-
Triage沙箱监控
Triage沙箱可以免费分析恶意软件样本。最先进的恶意软件分析沙箱,具有您需要的所有功能。
在可定制的环境中提交大量样本,并对许多恶意软件系列进行检测和配置提取。立即查看公开报告并对您的恶意软件进行分类!
官方网址:https://tria.ge/
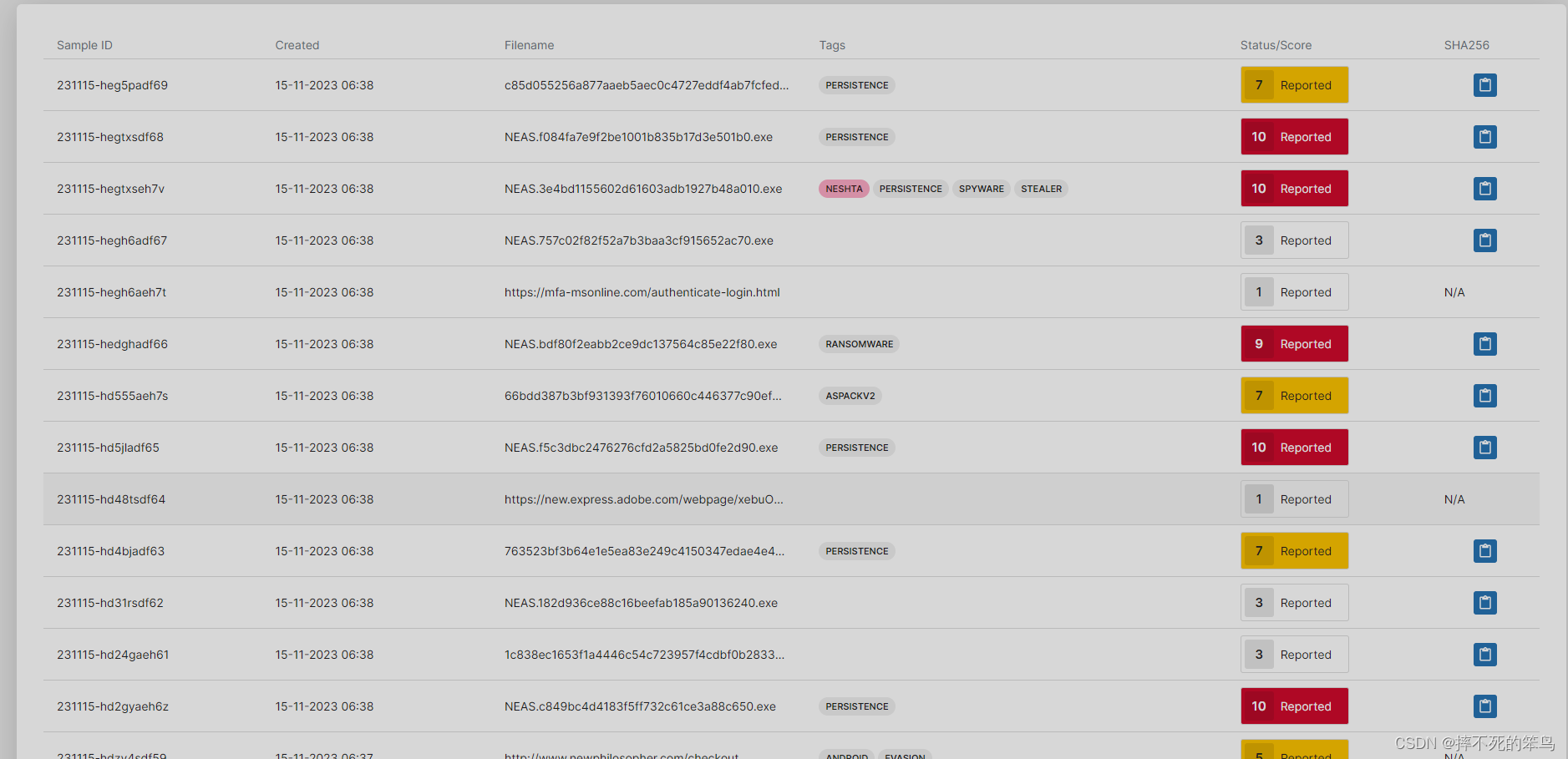
监控该沙箱结果产出的python代码如下:
import requests import datetime from bs4 import BeautifulSoup import hashlib import random import json import time import os import re user_agent = { "User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36' } #proxies = {'https': '127.0.0.1:7890'} proxies = {} write_file = 'triage_ioc.txt' def get_webcontent(url): try: response = requests.get(url,proxies=proxies,headers=user_agent,timeout=10) if response.status_code == 200: soup = BeautifulSoup(response.text, "html.parser") return soup except requests.exceptions.RequestException as e: print("[ERROR]:Fail to get WebContent!", e) return False def parse_sample_class(element): sample_class = [] temp = element.split('span class=') if len(temp)<2: return sample_class else: for str in temp: if str.find('span')!=-1: sample_class.append(str.split('">')[-1].split(')[0]) return sample_class def get_sample_c2(sample_id): sanbox_url = 'https://tria.ge/' + sample_id print(sanbox_url) soup = get_webcontent(sanbox_url) if soup == False or None: return [] temp = soup.find_all("span", class_="clipboard") regex = re.compile('(?<=title=").*?(?=")') c2 = regex.findall(str(temp)) return c2 def download_from_url(url,save_file): try: response = requests.get(url,proxies=proxies,stream=True,timeout=8) if response.status_code == 200: with open(save_file, "wb") as f: for ch in response: f.write(ch) f.close() except requests.exceptions.RequestException as e: print("Error downloading file:"+save_file, e) def write_to_file(str): with open(write_file,'a',encoding='utf-8') as d: d.write(str+'\n') d.close def parse_triage(): soup= get_webcontent('https://tria.ge/reports/public') if soup == False: return #print(soup) #print('——————————————————————————————————————————————————————') createtime = soup.find_all("div", class_="column-created") hash = soup.find_all("div", class_="column-hash") filename = soup.find_all("div", class_="column-target") fileclass = soup.find_all("div", class_="tags nano") score = soup.find_all("div", class_="column-score") regex = re.compile('(?<=data-sample-id=").*?(?=")') #提取href=""之间的url链接 sample_id = regex.findall(str(soup)) i = 0 while i<len(createtime): if str(score[i]).find('Running')!=-1 or str(score[i]).find('Submission')!=-1: i = i + 1 continue create_time = str(createtime[i]).split('">')[-1].split(')[0] print(create_time) file_name = str(filename[i]).split('title="')[-1].split('">')[0] print(file_name) sha256 = str(hash[i]).split('clipboard="')[-1].split('"')[0] if sha256.find('')[-1].split(')[0] print(sanbox_score) print(sample_id[i]) if sanbox_score!='' and int(sanbox_score)>=8: c2 = get_sample_c2(sample_id[i]) print(c2) if sanbox_score!='' and int(sanbox_score)>=8: if len(sha256) ==64: write_to_file(sha256) if c2!=[] and len(c2)<5: for domain in c2: write_to_file(domain) #if len(sha256) ==64: #print('Download sample:',sha256) #download_url = 'https://tria.ge/samples/' + sample_id[i] +'/sample.zip' #save_file = './sample/' + sha256 #download_from_url(download_url,save_file) #input() time.sleep(10) print('--------------------------------------------------------------------------------------------') i = i + 1 if __name__ == "__main__": if not os.path.exists('sample'): os.makedirs('sample') while 1: parse_triage() time.sleep(300) print(datetime.datetime.now())- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 相关阅读:
经济管理专业必备的15种国内数据库推荐
可观测平台如何存储时序曲线?滴滴实践全历程分享
APP 开发方式的优缺点有哪些?
基于JAVA-游戏账号交易平台-演示录像-计算机毕业设计源码+系统+mysql数据库+lw文档+部署
PHP 通过 Redis 解决并发请求的操作问题
7个最佳开源免费库存/仓库管理系统(WMS)
避免数据泄露风险!NineData提供SQL开发规范和用户访问量管理
redis哨兵模式详解
Python下载安装教程Python3.7版本
关于数据存储的三道面试题,你会吗?
- 原文地址:https://blog.csdn.net/qq_43312649/article/details/134419973
