-
总结Redis的原理
一、为什么要使用Redis
- 缓解数据库访问压力
- mysql读请求进行
磁盘I/O速度慢,给数据库加Redis缓存(参考CPU缓存),将数据缓存在内存中,省略了I/O操作
二、Redis数据管理
2.1 redis数据的删除
定时删除+惰性删除+内存淘汰
问题1:内存也是有空间限制的
方案1:加超时时间
问题2:超时数据量大,无法一次性删除
方案2:随机算法删除(惰性删除)
问题3:有些超时数据运气好,一直没有被随机匹配到
方案3:在查询时判断是否过期,确认为过期的数据被动式触发删除
问题4:没有被随机删除也没有被查询的数据越来越多
方案4:内存淘汰策略

2.2 特殊缓存处理
缓存穿透:查询
不存在的数据方案:缓存空结果null+过期时间
缓存雪崩:大量缓存
同时失效(大量不同的请求打到数据库)方案:原有失效时间上增加随机值,即过期时间均匀分布+热点数据永不过期
缓存击穿:超
高并发访问一个正好失效的Key(大量相同的请求打到数据库)方案:加锁(用户出现大并发访问的时候,在查询缓存的时候和查询数据库的过程加锁,只能第一个进来的请求进行执行,当第一个请求把该数据放进缓存中,接下来的访问就会直接集中缓存)
热点数据永不过期,不设置热点key的失效时间2.3 热点key
热key:在极短的时间内访问频次非常高的key
2.3.1 如何定位热点key?
提前预测
- 凭业务经验
实时收集
- 独立的热key检测系统:将该SDK引入到应用系统
- 客户端收集:Redis服务器有专门的客户端工具SDK(Redisson),可以对其进行改写封装(理解:二次开发,缺点:代码有入侵性,维护成本高,存在语言异构和版本升级问题),在发送请求前进行收集采集,并上报到统一的服务进行聚合计算。
- 代理层收集:如果Redis的请求都经过代理的话,考虑改写proxy代码收集
- Redis定时扫描:使用Redis的自带命令-Hotkeys参数
- Redis节点抓包:通过tcpdump抓取一段时间内的流量并上报,然后由一个外部的程序去解析并计算(缺点:流量高时抓包数据量过大,负担大)
2.3.2 解决方案
-
本地缓存(guava cache或caffeine)
发现热点key后将其加载到JVM中,不用到DB或Redis中查询
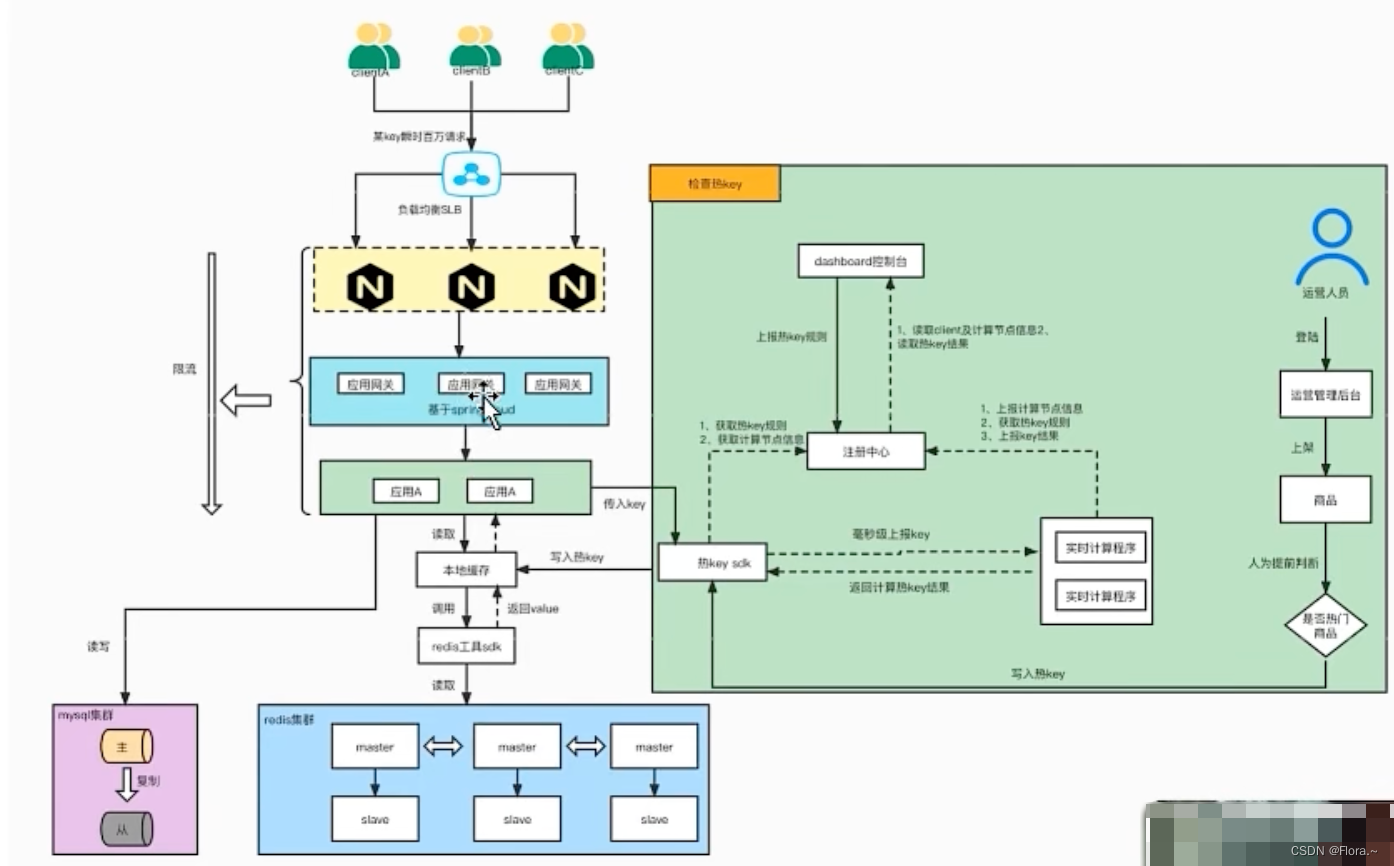
理解:
1 请求访问热点key,先经过负载均衡器,到达Nginx集群,
2 再由Nginx通过负载均衡到达应用网关,
3 网关转发到后端微服务,
4 准备热key检测系统- 1 管理后台dashboard:管理热key的规则,如userId,活动id,以及可视化。
- 2 注册中心:管理分布式服务集群。
- 3 实时计算程序:根据前端传来的key。
- 4 SDK:用于接入外部系统。
- 由注册中心将这4块进行连接互通
5 计算得到的
热key通过SDK传入系统并写入本地缓存,
6 请求访问本地缓存,如果存在热点key,则读取Redis并写入本地缓存,
7 此时,前端再次访问时就可以直接从本地缓存拿到数据 -
冗余存储备份key
设计思想:将热key分成不同的小key(比如key拼接节点ID),存储在不同的Redis节点上,降低数据的倾斜,通过小key分流,分散请求到Redis节点,
将热点key拼接节点ID,去当前访问的Redis判断是否有值,如果没有则读取数据库,存入Redis并返回数据 -
限流熔断(兜底方案)
限流(Nginx-集成lua脚本插件、网关、微服务-hystrix或sentinel对服务接口限流)
三、Redis为什么这么快
- Redis基于
内存,内存的访问速度是磁盘的上千倍 - Redis内置了多种优化后的
数据结构实现,性能高 - Redis基于reactor模式开发了一套高效的
事件处理模型(单线程事件循环,IO多路复用,类似netty网络通信)
四、Redis的备份机制
Redis数据持久化
- RDB:在指定的时间间隔内生成数据集的时间点
快照(理解:数据备份,不同时间段的数据都放在一个RDB文件中)
问题:数据丢失。如果 Redis 宕机,那么服务器将丢失最近写入、且仍未保存到快照中的那些数据。 - AOF:(append-only file,追加操作的文件)记录服务器执行的所有
写操作命令(理解:参考了MySQL的Binlog日志),命令会暂存在Redis的aof_buf中,从缓存中写入AOF。
在服务器启动时,通过重新执行这些命令来还原数据集
问题1:命令多
方案1:指令合并
问题2:耗时间
方案2:fork出子进程进行处理指令合并
问题3:子进程在重写期间,如果进行了数据修改,就会出现数据不一致,
方案3:aof_rewrite_buf,从fork子进程起后面写入的命令也copy到重写缓存区,等子线程重写结束,将重写缓存区的命令写入AOF
五、Redis主从同步
主节点负责写,从节点负责读- 当从节点宕机时,主节点发送RDB文件给从节点进行
数据同步 - 为了进行快速同步,主节点中设置
缓存区,并设置复制偏移量(目的:确认缺失的信息范围)
六、Redis哨兵机制
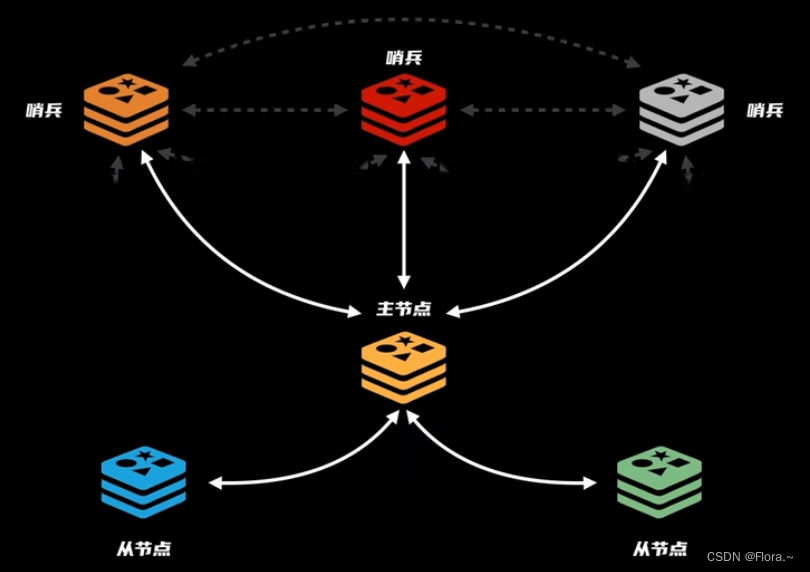
解决:
主节点宕机问题,实现高可用sentinel哨兵负责统筹协调,监控主节点(定时去确认其响应能力)- 哨兵集群(规定数量认定主节点客观下线)
- 故障转移:选择新的主节点(规则:复制偏移量最大的节点),主节点进行数据同步,将原主节点改为从节点
七、Redis集群
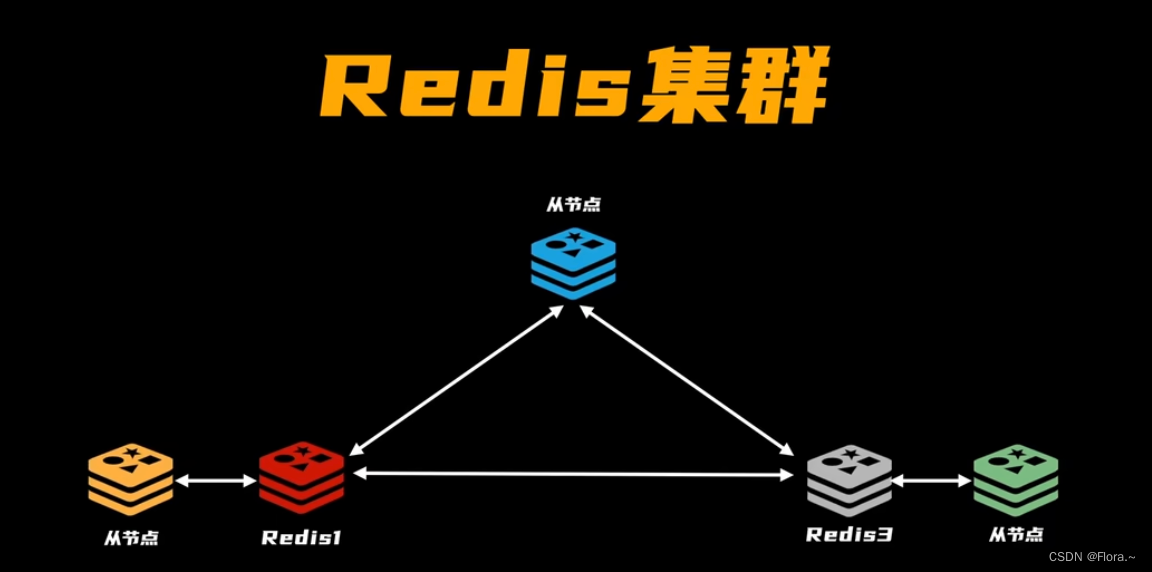
加入集群:需要和其中一个Redis(IP+端口)建立联系(类似TCP三次握手),Redis原集群内部进行同步确认
数据存储任务分配:槽位slot(类似哈希表),内存空间大的占更多的槽位。
信息同步:redis节点之间要同步自己所负责的槽位信息
问题1:数据量大,
方案1:每个槽位用1bit表示,自己负责的为1,不负责的为0
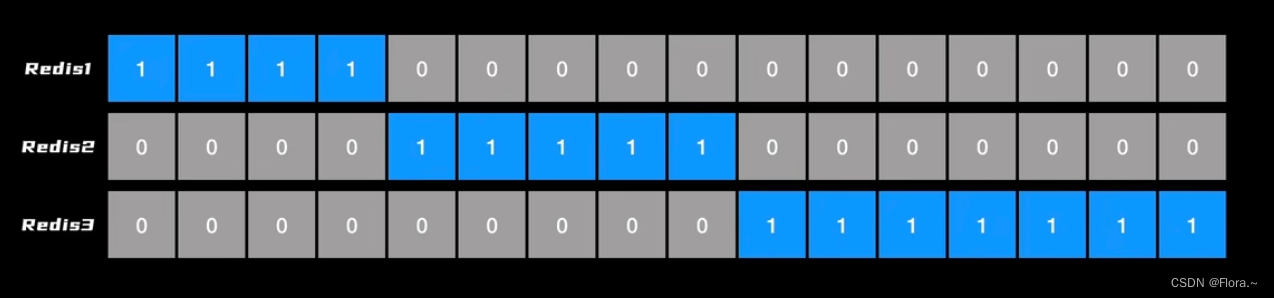
问题2:定位节点麻烦
方案2:用一个超大的数组存储每个槽位,空间换时间struct clusterNode *slots[16384/8];- 1
集群工作:
确认请求的位置是不是自己负责,如果不是则返回一个moved错误给请求端,同时发出对应的负责节点的IP和端口 -
相关阅读:
Java之JDBC
基于Django搭建服务器平台的投票应用
【FreeRTOS】15 空闲任务(实例:CPU利用率统计)
2024快手校招面试真题汇总及其解答(一)
BSV 上用于通用计算的隐私非交互式赏金
移动Web第一天 1 字体图标 && 2 平面转换 && 3 渐变
Centos7挂载磁盘(笔记)
vue3+ts+element-plus实际开发之统一掉用弹窗封装
开源模型应用落地-LangChain高阶-事件回调-合规校验
接入电商数据平台官方开放平台API接口获取商品实时信息数据,销量,评论,详情页演示
- 原文地址:https://blog.csdn.net/weixin_40497710/article/details/136515428