module(name="chinese_text_detection_db_server")
- result = text_detector.detect_text(images=[cv2.imread('fp.png')])
- print(result)
输出:

提示: 第一次运行的时候需要联网下载相应的模型,否则会报错。我的因为模型下载完毕,所以提示无需安装。
OCR识别
- # -*- coding = 'utf-8' -*-
- # 测试OCR安装环境
- import paddlehub as hub
- import cv2
- import time
- file = r'fp.png'
- t1 = time.time()
- #ocr = hub.Module(name="chinese_ocr_db_crnn_server")
- ocr = hub.Module(name="chinese_ocr_db_crnn_mobile")
- result_list = []
- image = cv2.imread(file)
- #print(image)
- #image = image[440:550,170:290]
- #image = cv2.resize(image,[300,300])
- #cv2.imwrite('./2.jpg', image)
- t2 = time.time()
- results = ocr.recognize_text(
- images=[image], # 图片数据,ndarray.shape 为 [H, W, C],BGR格式;
- use_gpu=False, # 是否使用 GPU;若使用GPU,请先设置CUDA_VISIBLE_DEVICES环境变量
- visualization=True, # 是否将识别结果保存为图片文件;
- box_thresh=0.5, # 检测文本框置信度的阈值;
- text_thresh=0.5) # 识别中文文本置信度的阈值;
- for result in results:
- data = result['data']
- for index, infomation in enumerate(data):
- result_list.append(infomation['text'])
- #print(result_list)
- t3 = time.time()
- print(results, t2-t1,t3-t2)

-
相关阅读:
【VUE复习·4】计算属性computed:原理、完整写法(不常用)、与 methods 的区别、简写(最常用)、应用案例!
C++学习笔记——链表基础算法
android dex 优化
如何让电脑同时远程控制5台手机?
React-hooks
Node.js躬行记(25)——Web自动化测试
JVM的运行时数据区
Python中判断两个集合是否相交的方法 - isdisjoint()
shell脚本中的条件测试和条件语法
【智能电网随机调度】智能电网的双层模型时间尺度随机优化调度(Matlab代码实现)
- 原文地址:https://blog.csdn.net/mzl_18353516147/article/details/136506525
