-
利用多核的Rust快速Merkle tree
1. 引言
利用多核的Rust快速Merkle tree,开源代码见:
其具有如下属性:
- 可调整为任意高度
- 构建root复杂度为O(n)
- 提供了插入和获取叶子节点的方法
- 获取某叶子节点的opening proof,并基于某root验证该proof
- 抽象化的哈希函数,可任意替换为其它哈希函数。
- 默认叶子节点为h(0)
- 可选择使用multi processing(多重处理)
cargo test来做测试用例测试。cargo bench来做benchmark。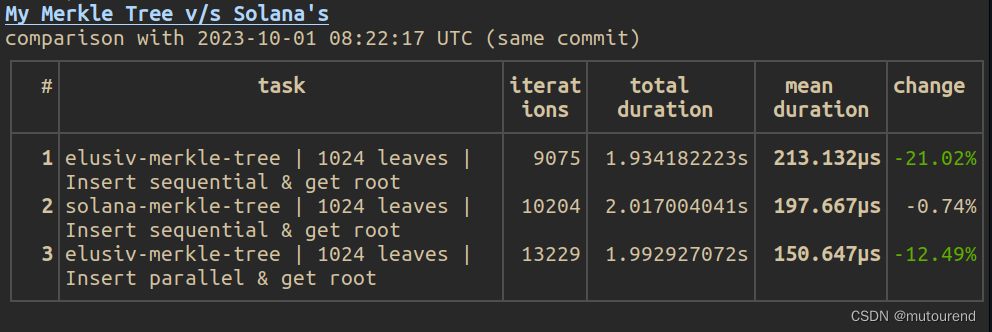
在做代码优化时,通常需权衡代码效率和代码可读以及可维护性。
https://github.com/anoushk1234/fast-merkle-tree 代码实现和优化时,试图兼顾了三者(效率、可读性、可维护性)。具体的算法优化有:
- 1)由于所有的叶子节点都预填充了默认值,实际插入时,无法简单将data hash推入,直观方法是轮询找到某叶子节点然后替换为data hash。这样复杂度为
O
(
n
!
)
O(n!)
O(n!)。本文会记录Merkle tree的当前可添加叶子节点的index,这样有助于跟踪那个index可被替换,从而将插入平均时长缩短了约800ms。
之前方案:

现在方案:

- 2)由于已知Merkle tree的容量,可提前预分配向量,来节约在heap中没必要的分配,从而节约调用syscall的开销(因需做上下文切换)。
- 3)将DEFAULT_LEAF等值用作常量值,节约在运行时对其进行哈希的时间。
同时,还做了如下并行优化:
- 1)不是顺序插入叶子节点,而是使用多个线程来哈希叶子节点,然后一次性附加到数组中,可节约约70ms到80ms的时间。
- 2)即使对Merkle tree进行了预填充,由于向量已分配,可使用
par_extend来并行预填充,但性能改进可忽略,此处倾向于简化for循环中的逻辑。
代码可读性改进:
- 1)当计算level length或tree height时,可使用浮点数计算,如:
(current_level_len as f64 / 2.0).ceil() as usize- 1
if current_level_len % 2 == 0 { current_level_len / 2 } else { (current_level_len + 1) / 2 }- 1
- 2
- 3
- 4
- 5
未来性能改进点:
- 1)AVX-512 Accelarated SHA256,已有一些开源实现。
- 2)定制Heap Allocator:使用定制allocator来分配单个dram page,然后每次需给向量分配heap时,使用该定制allocator。可节约向内核做syscall的额外开销。类似如Hoard Allocator。
- 3)向量化:不同于 使用多个变量来存储不同的值,可使用搭个matrix/vector来存储不同的值。但这将牺牲可读性。
- 4)使用Blake4而不是SHA-256。
-
相关阅读:
JAVA医药进销存管理系统(附源码+调试)
计算机服务器中了DevicData勒索病毒怎么办?DevicData勒索病毒解密数据恢复
珠宝饰品经营小程序商城的作用是什么
销售管道管理软件推荐:提升销售业绩与效率
[面试直通]操作系统核心之存储系统(上)
七周成为数据分析师 | 数据可视化
excel 如何自动调整行间距 vba
什么是轮式里程计
IDEA中使用Git,Github,Gitee
什么?你还不会JVM调优?
- 原文地址:https://blog.csdn.net/mutourend/article/details/134528599