-
EI级 | Matlab实现TCN-GRU-MATT、TCN-GRU、TCN、GRU多变量时间序列预测对比
EI级 | Matlab实现TCN-GRU-MATT、TCN-GRU、TCN、GRU多变量时间序列预测对比
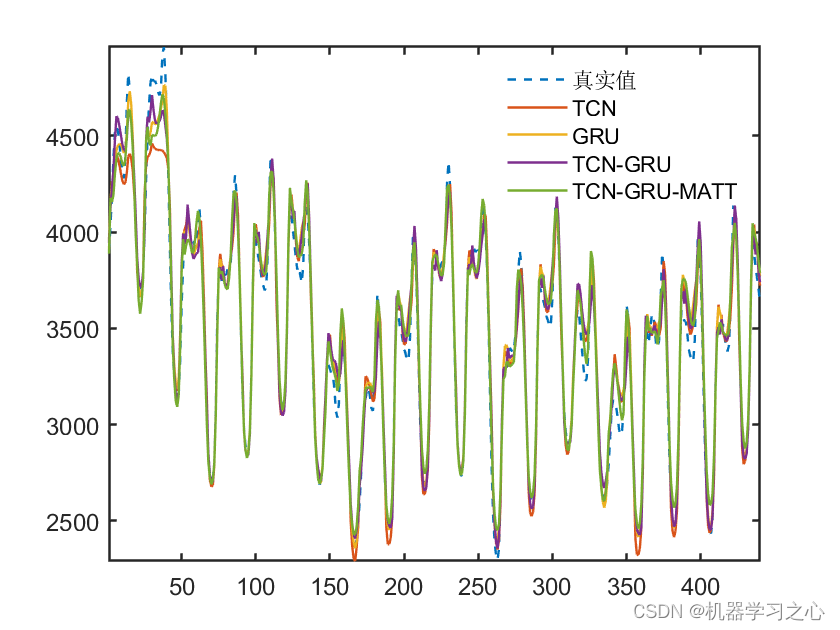
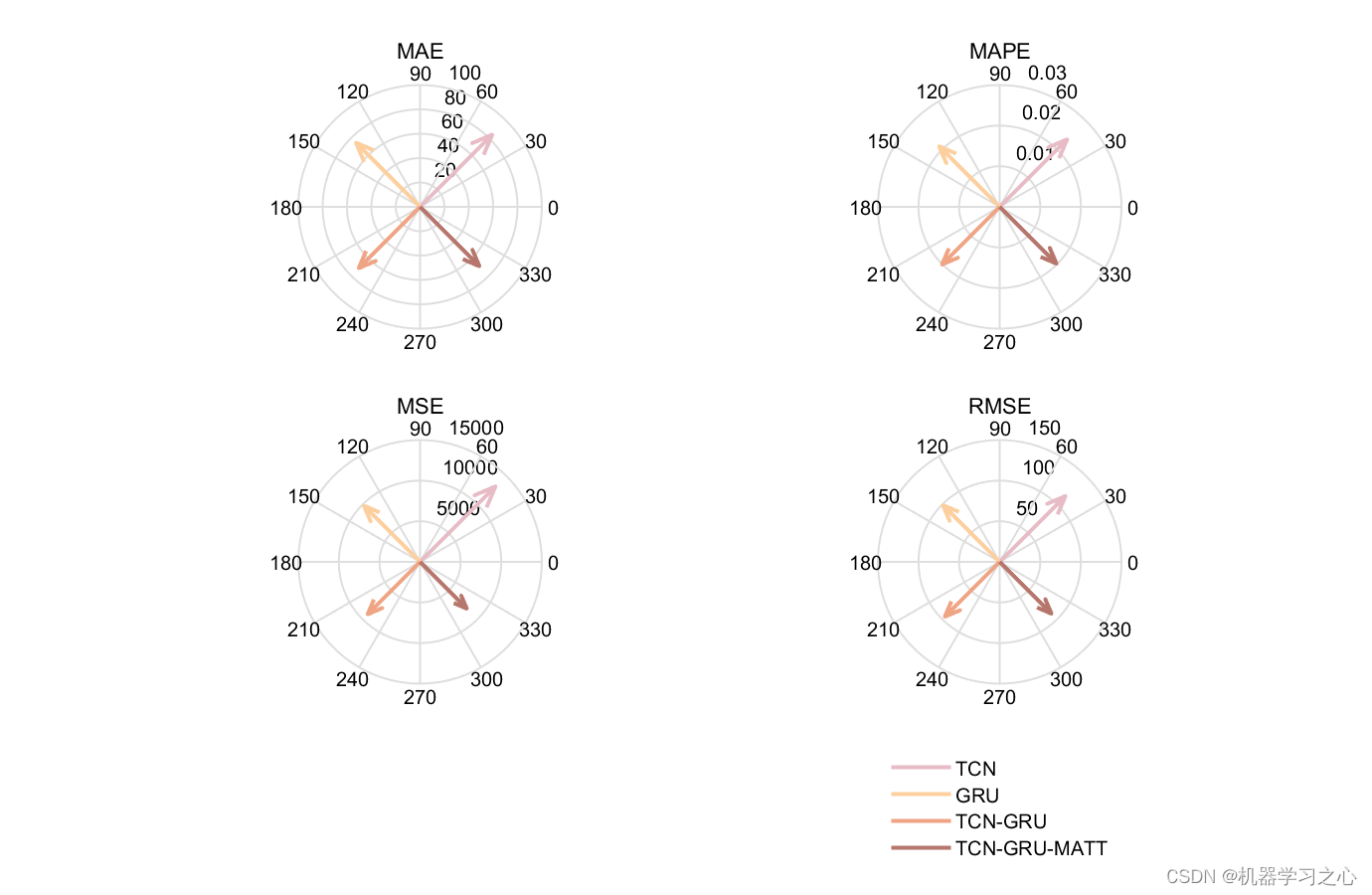
预测效果

基本介绍
【EI级】Matlab实现TCN-GRU-MATT、TCN-GRU、TCN、GRU多变量时间序列预测对比
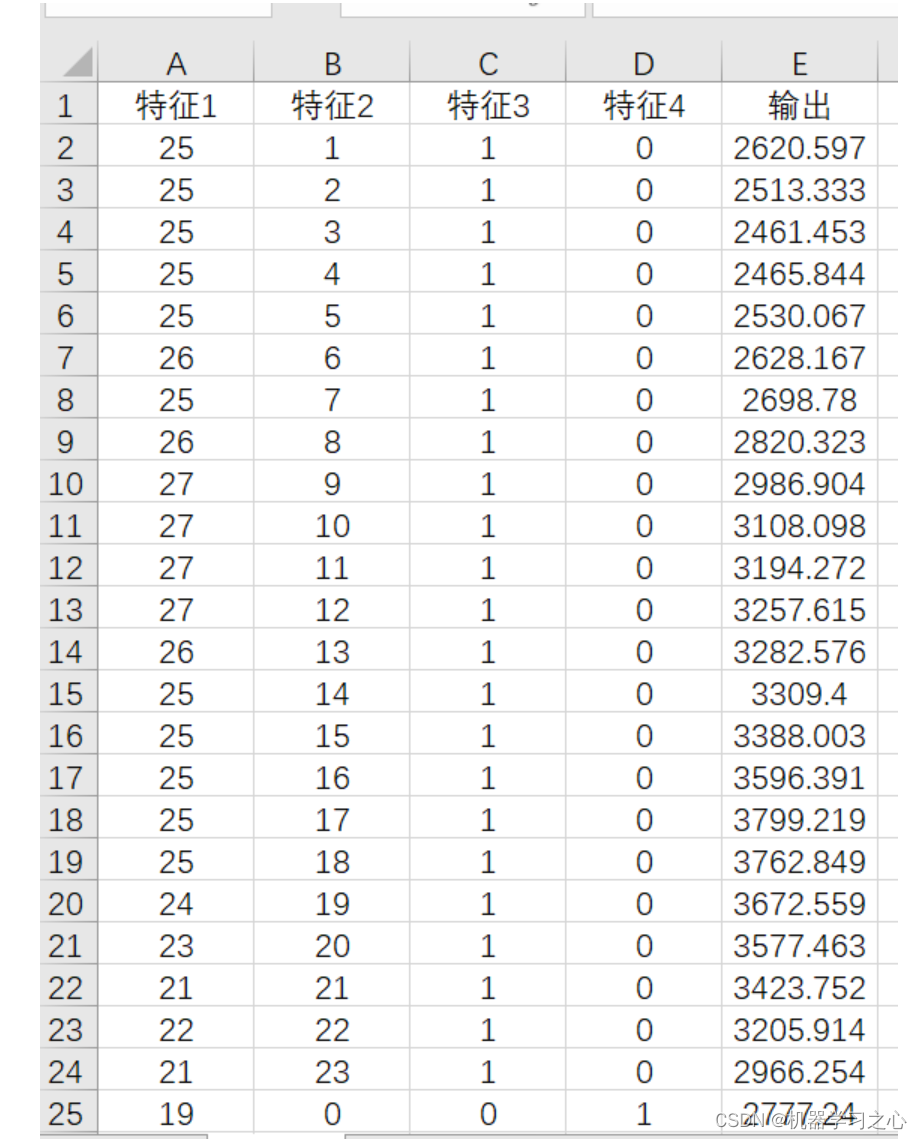
1.data为数据集,格式为excel,4个输入特征,1个输出特征,考虑历史特征的影响,多变量时间序列预测;
2.Mian1_TCN.m(时间卷积神经网络)、Mian2_GRU.m(门控循环单元)、Mian3_TCN_GRU.m(时间卷积门控循环单元)、Mian4_TCN_GRU_MATT.m(时间卷积门控循环单元融合多头注意力机制)为主程序文件,运行即可;
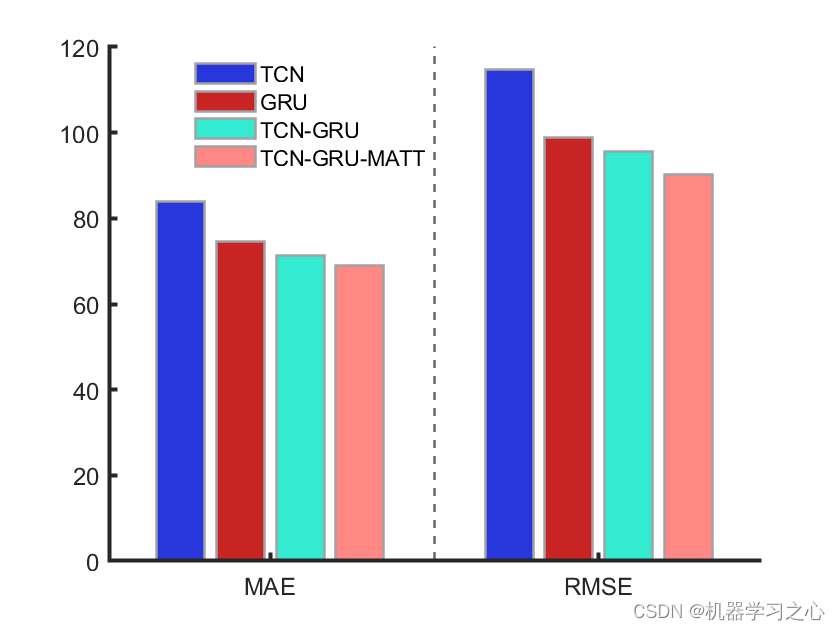
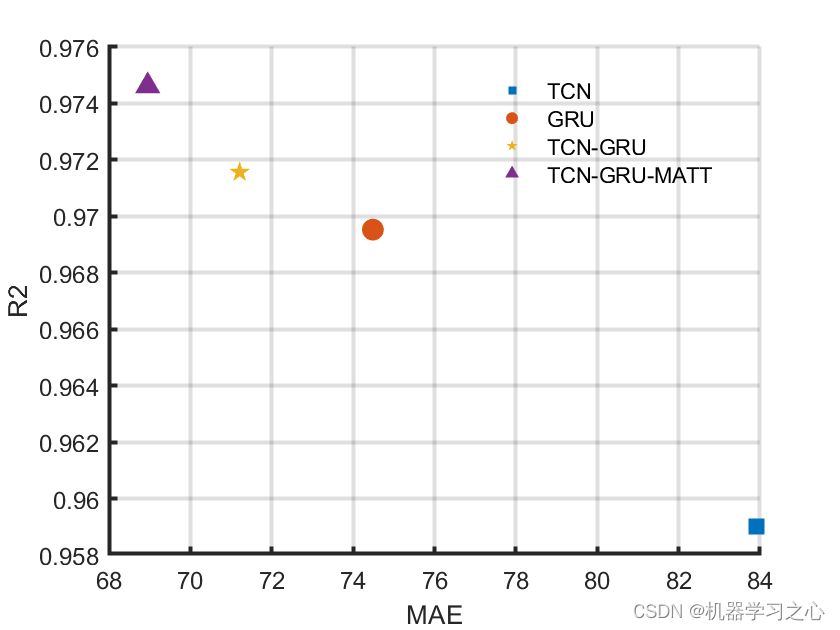
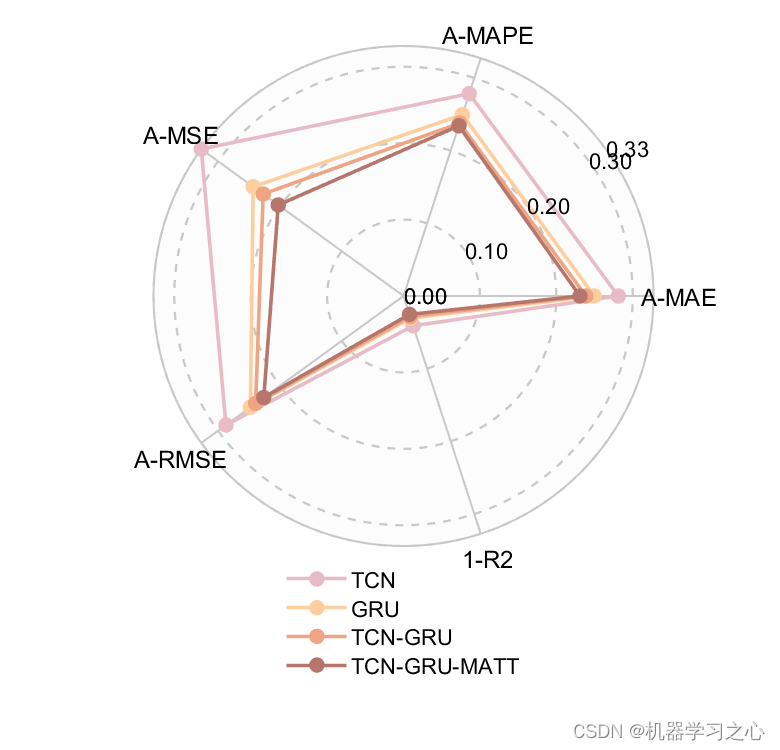
3.命令窗口输出R2、MAE、MAPE、MSE和RMSE,可在下载区获取数据和程序内容;
注意程序和数据放在一个文件夹,运行环境为Matlab2023a及以上。
多头自注意力层 (Multihead-Self-Attention):Multihead-Self-Attention多头注意力机制是一种用于模型关注输入序列中不同位置相关性的机制。它通过计算每个位置与其他位置之间的注意力权重,进而对输入序列进行加权求和。注意力能够帮助模型在处理序列数据时,对不同位置的信息进行适当的加权,从而更好地捕捉序列中的关键信息。在时序预测任务中,注意力机制可以用于对序列中不同时间步之间的相关性进行建模。数据集:
程序设计
- 完整程序和数据获取方式私信博主回复Matlab实现TCN-GRU-MATT、TCN-GRU、TCN、GRU多变量时间序列预测对比。
% 训练集和测试集划分 outdim = 1; % 最后一列为输出 num_size = 0.7; % 训练集占数据集比例 num_train_s = round(num_size * num_samples); % 训练集样本个数 f_ = size(res, 2) - outdim; % 输入特征维度 P_train = res(1: num_train_s, 1: f_)'; T_train = res(1: num_train_s, f_ + 1: end)'; M = size(P_train, 2); P_test = res(num_train_s + 1: end, 1: f_)'; T_test = res(num_train_s + 1: end, f_ + 1: end)'; N = size(P_test, 2); % 数据归一化 [p_train, ps_input] = mapminmax(P_train, 0, 1); p_test = mapminmax('apply', P_test, ps_input); [t_train, ps_output] = mapminmax(T_train, 0, 1); t_test = mapminmax('apply', T_test, ps_output); % 参数设置 options0 = trainingOptions('adam', ... % 优化算法Adam 'MaxEpochs', 150, ... % 最大训练次数 'GradientThreshold', 1, ... % 梯度阈值 'InitialLearnRate', 0.01, ... % 初始学习率 'LearnRateSchedule', 'piecewise', ... % 学习率调整 'LearnRateDropPeriod',100, ... % 训练100次后开始调整学习率 'LearnRateDropFactor',0.001, ... % 学习率调整因子 'L2Regularization', 0.001, ... % 正则化参数 'ExecutionEnvironment', 'cpu',... % 训练环境 'Verbose', 1, ... % 关闭优化过程 'Plots', 'none'); % 画出曲线- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
参考资料
[1] https://blog.csdn.net/kjm13182345320/category_11799242.html?spm=1001.2014.3001.5482
[2] https://blog.csdn.net/kjm13182345320/article/details/124571691 -
相关阅读:
ESP8266--SDK开发(延时、定时器)
数据通信习题——期中测试
linux systemctl删除失效的服务单元
springboot小型命题系统毕业设计源码011508
Canal使用和安装总结
Java面试
1003 Emergency
百趣代谢组学资讯:@熬夜的年轻人代谢紊乱急救包-喝普洱茶!
javascript流程控制(2)
Stable Diffussion和MJ的详细对比
- 原文地址:https://blog.csdn.net/kjm13182345320/article/details/136179958