-
docker存储驱动
目录
一、写时复制和用时分配
我们知道一个镜像可以跑多个容器,如果每个容器都去复制一份镜像内的文件系统,那么将会占用大量的存储空间。docker使用了写时复制cow(copy-on-write)和用时分配(allocate-on-demand)技术来提高存储的利用率。可以理解为kvm的创建虚拟机链接
1、写时复制:
写时复制技术可以让多个容器共享同一个镜像的文件系统,所有数据都从镜像中读取
只有当要对文件进行写操作时,才从镜像里把要写的文件复制到自己的文件系统进行修改。所以无论有多少个容器共享同一个镜像,所做的写操作都是对从镜像中复制到自己的文件系统中的复本上进行,并不会修改镜像的源文件
多个容器操作同一个文件,会在每个容器的文件系统里生成一个复本,每个容器修改的都是自己的复本,相互隔离,相互不影响
2、用时分配:
启动一个容器,并不会为这个容器预分配一些磁盘空间,而是当有新文件写入时,才按需分配新空间二、联合文件系统
联合文件系统(UnionFS)就是把不同物理位置的目录合并mount到同一个目录中
比如你可以将一个光盘与一个硬盘上的目录联合挂载到一起,然后对只读的光盘文件进行修改,修改的文件不存放回光盘进行覆盖,而是存放到硬盘目录。这样做达到了不影响光盘原数据,而修改的目的。
思考:把光盘看作是docker里的image,而硬盘目录看作是container,你再想想看?
docker就支持aufs和overlay两种联合文件系统。2.1、aufs
Docker最开始采用AUFS作为文件系统,也得益于AUFS分层的概念,实现了多个Container可以共享同一个image。
aufs(Another UnionFS),后来叫Alternative UnionFS,后来可能觉得不够霸气,叫成AdvanceUnionFS.
除了最上面的一层是读写层之外,下面的其他层都是只读的镜像层
多个容器共享同一个基础镜像之后,修改其他容器内镜像需要的内存其实就是基础镜像内存自动 分配且独立的。例如修改了阿帕奇记录需要3M基础镜像不会变,容器则会记录修改的内容

容器中修改的镜像内容不会覆盖原来的镜像

2.2、分层的问题
分层实际上是记录每次修改的内容,如果修改次数太多了会占用存储空间去记录
例如:vim 一个文件第一次写入1,第二次把1改成2,实际上是记录修改内容的存储空间是不变的
但是如果分层记录互不影响的话,会记录每次修改的内容导致占用存储空间
2.3、overlay
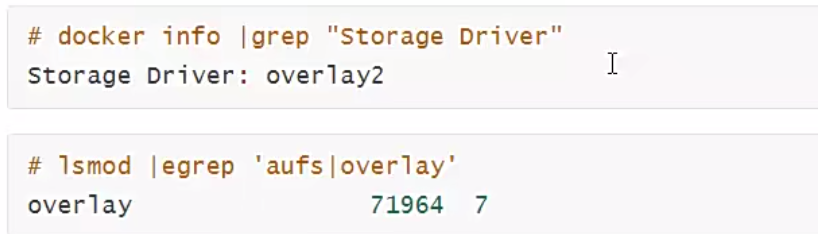
由于AUFS未并入Linux内核,且只支持Ubuntu,考虑到兼容性问题,在Docker 0.7版本中引入了存储驱动。目前,Docker支持AUFS,OverlayFS,Btrfs,Device mapper,ZFS五种存储驱动.
目前,在ubuntu发行版上默认存储方式为AUFS,CentOS发行版上的默认存储方式为overlay或overlay2
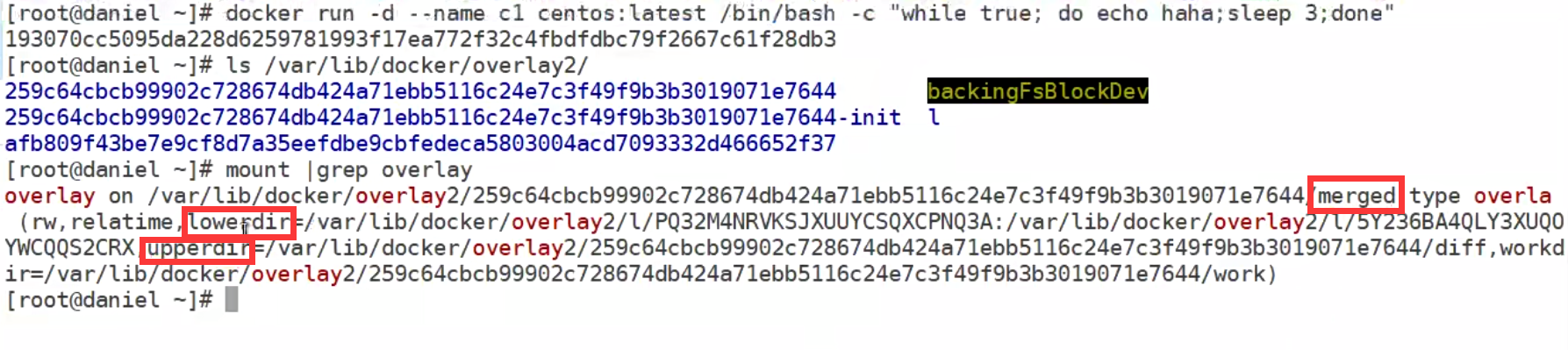
Overlay是Linux内核3.18后支持的(当前3.10内核加载模块也可以使用),也是一种Union FS,和AUFS的多层不同的是Overlay只有两层:一个upper文件系统和一个lower文件系统,分别代表Docker的容器层和镜像层..OverlayFS底层目录称为lowerdir,高层目录称为upperdir。合并统一视图称为merged。当需要修改一个文件时,使用cow将文件从只读的Lower复制到可写的upper进行修改,结果也保存在Upper层。在Docker中,底下的只读层就是image,可写层就是Container
下图分层图,镜像层是lowdir,容器层是upperdir,统--的视图层是merged层.
视图层就是给用户提供了一个统一的视角,隐藏了多个层的复杂性,对用户来说只存在一个文件系统。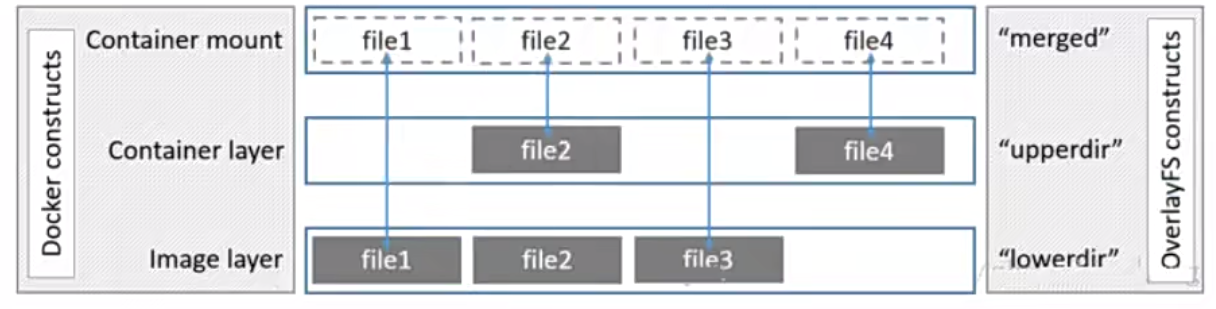
如果upperdir和lowerdir有同名文件时会用upperdir的文件读文件的时候,文件不在upperdir则从lowerdir读
如果写的文件不在uppderdir在lowerdir,则从lowerdir里面copy到upperdir。
不管文件多大,copy完再写,删除或者重命名镜像层的文件都只是在容器层生成whiteout文件标志(标记为删除,并不是真的删除)
2.4 文件系统区别
aufs:使用多层分层
overlay:使用2层分层,共享数据方式是通过硬连接,只挂载一层,其他层通过最高层通过硬连接形式共享(增加了磁盘inode的负担)
overlay2:使用2层分层,驱动原生地支持多层lower overlay镜像(最多128层),与overlay驱动对比,消耗更少的inode(索引)

三、容器跑httpd案例
3.1、案例1:端口映射
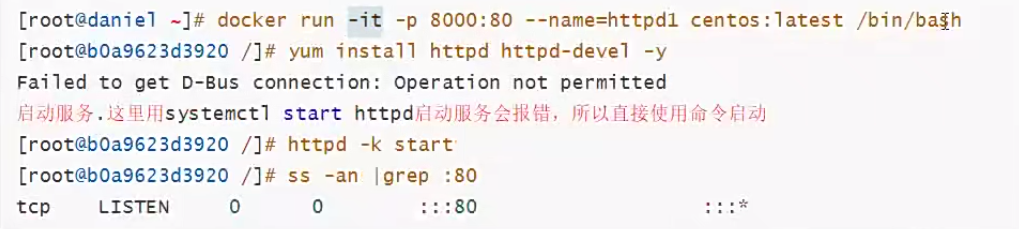
利用官方centos镜像运行容器跑httpd服务,因为官方centos镜像里默认并没有安装httpd服务,所以需要我们自定义安装
docker内部跑httpd启动80端口,需要与docker_host(宿主机)进行端口映射,才能让客户端通过网络来访问
1,运行容器httpd1; -p 8000:80的意思是把容器里的80端口映射为docker_host(宿主机)的8000端口
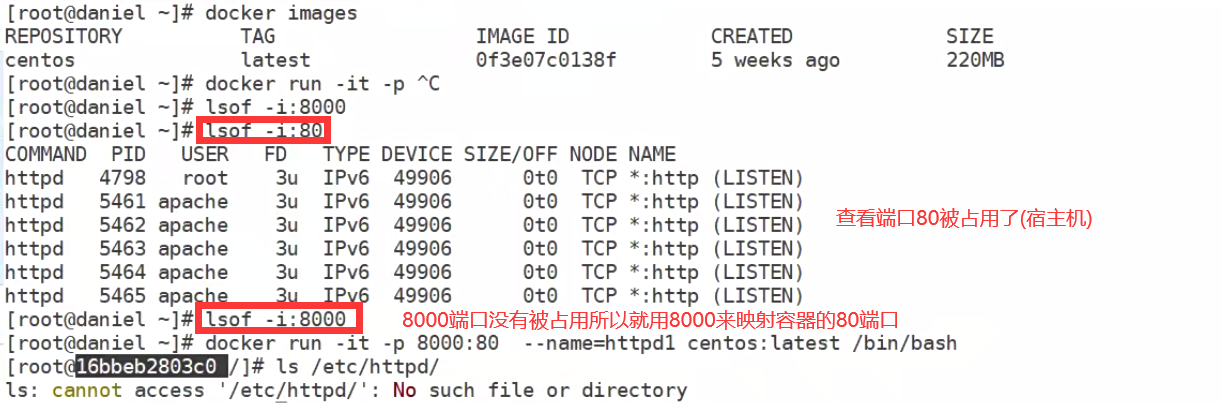
查看容器的dns,容器和docker宿主机之间通过虚拟的交换机链接
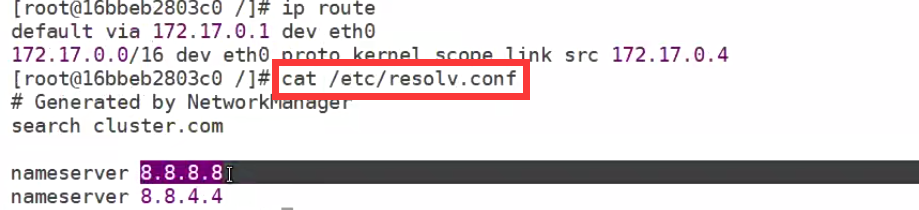
在docker宿主机上查看IP可以使用inspect
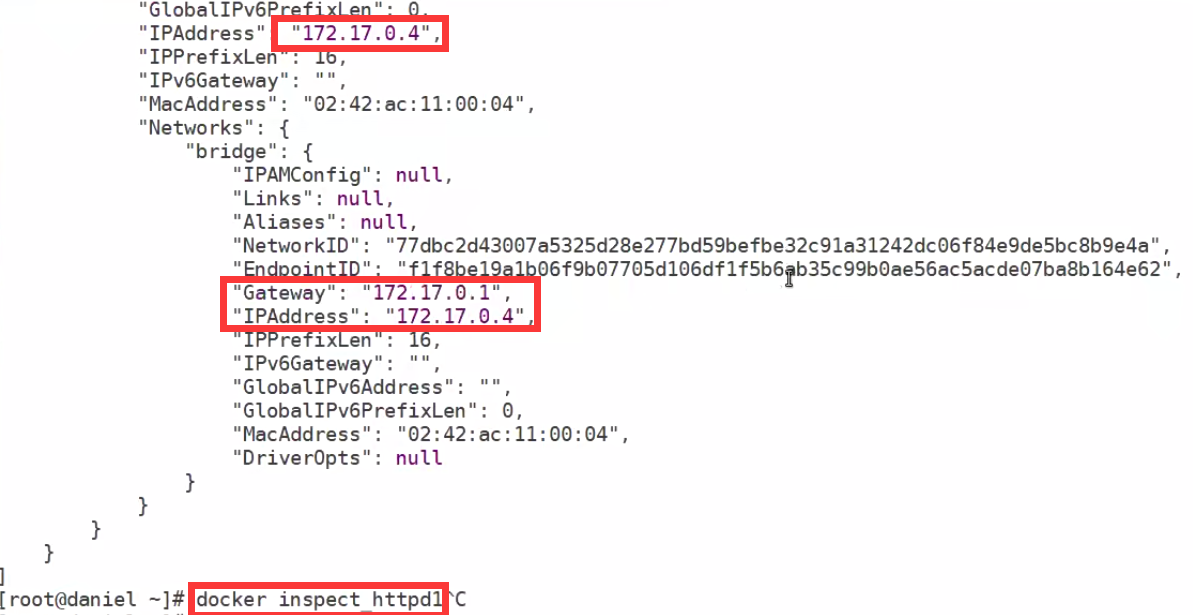
容器内核 和宿主一样
 容器实际上只是一个宿主机的进程所以无法使用systemctl启动,无法模拟systemd
容器实际上只是一个宿主机的进程所以无法使用systemctl启动,无法模拟systemd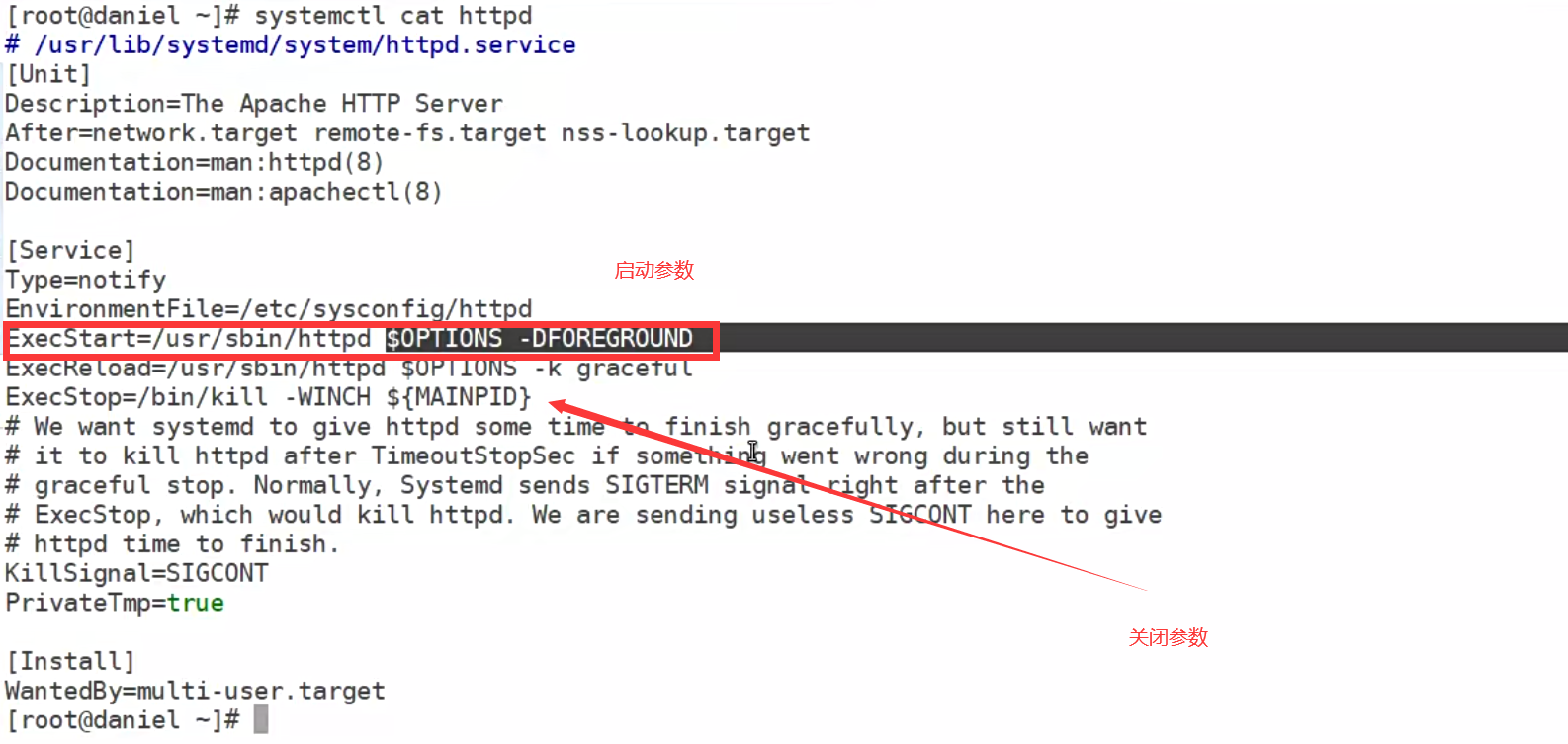
使用宿主机curl ip 查看

端口映射必须打开ip_forward

测试可以使用另一台电脑的浏览器访问宿主机IP:8000
因为宿主机中的容器IP不可能一样,防止端口冲突问题就必须做端口映射
另一台电脑中可能也有相同的容器IP
3.2、案例2:制作httpd应用镜像
cenots镜像里并没有httpd,所以需要安装.但是如果每次启动一个容器都要安装一遍httpd是让人受不了的.所以我们在一个容器里安装一次,把想自定义的全做了,然后将此容器commit成一个新的镜像。
以后就用这个新镜像运行容器就可以不用再重复装环境了。
自定义修改阿帕奇的家目录必须注意不能改错,只能跳着改两个地方
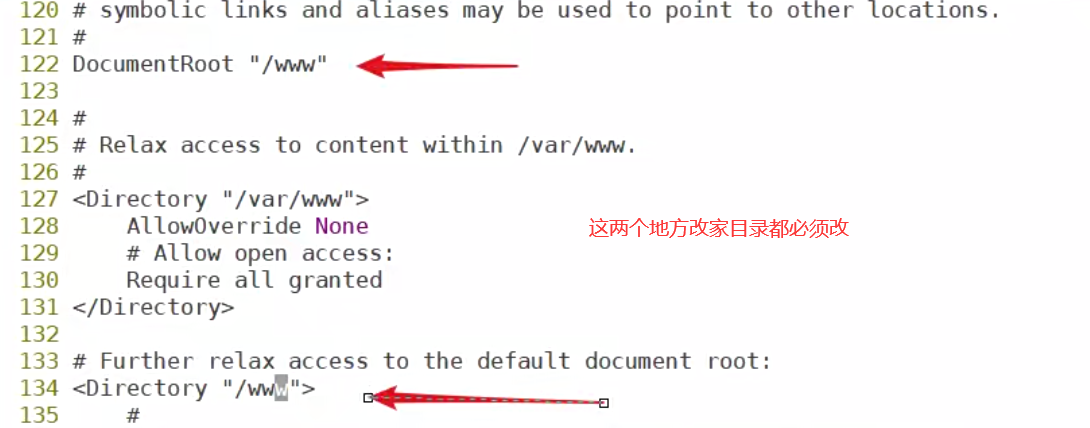
修改完家目录之后创建家目录然后随便编辑内容再启动httpd服务,由于lsof、netstat命令没有
只能用ss命令查看80端口
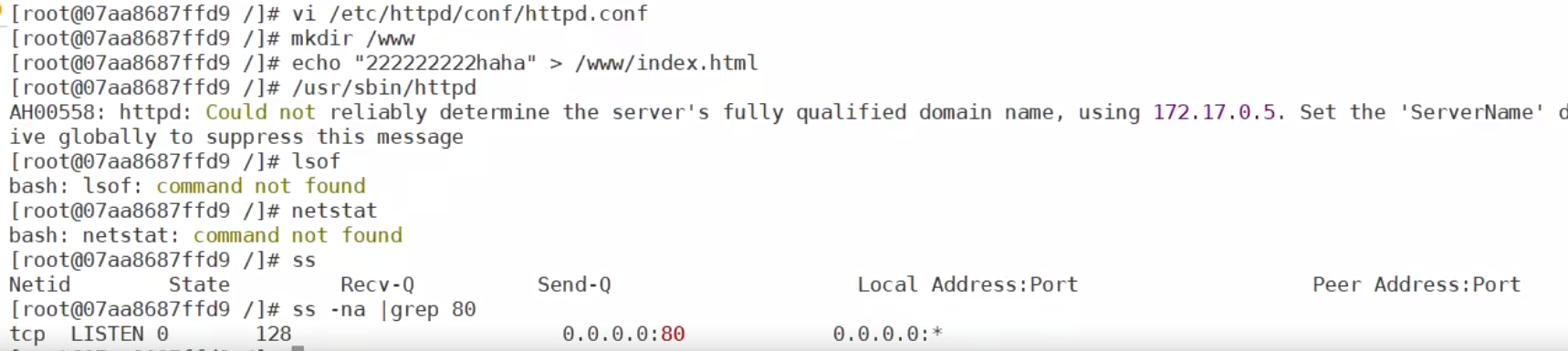
将搭建好的环境commit成新的镜像(此镜像相当于是自定义的,生产环境中可以按需求push到镜像仓库)
 后面那个标签自定义
后面那个标签自定义-D FOREGROUND 参数需要自己查找 就是阿帕奇的容器启动参数
将commit提交的镜像启动一个新的容器,并将端口80映射到宿主机的8001
 使用另一台电脑的浏览器访问宿主机ip:8001测试
使用另一台电脑的浏览器访问宿主机ip:8001测试 加-d 是隐藏后台输出的信息 避免卡住终端
加-d 是隐藏后台输出的信息 避免卡住终端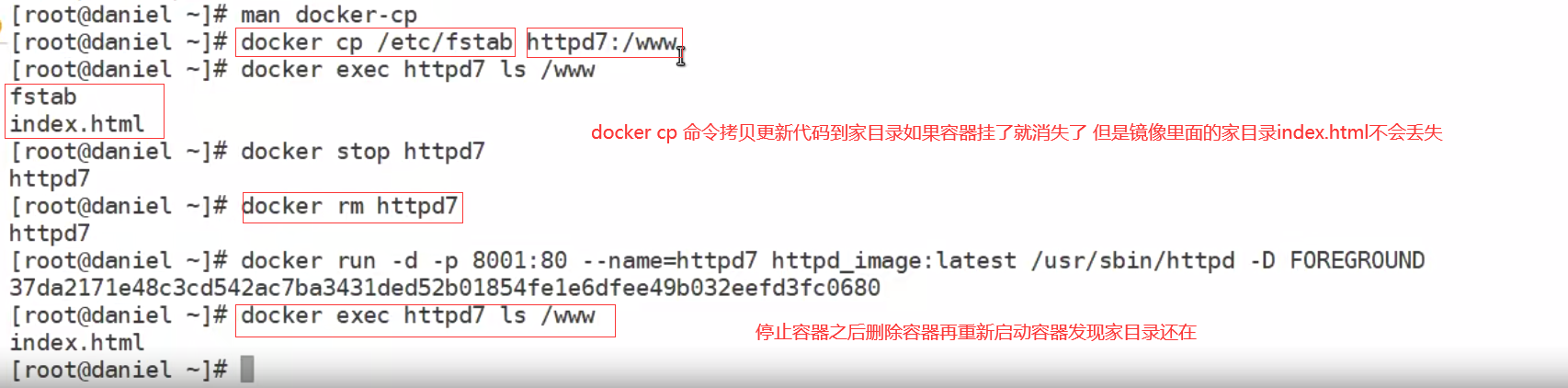
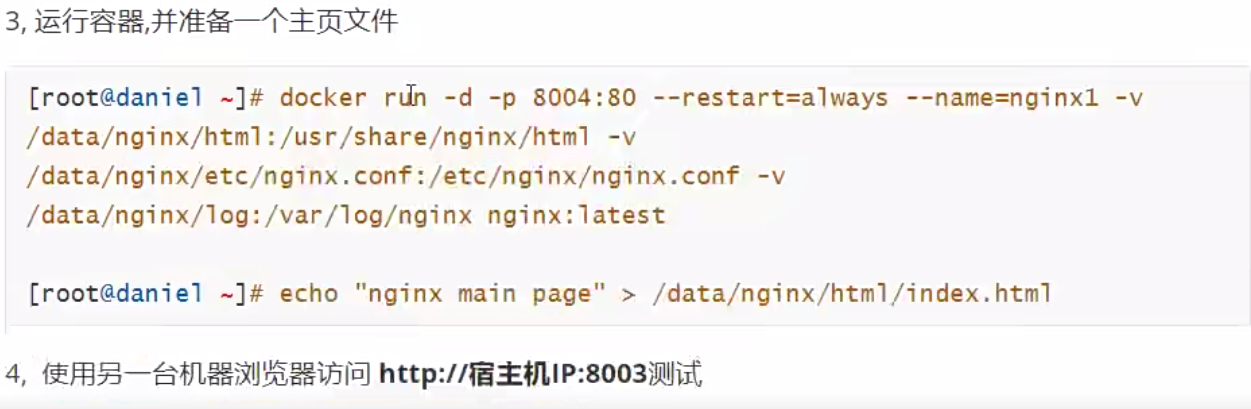
3.3、案例3:docker数据卷挂载
有以下需求:
容器内配置文件需要修改
容器内数据(如:如httpd家目录内的数据)需要保存
不同容器间数据需要共享(如:两个httpd容器家目录数据共享)当容器删除时,里面的相关改变的数据也会删除,也就是说数据不能持久化保存。
我们可以将服务的配置文件,数据目录,日志目录等与宿主机的目录映射,把数据保持到宿主机上实现数据持久化宿主机的目录也可以共享给多个容器使用
将宿主机的目录(数据卷、配置文件)挂载到容器中(解耦作用)头和身体是耦合的 手和指甲可以解耦

往宿主机中发布或更新项目就能实在cicd 解耦之后不用管容器了和容器分离 实现数据持久化

可以一次性挂载多个-v 命令
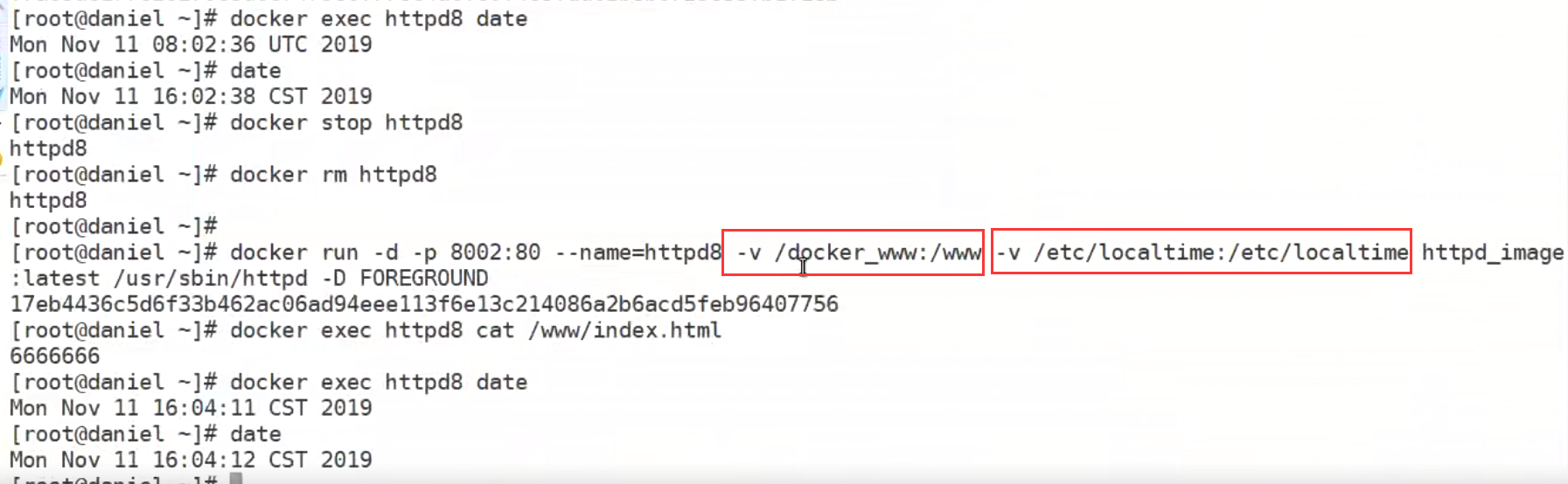
挂载配置文件


通过系统镜像自定义应用或者直接使用应用镜像
3.4、案例4:官方httpd镜像运行
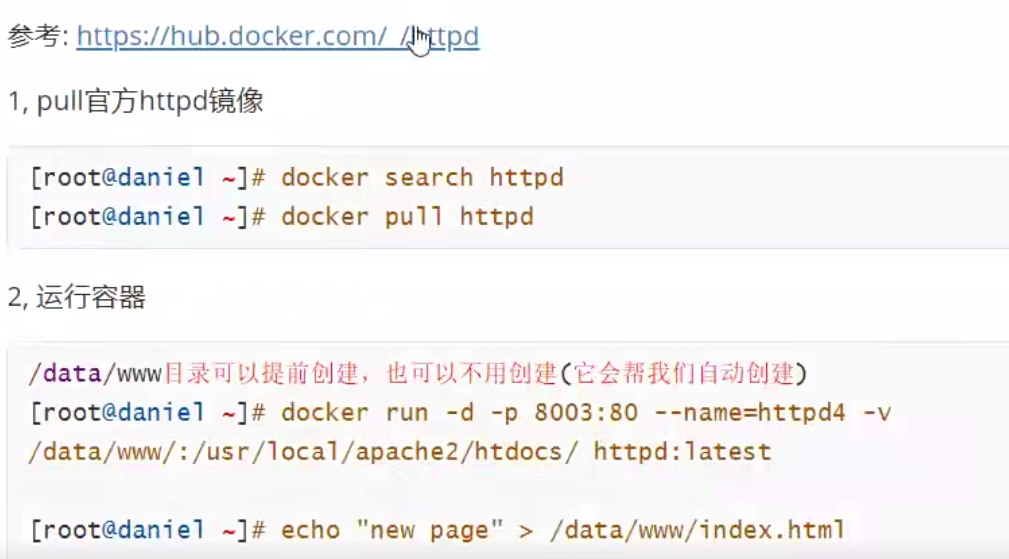

四、容器中运行应用
4.1、官方mariadb镜像运行
在docker官方仓库pull需要的数据库即可,参考操作文档安装就行
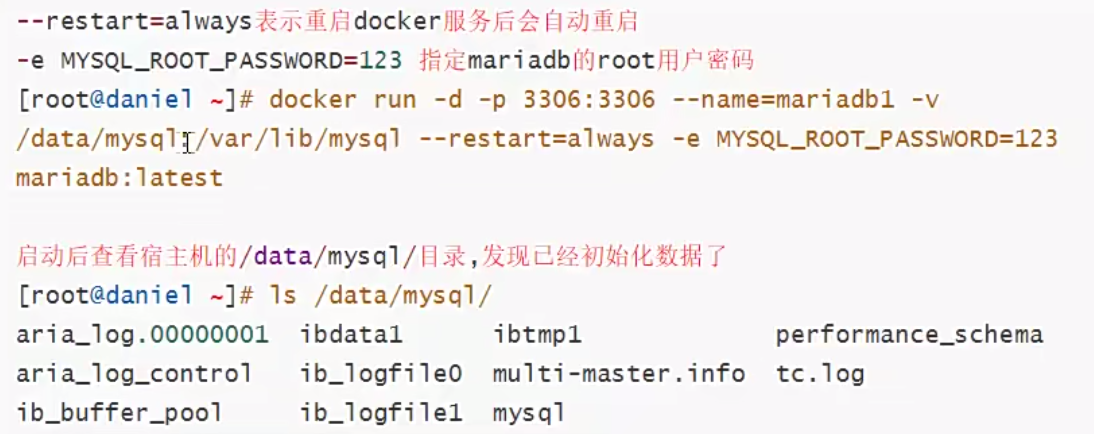
启动容器没反应大概率是因为端口被占用了,使用lsof -i 3306 排查

在容器中运行mysql发现密码没有传入
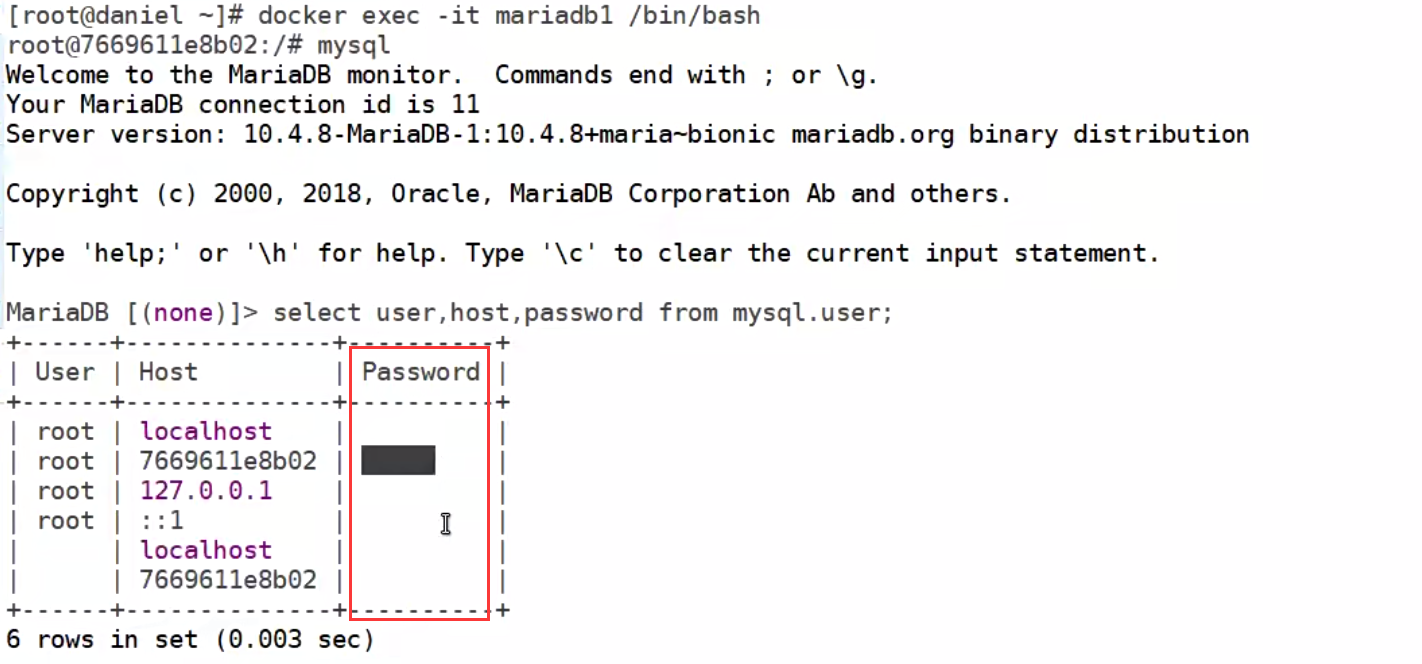
使用宿主机远程链接容器中的数据库

因为数据库版本原因导致远程访问授权方式不一样,可以参考文档就行配置授权
4.2、系统镜像自定义mariadb环境
-d命令是后台运行容器 容器不会立刻和终端进行交互 必须使用attach命令进行交互
 &后台配置参数这些无法实现自动化 必须每次都传参一次才行
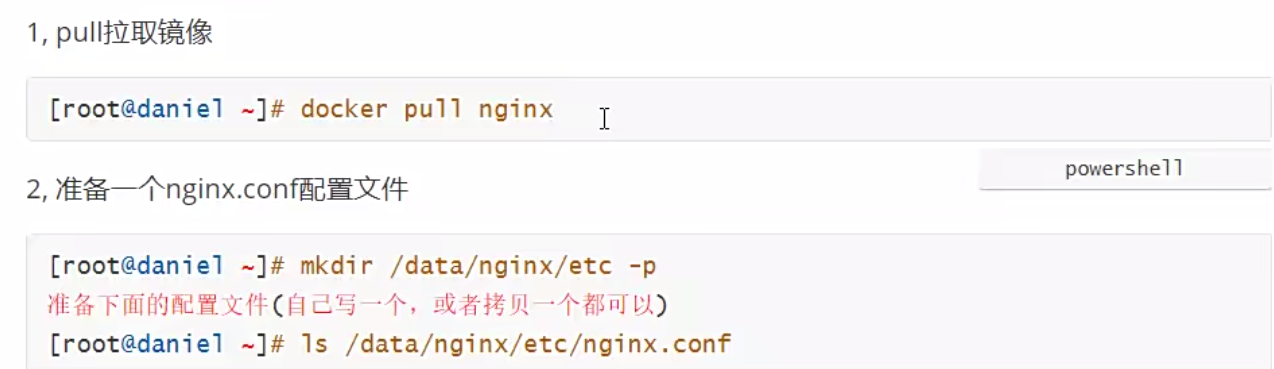
&后台配置参数这些无法实现自动化 必须每次都传参一次才行4.3、官方nginx镜像运行容器
需要注意的就是官方文档中的nginx版本

-
相关阅读:
Spring(SpringBoot)--解决拦截器中注入Bean失败的问题
重新认识WorkPlus,不止IM即时通讯,是企业移动应用管理专家
Linux安装Nexus3搭建maven私服超详细搭建上传步骤
【服务器数据恢复】Zfs文件系统误删除数据的数据恢复案例
uni-app运行到微信开发者工具-没有打印的情况
C++面试知识点
网站有绕过认证逻辑漏洞怎么修复
直方图的计算,绘制与分析
机器学习——线性回归欠拟合优化增加多项式特征
嵌入式开发:以数据为中心的软件设计的3个技巧
- 原文地址:https://blog.csdn.net/CCTVZHENG/article/details/136218186