-
CUDA学习笔记8——GPU硬件资源
简单来说就是为了充分利用GPU,不要让分出去的CUDA核心摸鱼闲置;GPU每次干活,都是以最小的组分配的,因此分派任务的时候就尽量充分发挥每个小组里CUDA核心的作用。这里的每个小组就是一个SM(stream multi-processor);因为硬件设计的时候每个SM里设计了固定个数的CUDA核心(如Fermi架构SM里有32个CUDA核心);对应软件端,线程会以线程块的形式分配到SM上;因此计算线程束数量时候就整份整份的去分配。
流式多处理器/stream multi-processor(SM)
GPU架构是围绕一个流式多处理器/stream multi-processor(SM)的扩展阵列搭建的。通过复制这种结构来实现GPU的硬件并行。
一个GPU是由多个SM构成的,Fermi架构SM包括以下关键组件:- CUDA核心(CUDA core)
- 共享内存/一级缓存(shared memory / L1 cache)
- 寄存器文件(Register File)
- 加载/存储单元(Load/Store Units)
- 特殊功能单元(Special Function Unit)
- 线程束调度器(Warps Scheduler)
如图 - 橙色部分:2 个 Warp Scheduler/Dispatch Unit
- 绿色部分:32 个 CUDA 内核,分在两条 lane 上,每条分别是 16 个
- 浅蓝色部分:register file-寄存器文件和 L1 cache
- 16 个 Load/Store units (LD/ST Unit)
- 4 个 Special Function Units (SFU)
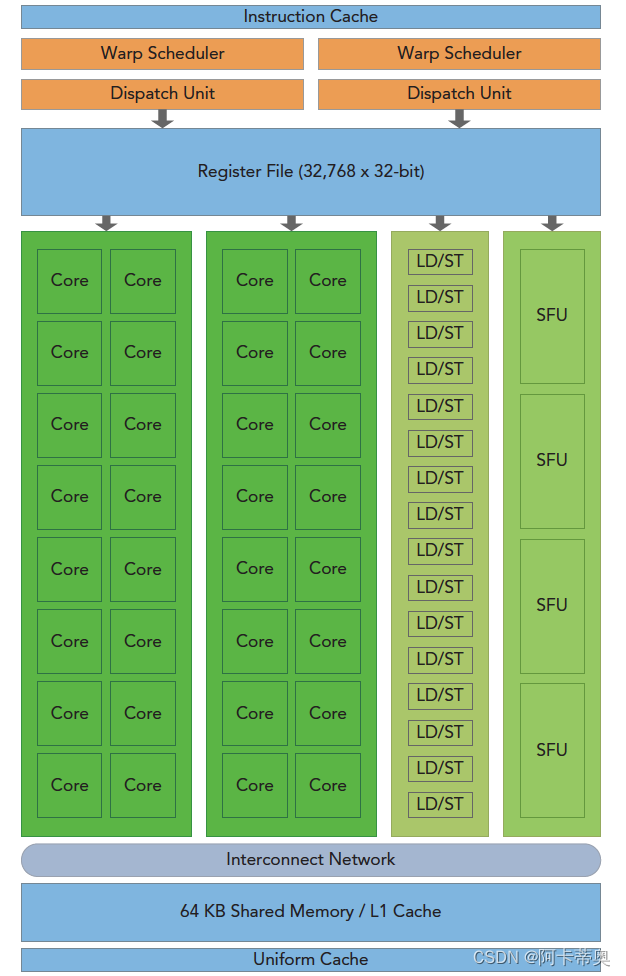
每个 SM 具有 32 个 CUDA 内核,就是图中写着Core的绿色小方块儿,每个 CUDA 内核都有一个完全流水线化的整数算术逻辑单元 (ALU) 和浮点单元 (FPU):
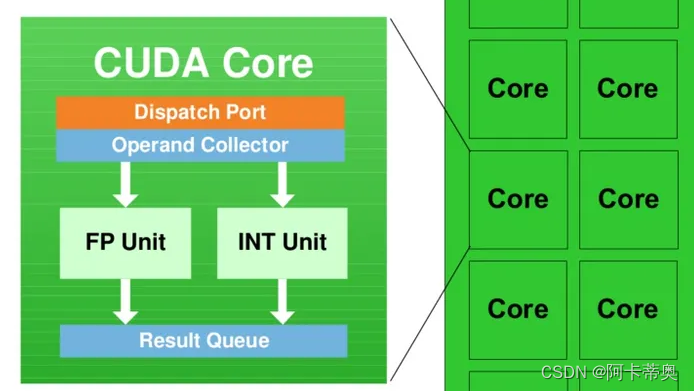
GPU中每个SM都可以支持数百个线程并发执行;
并发与并行区别:
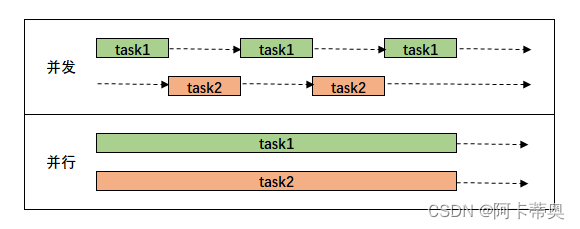
以线程块block为单位,向SM分配线程块,多个线程块可以同时被分配到一个可用SM上,同时执行线程块的大小取决于GUP硬件;
当一个线程块被分派好SM后,就不可以再分配到其他SM上;软件抽象资源包括Thread、Warp、Block和Grid
硬件资源包括SP和SM
网络中的所有线程块需要分配到SM上进行执行;
线程块内的所有线程块需要分配到同一个SM中执行,但是每个SM上可以被分配多个线程块;
线程块分配SM中后,会以32个线程为一组进行分割,每个组成为一个warp;(因为硬件资源有限,所以活跃的线程束的数量会受到SM资源限制)线程束数量=ceil(线程块中的线程数/32) ——向上取整
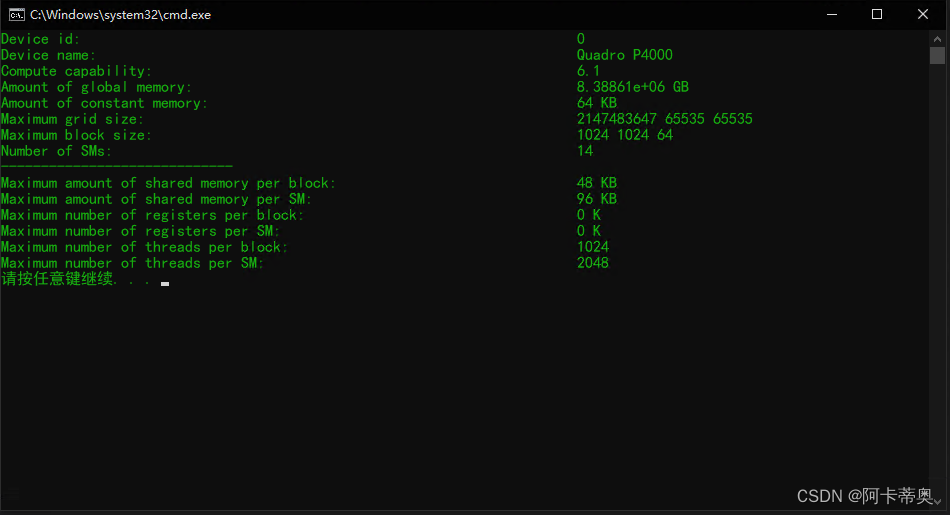
GPU设备规格查询
#include#include "cuda_runtime.h" #include "device_launch_parameters.h" int main() { int device_id = 0; cudaDeviceProp prop; cudaGetDeviceProperties(&prop, device_id); printf("Device id: %d\n", device_id); printf("Device name: %s\n", prop.name); printf("Compute capability: %d.%d\n", prop.major, prop.minor); printf("Amount of global memory: %g GB\n", prop.totalGlobalMem / 1024.0); printf("Amount of constant memory: %g KB\n", prop.totalConstMem / 1024.0); printf("Maximum grid size: %d %d %d\n",prop.maxGridSize[0], prop.maxGridSize[1], prop.maxGridSize[2]); printf("Maximum block size: %d %d %d\n", prop.maxThreadsDim[0], prop.maxThreadsDim[1], prop.maxThreadsDim[2]); printf("Number of SMs: %d\n", prop.multiProcessorCount); printf("----------------------------- \n"); printf("Maximum amount of shared memory per block: %g KB\n", prop.sharedMemPerBlock / 1024.0); printf("Maximum amount of shared memory per SM: %g KB\n",prop.sharedMemPerMultiprocessor / 1024.0); printf("Maximum number of registers per block: %d K\n", prop.regsPerBlock / 1024.0); printf("Maximum number of registers per SM: %d K\n", prop.regsPerMultiprocessor / 1024.0); printf("Maximum number of threads per block: %d \n", prop.maxThreadsPerBlock); printf("Maximum number of threads per SM: %d \n", prop.maxThreadsPerMultiProcessor); return 0; } - 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
-
相关阅读:
Oracle-Ogg集成模式降级为经典模式步骤
mysql日志持久化机制
常见首屏优化
如何判断线程池任务执行完?
CGCS2000、WGS84和ITRF框架坐标之间的差异和转换方法
一文搞懂Maven配置,从此不再糊涂下载依赖(文末有成品)
CSS常用属性(二)
目标检测论文解读复现之十一:基于特征融合与注意力的遥感图像小目标检测
济南抢注商标与商标在先使用如何认定
Java笔记——文件操作I/O 01
- 原文地址:https://blog.csdn.net/akadiao/article/details/134448806
