-
spark基础
文章目录
spark框架概述
什么是spark
用于大规模数据处理的统一分析引擎
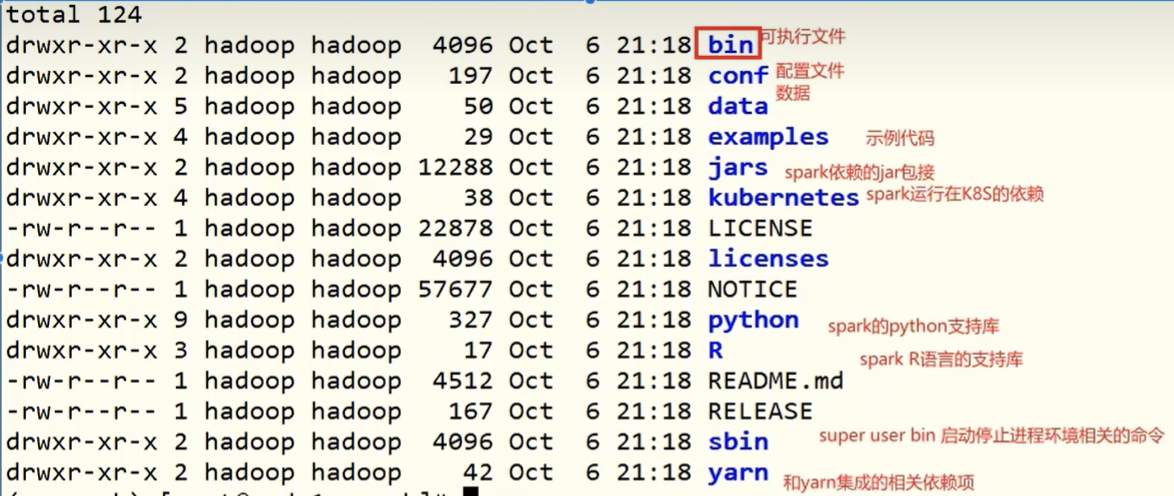
特点:对任意类型(结构化、半结构化、非结构化)的数据进行自定义计算起源
2009年起源加州伯克利
2010年开源
2013年原创团队成立databricks;同年被捐给apache基金会
2014年成为apache顶级项目
2016年spark2.0
2019年spark3.0spark VS hadoop(mapreduce)
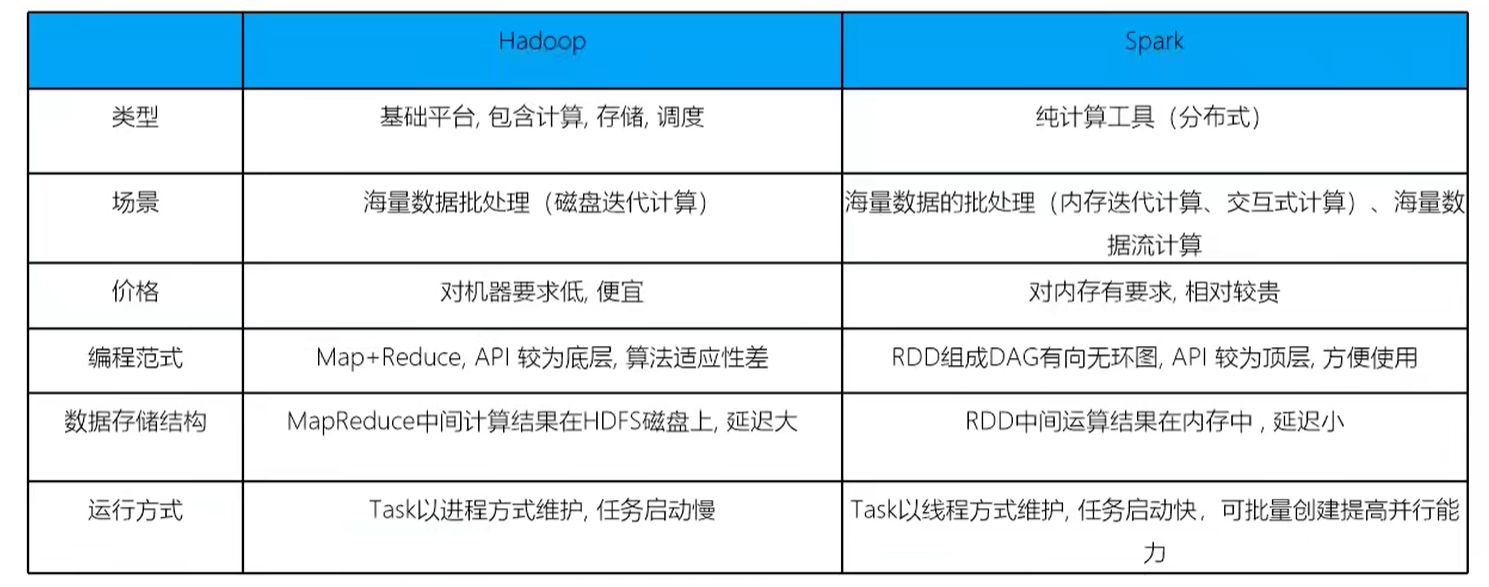
spark相对hadoop有优势,但不能完全取代:- 计算层面:spark相比mapreduce有巨大优势,但至今有很多基于MR架构的计算工具,如hive
- spark仅做计算:hadoop不仅有计算(mapreduce),也有存储(hdfs),资源管理调度(yarn);hdfs和yarn仍然是很多大数据体系的核心架构
spark特点
- 速度快:100x mapreduce(支持内存计算,并通过DAG(有向无环图)来完成数据的迭代计算)
- spark处理数据时,将中间数据结果存储到内存中(hadoop存储在硬盘中,读取硬盘)
- spark提供丰富的算子(API),做到复杂任务在一个spark程序中完成(mapreduce只有两个算子:map和reduce)
- 易使用:python、Java、Scala、R
df = spark.read.json("log.json") df.where("age">21).select("name.first").show(()- 1
- 2
- 通用:包含spark sql、spark streaming、MLlib、GraphX等,

spark core api:spark核心- 运行广泛:runs on hadoop、mesos、standalone、cloud
支持多种运行方式:hadoop、mesos,也支持Standalone的独立运行模式,也支持云kubernetes(spark2.3)
支持多种数据源:hdfs、hbase、cassandra、kafka、mysql、elastic、redis、mangodb、postagesql(支持定制数据源)spark框架模块
spark整个框架模块包括:spark core、spark sql、spark streaming、spark graphx、spark mllib,后四项建立在核心引擎之上
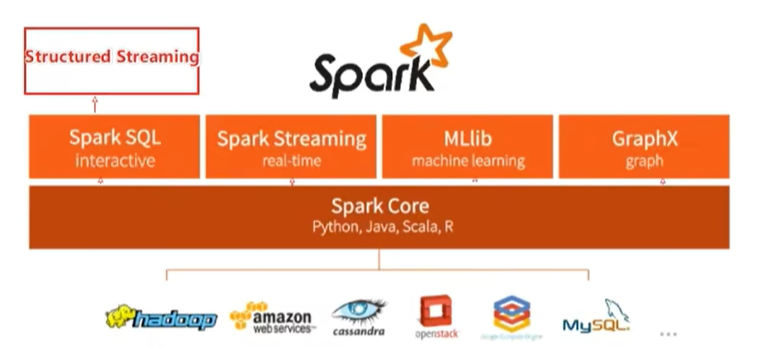
spark core:spark核心,spark运行的基础。以RDD(Resilient Distributed Dataset,分布式弹性数据集)数据抽象,提供python、java、scala、r语言的api,可进行海量离线数据批处理(不管是否结构化)
spark sql:基于spark core提供结构化数据的处理,本身针对离线计算场景。基于spark sql提供structuredStreaming模块,进行数据流式计算(spark sql只能处理结构化)
spark streaming:以spark core为基础,提供数据流式计算
spark graphx:以spark core为基础,进行机器学习计算,内置大量机器学习库和api算法,方便用户以分布式模式进行机器学习计算
spark mlib:以spark core为基础,进行图计算,提供大量图计算api,方便用户以分布式模式进行图计算spark运行模式
- 本地模式(单机)
本地模式就是一个独立进程,通过内部多个线程来模拟整个spark运行的环境
- standalone模式(集群)
spark中各个角色以独立进程的形式存在,并组成spark集群环境
- hadoop yarn模式(集群)
spark中各个角色运行在yarn容器内部,并组成spark集群环境
- kubernetes模式(容器集群)
spark中各个角色运行在kubernetes容器内部,并组成spark集群环境
- 云服务模式
运行在云平台上
- …
除本地模式外,都可以用于生产
spark架构角色
yarn角色
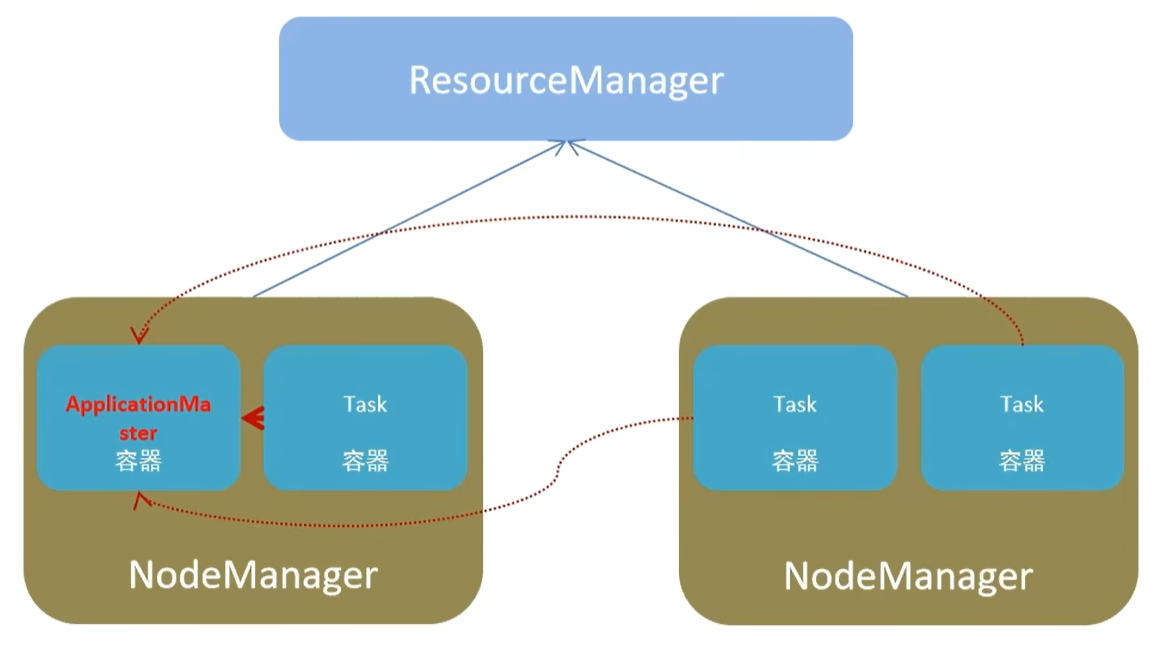
资源管理层面:
resourcemanager:集群资源管理者
nodemanager:单机资源管理者
任务计算层面:
applicationmaster:单任务管理者(如任务失败重启、任务资源分配、任务工作调度)
task:单任务执行者saprk角色
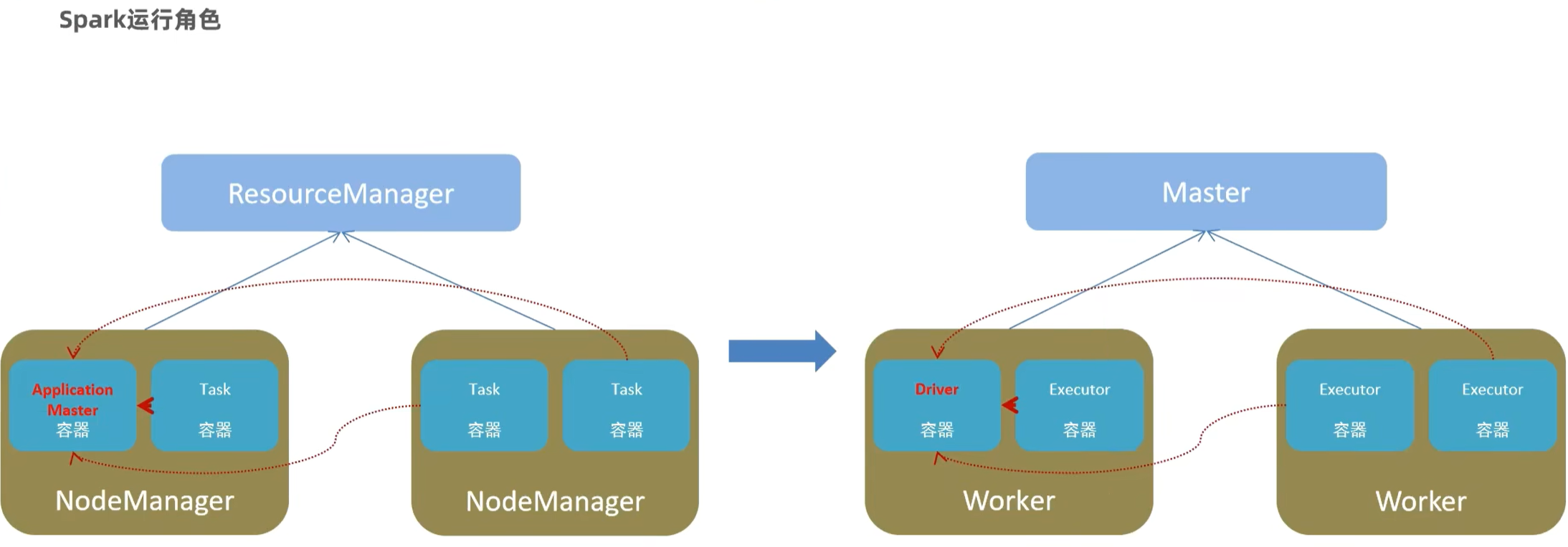
master:集群资源管理者
worker:单机资源管理者
driver:单任务管理者
executor:单任务计算
正常executor干活,特殊场景下(local)driver除了管理也可以干活小结:
解决问题
针对海量数据进行离线批处理和实时流计算
模块
spark core、spark sql、spark streaming、graphX、MLlib
特点
快、简单、通用、多模式运行
运行模式
- 本地模式
- 集群模式(standalone、yarn、kubernetes)
- 云模式
运行角色
master;worker;driver;executor
spark环境搭建-local
实验服务器环境
node1:master和worker
node2:worker
node3:worker和hive- hadoop3以上
- jdk1.8
- centos7(7.6)
基本原理
本质
启动一个JVM process进程(一个进程有多个线程),执行任务task
- local模式可以限制spark集群环境的线程数量,即local[N]或local[*]
- N代表可以使用N个线程,每个线程拥有1个cpu core;如果不指定N,默认1个线程;通常几核cpu就指定几个线程,最大化利用计算能力
- local[*]表示按最多的cppu核心数设置线程数
角色分布
资源管理:
master:local进程本身
worker:local进程本身
任务执行:
driver:local进程本身(driver可以理解为有时候做管理(local),有时候做工人)
executor:不存在,由local进程内的线程提供计算能力(executor可以理解为纯工人)local模式只能运行一个spark程序,如果执行多个spark程序,需要多个相互独立的local进程执行
搭建
centos装好系统
anaconda、hadoop、spark、jdk安装anaconda
bash Miniconda-tab source .bashrc conda create -n pyspark python=3.8 -y- 1
- 2
- 3
- 4
- 5
安装spark、hadoop、spark
tar -zxvf spark-tab -C /export/server tar -xvf hadoop-tab -C /export/server tar -xvf jdk-tab -C /export/server ln -s spark-tab spark- 1
- 2
- 3
- 4
- 5
配置环境变量
vim /etc/profile export JAVA_HOME=/export/server/jdk export SPARK_HOME=/export/server/spark export HADOOP_HOME=/export/server/hadoop export PYSPARK_PYTHON=/root/miniconda3/envs/pyspark export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:HADOOP_HOME/sbin:$PATH vim ~/.bashrc export JAVA_HOME=/export/server/jdk export PYSPARK_PYTHON=/root/miniconda3/envs/pyspark- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
启动spark
# 在spark的bin目录下 # 1. 启动spark的python版本pyspark ./pyspark # 2. 带参数启动pyspark ./pyspark --master local[*] # 3. 启动spark-shell ./spark-shell # 4. 执行简单命令 sc.parallelize(Array(1,2,3,4,5)).map(x => x *10).collect() # 5. 执行spark-submit ./spark-submit --master local[*] /export/server/spark/examples/src/main/python/pi.py 10 # 执行圆周率的实例程序,迭代10次- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
功能名称 bin/spark-submit bin/pyspark bin/spark-shell 功能 提交java\scala\python代码到spark中运行 提供一个python 解释器环境用来以python代码执行spark程序 提供一个scala 解释器环境用来以scala代码执行spark程序 特点 提交代码用 解释器环境 写一行执行一行 解释器环境 写一行执行一行 使用场景 正式场合, 正式提交spark程序运行 测试\学习\写一行执行一行\用来验证代码等 测试\学习\写一行执行一行\用来验证代码等 local模式小结
运行原理
一个独立进程配合内部线程完成spark运行时环境;
local模式可以通过spark-shell/pyspark/spark-submit等开启bin/pyspark是什么程序
是一个交互式解释器执行环境,启动后得到一个local spark环境,运行python代码来进行spark计算
不同于python解释器,pyspark可以调用spark api完成spark计算spark的4040端口
spark任务启动后,driver所在机器绑定4040端口,提供当前任务的监控页面;
任务结束,则4040解绑;
多个任务,则分别绑定到多个不同端口spark环境搭建-standalone
standalone架构
local通过一个进程内的线程模拟spark运行环境
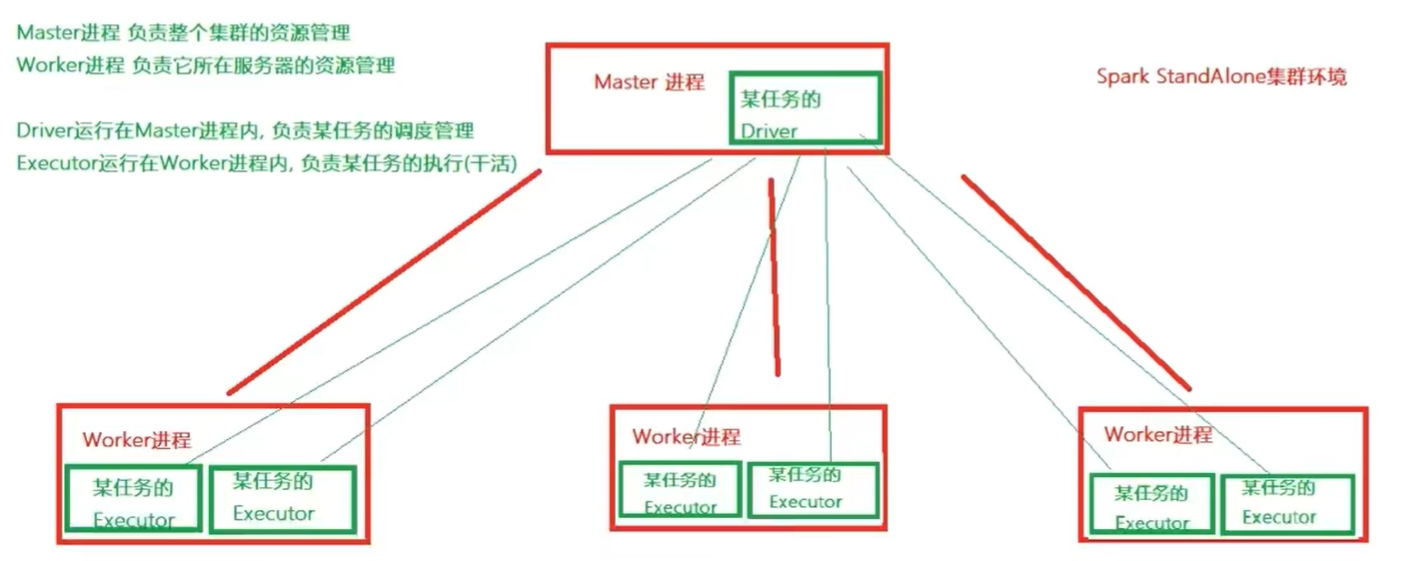
standalone是spark自带的一种集群环境,不同于local模拟,standalone真实地在多个机器之间搭建spark集群环境,可用于实际大数据处理standalone是完整的spark(分布式)运行环境
master以master进程存在(可多个master),worker以worker进程存在(可多个worker)
driver运行时存在master进程内,executor运行于worker进程内主要3类进程
- 主节点master进程:master角色,管理整个集群资源,托管运行各任务的driver
- 从节点worker:worker角色,管理每个机器的资源,分配对应资源(memory、cpu cores)来运行executor
- 历史服务器HistoryServer(可选):spark application运行完成后,保存事件日志数据到hdfs,启动HistoryServer可查看应用运行相关内容
master集群
driver任务
worker单机资源
executor某任务执行standalone部署
- 三台服务器(虚拟机,三台均如local配置部署即可)
node1\ node2\ node3 node1运行: Spark的Master进程 和 1个Worker进程 node2运行: spark的1个worker进程 node3运行: spark的1个worker进程 整个集群提供: 1个master进程 和 3个worker进程- 1
- 2
- 3
- 4
- 5
- 修改配置文件
# 切换到hadoop用户 chown -R hadoop:hadoop spark* su - hadoop cd conf # /export/server/spark/conf # 配置workers文件 mv workers.template workers vim workers # 指定workers node1 node2 node3 # 配置spark-env.sh文件 mv spark-env.sh.template spark-env.sh vim spark-env.sh # 追加以下内容 JAVA_HOME=/export/server/jdk HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop YARN_CONF_DIR=/export/server/hadoop/etc/hadoop export SPARK_MASTER_HOST=node1 # 指定master export SPARK_MASTER_PORT=7077 # 指定master的通讯端口 SPARK_MASTER_WEBUI_PORT=8080 # 指定master webui端口 SPARK_WORKER_CORES=1 # 可用cpu核心数 SPARK_WORKER_MEMORY=1g # 可用内存大小 SPARK_WORKER_PORT=7078 # worker工作通讯端口 SPARK_WORKER_WEBUI_PORT=8081 # worker webui端口 # 配置历史服务器:将spark程序运行的历史日志存到hdfs的/sparklog文件夹中 SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://node1:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true" # 在hadoop中查看是否存在sparklog文件夹 hadoop fs -ls / # 如果没有sparklog文件夹,则需要在hdfs上创建 hadoop fs -mkdir /sparklog hadoop fs -chmod 777 /sparklog # 配置spark-defaults.conf mv spark-defaults.conf.template spark-defaults.conf # 追加以下内容 spark.eventLog.enabled true # 开启spark的日期记录功能 spark.eventLog.dir hdfs://node1:8020/sparklog/ # 设置spark日志记录的路径 spark.eventLog.compress true # 设置spark日志是否启动压缩:减小体积,提升网络IO # 配置log4j.properties文件 [可选: 因为spark日志输出太多,看任务需求] mv log4j.properties.template log4j.properties vim log4j.properties log4j.rootCategory=WARN, console # 将INFO修改为WARN # 在其他node上也安装spark scp -r spark-3.1.2-bin-hadoop3.2 node2:/export/server/ scp -r spark-3.1.2-bin-hadoop3.2 node3:/export/server/ # 设置软链接 ln -s /export/server/spark-3.1.2-bin-hadoop3.2 /export/server/spark- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 启动历史服务器
sbin/start-history-server.sh # node1jps # 显示所有Java进程的pid xxx JobHistoryServer # hadoop yarn的历史记录服务器 xxx HistoryServer # spark的历史纪录服务器- 1
- 2
- 3
- 4
- 启动spark的master和worker进程
# 启动全部master和worker sbin/start-all.sh # 或者一个个启动: # 启动当前机器的master sbin/start-master.sh # 启动当前机器的worker sbin/start-worker.sh # 停止全部 sbin/stop-all.sh # 停止当前机器的master sbin/stop-master.sh # 停止当前机器的worker sbin/stop-worker.sh- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 查看master的webui
默认设置为8080,如果被占用则向后顺延
日志中查看到:Service 'MasterUI' could not bind on port 8080. Attempting port 8081.
通过master的webui界面,可以检查spark集群启动是否正常测试
cd /export/server/spark/binpyspark
在master的webui界面查看通讯地址
./pyspark --master spark://node1:7077连接到集群
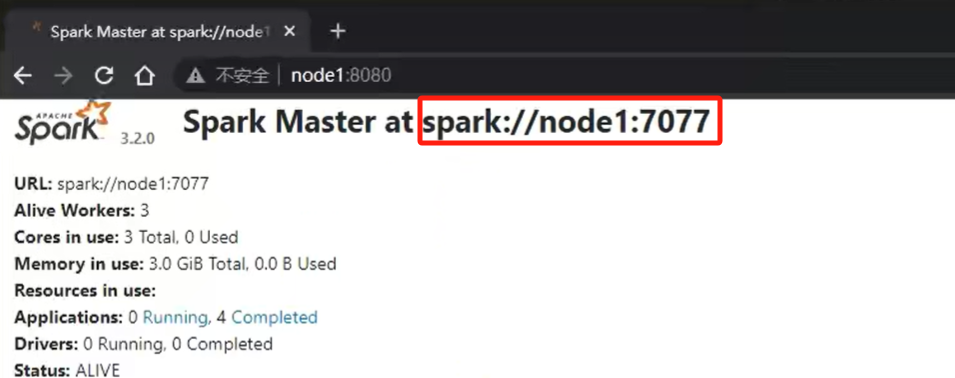
sc.parallelize([1,2,3,4,5]).map(lambda x: x*10).collect() # 运行简单的命令
任务结束后,driver结束,但master和worker仍在spark-submit
./spark-submit --master spark://node1:7077 /export/server/spark/examples/src/main/python/pi.py 100100次迭代计算圆周率
任务执行完成后,driver生命周期结束,通过历史服务器HistoryServer查看运行情况
历史服务器端口:18080
node1:18080中查看历史运行记录spark应用架构(层次结构)
一些监控页面
4040
是一个运行着的application在运行过程中临时绑定的端口,用以查看当前任务的状态
4040是一个临时端口,程序运行完成后即被注销(driver用)8080
默认standalone下master的web端口,用以查看master集群的状态
18080
默认历史服务器的端口,用以回看某个程序的历史运行状态
历史服务器长期稳定运行层级
一个应用程序
若干子任务
每个子任务的若干阶段
每个阶段由不同Task(线程)完成standalone模式小结
standalone原理
master和worker角色以独立进程形式存在,组成spark运行环境(集群 )
standalone中spark角色分布
master角色:master进程
worker角色:worker进程
driver角色:以线程运行在master中
executor角色:以线程运行在worker中standalone提交spark应用
bin/spark-submit --master spark://server:7077 xxx4040 8080 18080
4040:单个程序(driver)运行时的临时端口
8080:master的webui端口
18080:历史服务器job state task
job下若干state
state下若干task
一个spark程序会分为多个子任务(job),每个子任务会分为多个阶段(state),每个阶段会分成多个线程(task)来执行具体的任务spark环境搭建-standalone-ha
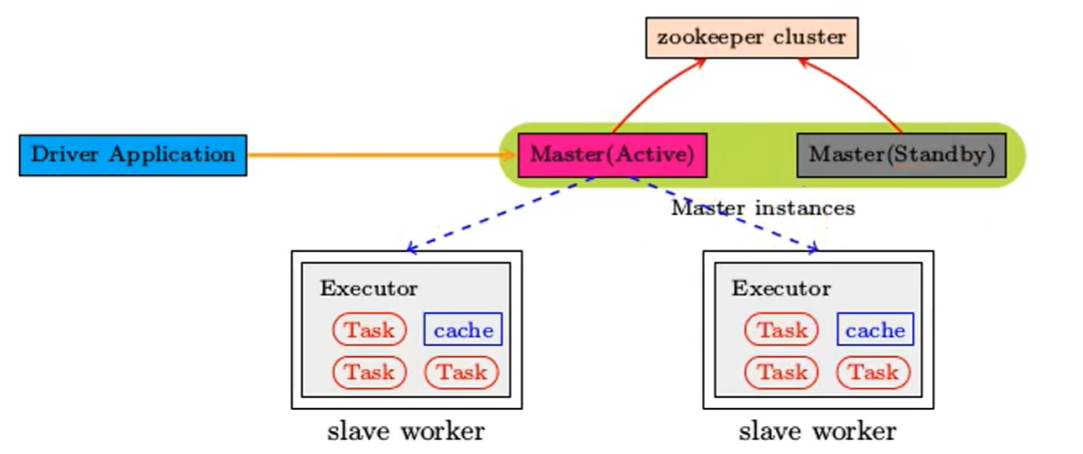
standalone集群是master-slaves架构的集群模式,存在单点故障问题(SPOF)
master宕机,则集群崩溃,所以要多个master来保证集群的资源分配高可用HA
spark解决单点故障问题的两种方案:
- 基于文件系统的单点恢复(Single-Node Recovery with Local File System):只限开发或测试
- 基于zookeeper的standby masters(standby masters with zookeeper):可用于生产
zookeeper提供leader election机制,保证集群中虽然有多个master,但只有一个保持活跃(active),其他都是standby。当活跃master出现故障时,standby master顶替。集群信息(worker,driver,application)都已持久化到文件系统,因此切换过程(有时间开销)只会影响job提交,正在进行的job不受任何影响。
基于zookeeper实现HA
启动zookeeper和hdfscd /export/server/spark/conf vim spark-env.sh # 修改为注释 # export SPARK_MASTER_HOST=node1 # 为了使用zookeeper动态切换master # 追加 SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=node1:2181,node2:2181,node3:2181 -Dspark.deploy.zookeeper.dir=/spark-ha"- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
standalone ha原理
基于zookeeper做状态维护,开启多个master,当活跃master宕机时,standby master能及时接管
spark环境搭建-spark on yarn
按前面方式部署,最优为standalone ha;
但企业服务器紧张,且不管什么业务基本都有Hadoop集群,也就是yarn集群;
standalone集群和yarn集群复用一套服务器资源利用率低,不如只使用yarn集群;
spark直接运行在yarn内,接受yarn调度;
对于spark on yarn,无需部署spark集群,只需一台服务器充当spark客户端,即可提交任务到yarn集群中运行spark on yarn本质
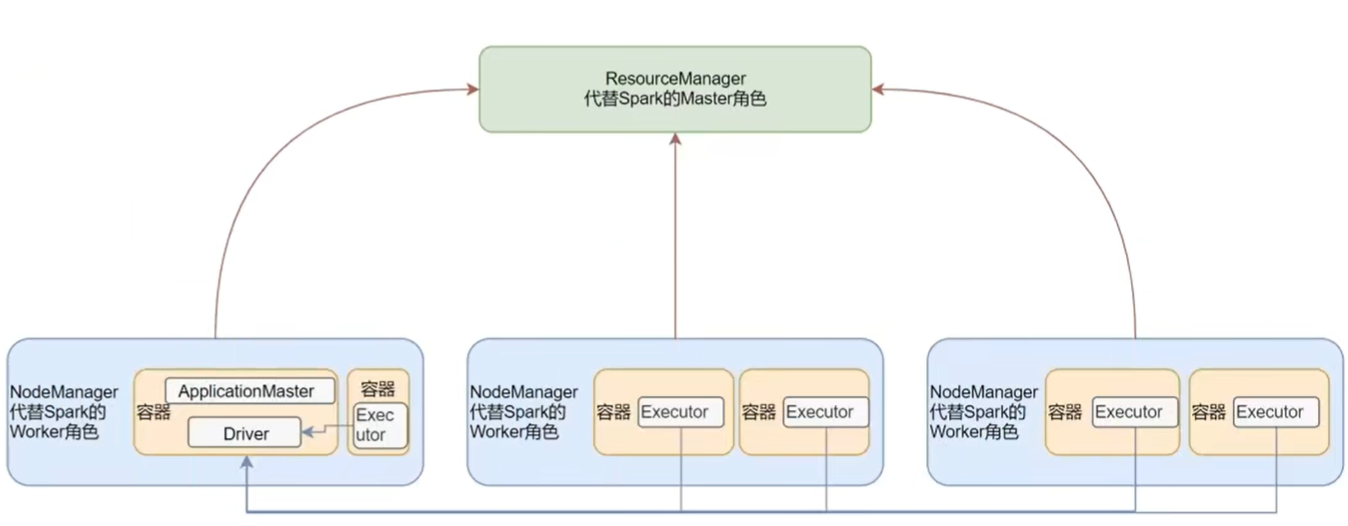
master角色由yarn的resourceManager担任
worker角色由yarn的nodeManager担任
driver角色运行在yarn容器内,或提交任务的客户端进程中
executor运行在yarn提供的容器内
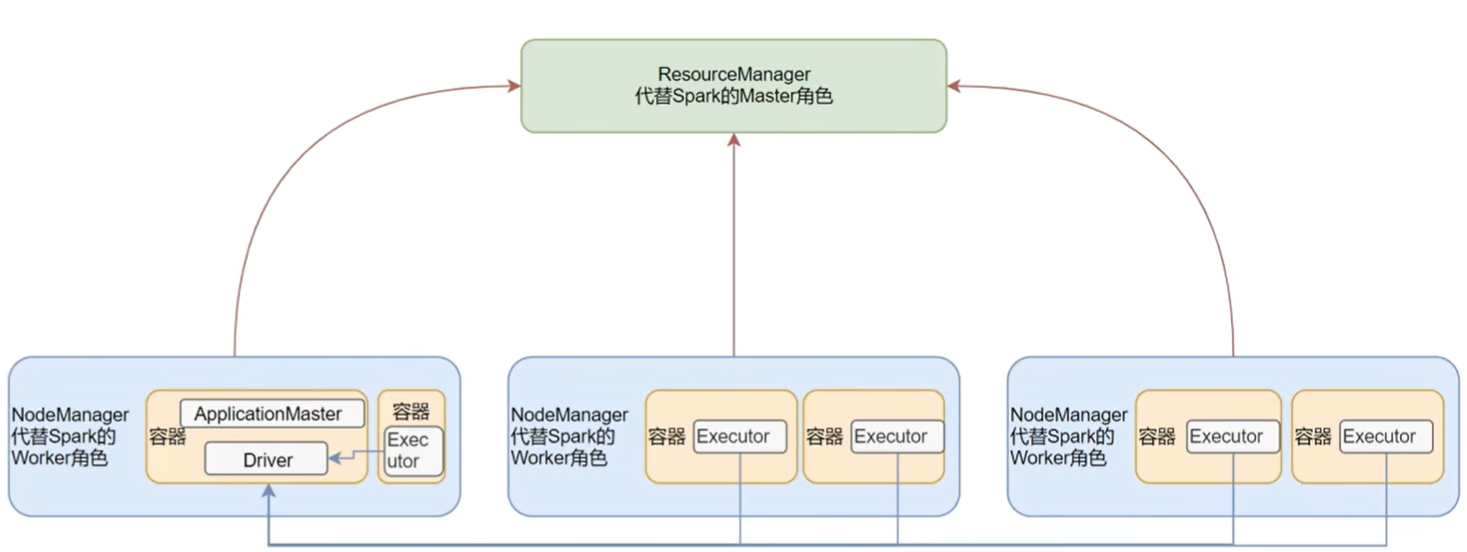
核心:让spark计算任务运行在yarn容器内部,资源管理交由resourceManager和nodeManager代替
spark on yarn的需求:- yarn集群
- spark客户端,如spark-submit,将spark程序提交到yarn中
- 被提交的代码,如pi.py等
spark on yarn环境配置
确保HADOOP_CONF_DIR YARN_CONF_DIR在spark-env.sh中配置了环境变量即可
bin/pyspark --master yarn --deploy-mode client|cluster # yarn中独有 --deploy-mode # 交互式环境pyspark和spark-shell只能运行客户端模式- 1
- 2
- 3
deployMode部署模式
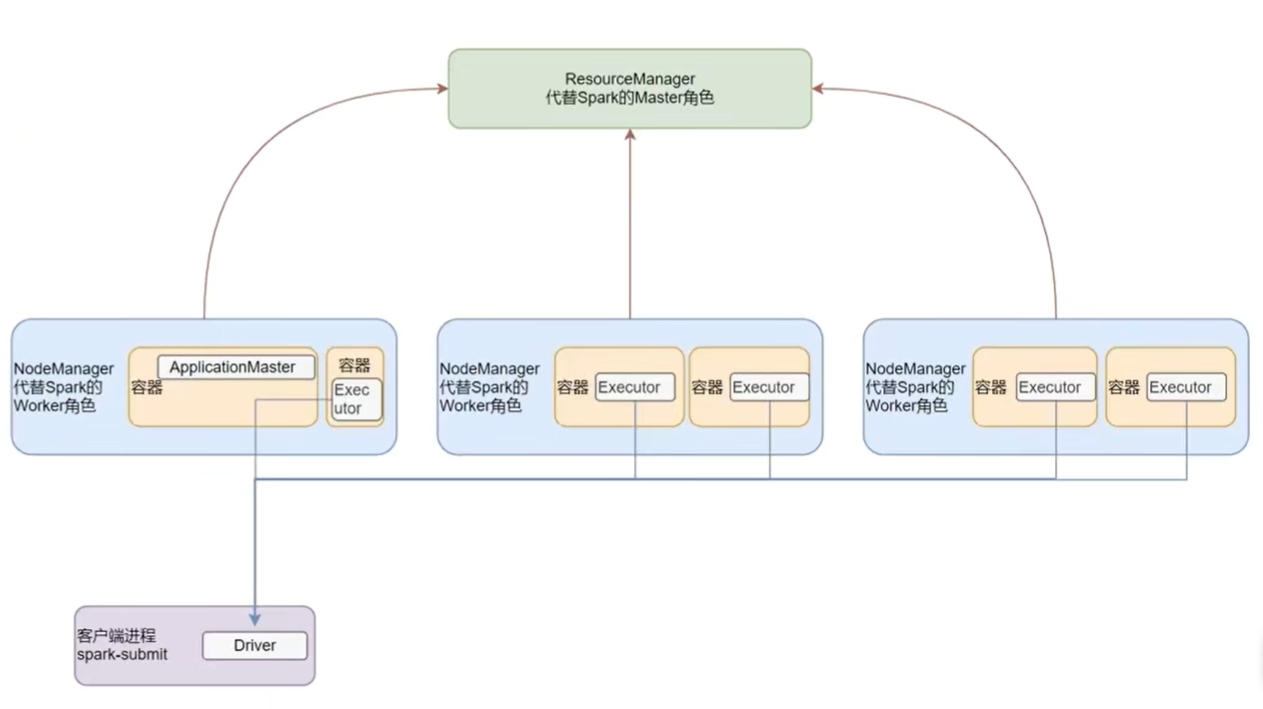
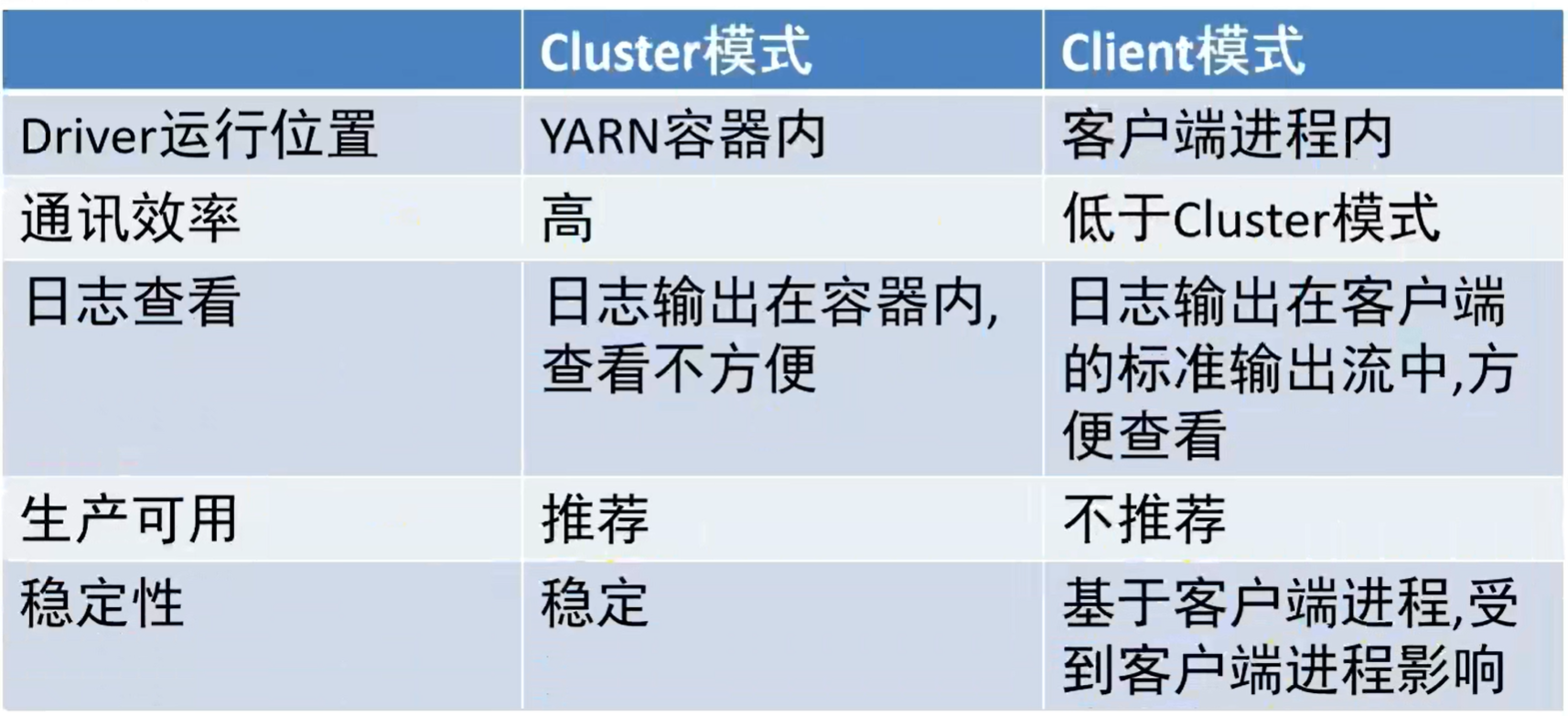
cluster模式和client模式
spark on yarn两种运行模式:Cluster集群模式、Client客户端模式
两种模式区别在于driver运行位置
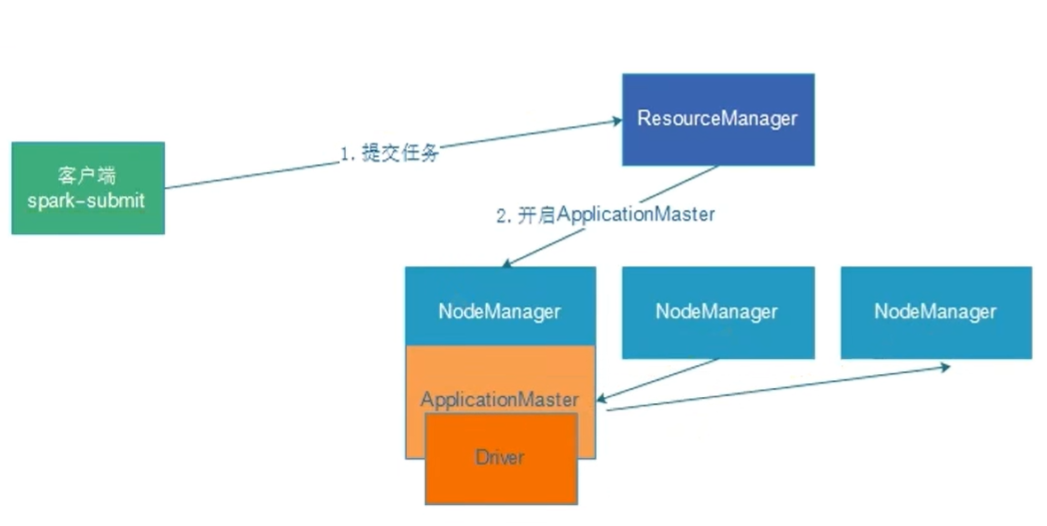
cluster模式:driver运行在yarn内部,和applicationManager在同一个容器内部
client模式:driver运行在客户端进程中,如driver运行在spark-submit程序的进程中cluster模式
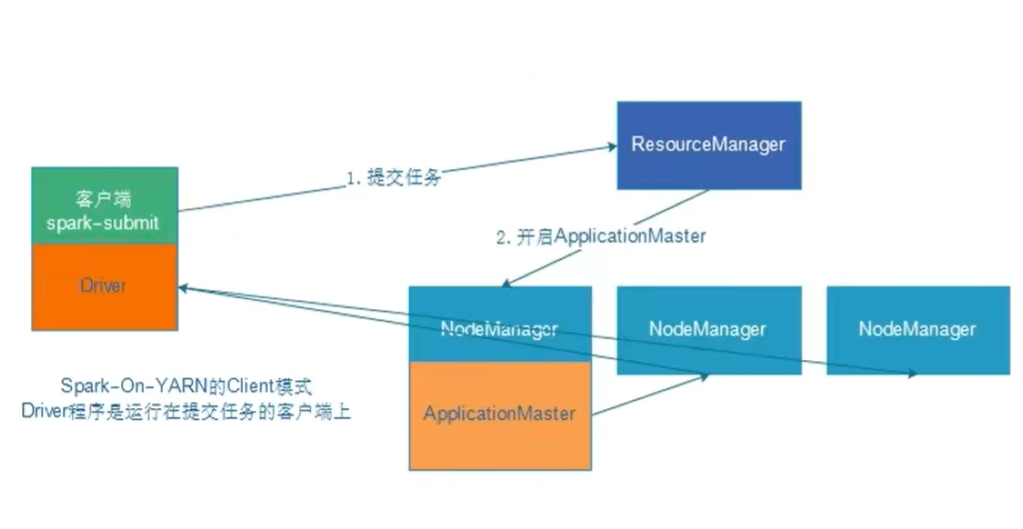
client模式
cluster模式:- 效率高,直接在容器内通信,集群通信成本低
- 查看日志困难,日志也是容器内日志
- 集群模式下driver运行在applicationMaster节点上,由yarn管理,出现问题yarn会重启applicationMaster(driver)
client模式(方便,但性能低稳定差,生产不推荐):
- 容易看日志,日志是客户端日志
- 效率低,需要跨容器通信,通信成本高
client模式测试
# 客户端模式 bin/spark-submit --master yarn --deploy-mode client --driver-memory 512m --executor-memory 512m --num-executors 3 --total-executor-cores 3 /export/server/spark/examples/src/main/python/pi.py 100 # 集群模式 bin/spark-submit --master yarn --deploy-mode cluster --driver-memory 512m --executor-memory 512m --num-executors 3 --total-executor-cores 3 /export/server/spark/examples/src/main/python/pi.py 100- 1
- 2
- 3
- 4
拓展:两种模式详细流程
yarn的client模式下,driver在任务提交的本地机器上运行
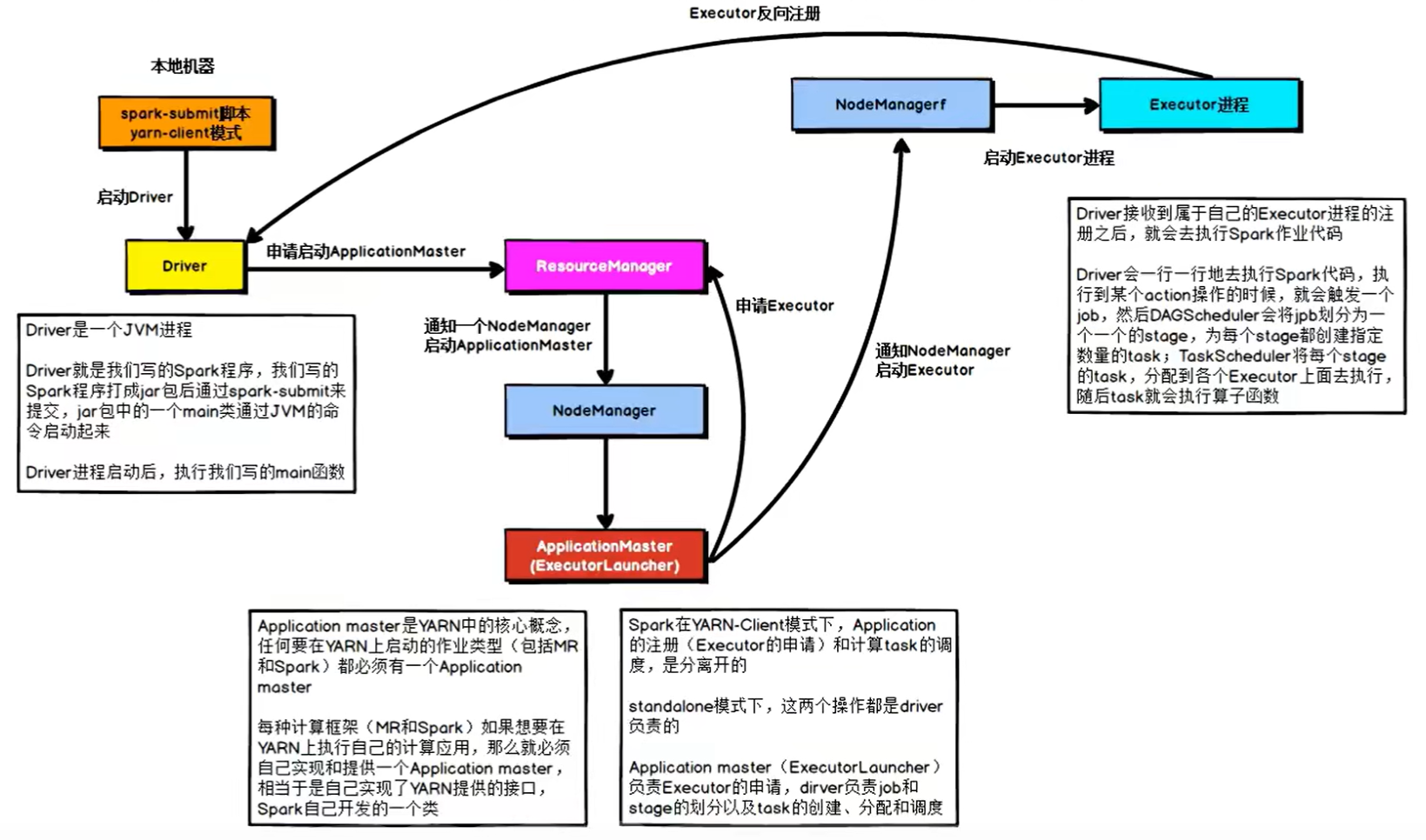
- Driver在任务提交的本地机器上运行,Driver启动后会和ResourceManager通讯申请启动ApplicationMaster;
- 随后ResourceManager分配Container,在适的NodeManager上启动ApplicationMaster,此时的ApplicationMaster的功能相当于一个ExecutorLauncher,只负责向ResourceManager申请Executor内存;
- ResourceManager接到ApplicationMaster的资源申请后会分配Container,然后ApplicationMaster在资源分配指定的NodeManager上启动Executor进程
- Executor进程启动后会向Driver反向注册,Executor全部注册完成后Driver开始执行main函数
- 之后执行到Action算子时,触发一个Job,并根据宽依赖开始划分stage,每个Stage生成对应的TaskSet,之后将Task分发到各个Executor上执行。
yarn的cluster模式下,driver运行在nodeManager容器内,driver与applicationMaster一体:
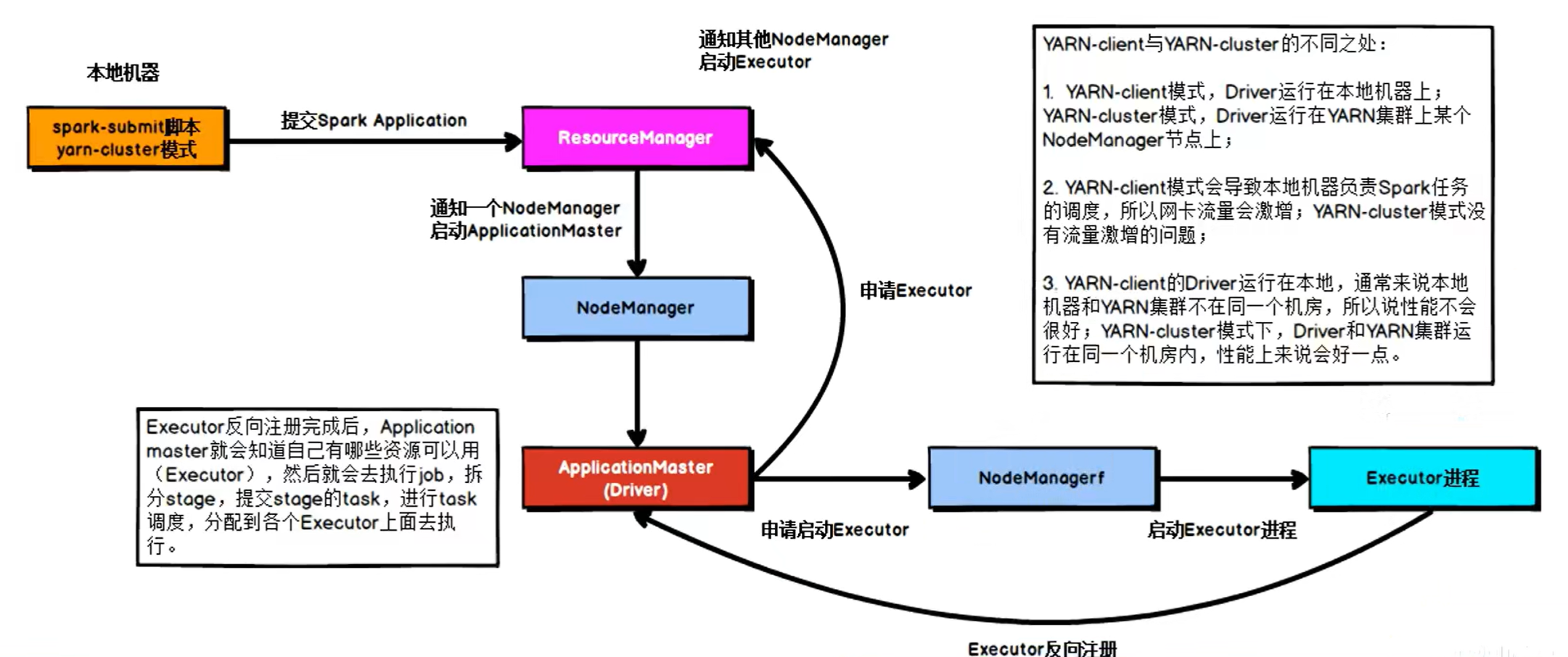
总结
spark on yarn本质
master由resourceManager代替
worker由nodeManager代替
driver可运行在容器中(cluster),也可运行在客户端上(client)
executor全部运行在yarn容器中why spark on yarn?
提高资源利用率,在已有yarn场景下使得spark受到yarn的调度,来更好地管理资源、调度资源
pyspark安装
框架、类库
类库:可重用的代码库,如numpy、pandas
框架:可以独立运行,并提供编程结构的一种软件产品,如sparkbin/pyspark 是一个应用程序,客户端程序,提供python解释器来运行spark命令
pyspark类库 import pysparkpyspark类库
pyspark是spark官方提供的一个python类库,内置完全的spark api
pyspark安装
pip install pyspark总结
pyspark:类库,提供spark api
bin/pyspark:交互式应用程序本机开发环境搭建(windows)
windows环境配置
将文件包中的hadoop3.3.0复制进windows中,将其hadoop.dll复制进
c:\windows\system32文件夹下,将hadoop3.3.0文件夹路径加如系统环境变量中HADOOP_HOME:xxx\hadoop3.3.0应用入口
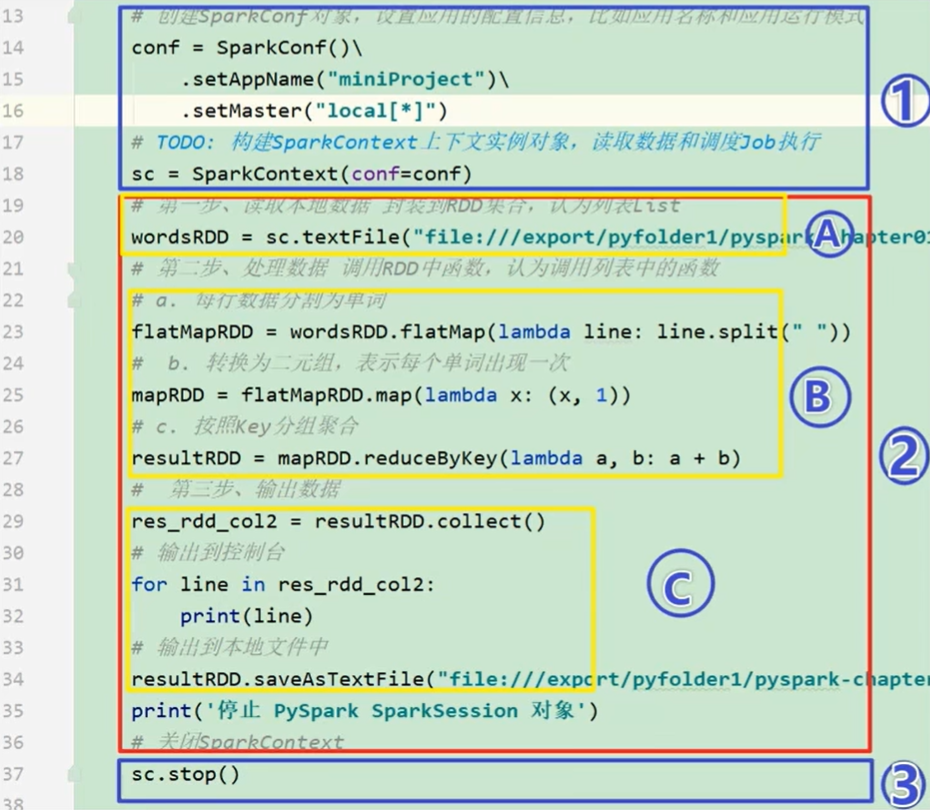
spark application程序入口为sparkContext,任何一个应用首先需要构建sparkContext对象:
- 创建SparkConf对象:设置spark application基本信息,如应用名称AppName、应用运行Master等
- 基于SparkConf对象,创建SparkContext对象
conf = Sparkconf().setAppName(appName).setMaster(master) sc = SparkContext(conf=conf) from pyspark import SparkConf, SparkContext if __name__ == '__main__': conf = Sparkconf().setAppName('WordCount').setMaster('local[*]') # 如果是yarn模式,就不要设置master sc = SparkContext(conf=conf) # 读取hdfs的word.txt,统计单词出现的数量 file_rdd = sc.textFile('hdfs://ndoe1:8020/input/word.txt') # rdd 弹性分布式数据集;;最好是hdfs地址,文件都可以访问到 words_rdd = file_rdd.flatMap(lambda line: line.split(" ")) words_with_one_rdd = words_rdd.map(lambda x: (x, 1)) result_rdd = words_with_one_rdd.reduceByKey(lambda a,b:a+b) print(result_rdd.collect())- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
总结
python开发spark
主要是获取sparkContext对象,基于sparkContext对象作为环境入口
如何提交spark应用
代码上传到服务器上,通过spark-submit工具提交
- 代码中不要设置master,代码中优先级更高
- 读取的文件一定是各个机器都能读取到的地址(分布式计算),如HDFS
分布式代码执行
spark集群角色
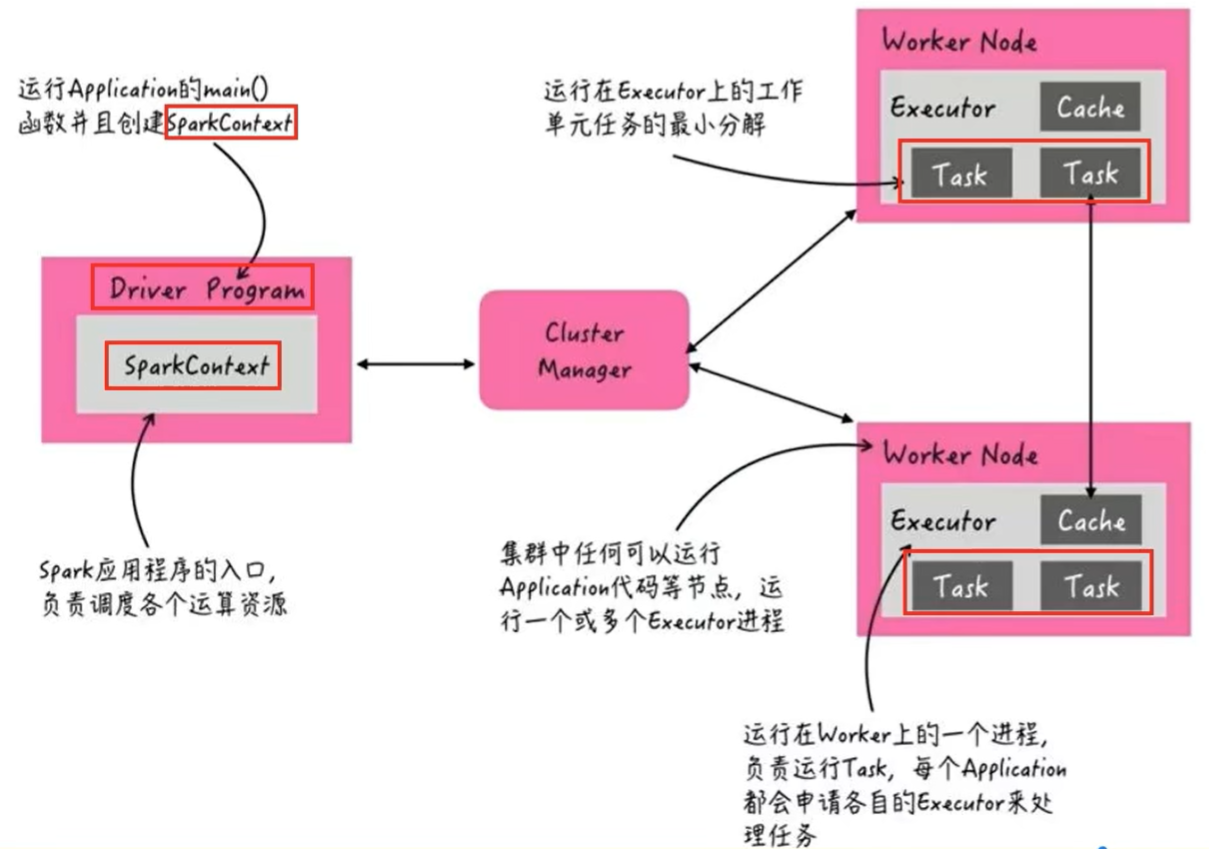
当spark application运行在集群上时,主要有四个部分:- master(resourceManager):集群资源管理
- worker(nodeManager):单机资源管理
- driver:单个spark任务管理,相当于yarn的applicationMaster
- executor:spark的工作任务Task都由executor负责执行
application->job->stage -> task
分布式代码执行分析
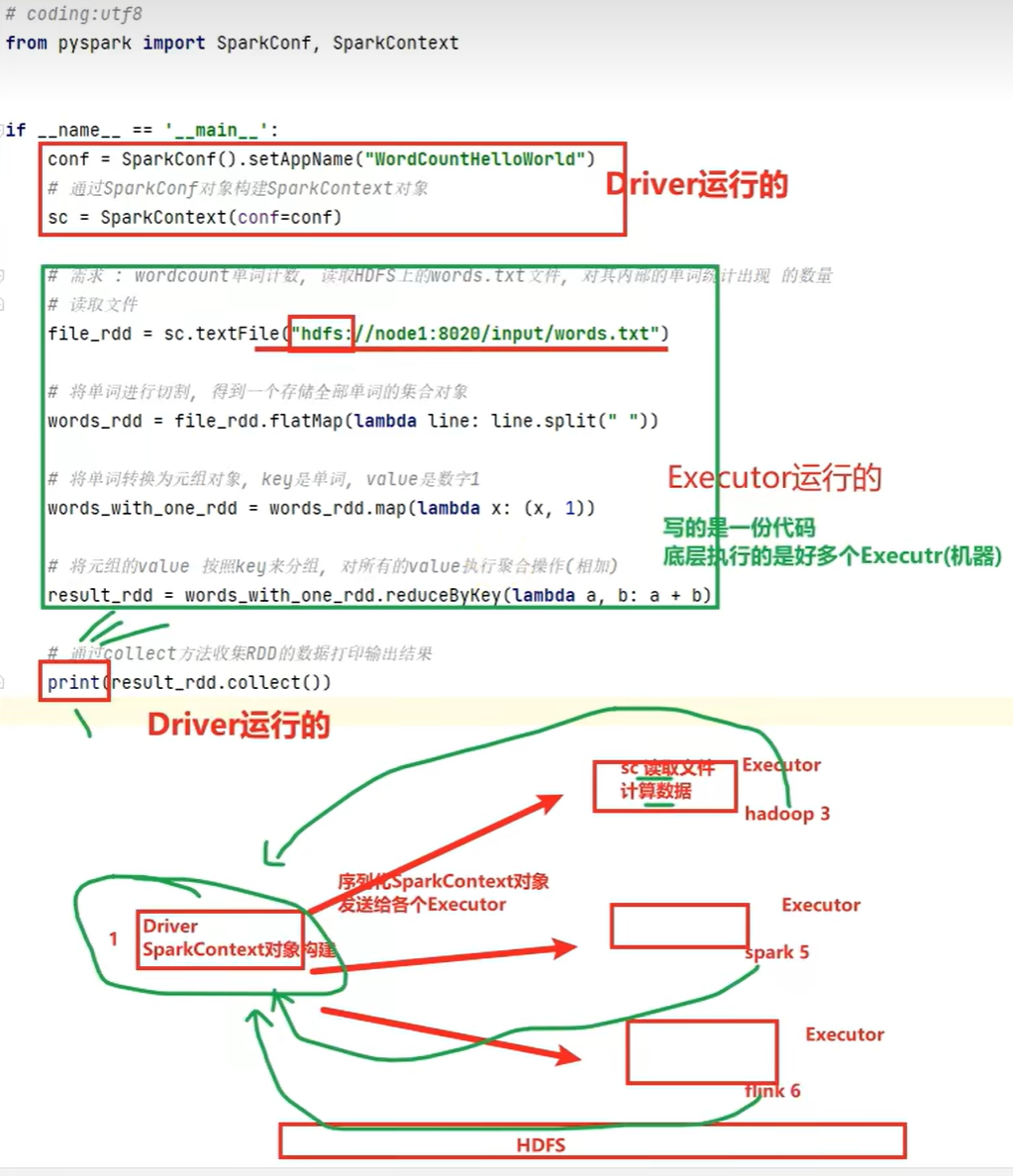
python on spark原理

简言之:driver跑的JVM(翻译);executor跑的python(中转调度)
两套语言运行
pyspark宗旨是不破坏spark已有的运行时架构(Java系),在spark架构外层包装一层python api,借助Py4j实现python和Java交互,进而实现通过python编写spark应用程序

总结
分布式代码执行的重要特征
代码在集群上运行,则是被分布式运行的(一份代码,分布式运行)
spark中,非任务处理部分由driver执行(非rdd);任务处理部分由executor执行(rdd)
executor数量很多,所以任务的计算是分布式运行的pyspark架构体系
spark on python:
driver端由jvm执行;executor端由jvm做命令转发,底层由python解释器工作 -
相关阅读:
使用Docker部署开源分布式任务调度系统DolphinScheduler
Biome-BGC生态系统模型与Python融合
numpy在数字图像处理中的应用
lab3_系统调用(下)
快速掌握Nginx部署前端项目(从Nginx安装配置及部署都非常详细哦!)
mysql5.7.35安装配置教程【超级详细安装教程】
Toronto Research Chemicals盐酸乙环胺应用说明
【JVM笔记】方法区的演进细节
CompassArena 司南大模型测评--代码编写
sql语句实现查询
- 原文地址:https://blog.csdn.net/CSDN_Ethan2086/article/details/136256986
