-
【Linux系统编程十八】:(基础IO5)--动静态库共享/动静态加载问题(涉及地址空间)
一.可执行程序如何被加载的
1.加载之前
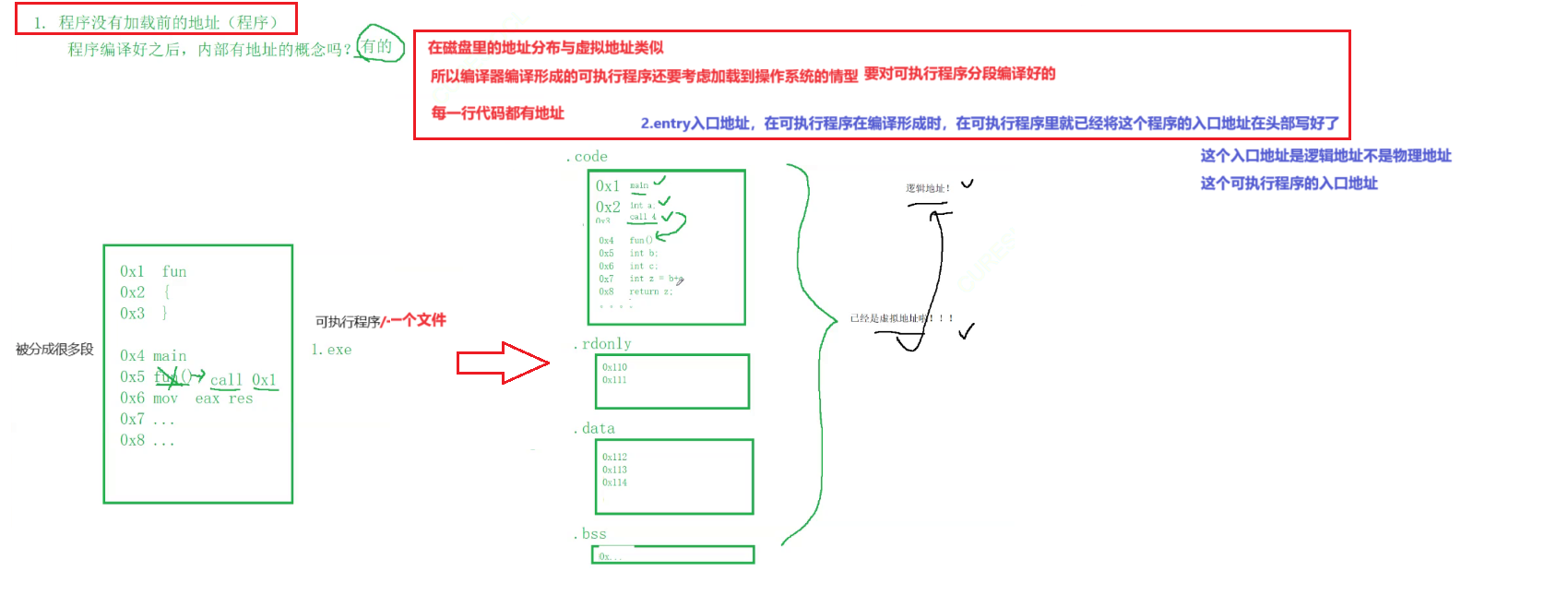
我们实际在当前的编译,在编译形成可执行的程序的时候。编译器是要考虑加载的问题的。
它不是说啊我随便编一下就完了啊,不是的,它呢是把可执行程序分段给我们编译好的。那么分段编译好之后呢,然后它上面在编译的时候,那么相关的字段都会有它对应的地址。
这个地址呢我们可以理解成叫做每一个函数它的入口,每一个变量它的定义,相对于零号地址数对应的一个偏移量。
所以这个地址在我们的程序当中已经存在了。
好,那么我们把这种在可执行程序当中的地址呢,我们其实把它叫做逻辑地址,逻辑地址其实它是一种断地址间偏移的一种表述方式。但其实说白了它已经是虚拟地址了啊,或者叫做线性地址了。所以这样的程序在没有被加载前,已经内部有地址了。
 这些指令每一个它都有地址,它将来都是c p u要去执行的。
这些指令每一个它都有地址,它将来都是c p u要去执行的。
那么我们c p u它怎么能够帮我去执行这些指令呢?c p u呢它其实呢已经在自己被制作的时候,就已经内置了很多能够认识这些基础指令的工作。只不过这些指令都是用二进制制作的,所以呢我们把这种数字二进制的,那么可以提前在c p u内部设置好很多的,我们把它称之为叫做指令集的东西。 也就是在cpu里面呢,你向它对应的一些就是寄存器当中写入这种指令集,它是会被被当做指令或者控制指令来看待的,它不会把它当数据处理的。
所以呢你的c p u呢它就能认识你喂给它的各种各样的这样的汇编。那汇编呢连起来一长啊多一多,它就变成了一种具体的动作。c p u它要能执行指令,它得先识别指令。
c p u它是能区分清楚哪些是指令,哪些是数据的。2.加载之后
可执行程序它在加载的内存的时候,它的所有的代码的指令呢,包括函数调用,变量等。
那么已经在我们那么可执行程序里面已经按照e l f这样的可执行程序的格式已经给我们编好了。
它内部的函数跳转时或者是变量寻找时都有它对应的地址。
每个进程还有自己的p c d对象,这就叫task_struct。每一个进程还有自己所对应的叫做地址空间啊
未来呢c p u要执行对应的代码和数据,c p u要执行我们定义的代码和数据的时候,那么我们现在程序已经加入了内存了。
那么我们进程数结构也也创建好了,那么下面我们该如何破局呢?①如何执行第一条命令

你c p u执行指令的时候啊,那么如何执行第一条指令呢?关键在于我们对应的可行程序形成的时候,它里面包含了一个e n t r y啊,叫做我们的入口地址。他的可行程序在编译形成的时候,他已经在自己的可行程序里,头部呢提前把自己整个程序的入口地址已经写好了。入口地址是逻辑地址啊,在内存里它就叫做虚拟地址。所以当我们对应的这个可行程序被加载到内存的时候,那么一方面我们把程序加到内存,当然你也可以不加载啊,因为我们曾经讲过,一一定是先形成内核这部分的,也就是内存储结构先有。
然后呢,我们的可行程序要运行的时候,它其实首先要做的就是把我们这个表当中,我们叫做入口地址拿过来。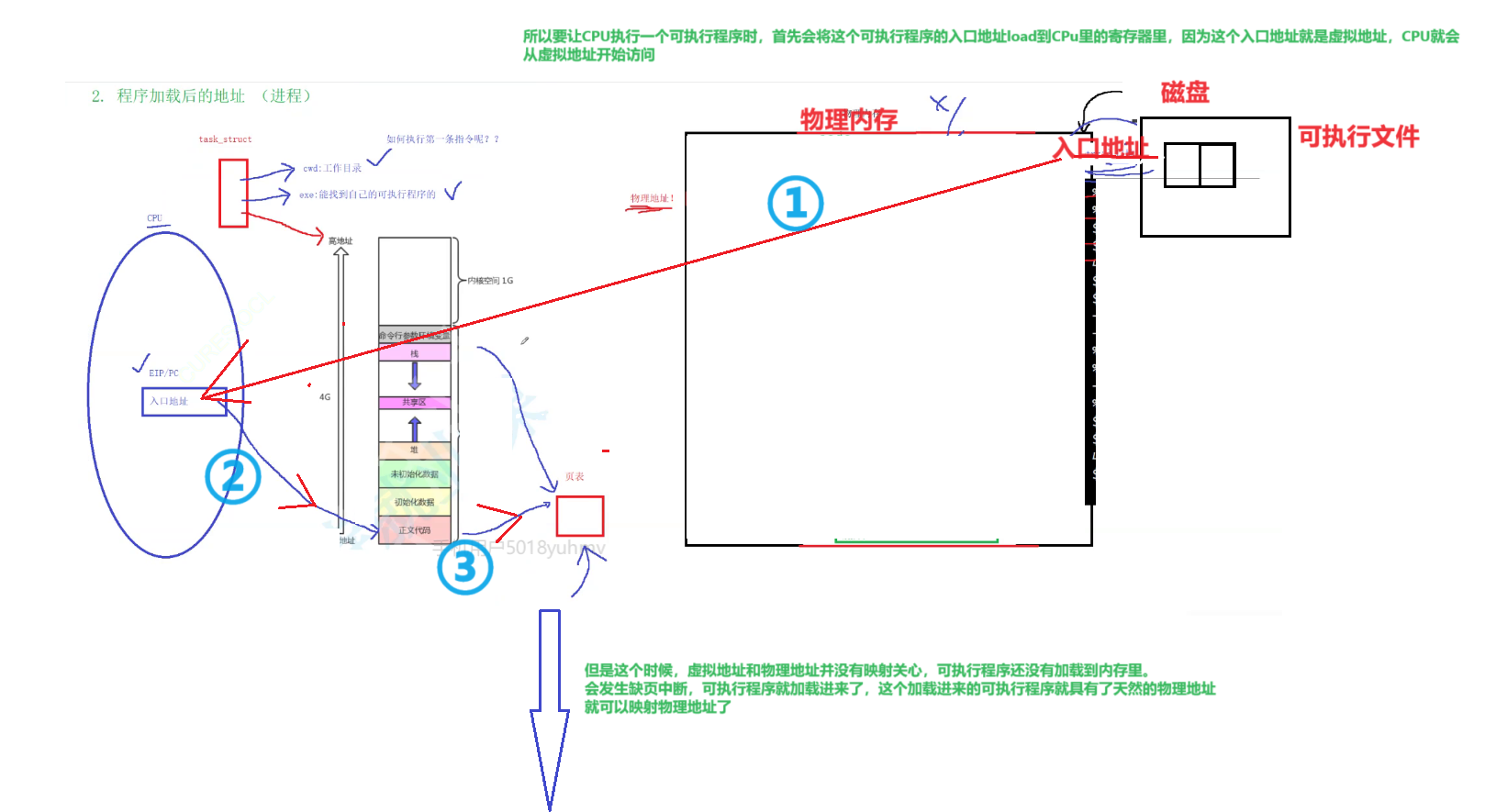
所以呢我们直接在读取这个可行程序时,把对应的入口地址直接load到c p u的寄存器当中。
好,那么录录到c p u的寄存器里面的时候,这个地址因为它这个地址已经是在天然编织的时候,就是一个我们对应的虚拟地址。
所以从c p u就开始执行了。
那么当它开始执行的时候,它就需要从经过我们对应的经过我们对应的页表呢来把我们对应的就是这个地址,很明显就是虚拟地址了。读第一条指令,这个先读到的地址就是虚拟地址。
c p u去执行的时候,发现这个页表当中有没有建立对应的内存,就会触发缺页中断。缺页中断后,我们的程序时候就被加载进来了。②缺页中断/与地址空间建立联系
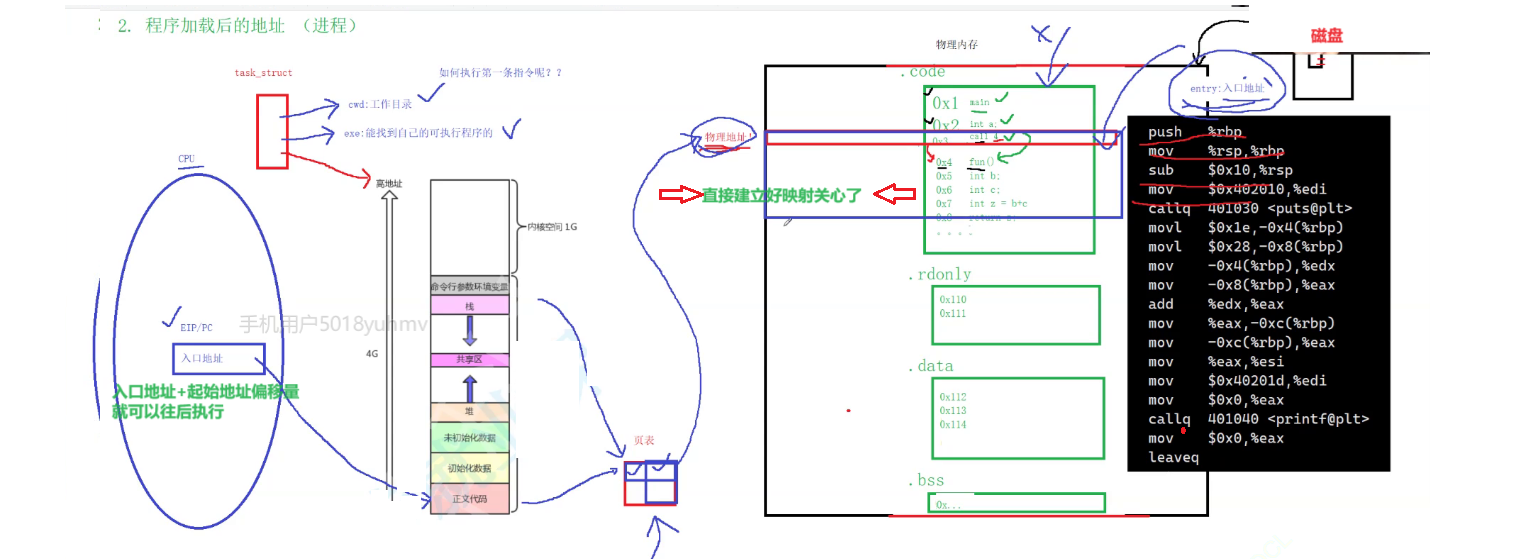
它加载到内存的时候,它要不要占据我们对应的叫做词呃物理内存当中的空间呢可执行程序加入到内存的时候,要不要占据那个内存的空间啊?它是需要的啊。那么它是不是也一定会同步的存在?
既然它要占物理内存,所以整个代码或者数据呢或者是各种区域呢,每一条呢它都要有自己对应的物理地址。
当你把对应的可执行程序加载到我们对应的内存之后呢。
啊,加载到我们对应的内存之后,那么每条只有天然的就具备了物理地址。
你要访问的是你内部的地址啊,但是你自己这条指令它有自己的物理地址。
那么所以当我们的程序加载到内存的时候,它每一行指令,它都会有两套地址。
一个叫做我们自己内部所采用的,曾经加载内存之前的叫做逻辑地址啊,那么另一个就是加载物理内存时所具备的物理地址。
好,这个道理呢就好比。你在学校里面。每一个人都有自己的学号。这是在全校范围内给我们编好的。那么可是呢当我们坐在一个具体的教室里面的时候,我可能坐在桌子每一张桌子,比如说五十张桌子编号一到五十。我坐在其中的三号桌子上,那么当我坐在那个桌子上的时候,我就叫做从教室外加载到教室内。那么此时我自己内部用的地址,我自己和我的同学啊,我们之间聊的话,我们用的是学号。可是当我们坐在教室里的时候,我们每一个人桌子上也有对应的地址,我们叫做物理地址。
被加载进来之后,刚刚我说了,一旦你被加载,你的程序天然就具备了物理地址。好,加载的具体地址我就知道了。那么这个天然的物理地址和可执行程序内部的逻辑逻辑地址(也就是虚拟地址)就直接建立映射关系了。
对应的页表里就可以立马填上左侧的虚拟地址和右侧的页表的物理地址。
因为加载之后的程序是有两套地址的。
具体到物理地址这个地址初始化页表,这时页表映射关系瞬间建立。
我们在程序内部,在你的程序内部已经编好的这个虚拟地址,我已经给你搞好了,拿过来用就行了。
所以而且你一站在物理内存上,每一条指令都天然就具备了它的,我们可以称之为物理地址。
所以我们的物理列表一填,同学们此时映射关系就建立好了。c p u不知道这个指令,发现它是一个函数调用,c p u在读到指令时,你的指令内部用到的地址,告诉我这是什么地址。指令也可能要进行我们对应的寻址了,寻找什么函数的地址,而这个函数地址是什么呢?
没错,这个地址它就是逻辑地址即虚拟地址。
所以直接调用,先在虚拟地址空间里找到我们的新地址,再转成物理地址。
最后再从物理地址转成我们所对应的这个我们对应的这个指令处开始进行
CPU从读取程序当中的地址。
到内部分析处理,到我们最后再重新二次继续访问它。整个过程我们凡是读到的这个指令里面的地址都是虚拟地址。
但c p u真正的要找到你,你再怎么给我虚拟,也找不到,真正的数据在物理地址里,所以这也就不需要虚拟地址转换成物理地址了。可执行程序,其实它有两个地址,编译器编译的时候就已经考虑虚拟地址空间了。进程在设计的时候就已经考虑了你对应的地址空间了。这就是我们编译器和操作系统互相协同的最重要的表现之一。
二.动态库如何加载的
动态库就是一个可执行文件,它的加载与可执行文件的加载是一样的关键问题在于我把这个动态库应该映射到我的共享区里,这个可执行程序里面那么任何地址它都是我们对应已经编译好对应的线性地址。
好,你今天要调的这个地址,那在我看来他也是序列地址喽。那么如果按照序列地址的话,那么共享库加载它在序列地址里必须被加载到这个位置。也就是我在把我们对应的磁盘当中,把对应共享库加载到对应的那么内存里,加到对应的内存映射的时候,必须得把它映射到固定位置处。那这就有点坑爹了。
一个进程在运行时,你的库先加载后加载完完全全料不定了。
因为你的程进程可能要有十几个库,我怎么保证每一个库它都必须得加载到固定位置呢?
那么被加载到我们对应的叫做固定地址空间。固定地址我给占了怎么办?你怎么保证你每一次加的时候,还要让这个库固定的映射到一个位置,那这个成本太高了。
库呢设计成得想办法让他在共享区任意位置加载都可以。我们是采用相对以逻辑地址加偏移量的方式。
我们只以偏移量来标准啊,或者给大家写清楚,我们不要采用绝对地址来编制。只要每个函数在库中的偏移偏移量即可。
好,也就是说呢,我自己动态库啊,我自己在编的时候,我不要太多。你把每一个库它在地址空间里的起始地址,你给我记下来就可以。
我我们在加载时,最后我们来确定加偏量就能访问到它在库当中的绝对地址了。
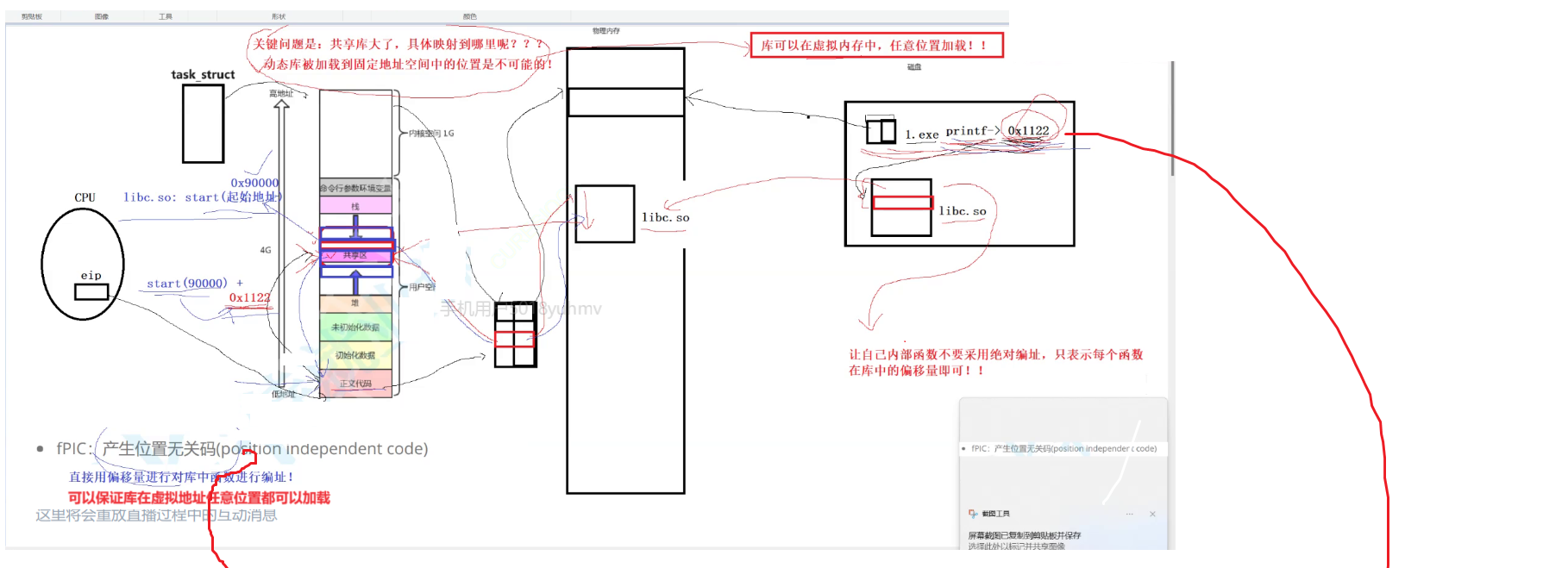
这也是为什么在制作动态库时,需要一个东西叫做FPIC与位置无关码了。
我我们在加载时,最后我们来确定加偏量就能访问到它在库当中的绝对地址了。三.动态库如何实现多进程间共享的
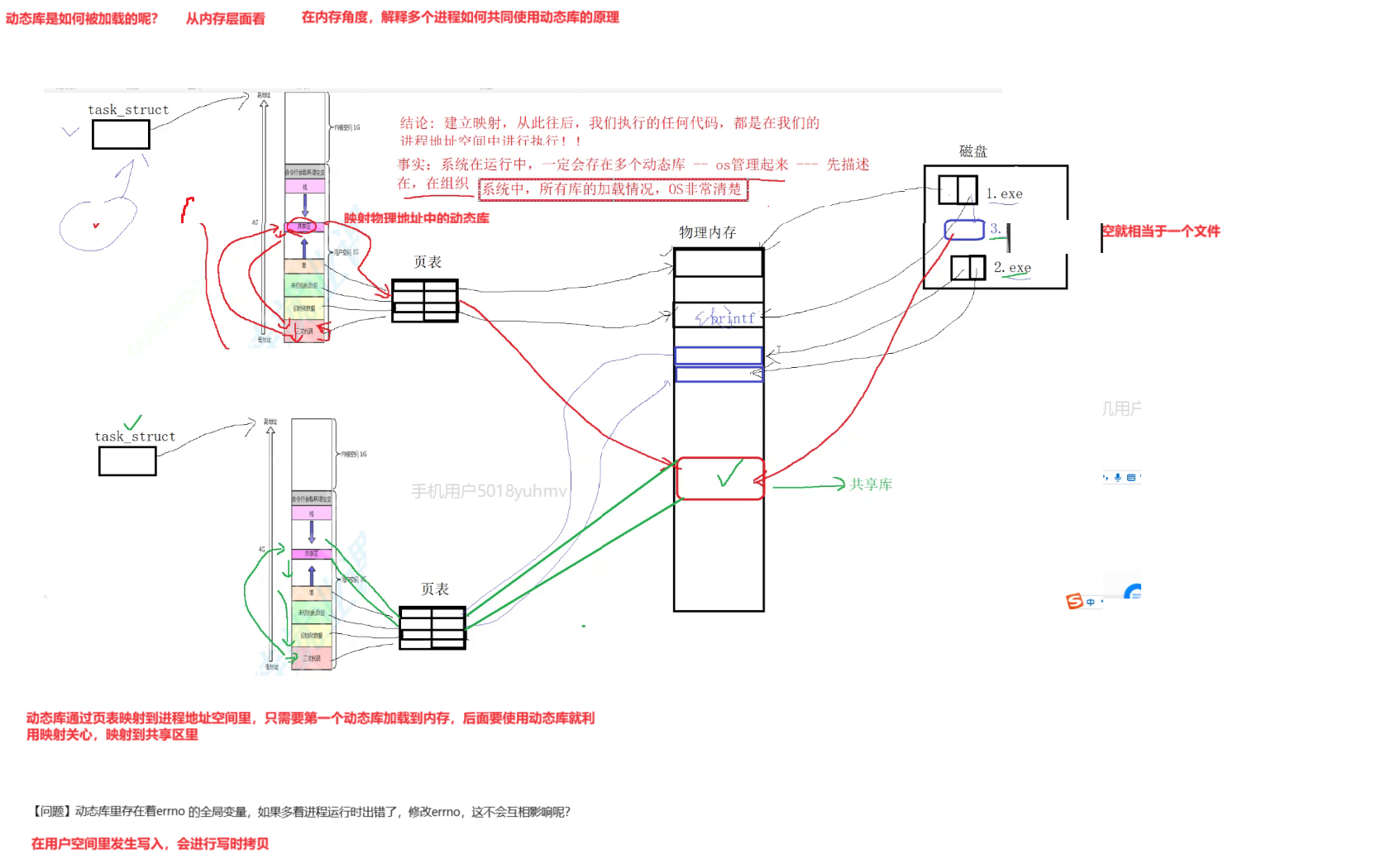
动态库通过页表映射到进程地址空间的共享区里,只需要第一俄国动态库加载到内存里,后面要是有动态库就直接建立映射关系到共享区里,就可以使用。 -
相关阅读:
钉钉小程序 访问ip不在白名单之中
【小程序图片水印】微信小程序图片加水印功能 canvas绘图
Java框架总结三
每日一练 | 华为认证真题练习Day220
计算机毕业设计(附源码)python疫情下校园食品安全信息管理
【JUC】多线程基础概述
某今日头条_signature解析
神奇的嗅觉
04-树5 Root of AVL Tree
基于springboot实现医院固定资产平台系统项目【项目源码】计算机毕业设计
- 原文地址:https://blog.csdn.net/Extreme_wei/article/details/134446108