-
验证码识别之OCR识别
验证码识别:
背景:
决定开一个专题给大家讲一下验证码识别,不要多想,我们不搞深度学习,知识用于攻破模拟登录的时候弹出的验证码,后续会给大家讲讲滑块等等,反爬虫策略如何应对。
好了,言归正传,目前市面上的验证码识别主要是:
- OCR识别 但是可能准确率不高
- 各种打码平台
- opencv
- 深度学习模型
环境安装:
首先需要安装一个软件,我们可以理解为驱动 Home · UB-Mannheim/tesseract Wiki (github.com),然后根据你的机器是32还是64傻瓜式安装即可。
然后配置一下环境变量:
安装完后,需要将Tesseract添加到系统变量中。
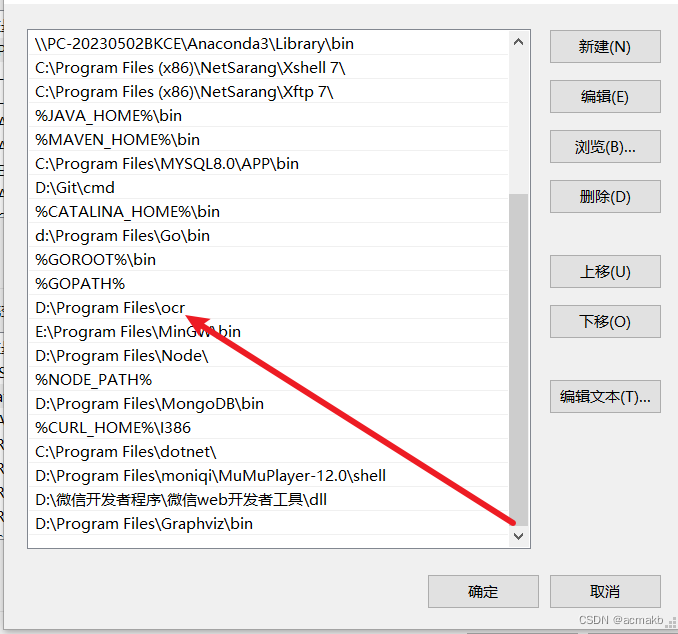
环境变量: 我的电脑 ->属性 -> 高级系统设置 ->环境变量 ->系统变量 ,在 path 中添加 安装路径。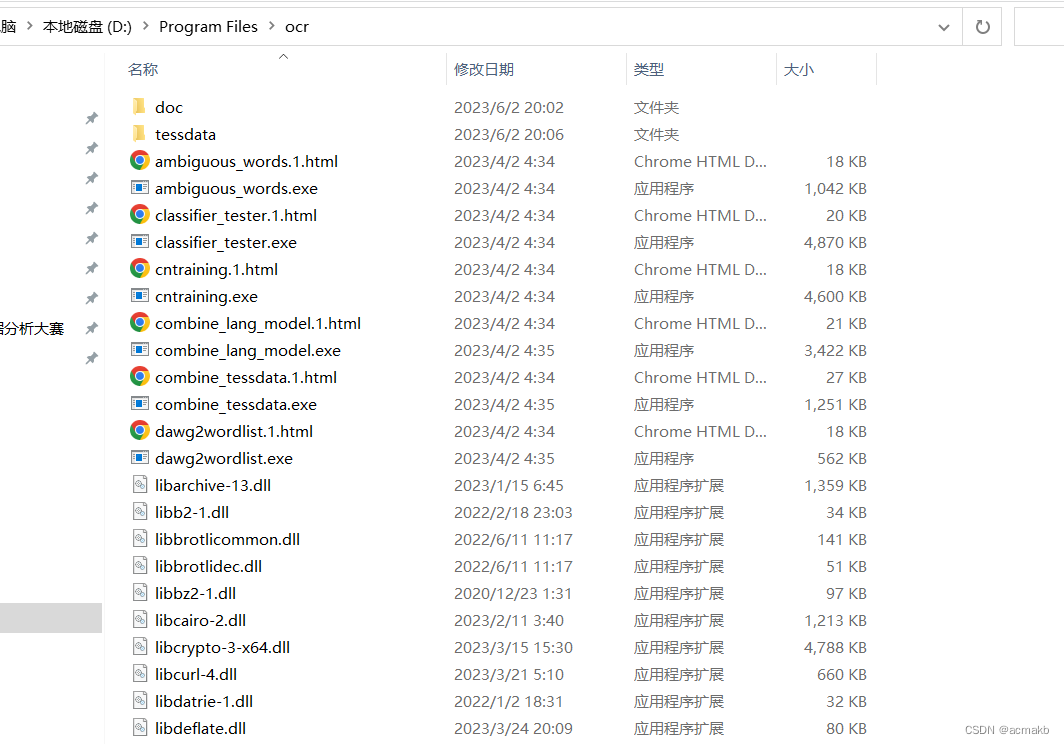
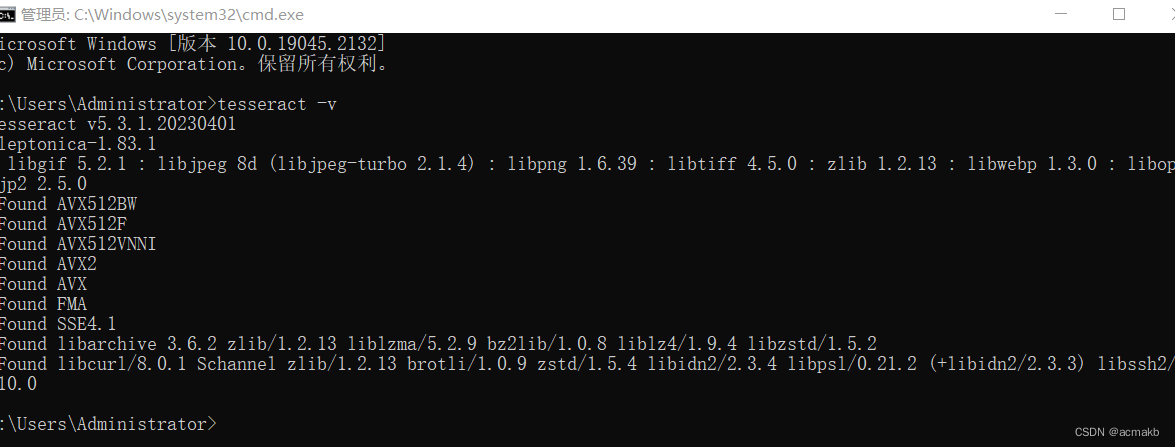
然后打开cmd输入:
tesseract -v- 1
然后出现版本就说明配置成功了!
然后需要安装两个python的外部库:
pip install pillow pip install pytesseract # 或者 conda install pillow conda install pytesseract- 1
- 2
- 3
- 4
- 5
OCR代码实现:
找一张图片去试试!我们平时模拟登录的时候一般是讲图片爬取到本地然后进行识别,然后调用识别后的值.

上代码:
import pytesseract from PIL import Image img = Image.open("./code.jpg") text = pytesseract.image_to_string(img, lang='eng') # lang='eng' 表示将识别语言设置为英语(English) 也可以识别数字 # text = pytesseract.image_to_string(img, lang='eng+chi_sim') print(text)- 1
- 2
- 3
- 4
- 5
- 6
参数:
除了英语之外,pytesseract还支持其他语言的文字识别。以下是一些常见的语言参数示例:- 1
-
英语:
lang='eng' -
中文简体:
lang='chi_sim' -
中文繁体:
lang='chi_tra' -
西班牙语:
lang='spa' -
法语:
lang='fra' -
德语:
lang='deu' -
意大利语:
lang='ita' -
日语:
lang='jpn' -
韩语:
lang='kor'大家可以根据需要将语言参数设置为适当的值。如果需要识别多种语言的混合文本,可以将语言参数设置为多个值,例如
lang='eng+chi_sim'表示同时使用英语和中文简体进行识别。我们看一下识别后的结果:
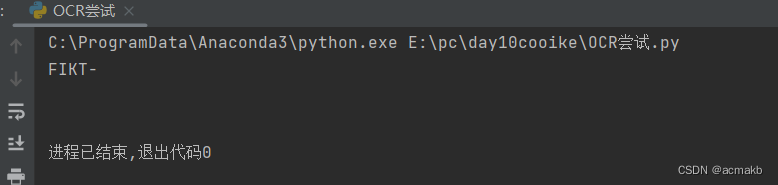
发现不是很一样吧,因为验证码边缘模糊,像素等等原因,直接使用OCR识别验证码识别率不高,我们也不常用,大家记住,天下没有免费的午餐,接下来我们看一下中文的识别效果。
识别文本:
import pytesseract from PIL import Image img = Image.open(r"E:\OCR\img\test.jpg") text = pytesseract.image_to_string(img, lang='eng+chi_sim') print(text)- 1
- 2
- 3
- 4
- 5

哟,识别的还不错,我们基于识别后的结果做一些字符串操作就可以准确得到啦!
-
相关阅读:
理论+案例,带你掌握Angular依赖注入模式的应用
OpenHarmony之C/C++编码风格一键格式化
go语言并发实战——日志收集系统(四) 利用tail包实现对日志文件的实时监控
刷题 | 迷宫求解
React报错之Cannot assign to 'current' because it is a read-only property
设计模式-结构型-适配器模式-Adapter
sulfo-CY3(Cyanine3) DBCO,磺酸基-花青素CY5二苯并环辛炔,1782950-79-1
leetcode:2926. 平衡子序列的最大和 【树状数组维护最大前缀和】
RunLoop解析
Session会话追踪的实现机制
- 原文地址:https://blog.csdn.net/ak_bingbing/article/details/134451597