前言:
每次你在游戏中看到玩家排行榜,或者在音乐应用中浏览热门歌单,有没有想过这个排行榜是如何做到实时更新的?当然,依靠 Redis 即可做到。
在技术领域,我们经常听到「键值存储」 这个词。但在 Redis 的世界里,这只是冰山一角。Redis 的对象,不仅仅是简单的数据,它们是为各种任务量身定制的超能工具。
接下来,让我们走进 Redis 的对象世界,Redis 5.0版本就已经支持了下面的 9 种类型,分别是 :字符串对象、列表对象、哈希对象、集合对象、有序集合对象、Bitmaps 对象、HyperLogLog 对象、Geospatial 对象、Stream对象。

Redis 对象:
首先,我们要知道,Redis 中保存的数据是以键值对的形式存在的。
对象的类型与编码
类型
在 Redis 的大家庭中,每个键值对都有两个重要的“身份证”。那就是键的类型和值的类型。就好像我们的名字和职业,其中名字(键)总是一个字符串,而职业(值)则可以是各种各样:可以是字符串、列表、哈希、集合,甚至是有序集合。这就是我们所说的对象类型,五彩斑斓,各有特色。
编码
我们都知道超级英雄有着不同的超能力,蜘蛛侠(Spider-Man) 有蜘蛛感应,钢铁侠(Iron Man)有高科技装备。同样,Redis 中的每个对象都有一种称为“编码”的隐藏能力。这是什么呢?
简单说,编码是对象的“内部魔法”。它决定了对象在 Redis 内部的存储方式。就好像手机里的照片可以是 JPEG 或 PNG 格式,Redis 对象也可以有不同的编码格式。
但为什么这很重要呢?因为不同的编码方式意味着不同的存储效率和性能。Redis 非常聪明,它会选择最佳的编码方式,为我们节省空间和提高性能。
我们先来看下 Redis 对象结构体声明
typedef struct redisObject {
unsigned type:4; # 数据类型,使用了4位来表示
unsigned encoding:4; # 编码方式
void *ptr; # 指向底层数据结构的指针
} robj;
Redis 中的每个对象都是由 redisObject 结构表示,其中的 encoding 成员记录了对象所使用的编码,encoding 的取值不同,对象内部使用的数据结构也会有所不同。关于 redis 对象的各个数据结构的讲解,本篇不涉及,后续会补上。
分类
字符串对象
基本概念:
字符串对象是最简单的类型,也是二进制安全的,意味着可以存储任何形式的数据,例如 JPEG 图片、序列化的对象或者纯文本。
简单图解:

value 可以存储任何类型的数据:包括普通字符串,数值类型(int,float) 等
内部实现
Redis 的 String 对象使用一种称为 简单动态字符串SDS(Simple Dynamic String) 的结构来存储数据。
对象结构体声明:
typedef struct redisObject {
unsigned type:4; # 数据类型,使用了4位来表示
unsigned encoding:4; # 编码方式
void *ptr; # 指向底层数据结构的指针
} robj;
SDS 结构体声明:
struct sdshdr {
size_t len; # 记录buf数组中已使用字节的数量。
size_t alloc; # 记录buf数组的总容量。
char buf[]; # 字节数组,用于保存字符串。
};
String 对象的编码
String 对象的编码有三种: int、embstr、raw 。
- int 编码 :对象 robj 的 ptr 成员指向的是 long 类型的整数
- embstr 和 raw 编码 : 对象 robj 的 ptr 成员指向的是 sdshdr 结构体,值存储在 buf 中。
使用限制: 单个 String 对象的值可以存储的数据大小上限为 512MB
常见命令:
基本操作
SET key value : 设置键的值
GET key : 获取键的值
DEL key : 删除键
> SET username "xiaokang"
OK
> GET username
"xiaokang"
> DEL username
(integer) 1
字符串操作
APPEND key value : 向字符串尾部追加
STRLEN key : 获取字符串的长度
SETRANGE key offset value : 覆盖部分内容
GETRANGE key start end : 获取子字符串
# 上面命令的参数 offset、start、end 都指的是下标(从0开始)
# 初始键值对 : SET username "xiaokang"
> APPEND username 1998
(integer) 12
> GET username
"xiaokang1998"
> STRLEN username
(integer) 12
> SETRANGE username 0 kang
(integer) 12
> GET username
"kangkang1998"
> GETRANGE username 8 -1 # -1代表的是值的结尾
"1998"
数值操作
INCR/DECY key : 自增1或自减1
INCRBY/DECRBY key increment : 自增或自减整数,步长为 increment 必须为整数,可正可负
INCRBYFLOAT key increment : 自增、自减浮点数,increment 推荐使用浮点数,代表你是在操作浮点数,可正可负
# redis 中没有提供 DECRBYFLOAT,所以要想递减浮点数,increment 为负即可
> set count 2
OK
> INCR count
(integer) 3
> DECR count
(integer) 2
127.0.0.1:6379> INCRBY count 3
(integer) 5
127.0.0.1:6379> DECRBY count 3
(integer) 2
> SET float_count 5.5
OK
> INCRBYFLOAT float_count 2.5
"8"
> INCRBYFLOAT float_count -3.5
"4.5"
批量操作
MSET key1 value1 key2 value2 : 批量设置键值
MGET key1 key2 : 批量获取键值
> MSET username xiaokang age 25
OK
> GET username
"xiaokang"
> MGET username age
1) "xiaokang"
2) "25"
条件设置
SETNX key value : 仅当键不存在时设置值,键存在则不会执行任何操作
MSETNX key value [key value ...] : 批量设置
> SETNX career programmer
(integer) 1
> MSETNX sex man hobby swim
(integer) 1
带有过期时间的设置
SETEX key seconds value : 为键值设置过期时间
# 10s 后 redis 会自动删除这个 key
> SETEX username 10 xiaokang
OK
应用案例
计数器
描述: 利用 Redis 追踪某些事物的数量。
具体应用 :
1. 文章访问计数:文章的阅读次数
#当某篇文章被访问时,递增该文章的阅读计数器。
INCR article:12345:views
#获取某篇文章的阅读次数。
GET article:12345:views
2. 社交媒体互动计数 :点赞数
#当某个帖子被点赞时,递增该帖子的点赞计数器。
INCR post:67890:likes
#检查某个帖子的点赞数。
GET post:67890:likes
3. 实时统计 :例如,一个电商网站可以使用 Redis 来跟踪网站上当前的在线用户数量
#当用户在线时,递增在线用户计数器。
INCR website:online_users
#检查当前在线的用户数量。
GET website:online_users
4. 限流: 例如,你可能想限制一个 API 在一定时间内的调用次数。
# 设置一个 API 的调用次数限制。这里以 60 秒内最多调用 10 次为例。
SETEX api:call_limit:client_ip 60 10
# 当 API 被调用时,递减调用计数器。如果值小于或等于 0,则表示已达到限流。
DECRBY api:call_limit:client_ip 1
# 检查某个 API 的剩余调用次数。
GET api:call_limit:client_ip
分布式锁 : 超越传统的锁机制
想象一下,一个电商网站正在进行一次秒杀活动,该活动只有100个商品库存。当活动开始时,数万用户同时尝试购买这些商品。
如果秒杀系统只部署在一个服务器上,那么我们可以使用普通锁来保证库存不会被超卖。但是,现在的大型电商平台的抢购系统都是部署在多个服务器上的,所以单个服务器上的普通锁并不能保证整个系统的数据一致性。
这时候,我们需要一个更强大的锁:分布式锁, 那什么是分布式锁呢? 分布式锁,顾名思义,是能在多个系统或多台机器之间都起到限制访问的“锁”。
在秒杀活动这个场景中,分布式锁确保了即便是数万用户在多个服务器上同时尝试购买,系统也能正确、有序地处理每一个购买请求,确保不会出现超卖的情况。
基本概念:
分布式锁是一种能够在多个计算机、服务器或节点之间确保任何时候只有一个进程在执行的机制。它是在复杂的分布式环境中维持顺序和一致性的关键工具。
实现方式:
使用 Redis 实现分布式锁一般步骤:
- 加锁:SET lock_key unique_id EX expire_time NX
- lock_key : 分布式锁名
- unique_id : 唯一标识符
- EX : 设置过期时间
- NX : 当 lock_key 不存在时命令才会成功
- 操作共享资源
- 释放锁:通过 Lua 脚本来释放锁,先 GET 判断锁是否归属自己,再 DEL 释放锁
Lua 脚本 : 用来保证释放锁操作的原子性
判断锁是自己的,才释放
if redis.call("GET",KEYS[1]) == ARGV[1]
then
return redis.call("DEL",KEYS[1])
else
return 0
end
上面实现方式存在一个问题:分布式锁的过期时间如何确定?
如果客户端预期的操作时间超过锁的过期时间,这该怎么办? 锁的超时时间设置过长过短都不好。一个合理的方案就是采用自动续期。
续期具体做法:
加锁时,我们设定一个到期时间,启动一个「守护线程」 定时查看锁的状态。如果锁即将到期且任务未完成,我们自动「续期」 这个锁,重新设置其到期时间。如果续期失败,为避免并发问题,客户端应立刻停止操作。
然而幸运的是,一些编程语言已经实现了专门的客户端库,如 Java 的 Redisson和 Go 的 redsync,它们提供了简化的分布式锁实现。这些库已内置了自动续期等关键功能,避免开发者手动构建这些逻辑。
注意:
以上只是实现了一个单机版的分布式锁,而 Redis 在实际生产环境中都会采用主从集群 + 哨兵的模式部署,这样当主库异常宕机时,哨兵可以实现「故障自动切换」,把从库提升为主库,继续提供服务,以此保证可用性。
我们来考虑一个问题:当「主从发生切换」时,这个分布锁会依旧安全吗?
关于这个问题我这里不做深入探讨,感兴趣的可以参考这篇文章:「链接地址在文章末尾」
缓存
描述:利用 Redis 缓存 MYSQL 等关系型数据库查询结果,从而减少关系型数据库的压力。
具体实现:
当用户请求某个数据时,首先检查 Redis 是否有这个数据。如果有,直接从 Redis 返回,这样可以避免查询数据库。如果 Redis 中没有,那么查询关系型数据库,获取数据后,存入 Redis,并设置一个适当的过期时间。
简单示例
func getUserInfo(rdb *redis.Client, userID string) string {
// 尝试从 Redis 中获取用户信息
val, err := rdb.Get(ctx, userID).Result()
if err == redis.nil{
userData := queryDatabase(userID) #在这里模拟一个数据库查询
rdb.Set(ctx, userID, userData, time.Hour) # 缓存结果1小时
return userData
}
return val
}
func queryDatabase(userID string) string {
//查询数据库
// ...
return result
}
Session 存储
Session 是什么:
每次你在网上购物时,在浏览、选择商品、加入购物车,网站都能“记得”你的选择,这是因为它使用了"Session"。简单来说,Session 是服务器给你的一个小“记忆空间”。
在日常的网页浏览中,每当一个用户的请求到达服务器,例如页面访问、API调用,为了维持用户状态或提供个性化的服务,系统通常需要读取该用户的 session 数据。
具体实现:
当用户登录到一个系统时,后端通常会为该用户生成一个唯一的 session ID 。这个 ID 会被传回给客户端,通常存储在 cookie 中。随后,每次客户端发出请求时,都会携带这个 session ID,允许服务器识别出该用户。
为了应对这种频繁的数据读取需求,我们可以将这个 session ID 和 session 数据分别作为键值存储到 redis 中。 session 数据包括 : 用户 ID、用户名等。使用 Redis 来存储 session 数据不仅提供了高速的读取效率,还让用户体验更为流畅。
使用示例:
# 在设置 session 存储时,一般会设置过期时间的。
SET session:userId expired_time "user_data_in_json_or_serialized_format"
GET session:userId
列表对象
基本概念
Redis 的列表对象是一个有序的字符串集合,这里的有序指的是添加元素有先后顺序的,可以被看作是一个双向链表。在 Redis 中,每个列表可以包含超过 4 亿个元素。
简单图解
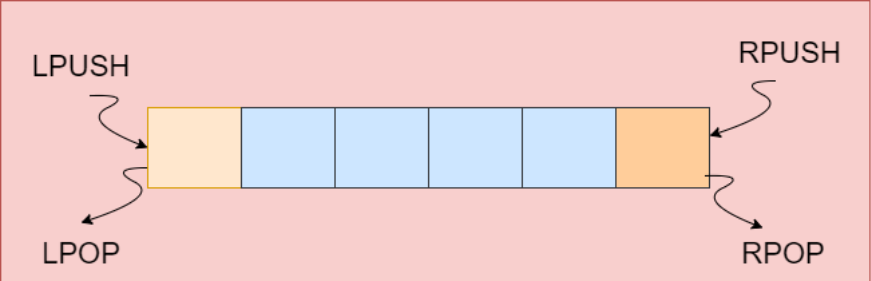
内部实现
- 压缩列表 (Ziplist): 当列表对象保存的所有字符串元素的长度都小于 64 字节并且列表对象保存的元素数量小于 512 个,列表对象会使用压缩列表(ziplist)作为其底层实现。
- 双向链表(Linkedlist):不满足上述两个条件之一的, 列表对象会使用双向链表(Linkedlist) 作为其底层实现。
常见命令:
查找元素
LRANGE key start stop : 获取列表指定范围内的元素
LINDEX key index : 通过索引获取列表中的元素
LLEN key : 返回列表的长度
# 查看列表对象的所有元素,-1 代表列表对象的最后一个元素
> LRANGE myList 0 -1
1) "grape"
2) "banana"
3) "apple"
4) "orange"
> LINDEX myList 1
"banana"
> LLEN myList
(integer) 4
插入元素 :
- 普通插入
LPUSH key element [element ...] : 将一个或多个值插入到列表头部
RPUSH key element [element ...] : 将一个或多个值插入到列表尾部
> LPUSH myList "apple" "banana"
(integer) 2
> LRANGE myList 0 -1
1) "banana"
2) "apple"
> RPUSH myList "orange" "pear"
(integer) 4
> LRANGE myList 0 -1
1) "banana"
2) "apple"
3) "orange"
4) "pear"
- 条件插入
LPUSHX key element [element ...] : 只有当列表存在时,将值插入到列表的头部,如果列表不存在,则什么也不做
RPUSHX key element [element ...] : 只有当列表存在时,将值插入到列表的尾部,如果列表不存在,则什么也不做
> LPUSHX myList "grape"
(integer) 5
> LRANGE myList 0 -1
1) "grape"
2) "banana"
3) "apple"
4) "orange"
5) "pear"
> LPUSHX noExistList "peach"
(integer) 0
删除元素:
LPOP key [count] : 移除并返回列表的前 count 个元素
RPOP key [count] : 移除并返回列表的最后 count 个元素
LREM key count value : 移除列表中与参数 value 相等的 count 个元素
# 先查看列表中的元素
> LRANGE myList 0 -1
1) "grape"
2) "banana"
3) "apple"
4) "orange"
5) "pear"
> LPOP myList
"grape"
> LRANGE myList 0 -1
1) "banana"
2) "apple"
3) "orange"
4) "pear"
> RPOP myList
"pear"
> LRANGE myList 0 -1
1) "banana"
2) "apple"
3) "orange"
修改元素:
LSET key index value : 通过索引来设置元素的值
LTRIM key start stop :裁剪列表
# 先查看列表中的元素
> LRANGE myList 0 -1
1) "grape"
2) "banana"
3) "apple"
4) "orange"
> LSET myList 0 "peach"
OK
> LRANGE myList 0 -1
1) "peach"
2) "banana"
3) "apple"
4) "orange"
> LTRIM myList 0 2
OK
> LRANGE myList 0 -1
1) "peach"
2) "banana"
3) "apple"
元素转移:
RPOPLPUSH source destination: 将 source 列表的最后一个元素弹出,并将该元素添加到 destination 列表的头部,同时返回该元素,如果 destination 列表不存在,redis 会自动创建 destination 列表
> LRANGE myList 0 -1
1) "banana"
2) "apple"
> RPOPLPUSH myList destList
"apple"
> LRANGE destList 0 -1
1) "apple"
要注意的是列表对象并不存在 LPOPRPUSH 命令,可以通过组合 LPOP 和 RPUSH 命令来实现类似效果。
阻塞操作:
BLPOP key [key ...] timeout : 移除并获取列表的第一个元素,或阻塞直到有一个可用
BRPOP key [key ...] timeout : 移除并获取列表的最后一个元素,或阻塞直到有一个可用
BRPOPLPUSH source destination timeout : 将 source 列表的最后一个元素弹出,并将该元素添加到 destination 列表的头部,同时返回该元素
# 先查看列表中的元素
> LRANGE myList 0 -1
1) "peach"
2) "banana"
3) "apple"
4) "orange"
> LRANGE noExistList 0 -1
(empty array)
> BLPOP myList noExistList 10
1) "myList"
2) "peach"
> LRANGE myList 0 -1
1) "banana"
2) "apple"
3) "orange"
> BRPOP myList noExistList 10
1) "myList"
2) "orange"
# 先查看列表的初识元素
> LRANGE myList 0 -1
1) "banana"
> LRANGE destList 0 -1
1) "apple"
> BRPOPLPUSH myList destList 10
"banana"
> LRANGE myList 0 -1
(empty array)
> LRANGE destList 0 -1
1) "banana"
2) "apple"
应用案例:
1.消息队列 :
当用户在网上购物下订单后,为了不让他们等待各种后续处理(如检查库存、处理付款、发货),我们直接把订单放入一个消息队列,然后由后台进程从队列中获取并处理订单。
实现步骤:
1. 生产者(下订单的用户)
LPUSH orders_queue order_id
2. 消费者服务获取订单( 消费者:后台处理订单的服务)
BRPOP orders_queue 5
3. 处理订单 :
一旦消费者从队列中获取了一个新订单,它可以开始进行必要的处理,
例如检查库存、处理付款等。
2.栈和队列 :
栈: 想象一个浏览器的返回功能。用户访问了几个页面,你希望能够提供一个[返回] 按钮让用户回到他们之前浏览的页面。
实现步骤:
1. 添加元素
LPUSH browser_history "page1"
LPUSH browser_history "page2"
LPUSH browser_history "page3"
2.当用户点击返回按钮时:
LPOP browser_history # Fetches "page3", the most recently visited
队列:
当我们在电商网站上浏览商品、点击广告或执行其他操作时,这些行为都可以被捕获为一个"事件"。每个事件通常都包含一些基本信息,如用户ID、商品ID、点击时间、页面URL等。
实现步骤:
- 用户点击事件捕获
假设一个用户点击了一个商品。此时,我们可以创建一个 JSON 对象来存储这次点击的详细信息。
$json = {
"user_id": "12345",
"product_id": "98765",
"timestamp": "2023-09-01T12:00:00Z",
"page_url": "/products/98765"
}
- 发送事件到队列
LPUSH click_events $json
- 消费者进程获取事件
RPOP click_events
当消费者进程从队列中获取事件后,可以进一步解析这个JSON对象,并进行所需的处理,例如更新商品的点击率等,以便将该商品推荐给更多的用户。
3.历史追踪:
可以使用 Redis 列表来跟踪最近的历史记录,例如最近访问的网页或其他活动。
以最近访问的网页举例说明: 在一个网站上,你可能希望追踪用户最近访问了哪些页面。每当用户访问一个新页面时,你可以使用 LPUSH 将这个页面 URL 添加到一个列表中,并使用 LTRIM 确保列表只保存最近 N 次访问。
LPUSH user_recent_pages "/home"
LPUSH user_recent_pages "/product/1"
LTRIM user_recent_pages 0 9 # 保留最近10个访问的页面
使用 Redis 列表来跟踪最近的历史记录能够高效地保存和查询用户的近期活动,从而为用户提供个性化的推荐。
哈希对象
基本概念
Redis 哈希对象也是一种用于存储键值对集合的数据结构,它允许你将多个键值对存储在一个 Redis 键中。
我们一般会使用 Redis 的 Hash 对象来存储对象信息,比如用户信息,用户的名字、年龄、爱好、电子邮箱、密码等。与使用普通的 key-value 存储方式相比 , 哈希对象的存储方式更为高效和节省空间,特别是当我们要存储大量小对象时。
简单图解:

简单说明:
假设你有一把大钥匙,这把钥匙可以打开一个特定的箱子。这箱子里面有很多物品,每个物品都有标签来描述它。
- 大钥匙 就是我们的 key
- 箱子 就代表一个 哈希对象
- 箱子里的物品与其标签 就是 field-value 键值对
内部实现
- 压缩列表(ziplist) : 当哈希对象保存的所有键值对的键和值的字符串长度都小于64字节并且哈希对象保存的键值对的数量小于 512 个,哈希对象会采用压缩列表作为其底层实现。
- 字典(基于哈希表实现) : 当不能满足上述条件之一时,哈希对象则会采用字典作为其底层实现。
常见命令
设置值
HSET key field value [field value ...] : 设置哈希的 Field-Value 对,可以设置多个
HSETNX key field value : 只有在字段 field 不存在时,才设置对应的 value 值,否则什么也不做。
> HSET userInfo username xiaokang age 25 hobby swim
(integer) 3
获取值
HGET key field : 获取哈希指定字段的值
HMGET key field [field ...] : 获取哈希多个字段的值 # 批量获取
HGETALL key : 获取哈希表中的所有字段和值
HKEYS key : 获取哈希中所有的字段名(field)
HVALS key : 获取哈希中所有的字段值(value)
> HGET userInfo username
"xiaokang"
> HMGET userInfo "username" "age"
1) "xiaokang"
2) "25"
> HGETALL userInfo
1) "username"
2) "xiaokang"
3) "age"
4) "25"
5) "hobby"
6) "swim"
> HKEYS userInfo
1) "username"
2) "age"
3) "hobby"
> HVALS userInfo
1) "xiaokang"
2) "25"
3) "swim"
自增操作
HINCRBY key field increment : 为哈希字段的整数值加上增量 # increment 可正可负
HINCRBYFLOAT key field increment : 为哈希字段的浮点数值加上增量 # increment 可正可负
> HGET userInfo age
"25"
> HINCRBY userInfo age 1
(integer) 26
> HGET userInfo age
"26"
# HINCRBYFLOAT 命令类似,increment 既可以是整数也可以是浮点数,可正可负
删除操作
HDEL key field [field ...] : 删除一个或多个哈希表字段
# 先查看 hash 字段的所有字段和值
> HGETALL userInfo
1) "username"
2) "xiaokang"
3) "age"
4) "25"
5) "hobby"
6) "swim"
> HDEL userInfo "hobby"
(integer) 1
> HGETALL userInfo
1) "username"
2) "xiaokang"
3) "age"
4) "25"
其他操作
HEXISTS key field : 检查哈希对象中是否存在给定的字段
HLEN key : 获取哈希中字段的数量
HSTRLEN key field : 获取哈希字段的字符串长度
# 先查看哈希的所有字段和值
> HGETALL userInfo
1) "username"
2) "xiaokang"
3) "age"
4) "25"
> HLEN userInfo
(integer) 2
> HSTRLEN userInfo "username"
(integer) 8
注意事项
- 小哈希优化: Redis 对于哈希对象的内存布局进行了优化。小哈希(即哈希对象字段数量很少且字段值大小较小)的内存使用会更加高效。
- 避免大量删除: 使用 HDEL 一次删除大量字段可能会影响性能,建议分批进行。
- 使用哈希而非多个键: 当需要存储有关特定对象的多个相关字段时,使用单个哈希键比使用多个独立的 Redis 键更为高效。
应用案例
- 对象存储 :
主要是指将某种实体或数据(如用户信息)持久性地保存在 Redis 中,如 :用户的用户名、邮箱、密码等信息。
保存用户信息:
HSET user:1234 name "John Doe" email "john.doe@example.com" age 30
获取用户的邮箱:
HGET user:1234 email
- 对象缓存:
这是指当数据原本存储在其他存储系统(如关系型数据库)中,但由于频繁访问或读取,我们决定在 Redis 中缓存该数据的一份副本,以减少对原始数据源的访问压力并提高读取速度。
场景描述:
假设你有一个博客网站,用户可以阅读和评论各种博客文章。每当用户点击一个博客标题,系统都会从关系型数据库中获取该文章的详细内容进行显示。但是,由于某些热门文章被大量用户频繁访问,直接从数据库中获取文章可能会对数据库造成很大的压力,从而影响网站的性能。
具体实现:
伪代码展示 :
import (
"github.com/go-redis/redis/v8"
"context"
)
var ctx = context.Background()
options := &redis.Options{
Addr: "localhost:6379", // Redis服务器地址
}
// 初始化Redis客户端:
rdb := redis.NewClient(options)
// 检查缓存:当用户请求一篇文章时,首先检查Redis缓存中是否存在该文章的数据。
exists, err := rdb.HExists(ctx, "article:ID", "title").Result()
if err != nil {
// Handle error
}
//从缓存中获取数据:如果文章存在于Redis中,则直接从Redis的哈希对象中获取所有相关字段,并显示给用户。
if exists {
articleData, err := rdb.HGetAll(ctx, "article:ID").Result()
if err != nil {
// Handle error
}
display(articleData)
}
//从数据库中获取数据:如果文章不在Redis缓存中,则从关系型数据库中获取数据保存到 Redis 缓存中,并且设置超时。
if !exists {
articleData := Database.fetchArticleByID("article:ID")
_, err := rdb.HMSet(ctx, "article:ID", map[string]interface{}{
"title": articleData.Title,
"author": articleData.Author,
"content": articleData.Content,
}).Result()
if err != nil {
// Handle error
}
rdb.Expire(ctx, "article:ID", time.Hour) // 设置1小时的过期时间
// 显示给用户
display(articleData)
}
//显示给用户的函数
func display(articleData map[string]string) {
// ... 你的显示逻辑
}
- 实时统计 :
为了跟踪网站的实时活动,我们可以使用哈希来保存当前在线用户、页面浏览量和API 请求次数等。
增加在线用户数:
HINCRBY website:stats online_users 1
减少在线用户数:
HINCRBY website:stats online_users -1
记录每个页面的访问次数:
HINCRBY pageviews:20230901 "/home" 1
集合对象
基本概念:
集合对象(Set)是一种存储多个唯一元素的无序集合数据结构,它提供了丰富的操作使得集合对象成为非常强大和灵活的工具。集合对象特别适用于存储不允许重复的数据项,例如标签、社交网络中的好友列表或者任何需要快速判断某个元素是否存在的场景。
简单图解
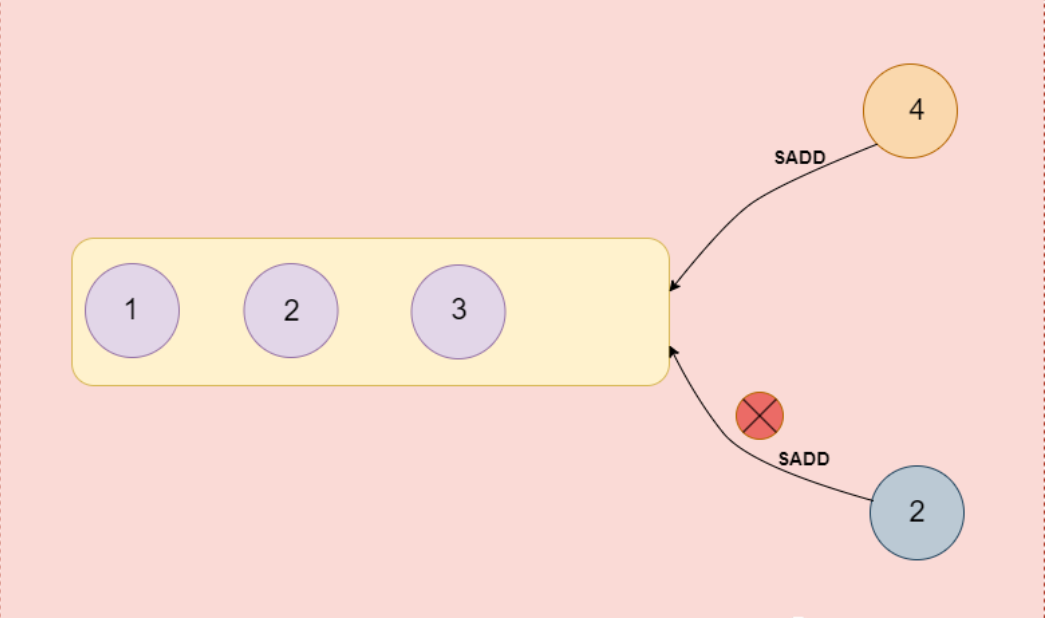
内部实现
- 整数集合(intset) : 当集合对象保存的所有元素都是整数或者集合对象保存的整数个数不超过512个时,集合对象采用 intset 作为其底层实现。
- 字典(基于哈希表实现): 不满足上面的两个条件之一,则采用字典作为其底层实现。
常见命令
基本操作:
SADD key member [member ...] :向集合添加一个或多个成员
SMEMBERS key :获取集合中的所有成员
SCARD key :获取集合的成员数量
SISMEMBER key member :判断 member 元素是否是集合 key 的成员
SREM key member [member ...] :移除集合中的一个或多个成员
> SADD mySet "apple" "banana" "peach"
(integer) 3
> SMEMBERS mySet
1) "peach"
2) "banana"
3) "apple"
> SCARD mySet
(integer) 3
> SISMEMBER mySet "peach" # 成员存在返回 1
(integer) 1
> SISMEMBER mySet "pear" # 成员不存在返回 0
(integer) 0
> SREM mySet "peach"
(integer) 1
> SMEMBERS mySet
1) "banana"
2) "apple"
集合运算:
SINTER key [key ...] :返回所有给定集合的交集
SINTERSTORE destination key [key ...] :交集存储在 destination 集合中
SUNION key [key ...] :返回所有给定集合的并集
SUNIONSTORE destination key [key ...] :并集存储在 destination 集合中
SDIFF key [key ...] :返回第一个集合与其他集合之间的差集
SDIFFSTORE destination key [key ...] :差集存储在 destination 集合中
> SMEMBERS mySet
1) "pear"
2) "banana"
3) "apple"
> SMEMBERS yourSet
1) "peach"
2) "banana"
3) "apple"
> SINTER mySet yourSet
1) "banana"
2) "apple"
> SINTERSTORE resultSet mySet yourSet
(integer) 2
> SMEMBERS resultSet
1) "banana"
2) "apple"
# 并集我这里不提了,和交集操作类似
> SDIFF mySet yourSet
1) "pear"
> SDIFFSTORE result mySet yourSet
(integer) 1
> SMEMBERS result
1) "pear"
随机操作:
SRANDMEMBER key [count] :随机返回集合中的一个或多个成员
SPOP key [count] :随机移除并返回集合中的一个或多个成员
> SMEMBERS mySet
1) "pear"
2) "banana"
3) "apple"
# 可以看到每次返回的成员都不一样
> SRANDMEMBER mySet
"pear"
> SRANDMEMBER mySet
"apple"
> SPOP mySet
"pear"
> SMEMBERS mySet
1) "banana"
2) "apple"
其他操作:
SMOVE source destination member : 将 member 成员从 source 集合移动到 destination 集合
> SMEMBERS mySet
1) "pear"
2) "banana"
3) "apple"
> SMEMBERS yourSet
1) "peach"
2) "banana"
3) "apple"
> SMOVE mySet yourSet "pear"
(integer) 1
> SMEMBERS mySet
1) "banana"
2) "apple"
> SMEMBERS yourSet
1) "peach"
2) "pear"
3) "banana"
4) "apple"
应用案例
- 社交网站的好友与关注系统
利用集合来存储每个用户的朋友或关注者列表。例如,我们可以为每个用户维护一个集合,其中包含他们的所有朋友或关注者。
SADD "alice:friends" "bob" # Alice 关注了 Bob
SADD "bob:friends" "charlie" # Bob 关注了 Charlie
SISMEMBER "alice:friends", "bob" # 判断 Bob 是否是 Alice 的朋友
- 标签系统
可以为内容(如文章、图片等)添加标签,并利用集合存储这些标签。
场景描述:假设你正在运行一个博客平台,你希望为每篇文章添加一组标签,使用户可以更容易地根据主题或兴趣查找相关文章。
1.为文章添加标签:
# 当你发布文章"Redis入门指南",其ID为1001,你为它添加了标签"technology", "tutorial",和"redis"。
SADD tag:technology 1001
SADD tag:tutorial 1001
SADD tag:redis 1001
2.查找具有特定标签的文章
# 如果用户想要查看所有与"redis"相关的文章:
SMEMBERS tag:redis # 输出 1001 :这表示文章ID为1001的文章带有"redis"标签。
3.获取文章的所有标签
# 每当你需要查看某篇文章的标签,你可以为其创建一个集合。以文章ID为1001为例:
SADD article:1001:tags "technology"
SADD article:1001:tags "tutorial"
SADD article:1001:tags "redis"
# 要查看文章1001的所有标签:
SMEMBERS article:1001:tags
# 输出:
1) "technology"
2) "tutorial"
3) "redis"
- 唯一计数
例如,记录网站的独立访客数。集合可以帮助我们做到这一点,因为它们只存储唯一的元素。
1.存储当天登录的所有用户ID:
SADD visitors:2023-09-20 user12345
SADD visitors:2023-09-20 user67890
2.获得当天登录的独立用户数
SCARD visitors:2023-09-20
有序集合对象
基本概念:
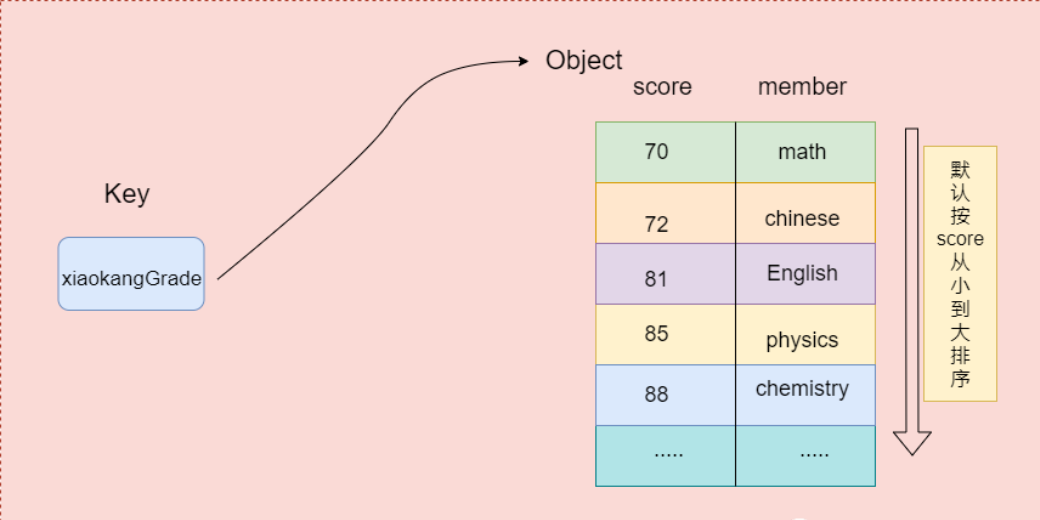
Redis 有序集合(Sorted Set)对象是一种存储非重复元素集合的数据结构,每个元素都关联一个双精度浮点数分数(score),用于维护元素之间的排序顺序。有序集合支持高效的元素插入和删除操作,同时保持元素按分数排序,使其非常适合于需要按照排序顺序访问元素的场景,如排行榜、带权重的任务队列等。
简单图解:
内部实现
- 压缩列表(ziplist): 当有序集合保存的元素数量小于 128 个 并且有序集合保存的所有元素成员的长度小于 64 字节,有序集合对象会采用 ziplist 作为其底层实现。
- 跳表(skiplist ):不满足以上2个条件之一的采用 skiplist 作为其底层实现。
常见命令
添加与更新成员
ZADD key score member [score member ...] : 添加一个或多个成员到有序集合,或者更新已存在成员的分数
ZINCRBY key increment member : 增加有序集合中指定成员的分数
> ZADD myZSet 10 member1 20 member2
(integer) 2
# 获取有序集合中的所有成员及其分数
> ZRANGE myZSet 0 -1 WITHSCORES
1) "member1"
2) "10"
3) "member2"
4) "20"
> ZINCRBY myZSet 5 "member1"
"15"
> ZRANGE myZSet 0 -1 WITHSCORES
1) "member1"
2) "15"
3) "member2"
4) "20"
查询操作
ZCARD key : 获取有序集合的成员数量
ZSCORE key member : 获取指定成员的分数值
ZRANK key member : 返回有序集合中指定成员的排名,排名依次是 0,1,2 ...
ZREVRANK key member : 返回有序集合中指定成员的排名,成员按分数值递减排列
> ZCARD myZSet
(integer) 2
> ZSCORE myZSet "member2"
"20"
> ZRANK myZSet "member1"
(integer) 0
> ZRANK myZSet "member2"
(integer) 1
> ZREVRANK myZSet "member2"
(integer) 0
> ZREVRANK myZSet "member1"
(integer) 1
ZRANGE key min max [WITHSCORES] : 返回有序集中指定区间内的成员 # min 和 max 是要获取的排名范围(排名可以理解为索引,从0开始,其中0是分数最低的成员),可选的 [WITHSCORES] 参数表示除了返回成员名外,还要返回它们的分数
ZREVRANGE key start stop [WITHSCORES] : 返回有序集中指定区间内的成员,成员按分数递减排列
> ZRANGE myZSet 0 1
1) "member1"
2) "member2"
> ZRANGE myZSet 0 1 WITHSCORES
1) "member1"
2) "15"
3) "member2"
4) "20"
> ZREVRANGE myZSet 0 1
1) "member2"
2) "member1"
> ZREVRANGE myZSet 0 1 WITHSCORES
1) "member2"
2) "20"
3) "member1"
4) "15"
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count] : 获取分数在指定区间的所有成员,建议:max >= min
ZREVRANGEBYSCORE key max min [WITHSCORES] [LIMIT offset count]: 获取分数在指定区间的所有成员,成员按分数递减排列; 建议:max >= min
#[LIMIT offset count] 这是一个限制返回的成员数量的可选项。其中,offset 是开始返回的起始位置(基于0的索引),count 是返回的成员总数。例如,LIMIT 1 3 会返回从下标为1开始的3个成员
> ZRANGEBYSCORE myZSet 16 22
1) "member2"
> ZRANGEBYSCORE myZSet 16 22 WITHSCORES
1) "member2"
2) "20"
> ZRANGEBYSCORE myZSet 15 22 WITHSCORES LIMIT 0 2
1) "member1"
2) "15"
3) "member2"
4) "20"
> ZREVRANGEBYSCORE myZSet 22 15 WITHSCORES
1) "member2"
2) "20"
3) "member1"
4) "15"
ZCOUNT key min max: 计算在有序集合中指定区间分数的成员数
ZLEXCOUNT key min max: 用于计算基于成员名称的字典序位于指定区间内的成员数量 # 对于 min和 max,要使用方括号 [ 或 ( 来指示范围的边界是否包含在计数中。方括号 [ 表示该值是包含的,而小括号 ( 表示该值是不包含的。
> ZCOUNT myZSet 15 20
(integer) 2
> ZLEXCOUNT myZSet [a [z
(integer) 2
> ZLEXCOUNT myZSet [a [b
(integer) 0
ZSCAN key cursor [MATCH pattern] [COUNT count]: 迭代Redis的有序集合(ZSET)的元素,包括它的成员和分数。是一种渐进地遍历有序集的方法,而不是一次返回所有结果,这对于大型数据集尤为有用,因为它不会因为要返回大量的结果而阻塞服务器。
# cursor: 用于迭代的游标。初次调用时,通常设置为"0",之后的调用将使用上次返回的游标值。
MATCH pattern (可选): 一个可选的匹配模式,用于筛选具有特定模式的元素。
COUNT count (可选): 提示服务器每次迭代应返回多少元素。实际数目可能会稍多或稍少。
> ZSCAN myZSet 0
1) "0"
2) 1) "member1"
2) "15"
3) "member2"
4) "20"
> ZSCAN myZSet 0 MATCH mem*
1) "0"
2) 1) "member1"
2) "15"
3) "member2"
4) "20"
> ZSCAN myZSet 0 COUNT 1
1) "0"
2) 1) "member1"
2) "15"
3) "member2"
4) "20"
删除操作
ZREM key member [member ...] : 移除有序集合中的一个或多个成员
# 先查看有序集合中的成员及分数
> ZRANGE myZSet 0 -1 WITHSCORES
1) "member1"
2) "15"
3) "member2"
4) "20"
> ZREM myZSet "member1"
(integer) 1
> ZRANGE myZSet 0 -1 WITHSCORES
1) "member2"
2) "20"
ZPOPMAX key [count] : 移除并返回有序集合中的最大的一些成员
> ZADD myZSet 15 "member1" 30 "member3" 55 "member5" 40 "member4"
(integer) 4
> ZRANGE myZSet 0 -1 WITHSCORES
1) "member1"
2) "15"
3) "member2"
4) "20"
5) "member3"
6) "30"
7) "member4"
8) "40"
9) "member5"
10) "55"
> ZPOPMAX myZSet 2
1) "member5"
2) "55"
3) "member4"
4) "40"
> ZRANGE myZSet 0 -1 WITHSCORES
1) "member1"
2) "15"
3) "member2"
4) "20"
5) "member3"
6) "30"
ZPOPMIN key [count] : 移除并返回有序集合中的最小的一些成员
# ZPOPMIN 我这里就不举例了,和 ZPOPMAX 类似
ZREMRANGEBYRANK key start stop : 移除有序集合中给定的排名区间的所有成员
ZREMRANGEBYSCORE key min max : 移除有序集合中给定的分数区间的所有成员
ZREMRANGEBYLEX key min max : 移除有序集合中给定的成员名字典区间的所有成员
> ZREMRANGEBYSCORE myZSet 20 30
(integer) 1
> ZRANGE myZSet 0 -1 WITHSCORES
(empty array)
> ZADD myZSet 15 "member1" 30 "member3" 55 "member5" 40 "member4"
(integer) 4
> ZRANGE myZSet 0 -1 WITHSCORES
1) "member1"
2) "15"
3) "member3"
4) "30"
5) "member4"
6) "40"
7) "member5"
8) "55"
> ZREMRANGEBYLEX myZSet ["member1" ["member4"
(integer) 3
> ZRANGE myZSet 0 -1 WITHSCORES
1) "member5"
2) "55"
集合操作
ZUNIONSTORE destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX] : 计算给定的一个或多个有序集的并集,并存储在新的 destination 中
ZINTERSTORE destination numkeys key [key ...] [WEIGHTS weight [weight ...]] [AGGREGATE SUM|MIN|MAX] : 计算给定的一个或多个有序集的交集,并存储在新的 destination 中
说明:
destination - 新的有序集合的名字,用于存放结果。
numkeys - 指定将要合并的有序集合的数量。
key [key ...] - 需要合并的有序集合的名字。
WEIGHTS - 可选参数,用于为每一个输入的有序集分配一个乘法因子。例如,如果某个集合的 WEIGHT 是2,那么在计算并集时,该集合中的每个元素的分数都会乘以2。
AGGREGATE - 可选参数,它决定了当多个有序集合中存在相同元素时,如何处理这些元素的分数。有三个选项:SUM(默认)、MIN和MAX。SUM将相同元素的分数加起来,MIN 使用最小分数,而 MAX 使用最大分数。
> ZADD set1 1 "one" 2 "two"
(integer) 2
> ZADD set2 1 "one" 3 "three"
(integer) 2
> ZRANGE set1 0 -1 WITHSCORES
1) "one"
2) "1"
3) "two"
4) "2"
> ZRANGE set2 0 -1 WITHSCORES
1) "one"
2) "1"
3) "three"
4) "3"
> ZUNIONSTORE result 2 set1 set2
(integer) 3
> ZRANGE result 0 -1 WITHSCORES
1) "one"
2) "2"
3) "two"
4) "2"
5) "three"
6) "3"
# 当然,你可以使用 WEIGHTS 和 AGGREGATE 参数来调整结果的计算方式。例如,如果你想要为 set1 的每个成员加倍其分数,然后和 set2 求并集,并取每个成员的最大值作为结果:
# set1 set2 两个集合的初始值没变,还是上面的数据
> ZUNIONSTORE result 2 set1 set2 WEIGHTS 2 1 AGGREGATE MAX
(integer) 3
> ZRANGE result 0 -1 WITHSCORES
1) "one"
2) "2"
3) "three"
4) "3"
5) "two"
6) "4"
应用案例
实时排行榜
- 游戏排行榜
在线游戏的实时排行榜,玩家或用户的得分可以即时更新,并按分数进行排序。
# 添加或更新分数
ZADD leaderboard 1500 "player1"
ZADD leaderboard 2200 "player2"
ZADD leaderboard 1800 "player3"
#查询前3名玩家
ZREVRANGE leaderboard 0 2 WITHSCORES
# 获取某个玩家的排名
ZREVRANK leaderboard "player1"
- 网站文章或视频的热门排行
网站可能希望展示其上点击量最高的文章或视频。每次有用户点击时,相关内容的计数就会增加,然后可以使用有序集合实时显示热门内容。
# 文章被点击:
ZINCRBY article_views 1 "article123"
#获取最热门的 3 篇文章
ZREVRANGE article_views 0 2 WITHSCORES
- 电商平台的热门产品排行
电商平台可能希望展示最受欢迎的产品。每当产品被购买,其热度都会增加。
#产品被购买:
ZINCRBY product_sales 1 "product123"
#获取最受欢迎的10个产品
ZREVRANGE product_sales 0 9 WITHSCORES
时间线事件记录
场景描述:假设我们正在为一个社交网络网站设计功能,用户每次登录、发帖或评论都会在其时间线上生成一个事件。我们希望可以跟踪这些事件并能够检索特定时间范围内的事件。
#用户在某个时间点登录了网站
ZADD user123:timeline 1631498200 "Logged in"
#该用户稍后发表了一篇文章
ZADD user123:timeline 1631498300 "Posted an article about Redis"
#查询该用户在指定的时间范围内的所有事件
ZRANGEBYSCORE user123:timeline 1631498200 1631498400
延迟任务队列
场景描述:用户订阅了一个在线服务,比如说一个音乐服务,它提供了一个月的免费试用。为了提醒用户及时续费或者保存他们的歌单数据,服务提供商可以在试用期结束前的几天,发送一个“您的试用即将结束,请及时续费”的提醒。这个提醒任务就可以放入延迟队列。
具体实现步骤:
# 用户注册: 当用户开始他们的免费试用时,你会将这个用户和他们试用结束时间的时间戳(减去3天,这样在结束前3天提醒他们)加入到一个有序集合中。
ZADD trial_end_reminders (start_timestamp + trial_period - few_days) user_id # 一般时间戳是以秒为单位的,对于这个例子,trial_period = 24*86400,few_days = 3 * 86400。
#后台任务:后台任务每天定期检查这个有序集合,查看哪些用户需要在今天被提醒。
ZRANGEBYSCORE trial_end_reminders (current_timestamp) (current_timestamp + 86400)
#发送提醒:对于上面命令返回的每一个用户,你的系统会发送一个提醒邮件或者应用内通知,告诉他们试用即将结束,并提供一个续订链接。
#清理:在发送提醒后,你需要从有序集合中移除这些用户,确保他们不会被再次提醒。
ZREM trial_end_reminders user_id_1 user_id_2 ...
Bitmaps
基本概念:
Redis 的 Bitmaps(位图)是一种特殊的数据结构,用于高效地处理大量的布尔值(true/false或者1/0)。在 Redis 中,Bitmaps 实际上并不是一种独立的数据类型,而是字符串(String)类型的一种特殊操作方式。通过 位操作 命令,Redis 允许用户在一个很大的字节数组中设置和获取位(bit)的值。
简单图解:

内部实现
Bitmaps 实际上就是一个 String,底层采用字节数组来存储数据。
Bitmaps 提供了一系列的命令来操作和查询二进制位。
基本命令:
设置和获取位值:
SETBIT key offset value : 设置或清除操作只需将对应位 置 0 即可指定的位 # 清除操作只需将对应位 置 0 即可, offset只能是非负整数。
GETBIT key offset : 获取指定位的值
# 将位于索引7的位设置为1
> SETBIT mymap 7 1
(integer) 0
# 获取位于索引7的位的值
> GETBIT mymap 7
(integer) 1
统计和查找:
BITCOUNT key :计算整个字符串中设置为1的位数
BITCOUNT key [start end] :计算在指定范围内设置为1的位数
BITPOS key bit [start] [end] : 找到第一个设置为1或0的位
其中,start和end是字符串的字节索引(不是bit索引)
> BITCOUNT mymap
(integer) 1
> BITCOUNT mymap 0 1 # 计算从字节0到字节1之间设置为1的位数
(integer) 1
> BITPOS mymap 1
(integer) 7
> BITPOS mymap 0
(integer) 0
其他运算
BITOP operation destkey key [key ...] : 对一个或多个bitmaps进行位运算
operation 可能是 AND, OR, XOR, NOT 其中一种
AND:逻辑与 、OR:逻辑或、XOR:逻辑异或、NOT:逻辑非
> SETBIT yourmap 5 1
(integer) 0
> BITOP AND destMap mymap yourmap
(integer) 1 # 返回 1,表示 destMap 的长度是 1 字节
应用案列:
员工打卡签到:
大家都知道,员工打卡签到系统几乎是每家公司的标配功能。每天上班,员工都需要打卡来记录他们的出勤情况。今天我们来探讨一下,如何利用 Redis 中的 Bitmaps 来高效地实现这个功能。
为什么选择 Bitmaps?
员工打卡签到无非就是两种结果:签到和未签到。这种二元状态正好与Bitmaps的存储方式相契合,每位员工的每天签到状态只需用一个位(0或1)来表示。
每天使用一个特定日期格式的 key(如 user:12345:attendance:2023-09-01)存储Bitmaps。员工的 ID 直接作为位索引,如 ID 为 42 的员工签到,则将sign_2023-09-01的第 42 位设为 1。
示例:
#员工打卡签到
SETBIT user:42:attendance:2023-09-01 42 1 # 员工 ID 42 在2023-09-01签到
SETBIT user:42:attendance:2023-09-01 1024 1 # 员工 ID 1024 在2023-09-01签到
#检查特定用户是否在某天签到
GETBIT user:42:attendance:2023-09-01 42 # 查看员工 ID 42 在2023-09-01是否签到
GETBIT user:42:attendance:2023-09-01 500 # 查看员工 ID 500 在2023-09-01是否签到
#计算某一天的签到用户数
BITCOUNT user:42:attendance:2023-09-01 # 查看2023-09-01的签到用户数
日活跟踪:
记录特定日期所有活跃用户的信息。例如,我们可以使用一个特定日期的 bitmaps 来跟踪该日期的所有活跃用户。
# 用户 ID 为 12345 和 67890 在 2023-09-01 都活跃了
SETBIT active_users:2023-09-01 12345 1
SETBIT active_users:2023-09-01 67890 1
# 检查用户 ID 为 12345 在 2023-09-01 是否活跃
GETBIT active_users:2023-09-01 12345
#检查某一天所有的活跃用户数
BITCOUNT user:42:attendance:2023-09-01
用户登录:
可以使用 bitmaps 来跟踪用户的登录状态,例如,确定用户是否已登录。
# 用户 ID 为 12345 登录了
SETBIT user:12345:login_status 1
# 检查用户 ID 为 12345 是否登录
GETBIT user:12345:login_status
这三个应用的关注点区别:
打卡签到: 主要关注个体用户的连续行为,例如连续签到多少天。
日活跟踪: 关注整体的用户行为,例如在某一天有多少用户活跃了。
用户登录: 主要跟踪用户的即时状态,例如某用户当前是否在线或已登录。
HyperLogLog
在大数据应用中,我们经常需要计算或估算某个集合中不重复元素的数量(基数),例如统计网站的独立访客(UV)。但当数据规模非常大时,传统的统计方法会消耗大量的存储和计算资源。这时,Redis 的 HyperLogLog(简称HLL)提供了一个很好的解决方案。
基本概念:
从广义上说,HyperLogLog 是一个概率性的数据结构,用于估算集合的基数(即不重复元素的数量)。它不会提供完美准确的计数,但它使用的存储空间非常小(最多使用12KB的内存)。
在 Redis 的语境中,我们可以将 HyperLogLog 视为一种特定的数据类型。
简单图解:

步骤说明:
- 输入值通过哈希函数生成固定长度的二进制哈希值。
- 哈希值的前几位决定了它应该进入数组的位置。
- 存储值,将给定值的前导零的个数存储在数组的对应位置
- 数组中的值可能会根据新的哈希值进行更新(新的哈希值的前导零个数大于数组值才会更新)
- 根据数组元素进行基数估计
内部实现
Redis 的 HyperLogLog 是一种特殊的数据类型,用来估计一个集合中有多少不同的元素。它不会给出完全准确的答案,但它的估计接近真实值,并且使用的存储空间非常小。它是基于一种名为 'HyperLogLog' 的聪明算法来工作的,这种算法使用概率学的魔法来做估计,而不是真正地数每一个元素。
基本命令:
PFADD key element [element ...] : 添加元素
PFCOUNT key [key ...] : 查询基数估计值
PFMERGE destkey sourcekey [sourcekey ...] : 合并多个 HyperLogLog 数据集
> PFADD myhll a b c d e f g
(integer) 1
> PFCOUNT myhll
(integer) 7
> PFADD yourhll a b c d h i j k
(integer) 1
> PFMERGE desthll myhll yourhll
OK
> PFCOUNT desthll
(integer) 11
应用案例:
网站的 UV(独立访客)统计
当你要统计一个网站的UV(独立访客)时,你的目标是确定有多少独立的用户访问了你的网站,而不是访问的总次数。传统的方法(比如,基于关系型数据库的计数)可能会很耗资源,特别是当访客量非常大时。
而 Redis 的 HyperLogLog 提供了一个空间效率非常高的方式来进行这样的估算。每当有用户访问网站时,你可以记录其 IP 地址或者某个与用户相关的唯一标识符(sessionID),然后使用 PFADD 命令将其加入到 HyperLogLog 中。
具体实现:
为每个独立的访客生成唯一标识:
现在大部分网站都会采用 cookie 技术。每当用户访问网站时,服务器都会为这位新访客生成一个唯一的 ID 并将其存储在 cookie 中。这个唯一的 ID 用于在后续的访问中识别该用户,从而跟踪其在网站上的行为和偏好。
我们使用 user_cookie_12345 ,user_cookie_12346 等来标识不同的cookie
添加 Cookie 到 HyperLogLog:
为了跟踪一天的 UV,可以为每天创建一个 HyperLogLog。当用户访问你的网站时,使用PFADD命令将他们的唯一标识添加到 HyperLogLog 中。
> PFADD uv_2023_09_01 user_cookie_12345
> PFADD uv_2023_09_01 user_cookie_12346
> PFADD uv_2023_09_01 user_cookie_12347
...
估算该日的UV:
使用 PFCOUNT 命令来获取估算的UV值。
该命令会返回一个估算的独立访客数量。请注意,这是一个估算值,但其精度在大多数情况下是足够的。
存储历史数据:
如果你想跟踪UV的历史数据,可以为每天保留一个 HyperLogLog。例如:uv_2023_09_01、uv_2023_09_02等。
合并多日数据:
如果你想要一个时间范围内的估算 UV(例如一个月),你可以使用 PFMERGE 命令合并多个 HyperLogLog。
以上就是使用 Redis 的 HyperLogLog 进行网站UV统计的基本方法。使用这种方法,你可以用非常少的空间(每个 HyperLogLog 只需要12KB)来跟踪大量的独立访客。
Geospatial
简介:
Redis支持一个称为 Geospatial 的地理空间索引功能。这一功能在许多需要地理定位数据的应用中都有着广泛应用,如找到某个位置附近的餐厅或商店等。
基本概念:
“Geo” 来源于希腊语,意为“地球”,而 “spatial” 则表示“与空间有关”。结合起来,Geospatial 主要关注地球上的空间位置或地域。在 Redis 中,这意味着我们可以使用坐标系统(如经纬度)来存储和查询地理位置的数据。
简单图解:
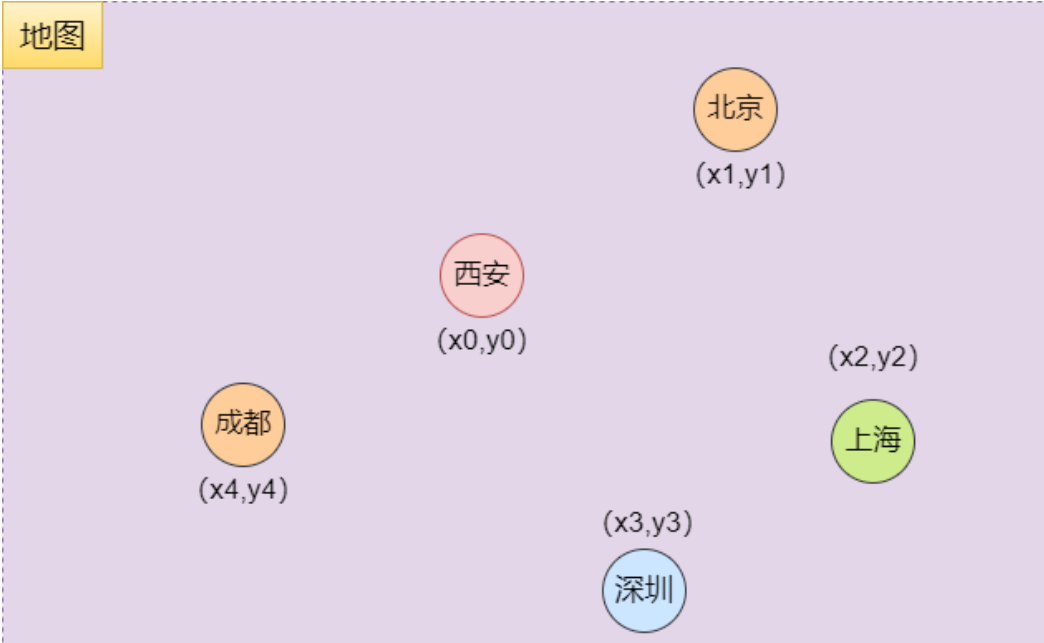
说明:图示的(x,y)代表的是 经纬度坐标
内部实现:
地图到数字:
想象一下,我们的地球是一个巨大的地图。如果我们要在这张地图上标记一个位置,通常会使用经纬度来描述它。但计算机更擅长处理数字而不是这样的坐标。因此,Redis 使用了一种叫做 Geohash 的技巧,它可以把这些坐标(比如经纬度)转换成一个数字。
把位置存进列表:
Redis 有一种特殊的列表叫做 zset(有序集合)。在 Geospatial 中,位置的名字(比如"北京")作为元素,而转换得到的数字(Geohash)作为这个元素的“分数”。
查找附近的地方:
当我们想知道某个位置附近的其他地方时,Redis 会先找出这个位置的数字(Geohash),然后在 zset 中查找分数接近的其他元素。这样就可以快速地找出附近的位置。
注意:
使用 Geohash 的方法可能不是百分之百精确的,因为它是一种近似的方法。但在实际应用中,这种小小的误差通常不会导致太大的问题,而它让存储和查找变得非常迅速。
基本命令
添加操作:
向指定的键中添加地理空间位置(经度、纬度、名称)
GEOADD key longitude latitude member [longitude latitude member ...] : 向指定的键中添加地理空间位置(经度、纬度、名称)
> GEOADD china:city 114.085947 22.547 shenzhen 113.280637 23.125178 guangzhou
(integer) 2
> GEOADD china:city 121.472644 31.231706 shanghai 116.405285 39.904989 beijing
(integer) 2
> GEOADD china:city 108.948024 34.263161 xian 106.504962 29.533155 chongqing
(integer) 2
获取操作:
GEOPOS key member [member ...] : 获取一个或多个位置元素的经纬度
GEODIST key member1 member2 [m|km|ft|mi] : 获取两个地点之间的距离 # [m|km|ft|mi]: 分别是:米,千米,英尺,英里
GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [ASC|DESC] [COUNT count] : 根据给定的经纬度坐标,返回位于给定距离内的位置。
#参数详解
WITHCOORD : 返回查询结果中地理位置的经纬度坐标
WITHDIST : 返回每个查询结果地点到给定坐标的距离
WITHHASH : 返回位置的 52 位整数表示的 geohash
ASC|DESC : 决定了查询结果的排序方式,按距离升序排列、按距离降序排列
COUNT count : 限制查询结果的数量。
> GEOADD china:city 108.948024 34.263161 xian 106.504962 29.533155 chongqing
(integer) 2
> GEOPOS china:city xian chongqing
1) 1) "108.94802302122116089"
2) "34.2631604414749944"
2) 1) "106.50495976209640503"
2) "29.53315530684997015"
> GEODIST china:city shenzhen xian km
"1396.1268"
> GEORADIUS china:city 118.767413 32.041544 500 km
1) "shanghai"
> GEORADIUS china:city 118.767413 32.041544 500 km WITHCOORD
1) 1) "shanghai"
2) 1) "121.47264629602432251"
2) "31.23170490709807012"
> GEORADIUS china:city 118.767413 32.041544 500 km WITHDIST
1) 1) "shanghai"
2) "271.5419"
我们来看一个混合使用参数的例子:
查询距离某个位置 1000 公里内的所有地方,并返回其名称、距离、坐标,然后按距离升序排序,只显示前 3 个结果。
> GEORADIUS china:city 118.767413 32.041544 1000 km WITHDIST WITHCOORD ASC COUNT 3
1) 1) "shanghai"
2) "271.5419"
3) 1) "121.47264629602432251"
2) "31.23170490709807012"
2) 1) "beijing"
2) "899.9931"
3) 1) "116.40528291463851929"
2) "39.9049884229125027"
3) 1) "xian"
2) "946.7395"
3) 1) "108.94802302122116089"
2) "34.2631604414749944"
应用案例
位置数据存储与查询:
- 社交应用:用户可以查找附近的朋友或兴趣点。例如,一个社交网络应用可以允许用户查看附近的其他用户或活动。
- 出行与导航:用于存储和查询地理位置数据,如共享单车或共享汽车的当前位置,以及用户附近的可用车辆。
Stream
基本概念
Redis Stream 是 Redis 5.0 中引入的新数据类型,设计用来存储和查询日志数据结构。Stream 是 Redis 对“日志”数据结构的实现,这种结构在各种场景中都很有用,如消息队列和事件日志。
与简单的 List 不同,Stream 能够更好地支持多用户并发操作,同时还提供了复杂的消息确认和消费机制。
Stream 基本组件介绍
Stream:一个Stream是一个按时间顺序排列的消息列表。每个消息都有一个唯一的ID和键值对组成的数据。
Consumer:这是一个从 Stream 读取消息的客户端。每个 Consumer 都有一个唯一的名字。
Consumer Group:一个 Consumer Group 包含一组 Consumer,它们共同读取一个 Stream。这样做是为了并行处理消息。
简单图解
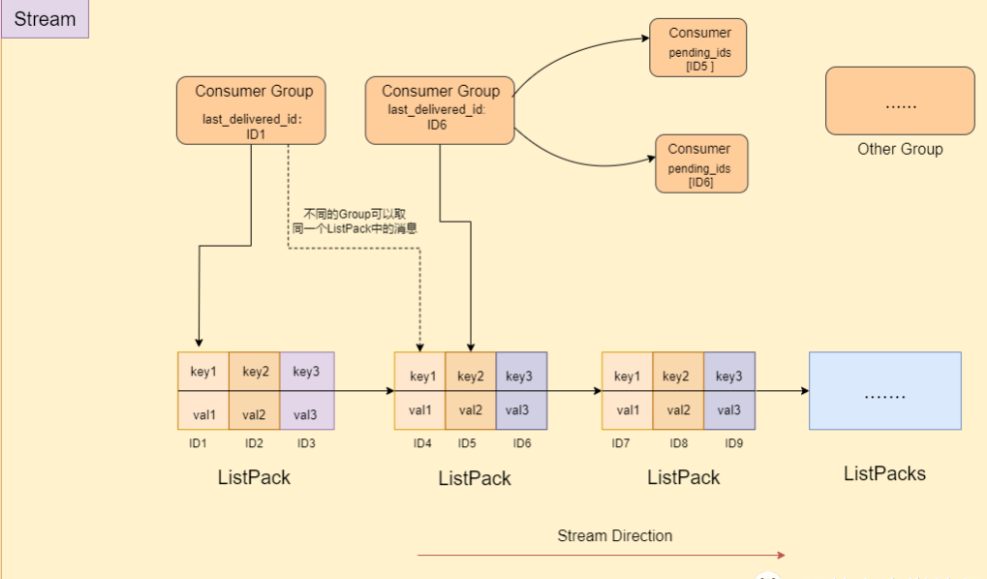
内部实现:
ListPack : Redis 中的 Stream 的底层用的是一种名为 ListPack 的数据结构,它非常紧凑并且效率高。
唯一ID : 每个消息都有一个由时间戳和序列号组成的唯一ID,确保消息的全局唯一性。
基本命令:
基础操作
添加操作:
XADD key *|ID field value [field value ...] :
# *|ID: 消息的 ID。使用 * 会自动生成一个ID,或者你可以指定一个
> XADD mystream * name xiaokang age 25
"1695020949856-0"
> XADD mystream * hobby swim job programmer
"1695029970290-0"
查询操作:
XRANGE key start end [COUNT count] : 查询指定ID范围内的消息
XREVRANGE key end start [COUNT count] : 反向查询指定ID范围内的消息
# 参数说明:
key : 表示你要检索的 Stream 的名字
[COUNT count] : 可选参数,用于限制返回的消息数量
对于 XRANGE 命令,参数 start 和 end 的含义:
start : 检索的起始消息 ID
end : 检索的结束消息 ID
对于 XRANGE 命令,参数 start 和 end 的含义:
start : 反向检索的起始消息 ID
end : 反向检索的结束消息 ID
特殊符号解释:
参数 start 取 '-' , 表示最早的消息,取 + 表示最新的消息
# 检索所有消息
> XRANGE mystream - +
1) 1) "1695020949856-0"
2) 1) "name"
2) "xiaokang"
3) "age"
4) "25"
2) 1) "1695029970290-0"
2) 1) "hobby"
2) "swim"
3) "job"
4) "programmer"
# 反向检索所有消息
> XREVRANGE mystream + -
1) 1) "1695029970290-0"
2) 1) "hobby"
2) "swim"
3) "job"
4) "programmer"
2) 1) "1695020949856-0"
2) 1) "name"
2) "xiaokang"
3) "age"
4) "25"
获取长度:
XLEN key :获取Stream中的消息数量
> XLEN mystream
(integer) 2
裁剪操作:
XTRIM key MAXLEN|MINID [=|~] threshold [LIMIT count] :裁减Stream 的长度,控制其大小
# 参数说明
MAXLEN|MINID : 裁减策略选择。
MAXLEN :使 Stream 最多保持指定数量的消息。
MINID :删除所有小于指定ID的消息。
[=|~]: 这是一个可选的修饰符,与上面的 MAXLEN 或 MINID 一起使用。
=:这意味着长度或ID应该精确匹配。对于 MAXLEN,它确保Stream的长度恰好等于指定的长度(删除任何额外的消息);对于 MINID,它确保删除的所有消息的ID值都小于等于给定值。
~:这意味着长度或ID是一个近似值。这可能会导致更快的裁减操作,但Stream的实际长度可会略微超过或低于指定的值。
[LIMIT count] : 这是一个可选的参数,它限制了在一个操作中可以删除的消息数
> XTRIM mystream MAXLEN = 1
(integer) 1
> XRANGE mystream - +
1) 1) "1695029970290-0"
2) 1) "hobby"
2) "swim"
3) "job"
4) "programmer"
删除操作:
XDEL key ID [ID ...] : 从Stream中删除指定的消息
> XDEL mystream "1695029970290-0"
(integer) 1
> XRANGE mystream - +
读取消息操作:
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] ID [ID ...] : 用于从一个或多个流中读取消息
参数说明:
COUNT count :可选参数,指定要从每个流中读取的最大消息数。
BLOCK milliseconds :可选参数,阻塞操作的时间(以毫秒为单位)。该命令会等待指定的时间,直到有新的消息可用。 在给定的时间内没有新消息,则命令会返回一个空响应
STREAMS :指示后面要列出要从中读取的流的名称。这是一个固定的关键字。
key [key ...] :要从中读取的流的名称列表
ID [ID ...] :为每个指定的流提供一个消息 ID,从该 ID 之后(不包括该 ID)开始读取消息。
特殊 ID $ :表示只读取新的消息,也就是那些在发出此 XREAD 命令之后添加到流中的消息。
消费者和消费者组操作
XGROUP:用于创建、修改或删除消费者组。
# 参数说明:
CREATE : 创建一个新的消费者组。
XGROUP CREATE key groupname ID|$ [MKSTREAM]
key : Stream 的名称。
groupname : 消费者组的名称。
ID : 从哪个消息 ID 开始消费。如果选择 $,则只会消费新添加到 Stream 的消息。
MKSTREAM : 可选参数。如果 Stream 不存在,它会创建一个新的空 Stream。
SETID : 设置消费者组的开始消费消息的 ID。
XGROUP SETID key groupname ID|$
key : Stream 的名称。
groupname : 消费者组的名称。
ID : 从哪个消息 ID 开始消费。如果选择 $,则只会消费新添加到 Stream 的消息。
DESTROY : 删除一个消费者组。
XGROUP DESTROY key groupname
key : Stream 的名称。
groupname : 消费者组的名称。
CREATECONSUMER : 在给定的消费者组中显式地创建一个消费者。
XGROUP CREATECONSUMER key groupname consumername
key : Stream 的名称。
groupname : 消费者组的名称。
consumername : 新创建的消费者的名称。
XREADGROUP:使用消费者组从Stream中读取消息。
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]
# 参数说明:
group : 指的是你想读取消息的消费者组的名称。
consumer : 是该消费者组内的消费者名称。每次使用 XREADGROUP,都需要指定消费者名称。
COUNT count : 可选参数,指定从每个流中读取的最大消息数量。
NOACK : 消息在被读取时不会被标记为“未确认”。因此,不需要(也不能)对它们进行确认。默认情况下,当消费者读取消息后,是需要对消息进行确认的。
ID [ID ...] : 为每个指定的流提供一个消息 ID,从该 ID 之后(不包括该 ID)开始读取消息。
特殊 ID > : 表示从上次读取的位置继续读取(只在使用 XREADGROUP 时有效)。
XACK : 用来确认消费者已成功处理的特定消息
XACK key group ID [ID ...]
# 参数解释
key : 这是你要确认消息的 Stream 的名字。
group : 这是消息所属的消费者组的名称。
ID [ID ...] : 一个或多个你想确认的消息的 ID。
XPENDING :用于查询消费者组中待处理(已发送但未确认)的消息
XPENDING key group [[IDLE min-idle-time] start end count [consumer]]
key : 你要查询的 Stream 的名称。
group: 你要查询的消费者组的名称。
IDLE min-idle-time : 这是一个可选的参数,它允许你只查询那些已经空闲或未确认超过指定毫秒数的消息。
start : 起始消息 ID。
end : 结束消息 ID。
count : 你要返回的消息的最大数量。
consumer : 这是一个可选的参数,它允许你只查询特定消费者的待处理消息。
XCLAIM : 允许一个消费者重新认领消费者组中的挂起消息,通常用于处理由失效消费者未完成的消息。
XCLAIM key group consumer min-idle-time ID [ID ...] [IDLE ms] [TIME ms-unix-time] [RETRYCOUNT count] [force] [justid]
key : 指定的 Stream 名称。
group : 你想要操作的消费者组名称。
consumer : 这是尝试认领消息的消费者的名字。
min-idle-time : 以毫秒为单位的时间,仅当消息的闲置时间超过此值时,消费者才能认领该消息。
ID [ID ...] : 你想要认领的消息的 ID 列表。
IDLE ms : 设置消息的新的闲置时间(自从最后一次被消费以来的时间)。
TIME ms-unix-time : 修改消息的最后一次被读取的时间为给定的 Unix 时间
RETRYCOUNT count : 设置消息的投递计数(即这条消息已经被送达的次数)。
force : 这个选项允许你不考虑 min-idle-time 条件,直接强制认领消息。
justid : 如果设置这个选项,命令只返回消息 ID,不返回消息的内容。
接下来,我通过一个示例来演示如何使用Redis Stream中的命令进行消息的添加、消费和确认。
场景:
以一个在线订单系统为例,当一个用户下单时,订单详细信息被添加到一个名为“orders”的stream中。有一个消费者组叫做“order-processors”,里面有两个消费者:“processor1”和“processor2”。它们的任务是处理这些订单,例如更新库存、发送确认邮件等。
1. 添加订单
XADD orders * order_id 123 item_id A1 count 2 # 用户A下了一个订单,订单编号为123,买了 2件
"1695103666038-0"
2.创建消费者组
XGROUP CREATE orders order-processors $ MKSTREAM # 创建一个名为“order-processors”的消费者组,从 stream 的开始处监听新的订单。
OK
3.读取和处理订单
# processor1读取了订单123并开始处理它
XREADGROUP GROUP order-processors processor1 COUNT 1 STREAMS orders >
# 同时,另一个用户B下了一个订单,编号为124
XADD orders * order_id 124 item_id A2 quantity 1
# 然后,processor2 开始读取订单:
XREADGROUP GROUP order-processors processor2 COUNT 1 STREAMS orders >
4.确认订单已处理
# 当processor1成功处理订单123时,它会确认处理完成:
XACK orders order-processors messageID1
# 注意:messageID1是processor1从Stream读取到的订单123的ID。
5.查看未处理的订单
XPENDING orders order-processors
# 假设processor2由于某种原因暂时不能处理订单124,这时我们会看到订单124尚未被处理。
6.重新处理失败的订单
# 如果processor2出现故障,processor1可以认领并处理订单124:
XCLAIM orders order-processors processor1 3600000 messageID2
这个简单的在线订购系统例子展示了如何使用Redis Streams进行实时订单处理。这种模式可以确保即使某个消费者失败,订单也能被其他消费者接手并顺利处理。
应用案例:
消息队列
消息队列是一种应用程序之间传递数据的方式。它允许应用程序异步地发送和接收消息,这意味着发送消息的应用程序和接收消息的应用程序无需同时运行。
以在线购物系统的订单处理为例进行说明:
考虑一个在线购物系统。当用户下单时,系统不应该让用户等待直到所有的后端处理(例如库存检查、付款处理、通知仓库等)都完成。相反,一旦订单提交,系统应该立即给用户一个响应,而后端的处理可以稍后进行。
#1. 添加订单到队列:
#用户下单后,我们将订单数据添加到名为orders的Redis Stream中。
XADD orders * order_id 101 product_id P01 quantity 3
#2.处理订单:
# 后台有多个workers(进程),它们不断地监听新的订单,并进行处理。这些worke 可以是分布在多台机器上的多个进程。
首先,我们创建一个消费者组:
XGROUP CREATE orders order-processors $ MKSTREAM
接着,一个worker可以开始读取并处理订单:
XREADGROUP GROUP order-processors worker1 COUNT 1 STREAMS orders >
# 这里,worker1是处理订单的消费者名称。>意味着从最新的消息开始读取。
确认订单处理完成:
一旦worker1处理完订单,它需要确认该订单已被处理:
XACK orders order-processors # 其中,是在步骤1中Redis生成的订单ID。
通过此例子,我们展示了如何使用 Redis Stream 作为消息队列,来异步处理在线购物系统中的订单。这种结构确保了用户下单后能够迅速得到响应,同时订单处理也能在后台高效地进行。
事件日志
事件日志就是记录系统或应用中发生的各种事件,如用户操作、系统异常等。
事件日志的常见应用是在电商平台中记录用户的购物行为。
假设你运营一个电商平台,每当用户浏览、搜索、点击、购买或者评论商品时,都会产生一个事件。你可以使用Redis Streams来记录这些事件。基于这些事件,可以做一些实时分析,比如:分析用户的购物模式和偏好,为他们提供更相关的商品推荐。
1.浏览商品:
事件:商品浏览
数据:用户ID,商品ID,浏览时间,来源页面等。
XADD user-activity * event "商品浏览" userID "12345" productID "abcd" timestamp "1632067200" source "主页"
2.搜索商品:
事件:商品搜索
数据:用户ID,搜索关键词,搜索时间,搜索结果数等。
XADD user-activity * event "商品搜索" userID "12345" keyword "运动鞋" timestamp "1632067250" results "50"
3.点击商品:
事件:商品点击
数据:用户ID,商品ID,点击时间。
XADD user-activity * event "商品点击" userID "12345" productID "abcd" timestamp "1632067300"
4.购买商品:
事件:商品购买
数据:用户ID,商品ID,购买数量,总价,购买时间。
XADD user-activity * event "商品购买" userID "12345" productID "abcd" quantity "2" total "200" timestamp "1632067400"
5.商品评价:
事件:商品评价
数据:用户ID,商品ID,评分,评论内容,评价时间。
XADD user-activity * event "商品评价" userID "12345" productID "abcd" rating "5" review "非常满意" timestamp "1632067500"
总结:
在上文,我们深入探讨了 Redis 的九种对象类型,包括字符串(String)、列表(List)、哈希(Hash)、集合(Set)、有序集合(Sorted Set)、Bitmaps、HyperLogLog、Geospatial 和 Stream。
这里简单总结下各种数据结构的使用场景:
- 字符串对象是最简单的数据类型,适用于缓存、临时存储等场景。
- 列表对象提供了队列的实现,非常适合消息队列和栈的应用。
- 哈希对象是存储对象属性的理想选择,适用于存储和访问对象。
- 集合对象和有序集合对象适用于存储不重复元素,其中有序集合还可以进行排名和范围查询。
- Bitmaps和 HyperLogLog 提供了高效的计数和统计功能。
- Geospatial 允许进行地理位置的存储和查询。
- Stream 为构建复杂的消息传递提供了基础。
Redis 作为一个高性能的键值数据库,已经成为现代应用开发不可或缺的组成部分。通过深入了解 Redis 的各种对象及其编码方式,我们不仅可以更加高效地利用其提供的功能,还能针对不同的应用场景选择最适合的对象类型,从而优化我们的应用性能和资源使用。
本篇文章旨在为大家提供一个关于 Redis 各个对象的全面指南,从基本概念到内部实现,再到实际应用案例。不管您是刚开始接触 Redis 还是已经有很多经验,希望本文都能为您带来新的启示。
最后
如果你对 Linux 编程,Redis 等后端技术感兴趣或者想学习计算机基础相关的知识,不妨关注我的公众号「跟着小康学编程」。这里不仅有丰富的学习资源,还有持续更新的简单易懂的技术文章。
大家可以关注我 ,具体可访问 :关注小康微信公众号
另外大家在阅读这篇文章的时候,如果觉得有问题的或者有不理解的知识点,欢迎大家评论区询问。我看到就会回复大家的。大家也可以加我的微信:jk-fwdkf , 备注加群。有任何不理解的都可以咨询我。
大家如果觉得我写的还不错,也希望大家能够帮忙点个赞,感谢大家的关注!
参考资料
[1]Redis分布式锁到底安全吗?: http://kaito-kidd.com/2021/06/08/is-redis-distributed-lock-really-safe/