-
高可用--限流&熔断&降级
熔断
熔断是应对微服务雪崩效应的一种链路保护机制。
场景
- 服务端出现问题
- 服务指标:响应时间、错误率、连续错误数等,超过阈值出发熔断。
- 硬件指标:CPU、网络IO、内存
目的
- 服务端恢复需要时间、服务端需要休息
- 避免全调用链路崩溃,不能再把请求再发给Server了,一旦堆积也会造成其他服务出现问题
手段
- 熔断器直接抛出熔断的异常响应,三个状态切换,决定是否处于熔断状态
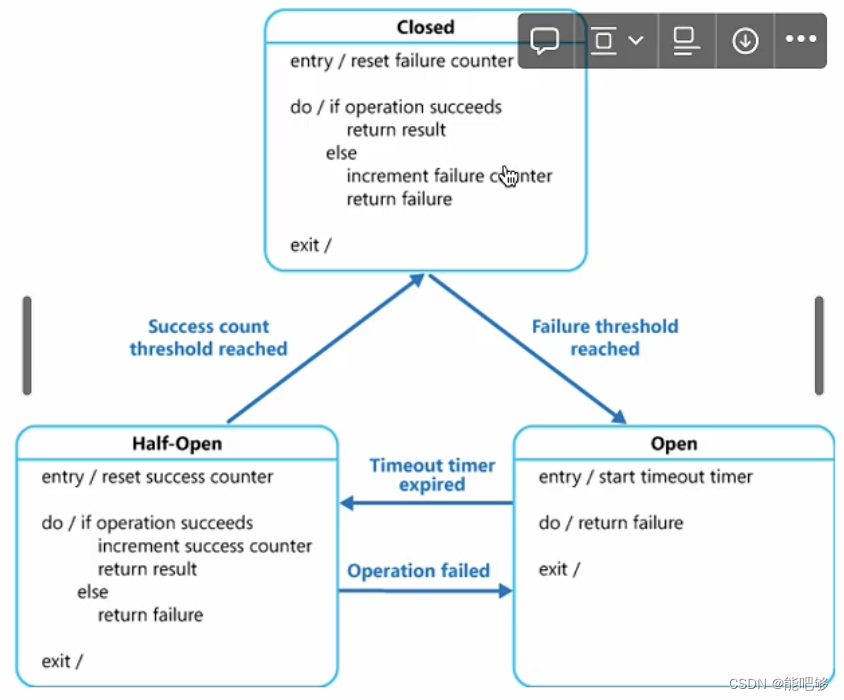
流程
- Server被监控到异常,出发熔断,熔断器抛出熔断的异常响应
- Client收到异常,利用负载均衡重新选择节点,后续请求不再打到被熔断的节点
- 一段时间后,Client再对这个节点重新请求,如果正常响应,则缓慢对这个节点放开流量,如果仍然是熔断状态,则继续执行Step2,如此循环
限流
场景 & 目的
-
突发的流量增大,使系统崩溃
-
判断指标:节点当前连接数、QPS等
静态算法
一般情况下,令牌产生速率/漏桶“开口速率”决定处理请求速率。
-
令牌桶:系统以恒定速率产生并把令牌放到桶里,每个请求从桶里拿到令牌才会被执行,反之被限流
-
漏桶:(令牌桶的桶容量是0就是漏桶)系统匀速产生令牌,没被取走也不会积攒下来。系统处理请求时均匀的。
-
固定窗口:固定时间段内,只执行固定数量的请求。
-
滑动窗口:滑动窗口随着时间线挪动窗口。
动态算法:BBR
类似于 TCP 的拥塞控制,根据一系列指标来判定是否需要触发限流。
流程
- 在中间件记录流量和阈值,并在中问件中实现限流算法。
- 对于偶发性的触发限流,只要在超时范围内,可以同步阻塞等待请求被处理。
- server的某个节点触发了 非偶发性限流,Client 利用负载均衡调低该节点的权重,尽量少向这个节点发请求。
如何确定阈值
- 阈值太低,导致资源被闲置;國值太高,导致系统撑不住而崩溃。
- 上线后看监控,根据业务峰值 QPS 来约定阈值。
- 上线前做压测,找准限流的阈值。
熔断&限流&降级关系
熔断是完全不再发请求,限流是降低发送请求的频率。
熔断是防止雪崩效应发生提前触发;降级
场景&目的
- 系统出现故障后的补救措施;或可预见的故障前的应对措施,来保证整体的可用性。
- 对非核心业务降级,为核心业务留出更多资源。
手段
- 考虑停用部分监控埋点、日志上报等观测类中间件。
- 根据业务场景判断,停用边缘服务,返回服务繁忙之类的响应。
- 对于有缓存的接口,降级时只查缓存,不查 DB,没命中缓存则返回错误的响应。
终:核心思想
- 如何判断节点的健康状态?是否需要熔断/限流/降级?
- 通过监控看指标:QPS、连接数、节点负载等
- 熔断/限流/降级后,怎么恢复?
- 熔断/限流搭配负载均衡,等节点恢复正常后,再重新选择
- 降级有时是手动恢复
- 服务端出现问题
-
相关阅读:
【第一阶段:java基础】第7章:面向对象编程中级-3(P319-P333):Object类详解、断点调试
女生适不适合干软件测试这一行?“钱”程如何?适合长期发展不?
Swin Transformer算法解读
Qt扫盲-QPen 理论使用总结
读《Linux内核设计与实现》我想到了这些书
前置微小信号放大器在光声技术的血管识别研究中的应用
华为机试真题 Java 实现【最多团队】
关于使用pandas导入excel文件失败,求帮助
【java中的反射】1.初识反射
CSS 3 弹跳的小球动画的制作
- 原文地址:https://blog.csdn.net/m0_61843855/article/details/134487564