-
数据分析 - 机器学习
1:线性回归
线性回归是一种统计技术用于对输出变量与一个或多个输入变量之间的关系进行建模
用外行人的话来说,将其视为通过某些数据点拟合一条线,如下所示
以便在未知数据上进行预测,假设变量之间存在线性关系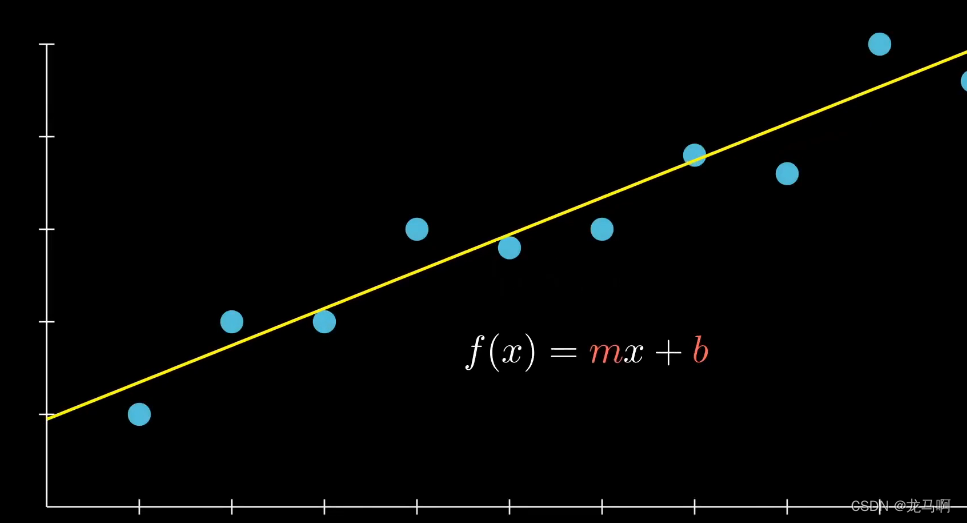
点和线之间存在微小的差异,被称为残差
他们是数据点和预测线之间的差异
取每个残差并对他们进行平方,得到平方误差,残差越大正方形的面积就越大
如果我们将给定线的所有这些正方形的面积相加,我们将得到平方误差的总和这就是我们的损失函数我们将三分之一的数据并将其放入测试数据集中,剩余的三分之二将成为训练数据集,
然后使用训练数据集来拟合回归线,
然后,测试数据集将用于验证回归线,
这样做是为了确保回归在之前未见过的数据上表现良好。决策树
决策树:为了达到目标根据一定条件进行选择的过程
常用语:房地产、银行,为了找到核心客户的学习方法
常被用于分类和回归
决策树由 根节点,子节点、叶子节点
决策树的分类标准:熵 (表示一个系统内在的混乱程度)熵代表是分支下样本种类的丰富性
样本种类越多越混乱,熵值越大,决策树的构造深度就是熵值的降低,熵值降低越快,代表决策树分类效率越高
决策树最大的优点是 天然的可解释性的,数据自动处理
缺点就是 不会存在完美的决策树,如果存在就是过拟合了
防止过拟合就是剪枝剪枝有两种:预剪枝和后剪枝
预剪枝是在训练开始前规定条件,比如树达到某一深度就停止训练
后剪枝则是先找到树,再根据一定条件如限制叶子节点的个数,去掉一部分分支随机森林
随机森林里面有很多决策树
随机森林是决策树的升级版
随机指的是树的生长过程
随机森林中的树也是各不相同
在构建决策树时,我们也不会使用数据的全部特征,而是随机选取部分特征进行训练,
每棵树使用的样本特征各不相同,训练的结果自然也各不相同
我们并不知道哪些是异常样本
也不知道哪些特征对分类结果影响更大,随机的过程降低了两者对分类结果的影响
随机森林的输出结果由投票决定,如果大部分决策认为测试数据是好苹果,那我们就认为它是好苹果,这很像人类的民主决策
推理过程和结论各不相同,但当每个人都拥有投票权时,往往能做出较优的决策,因为树与树之间的独立,它们可以同时训练,不需要花太多时间。
随机的过程让它不容易拟合,能处理特征较多的高维数据
也不需要做特征选择,合理训练后准确性很高,不知道使用什么分类方法时
先试一试随机森林准没错
在机器学习中随机森林属于集成学习,也就是将多个模型组合起来解决问题
这些模型会独立、预测、在投票出结果,准确性往往比单独的模型高很多聚类
k-mean
k 表示样本数,把数据分为几类
将一群无标签数据,按特征属性,分为有标签属性例如:有一个很多水果,但是很混乱,我不知道有哪几种水果,
-
相关阅读:
SpringBoot集成支付宝 - 少走弯路就看这篇
【maven下载、安装、配置教程】
【前端源码解析】AST 抽象语法树
下载免费的ip+构建ip地址池访问网站详细教程
MQ - 17 集群篇_(性能)分布式存储系统的编程技巧
CodeWhisperer proxy代理连不上(解决)
Java基础:Java虚拟机JVM
Linux 可执行文件瘦身指令 strip 使用示例
应用zabbix的实时导出(real-time export)功能
Mac远程访问Windows服务器
- 原文地址:https://blog.csdn.net/qq_43853213/article/details/136166037